こちらのBlogの翻訳記事になります。
https://medium.com/plotly/building-plotly-dash-apps-on-a-lakehouse-with-databricks-sql-b9761c201717
著者紹介
コディ・オースティン・デイヴィス (ソリューションアーキテクト、Databricks)
ハンナ・カー (Plotly社ソリューションアーキテクト)、Tammy Do氏、Daniel Anton Suchy氏からの寄稿。
参考リソース
Github リポジトリ | ライブアプリ | 8分間のチュートリアル
今回は使用しておりませんが、UnityCatalogにも対応しております。
概要
Python開発者、データサイエンティスト、その他Plotly Dash分析ウェブアプリケーションのフロントエンドをDatabricksのバックエンドに接続したい人は、Databricks SQL connector for Python(DBSQL)により、DatabricksとPlotly間の統合可能性を深め、分析コミュニティに最高クラスのインタラクティブ、柔軟、スケーラブルアプリケーションをもたらすことができるようになりました。
このライブラリにより、Plotly DashアプリはDatabricks SQLエンドポイント上で実行されるSQLクエリの結果を非常に迅速に実行・取得できるようになり、Databricksの顧客は以下のような幅広い分析データアプリの使用例に対してプラットフォームの使用を拡張・最大化できるようになりました
- データウェアハウスユースケース。SQL Endpointを他のデータウェアハウスと同様に接続する
- 高度なウォーターフォールフィルタリング/ビジュアライゼーション
- Dashアプリのダイナミックなスライダー/フィルター/依存ビジュアル
- 複雑で負荷の高いSQLクエリをDatabricks SQL Photonエンジンで実行し、記録的なパフォーマンスを実現します。
- リアルタイム ストリーミング ダッシュボード - DBSQL と Dash の
dcc.intervalコンポーネントを使用して、Dash アプリの更新をライブ ストリーミングします
詳細
Databricksから出荷されたサンプルデータセットを使用して、Databricks SQL上でシンプルなデータベースを構築する手順を説明するので、どのDatabricks環境でもSQLを実行することができます。データベースを作成した後、Databricks SQLエンドポイント上Dashアプリを構築することでフルスタックデータアプリケーションを配信・ホストします。
Gitプロジェクトをクローンすることで、ブログを読みながら自由に再作成してください。
このRepoを実行するための前提条件
- DatabricksSQLが有効なDatabricksワークスペース(Premium Workspaces以上でDBSQLが有効)
- 9.1LTS以上のDBSQLエンドポイントまたはDatabricksクラスタ(データエンジニアリングクラスタ)
- SQLエンドポイントにAPI経由で認証するためのDatabricksのパーソナルアクセストークン
- Pythonの開発環境(>=v 3.8)が必要です。ローカルIDEとしてVSCodeを、依存関係を管理するためにcondaやvirtual envを、コードを自動整形するためにblackを使うことをお勧めします。
ハイレベルなステップ
- クラシックまたはサーバーレスでDatabricksSQL(DBSQL)エンドポイントを作成する
-
utils/BuildBackendIoTDatabase.sqlの下にある SQL コードを DBSQL Query Editor にコピー&ペーストし、実行します。(注: DatabricksでインポートしたRepoから直接ノートブックでこのコードを実行することもできます。) - 上記のGitレポをローカルIDEにクローンします。
- Dashアプリを実行する場所に、IDEで
pip install -r requirements.txtを使用して依存関係をインストールします。 - DatabricksクラスタからSERVER_HOSTNAME、HTTP_PATH、ACCESS_TOKENの環境変数を設定します。SQLエンドポイントを選択し、エンドポイントUIの「接続の詳細」タブをクリックすると、この情報が表示されます。
- ローカルサーバ上でDashアプリを実行するには、
python app.pyを実行します。
Dashアプリのバックエンドを構築する
まず、Databricks でデータベースを作成し、その上に Dash アプリを構築することにします。始める前に、Databricks の SQL 環境でデータベースを作成するための権限があることを確認してください。Databricksに付属しているサンプルデータセットのdatabricks-datasetsリポジトリを利用することにします。このデータはJSONとCSV形式で提供されているので、単純なCOPY INTO文を実行するだけで生データを段階的に読み込み、Delta Tableに挿入することができます。このETLスクリプトは、ユーザーからのスマートウォッチの読み取りを表すIoTデータを読み込むものです。現実的なデータベースの動作を実装するために、生データに更新があることを想定し、パイプラインをMERGE INTO文で終了し、以下のようにupsertロジックを処理することができます。この処理を実行して、最終的に2つのテーブル、silver_sensors と silver_users を作成します。ここで「silver」という名称は、データが基本的なクリーニングを経て、BI Analyticsの準備が整ったことを示しています
Step 1 — Create Table
CREATE TABLE IF NOT EXISTS plotly_iot_dashboard.bronze_sensors
(
Id BIGINT GENERATED BY DEFAULT AS IDENTITY,
device_id INT,
user_id INT,
calories_burnt DECIMAL(10,2),
miles_walked DECIMAL(10,2),
num_steps DECIMAL(10,2),
timestamp TIMESTAMP,
value STRING
)
USING DELTA
TBLPROPERTIES("delta.targetFileSize"="128mb")
--LOCATION s3://<path>/
;
Step 2 — Incrementally read in raw data with COPY INTO
-- DBTITLE 1,Incrementally Ingest Source Data from Raw Files
COPY INTO plotly_iot_dashboard.bronze_sensors
FROM (SELECT
id::bigint AS Id,
device_id::integer AS device_id,
user_id::integer AS user_id,
calories_burnt::decimal(10,2) AS calories_burnt,
miles_walked::decimal(10,2) AS miles_walked,
num_steps::decimal(10,2) AS num_steps,
timestamp::timestamp AS timestamp,
value AS value
FROM "/databricks-datasets/iot-stream/data-device/")
FILEFORMAT = json
COPY_OPTIONS('force'='true') --option to be incremental or always load all files
;
Step 3 — Upsert Data into final tables called silver_sensors
-- DBTITLE 1,Perform Upserts - Device Data
MERGE INTO plotly_iot_dashboard.silver_sensors AS target
USING (SELECT Id::integer,
device_id::integer,
user_id::integer,
calories_burnt::decimal,
miles_walked::decimal,
num_steps::decimal,
timestamp::timestamp,
value::string
FROM plotly_iot_dashboard.bronze_sensors) AS source
ON source.Id = target.Id
AND source.user_id = target.user_id
AND source.device_id = target.device_id
WHEN MATCHED THEN UPDATE SET
target.calories_burnt = source.calories_burnt,
target.miles_walked = source.miles_walked,
target.num_steps = source.num_steps,
target.timestamp = source.timestamp
WHEN NOT MATCHED THEN INSERT *;
Step 4 — Select from the database
-- COMMAND ----------
SELECT * FROM plotly_iot_dashboard.silver_sensors;
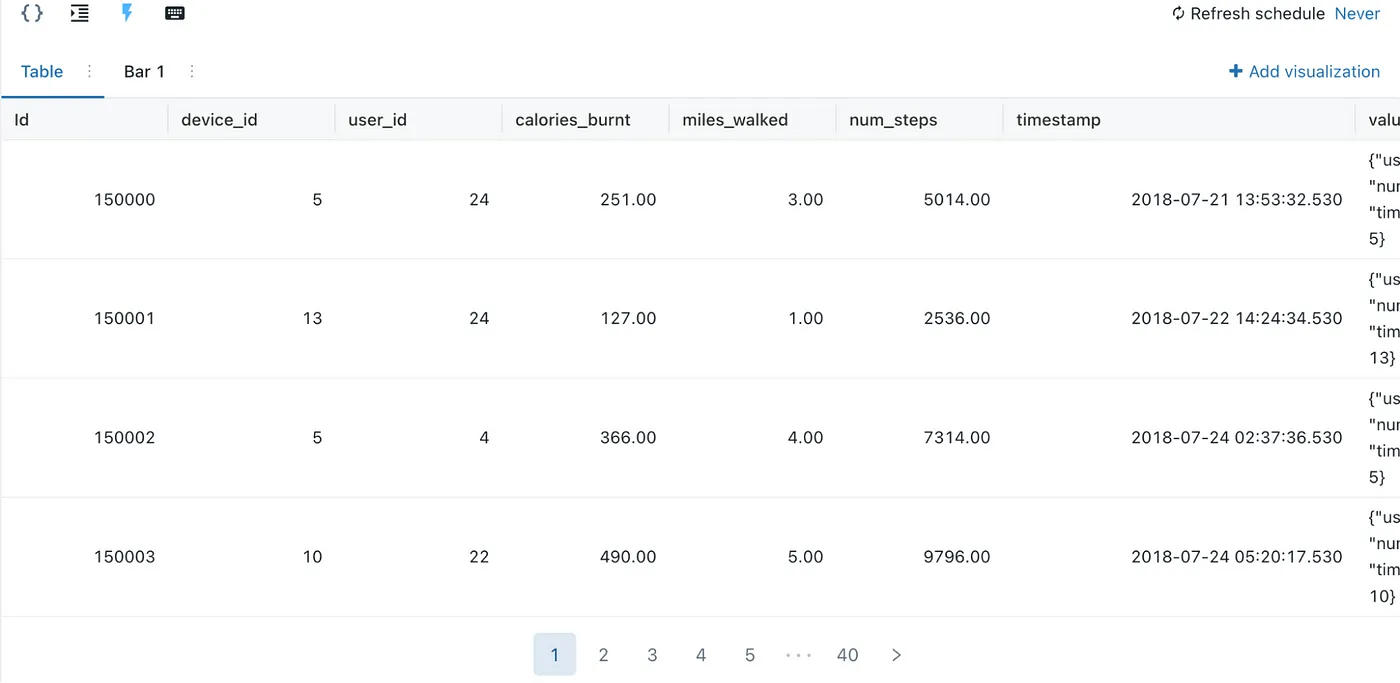
Set Up Plotly UI
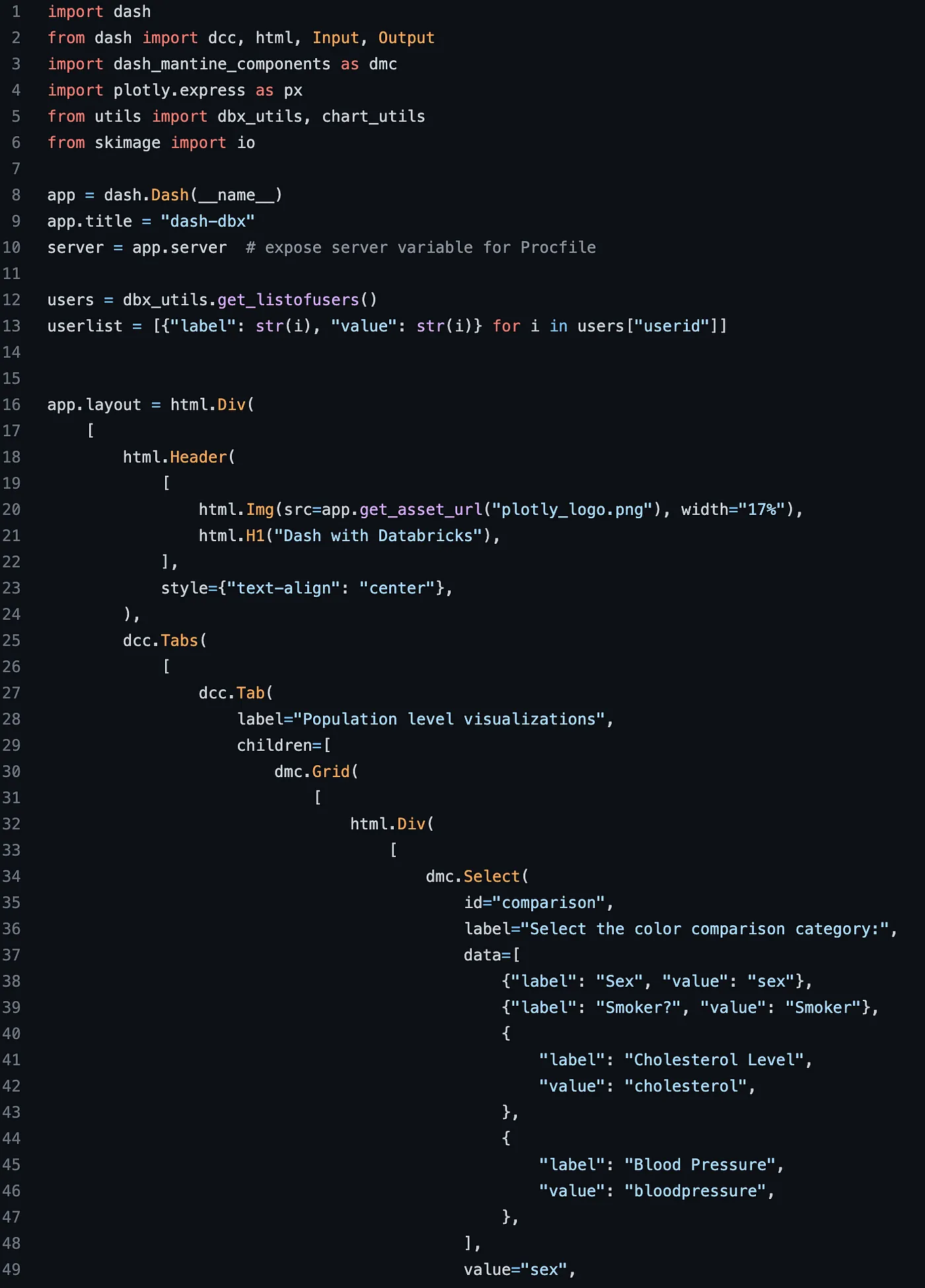
データベースの作成が完了したので、Plotly Dashアプリの構築を開始します。このプロセスでは、ローカルの IDE にアクセスします。app.py ファイルはこのアプリケーションのエントリポイントであり、アプリのレイアウトとインタラクティビティのための Dash 固有のコードを含んでいます。
Dash app foundations
アプリのレイアウトは、一連のネストしたコンポーネント(dcc.Graphやhtml.Divなど)を通じて定義され、完全に設定可能なUIを作成することができるようになります。詳細については、このドキュメントの例を参照してください。
Dash アプリには、コールバック関数によってインタラクティビティが追加されます。コールバックは、特定のユーザーアクション(ボタンのクリックなど)に対してトリガーされ、アプリのレイアウトの要素に変更を出力することができます。この例では、コールバック関数を使用して、ユーザーがドロップダウン項目を選択したときに、データ取得関数をトリガーして、チャートに表示されるデータを更新しています。また、dbx_utils.get_listofusers()関数で、Databricksからあらかじめ入力されたフィルタ値を読み込んでいることにも気づかれると思います。これは、DatabricksのSQLからDashアプリに値を渡すことができる多くの方法の1つです
データベース接続関数を書く
Dash アプリのコールバック関数をセットアップする前に、まずデータベースとやりとりするコードを書く必要があります。databricks-sql コネクタ、または SQLAlchemy を使えば、DBSQL から databricks を取得するための再利用可能な関数、例えば上記の get_listofusers 関数を書くことができます。この関数はdbx_utilsライブラリで以下のように定義されています。
変数のセット
DB_NAME = "plotly_iot_dashboard"
USER_TABLE = "silver_users"
DEVICE_TABLE = "silver_sensors"
Import connector
from databricks import sql
接続
def get_listofusers():
connection3 = sql.connect(
server_hostname=SERVER_HOSTNAME,
http_path=HTTP_PATH,
access_token=ACCESS_TOKEN,
)
cursor3 = connection3.cursor()
cursor3.execute(
f"SELECT DISTINCT userid FROM {DB_NAME}.{USER_TABLE} ORDER BY userid ASC"
)
df = cursor3.fetchall_arrow()
df = df.to_pandas()
cursor3.close()
connection3.close()
return df
また、以下の2つの関数で、チャートに入れる結果のpandas dataframeを読み込み、アプリで提供するための関数を生成しています。
Databricks SQL Endpointからデータを取得する
def get_scatter_data(xaxis, comp):
"""
Fetches specified columns and an aggregated column from the silver_users table, returns it as a pandas dataframe
Returns
-------
df : pandas dataframe
basic query of data from Databricks as a pandas dataframe
"""
connection0 = sql.connect(
server_hostname=SERVER_HOSTNAME,
http_path=HTTP_PATH,
access_token=ACCESS_TOKEN,
)
cursor0 = connection0.cursor()
cursor0.execute(
f"""SELECT {xaxis}, {comp}, risk, Count(DISTINCT userid) AS Total
FROM(
SELECT
CASE WHEN gender='F' THEN 'Female' ELSE 'Male' END AS sex,
age, height, weight,
CASE WHEN smoker='N' THEN 'Non-smoker' ELSE 'Smoker' END AS Smoker,
cholestlevs AS cholesterol, bp AS bloodpressure, risk, userid
FROM {DB_NAME}.{USER_TABLE}
)
GROUP BY {xaxis}, {comp}, risk
"""
)
df = cursor0.fetchall_arrow()
df = df.to_pandas()
cursor0.close()
connection0.close()
return df
Plotlyでチャートを生成するための関数にデータを渡す
def generate_scatter(df, xaxis, comp):
axis_labels = {
"age": "Age (years)",
"height": "Height (inches)",
"weight": "Weight (lbs)",
}
fig = px.scatter(
df,
x=xaxis,
y="risk",
color=comp,
color_discrete_sequence=custom_color[comp],
size="Total",
labels={xaxis: axis_labels[xaxis]},
title=f"Comparative Risk by Demographic",
)
return fig_style(fig)
そこで、まずDatabricksから結果を取得する関数を定義し、その結果をPlotly Expressが担当するチャート生成関数に渡します。
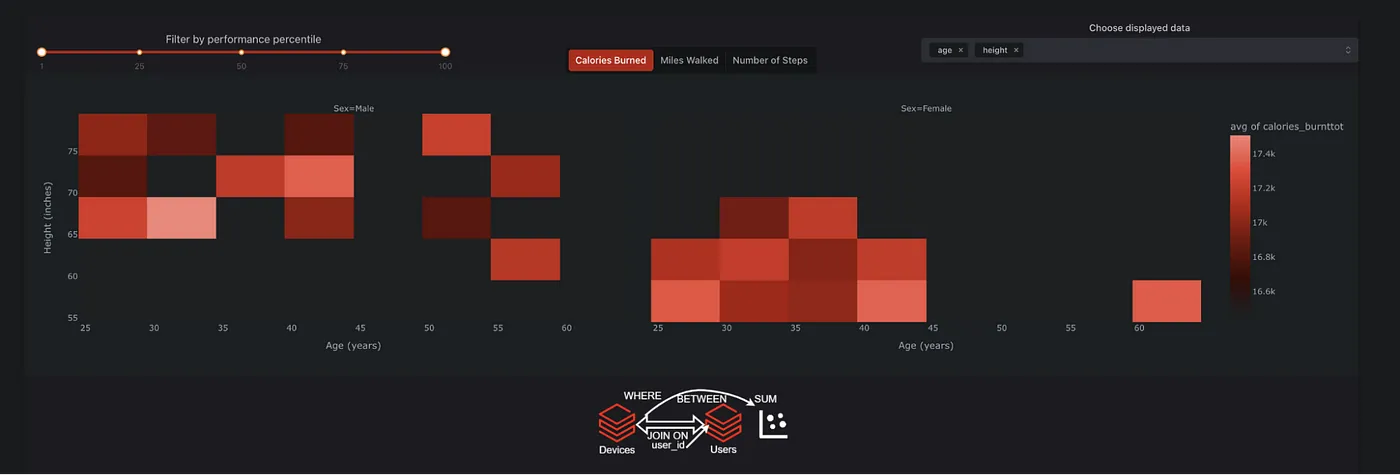
Real-time Apps
DatabricksSQL Data Lakehouseにリアルタイムでデータが流れている場合(Structured StreamingまたはDelta Live Tables経由)、Dashアプリが自動的に新しいデータをポーリングして、ダッシュボードを自動的に更新してリアルタイムのデータ変化に対応させることが容易にできます。Databricksの高効率なPhotonクエリーエンジンとPlotlyのdcc.intervalコンポーネントを組み合わせることで、非常に大きなデータセットでも無駄のない、きびきびとしたリアルタイムダッシュボードを作成することができます
Dashアプリをリアルタイムにするためには、アプリ内でdcc.intervalコンポーネントとコールバックを簡単に組み合わせ、あとはDatabricksに任せればよいのです。
Step 1 — Add dcc.interval component to app.layout
dcc.Interval(id="interval", interval=1_000),
Step 2 — Add callback trigger
@callback(Output("time", "children"), Input("interval", "n_intervals"))
def refresh_data_at_interval(interval_trigger):
"""
This simple callback demonstrates how to use the Interval component to update data at a regular interval.
This particular example updates time every second, however, you can subsitute this data query with any acquisition method your product requires.
"""
return dt.datetime.now().strftime("%M:%S")
Use Functions in Callbacks:
最後に、これらの関数をインタラクティブにするために、コールバック・デコレータで関数をラップし、アプリのapp.layout部分にあるDashコンポーネントに入出力を割り当てるだけです。上記の例では、動的な軸を持つデータの散布図を作成しました。以下は、すべての関数を結びつけ、UIに結びつけるコールバック関数です。
@app.callback(
Output ("demographics", "figure"),
Input("scatter-x", "value"),
Input ("comparison", "value"),
)
def make_scatter(xaxis, comp):
dfscatter = dbx_utils.get_scatter_data(xaxis, comp)
scatterfig = chart_utils.generate_scatter(dfscatter, xaxis, comp)
return scatterfig
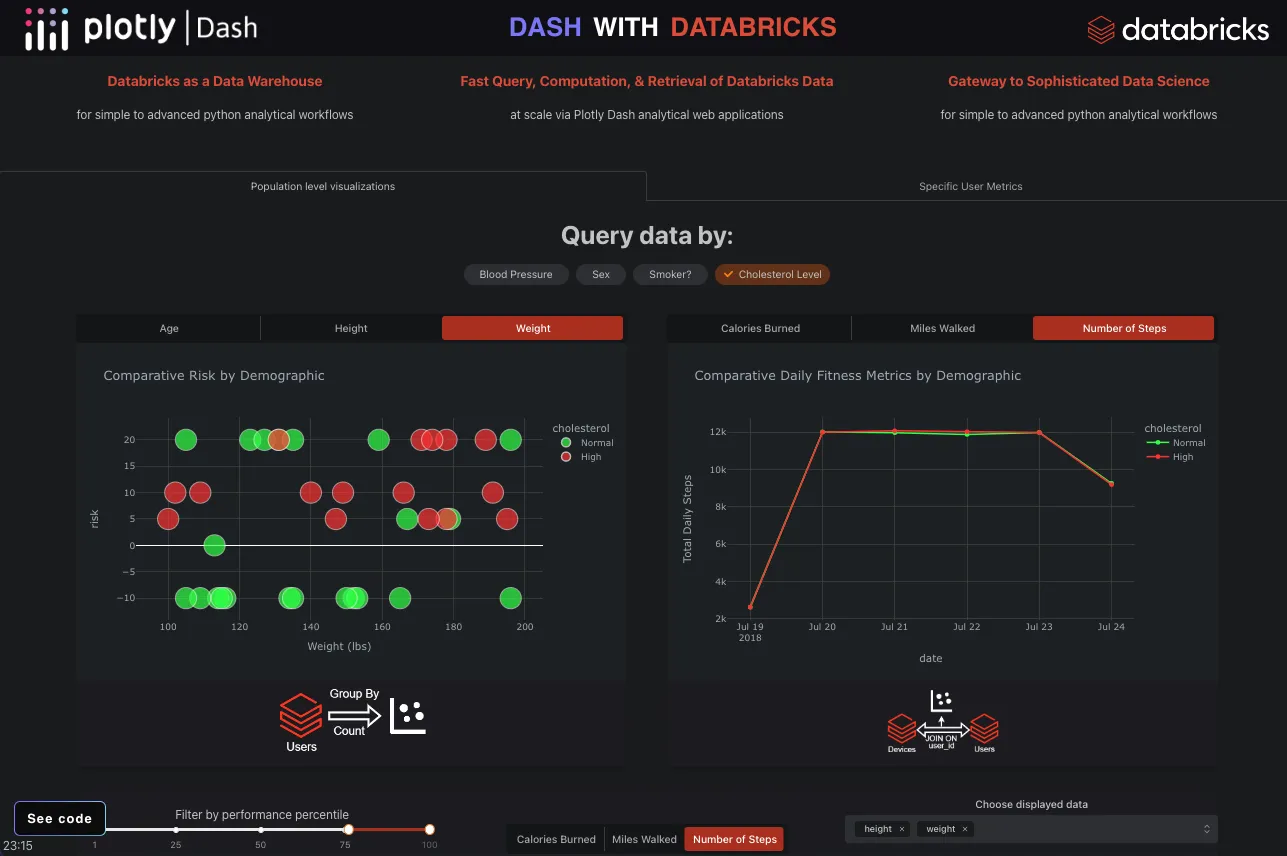
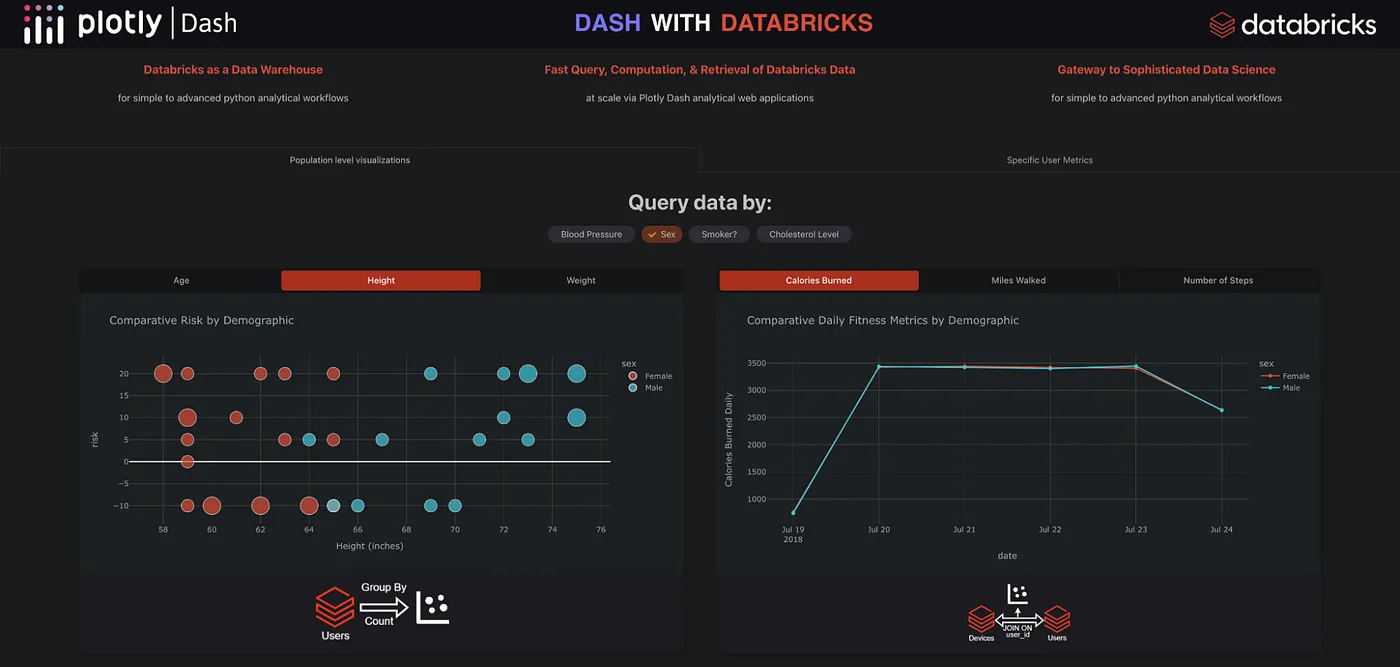
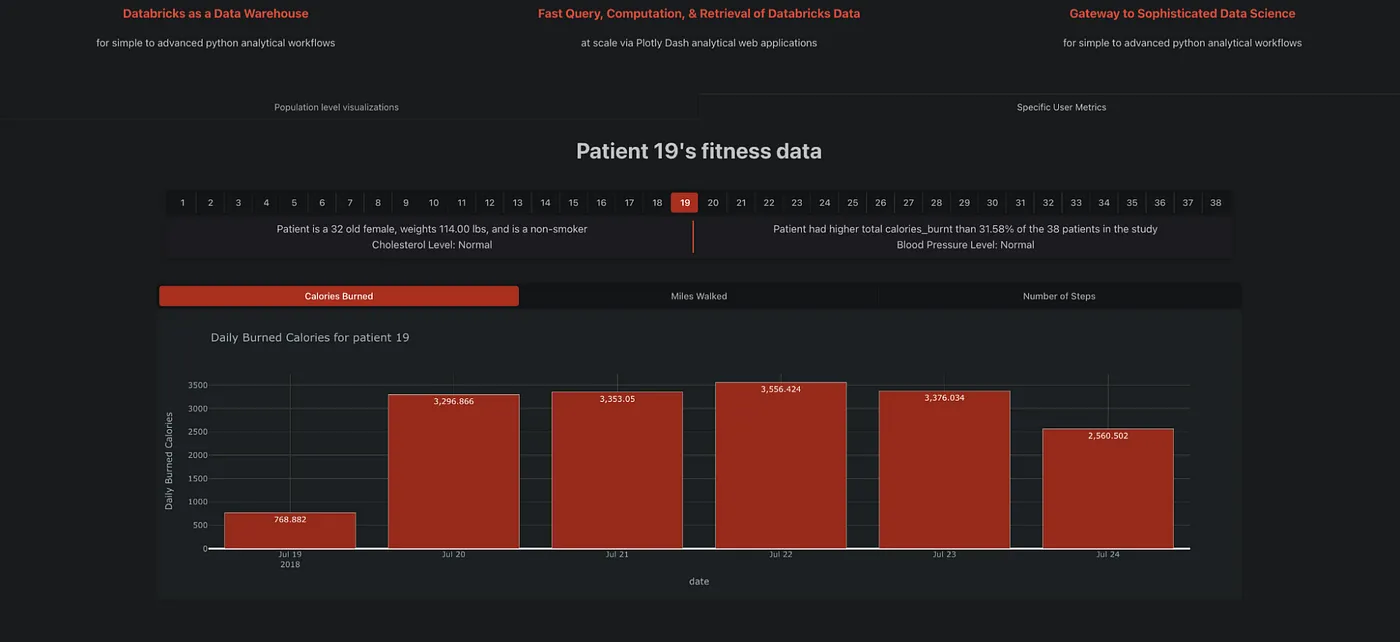
このコールバック関数は app.py にあり、scatter-x と comparison という Dash コンポーネントのフィルター/ボタンが変更されるのを待ちます。この例では、ユーザーはユーザーのコホートのリスクスコアを見て、独立変数との相関を特定することができます。以下の例では、体重とコレステロール値によるリスクスコアのユーザーのコホートの比較を示しています。
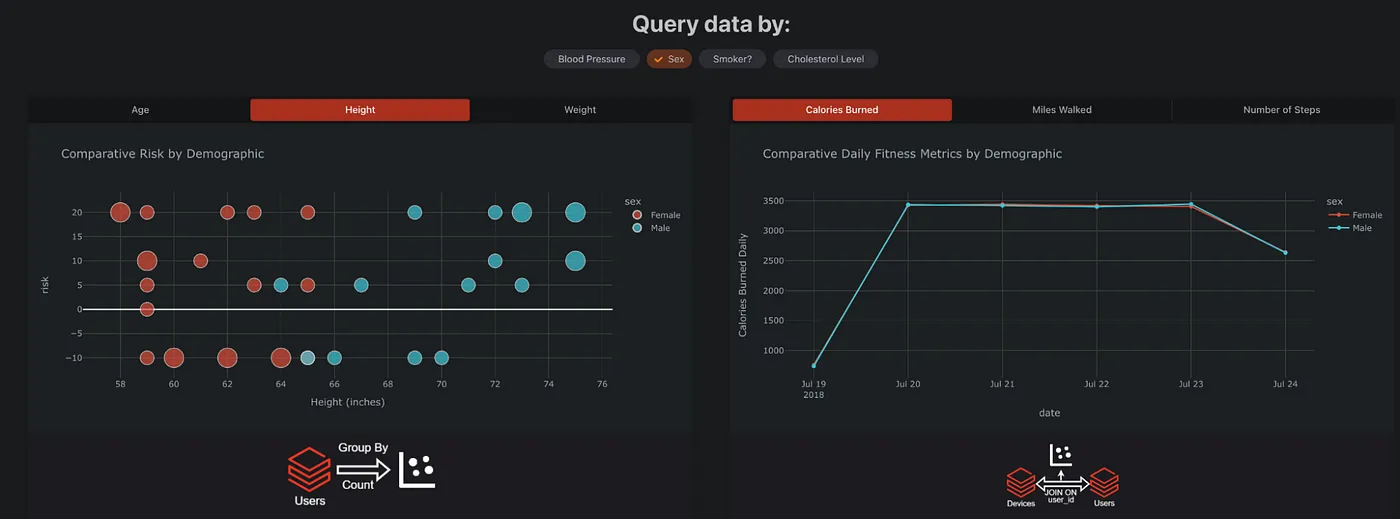
Run the App
これでようやく、すべてを結びつけることができます。ターミナルで python app.py を実行すると、ローカルサーバーが立ち上がり、完成したものを見ることができます。このバージョンのアプリは、あなたがコードを変更したときに自動的に更新されます。アプリに満足したら、デプロイして(例えばPlotlyのDash Enterpriseを使用して)ウェブ上の他の人に見てもらうことができます。
Next Step
Databricks Data + AI Summit 2022で私たちはこの話をいたしました。Plotly DashとDatabricksを活用することで可能性は無限に広がります。ではコメントでご意見をお聞かせください。ご質問は info@plotly.com にメールしてください