はじめに
将棋の棋譜データ(CSA)を分析するためのライブラリーなどいくつか公開されており、AI開発などにも活用されておりますが、棋譜データというのは膨大な量があり、分析するだけでもかなりの時間を要するかと思います。せっかくなのでSparkを使って分散処理したらどのくらい早くなるのか試してみました。
今回活用したデータ・ライブラリーについて
CSAデータとは?
異なる将棋ソフトの間で、棋譜や詰将棋・局面のデータ交換を可能とするために、棋譜ファイルの標準形式を規定したものです。そのままでは非常に読解が難しい内容となります。
http://www2.computer-shogi.org/protocol/record_v22.html
cshogiライブラリー
CSAデータをパースするために、今回はcshogiライブラリーを利用させていただきました。
cshogiは、盤面管理、合法手生成、指し手の検証、USIプロトコル、および機械学習向けフォーマットのサポートを備えた高速なPythonの将棋ライブラリです
https://github.com/TadaoYamaoka/cshogi
floodgateとは?
誰でも参加可能なコンピュータ将棋同士で対局させることができるオンライン上の対局所になります。対局した際の棋譜などが公開されており取得することができます。
http://wdoor.c.u-tokyo.ac.jp/shogi/floodgate.html
事前準備
- floodgateからCSAデータをダウンロードし、解凍後s3やblobストレージなどにアップロードしておきます。(今回は 2021年の棋譜データである wdoor2021.7z をダウンロードし解凍後、blobストレージにアップロードしております)
- 外部ストレージをDBFSにマウントしておきます。参考サイト
サンプルノートブック
今回利用したノートブックはこちらです。
データブリックス環境にインポートしてお使いいただけます。
CSAデータプロファイル情報
ノートブックを使って今回アップロードしたデータのプロファイルをチェックしてみます。
今回外部のblobストレージを /mnt/jmaru にマウントし、2020ディレクトリにCSAデータを保存しております。
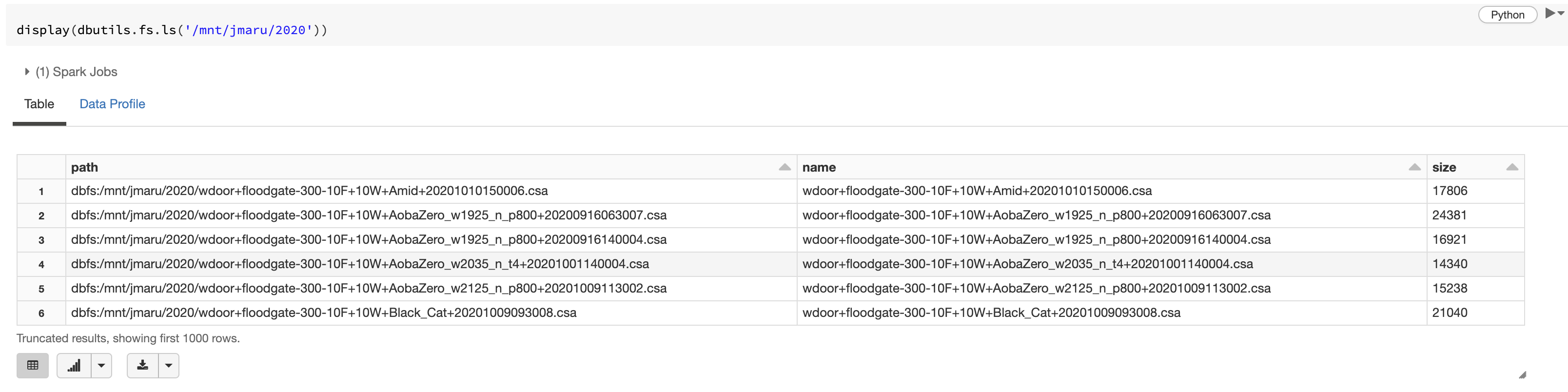
データブリックスのdisplay関数を利用すると簡単にデータプロファイル情報が確認できます。Data Profile__タブをクリックしてみると__139K のデータが存在しており、ファイルサイズの平均は__15.1KB__ というのがわかります。
まずは pandas dataframeでパースしてみる
まずは比較のため、pandasのdataframeとして作成し、cshogiライブラリーを使ってパースし情報を取得したいと思います。
from cshogi import CSA
kifu_list = glob.glob('/dbfs/mnt/jmaru/2020/*.csa')
endgame, rating, win,sfen,moves,scores,comments,names,comment,times = [],[],[],[],[],[],[],[],[],[]
for path in kifu_list:
for kif in CSA.Parser.parse_file(path):
names += [kif.names]
endgame += [kif.endgame]
rating += [kif.ratings]
win += [kif.win]
sfen += [kif.sfen]
moves += [kif.moves]
scores += [kif.scores]
comments += [kif.comments]
comment += [kif.comment]
times += [kif.times]
pdf = pd.DataFrame(list(zip(names,endgame,rating,win,sfen,moves,scores,comments,comment,times)),columns=['names','endgame','rating','win','sfen','moves','scores','comments','comment','times'])
pdf
結果としては、なんと 50分もかかってしまいました。
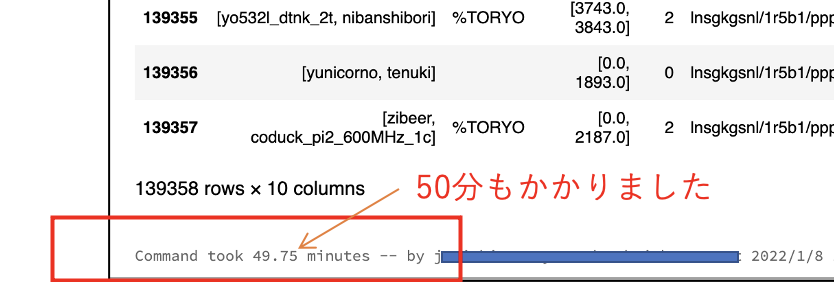
この後の処理も非常に遅く分析業務が全然進みません。。
それでは、Spark Dataframeとして読み込んでパースしてみます。
今回は2台スタートでMax8台までオートスケールするクラスター構成で実行しております。
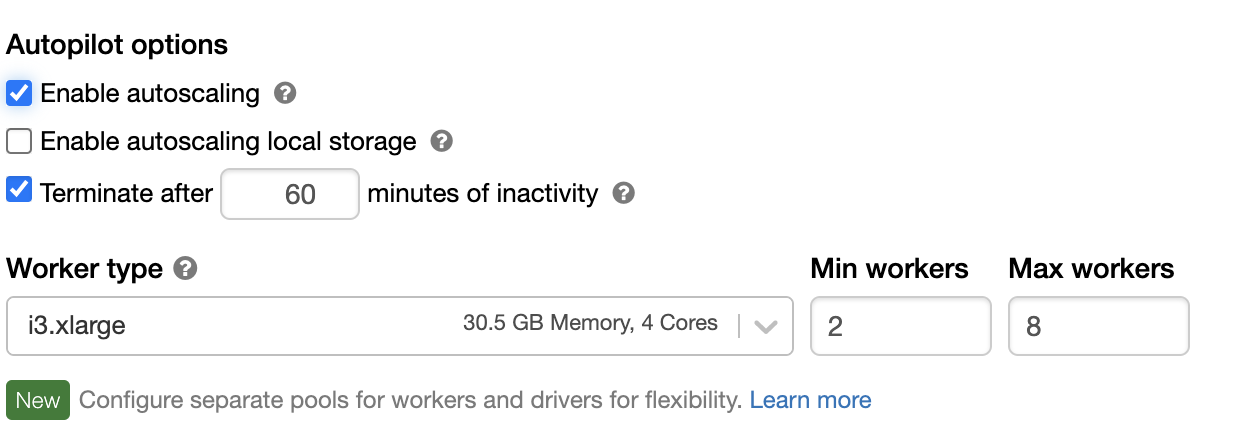
from pyspark.sql.functions import *
from pyspark.sql.types import *
from cshogi import CSA
# binary dataとして読み込み、file pathを取得する
df = spark.read.format('binaryFile').load('/mnt/jmaru/2020/*.csa')
# "dbfs:"" を "/dbfs/" に変換する。
df = df.withColumn('npath', regexp_replace(df['path'],("dbfs:"),'/dbfs'))
schemas = '''
names array<string>,
endgame string,
rating array<double>,
win long,
sfen string,
moves array<long>,
scores array<long>,
comments array<string>,
comment string,
times array<int>
'''
def ps(p: pd.Series)-> pd.DataFrame:
endgame, rating, win,sfen,moves,scores,comments,names,comment,times = [],[],[],[],[],[],[],[],[],[]
for path in p['npath']:
for kif in CSA.Parser.parse_file(path):
names += [kif.names]
endgame += [kif.endgame]
rating += [kif.ratings]
win += [kif.win]
sfen += [kif.sfen]
moves += [kif.moves]
scores += [kif.scores]
comments += [kif.comments]
comment += [kif.comment]
times += [kif.times]
pdf = pd.DataFrame(list(zip(names,endgame,rating,win,sfen,moves,scores,comments,comment,times)),columns=['names','endgame','rating','win','sfen','moves','scores','comments','comment','times'])
return pdf
df = df.groupby('npath').applyInPandas(ps, schema=schemas)
df
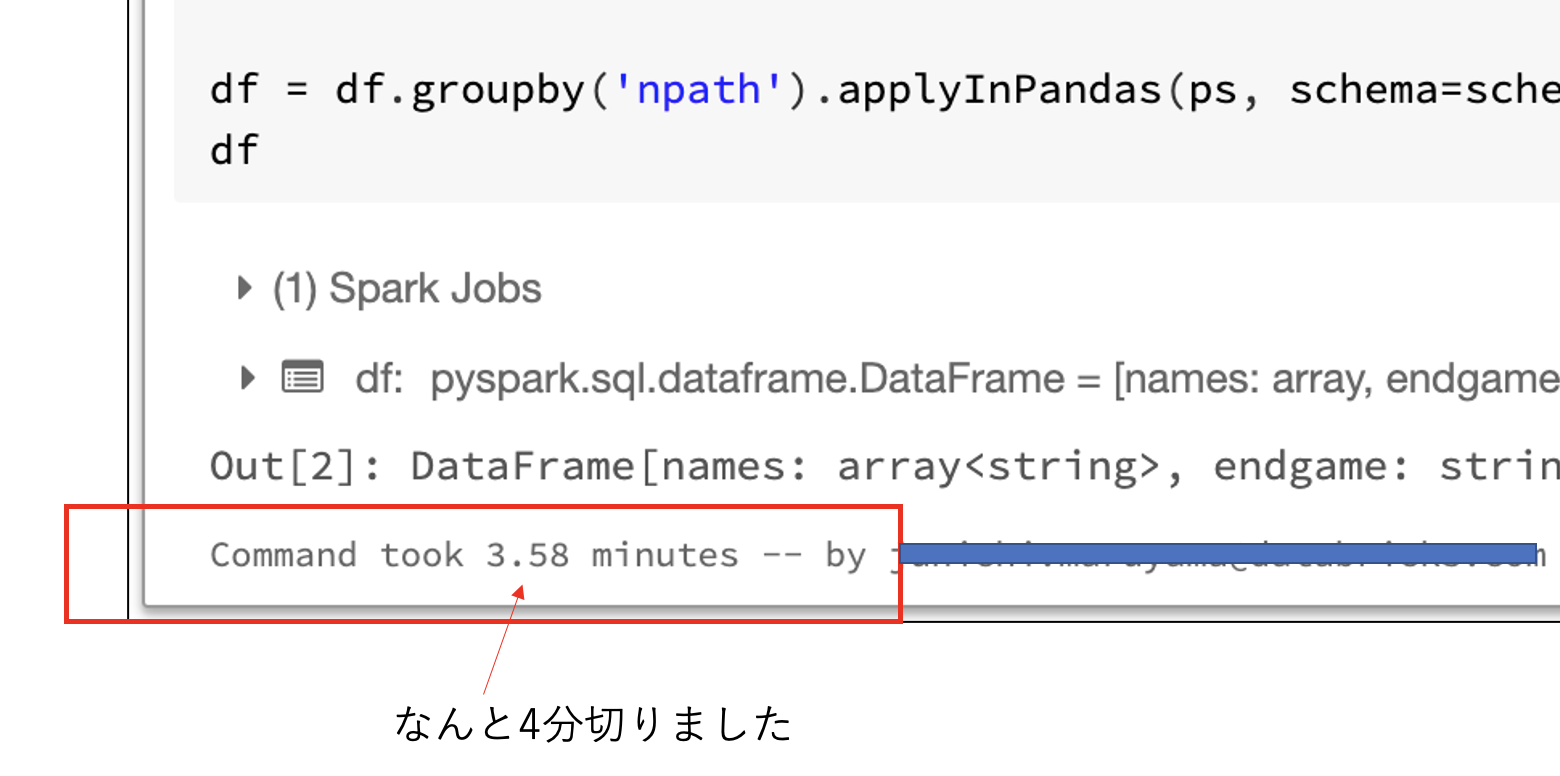
実行結果はなんと脅威の__4分__を切りました。 (pandasの12分の1) すご。
ちなみにClusterを再起動してpandasと同じ条件で実行しております。クラスターは最初2台からスタートしオートスケール時のインスタンス起動時間も含めておりますので、最初からインスタンス起動しておくともっと早く処理が完了します。
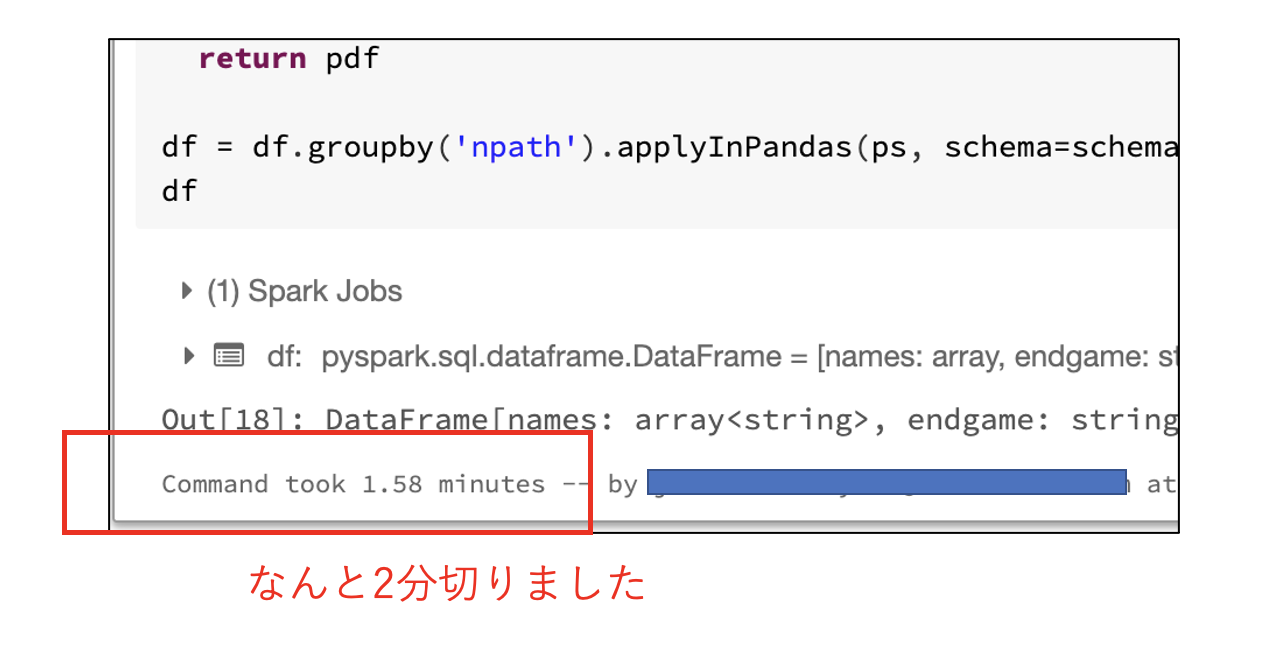
最初から8台起動した状態で同じ処理をしたら__2分__を切りました。
なんでこんなに早くなったのか?
Sparkの場合データ処理を複数のExecuterで分散処理させることが可能です。今回はデータのロード部分から複数サーバーで読み取り、その後の処理もそれぞれのサーバー上で分散処理することができました。ちなみに1台のサーバーでも複数コアに分散処理させることができるため、コア数が多いインスタンスではSparkを使う効果があります。(今回は4コアのサーバーを利用)
また今回パース処理部分をcshogi libraryを使っているため、その部分はSpark DataFrameでは扱えないのですが、ここで登場するのが__pandas_udf__です。これは従来のUDFと違いSparkとUDF部分のやりとりにデータフレームを利用できます。そのため従来のシリアル処理ではなく、dataframe単位でUDF側に引き渡すことが可能です。しかも複数サーバーに分散させることができるのです。
ディスパッチする単位はgroupbyで指定したグループ毎になります。今回は npathということで、1ファイル毎にディスパッチしたことになります。
そのため、データの読み込み処理からデータフレームとしてのETL処理、パース処理をうまく分散処理できたため非常に処理時間を短縮することができました。
さらに高速化してみる
このままでも pandas dataframeに比べると十分早いのですが、それでもdataframeを扱うたびに数分かかってしまっては作業に影響がでます。ここで更に高速化させるためにDelta Lakeとして保存し読み込みます。
Delta Lakeとはオープンソースのストレージレイヤーソフトで、従来のデータレイクに保存されるデータが持つ欠点(ACID特性ない、DML処理ができない、監査ログがない、遅い)などを補いDWH並みの信頼性と高速性を併せ持つことが出来るようになります。データ自体は従来通りblob storageなどのオブジェクトストレージ上に保存できます。また高速化処理の一つにsmall fileをまとめて大きなファイルとして最適化してくれる機能やキャッシング機能などがあります。これらの機能を追加コスト無しで利用できてしまうのです。
import os.path
# directory作成(パスを変更ください)
table_path = '/mnt/jmaru/shogi_raw_delta'
# delta lakeとして保存
(df.write
.mode('overwrite')
.save(table_path)
)
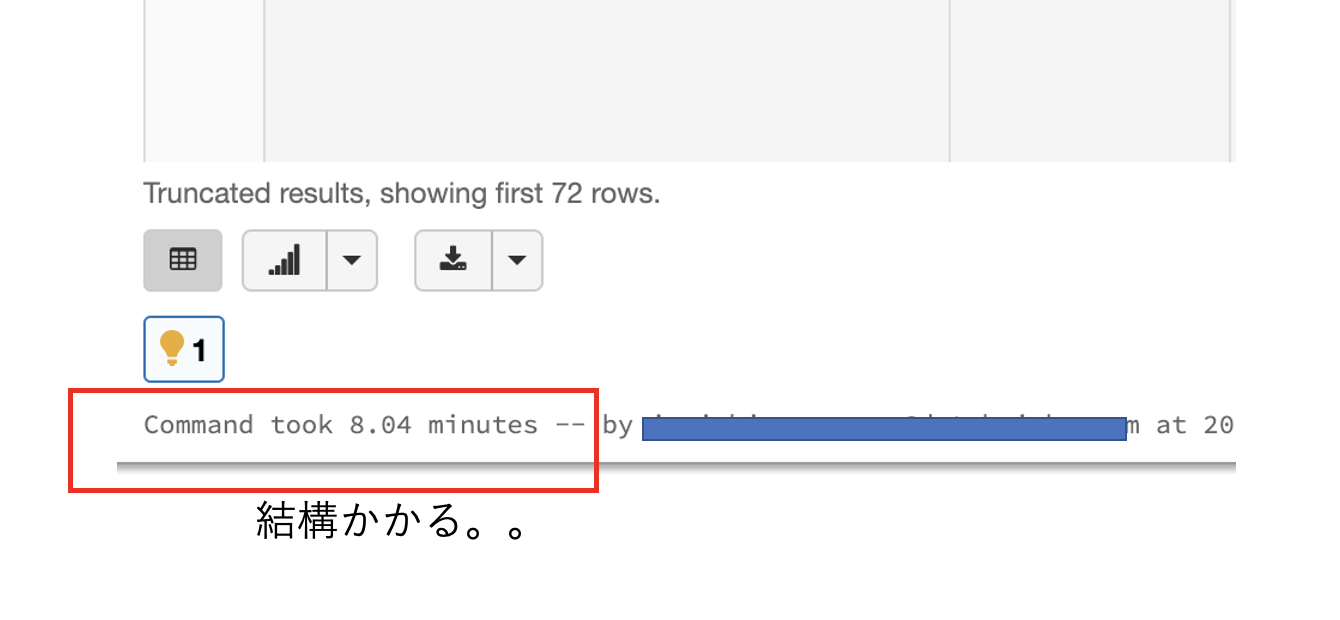
delta lakeからデータを読み込んで表示してみると、なんと__2秒__で表示できました。これでサクサクこのあとの作業ができます。しかもデータを保存しているストレージは安価なblobストレージのままです。(個人的な環境の問題で、AWSからAzure Blobストレージを利用しております)
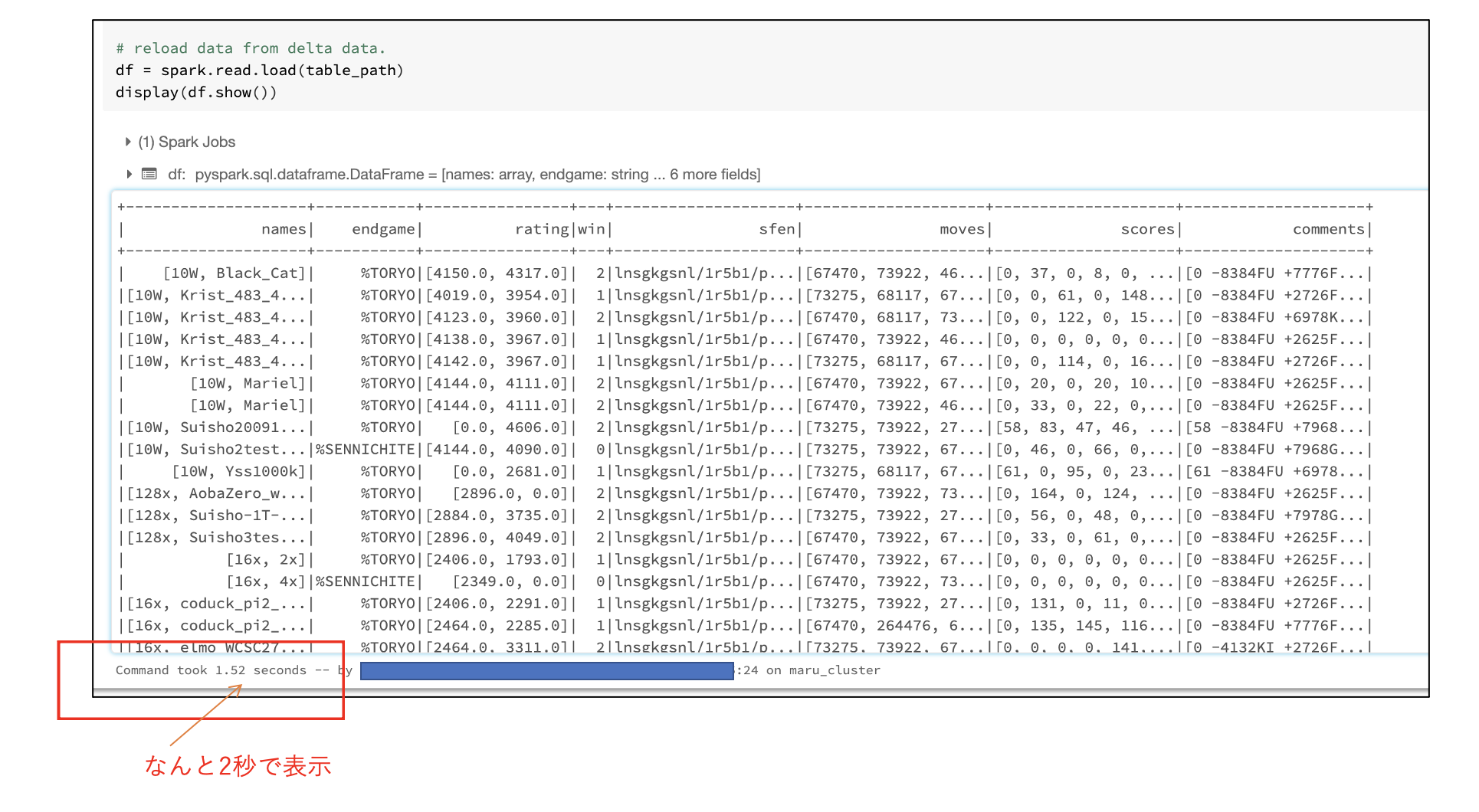
ちなみに、Dleta Lakeを利用せず、そのまま同じdisplay関数を使うとなんと__8分__もかかってしまいました。これは再度パース処理からスタートしてしまうからという理由もありますがDelta Lakeの高速化処理が有効に機能している証拠でしょう。
データ分析をしてみる
それではめちゃくちゃ早くなったので、データを加工して分析してみたいと思います。
データ加工&テーブル作成
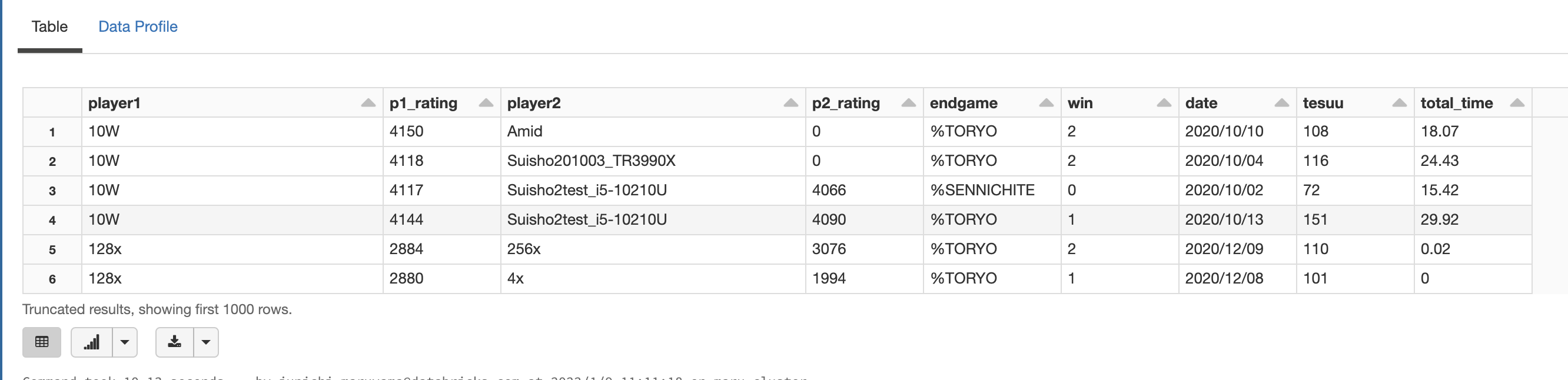
まずは分析しやすいように、さらにデータを抽出・加工し,SQLで分析できるように**テーブル(shogi_tbl)**を作成しておきます。
# 追加のパース処理
df1 = ((df.withColumn('player1', element_at(df.names,1))
.withColumn('player2', element_at(df.names,2))
.withColumn('p1_rating', element_at(df.rating,1))
.withColumn('p2_rating', element_at(df.rating,2))
.withColumn('endtime', regexp_extract(df.comment, r'END_TIME:(.*)', 1))
.withColumn('tesuu', size(df.moves))
.withColumn('total_time', expr('AGGREGATE(times, 0, (acc, x) -> acc + x)')/60)
.withColumn('time', to_timestamp('endtime', 'yyyy/MM/dd HH:mm:ss'))
.withColumn('date', date_format('time', 'yyyy/MM/dd'))
)
.select('player1','p1_rating','player2','p2_rating','endgame','win','date','tesuu',round('total_time',2).alias('total_time'))
)
# Delta Tableを作成 (shogi_tbl)
df1.write.mode('overwrite').saveAsTable("shogi_tbl")
display(spark.sql('select * from shogi_tbl'))
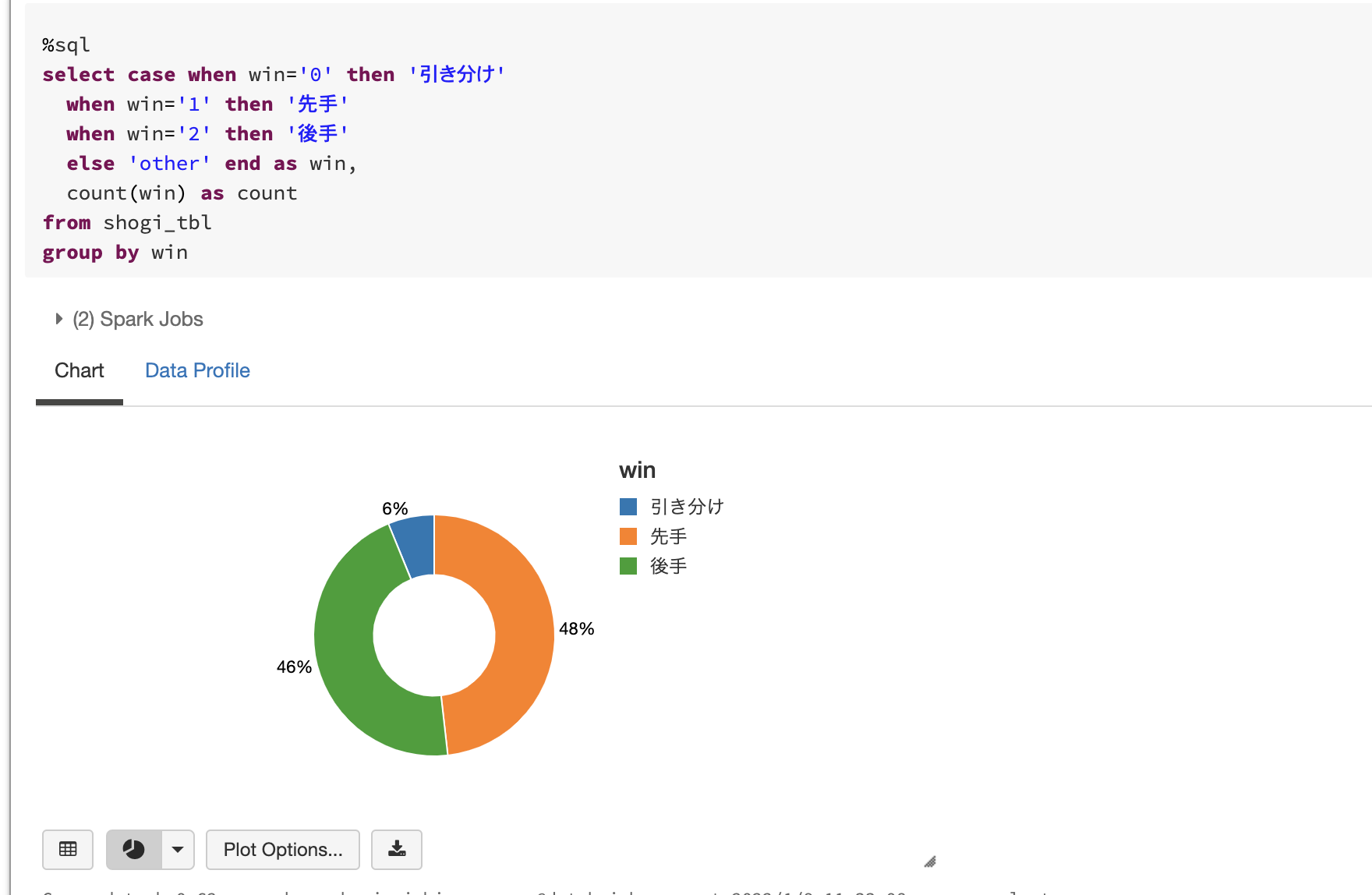
先手・後手の勝敗数分析
若干、先手の方が有利そうに見えます。
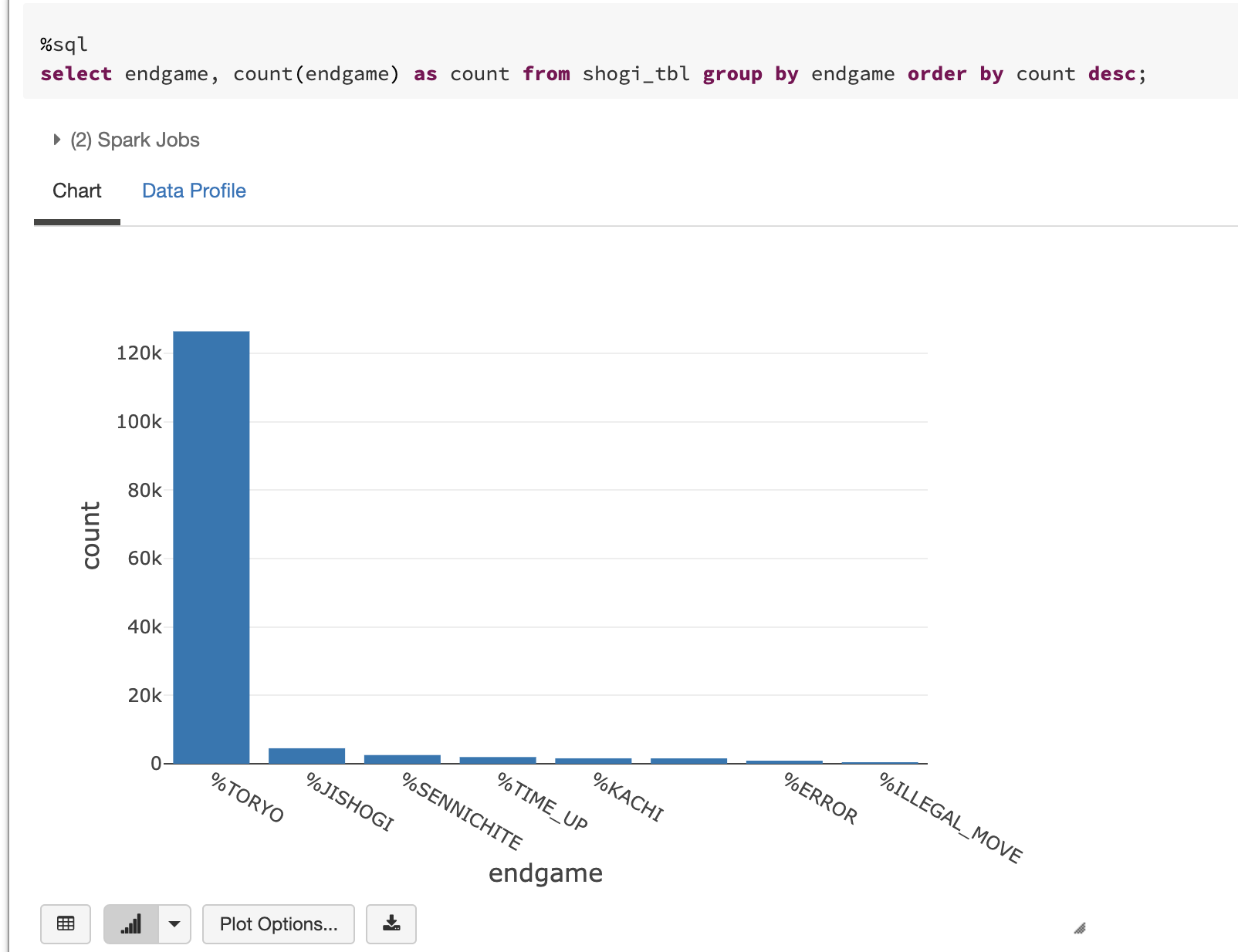
ゲーム終了の理由
圧倒的に投了。まで進んでおりますが、持将棋、千日手が続いての理由になってます。
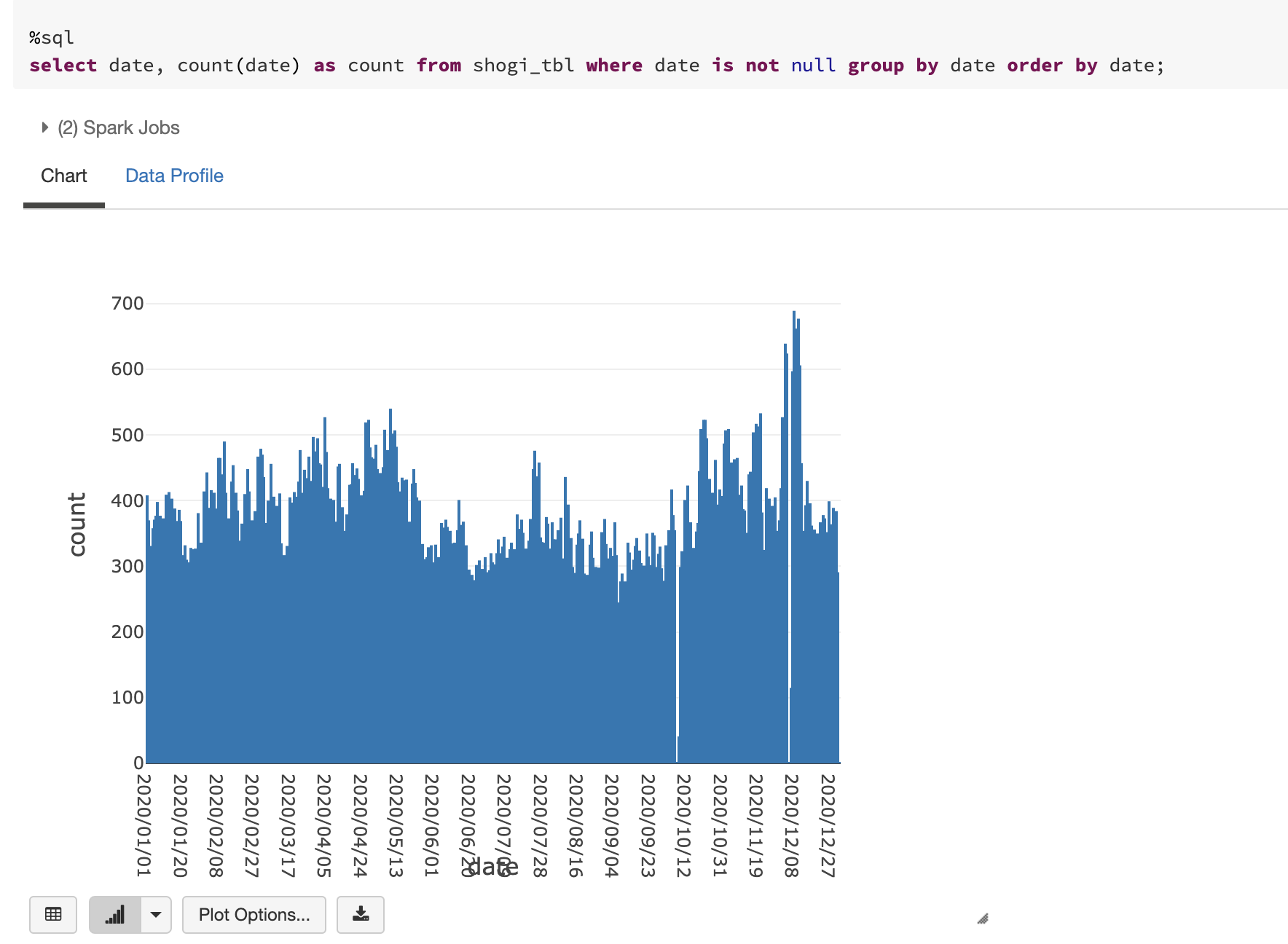
時系列に対局数をカウント
12月頭のあたりがピークになっており、9月あたりが比較的少ないようです。原因はなにかあるのかな?
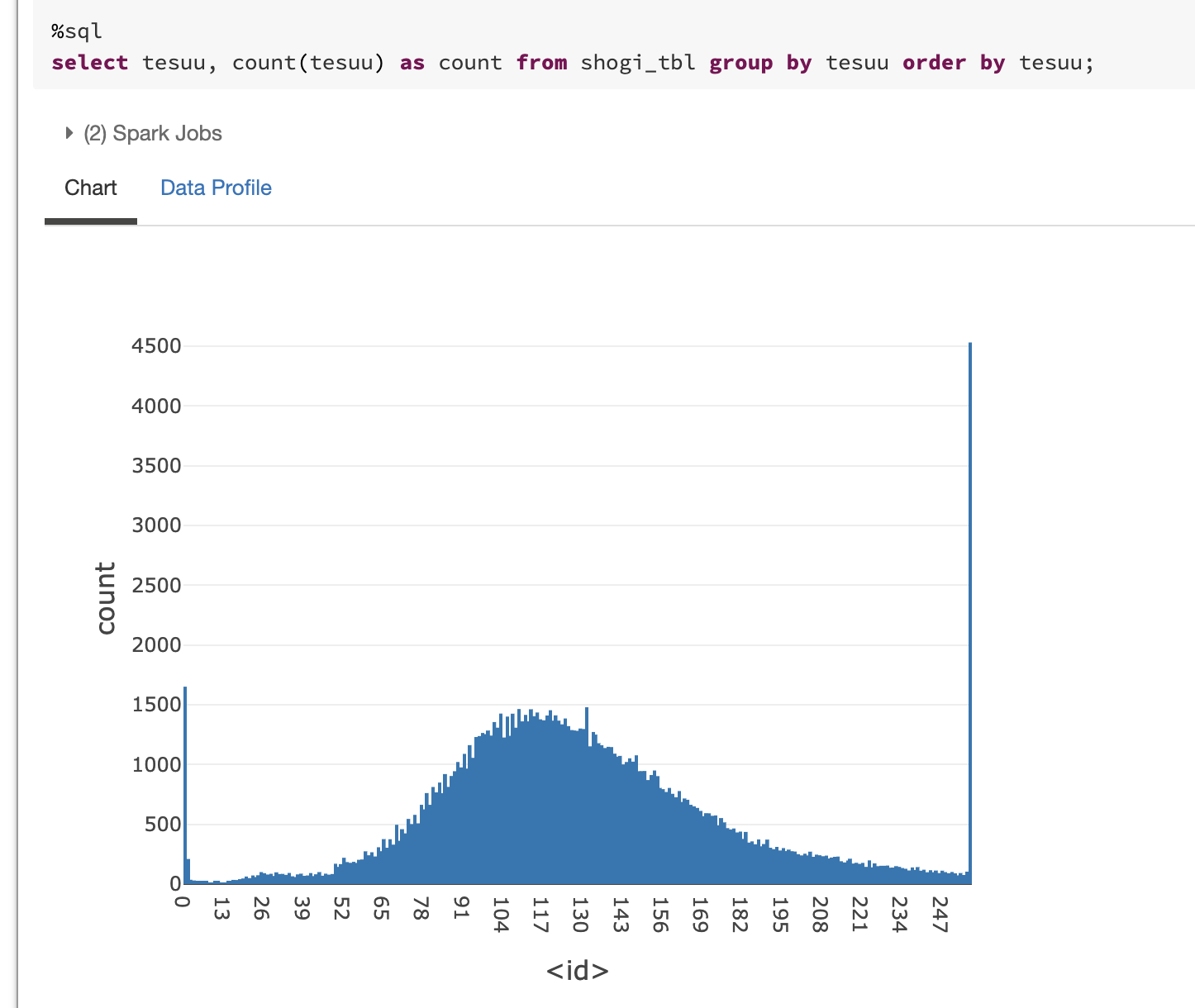
手数の分布図
256手が最大と設定されているため、256手で切れている対局数が大きくなっておりますが、110手あたりが最頻値のようにみえます。
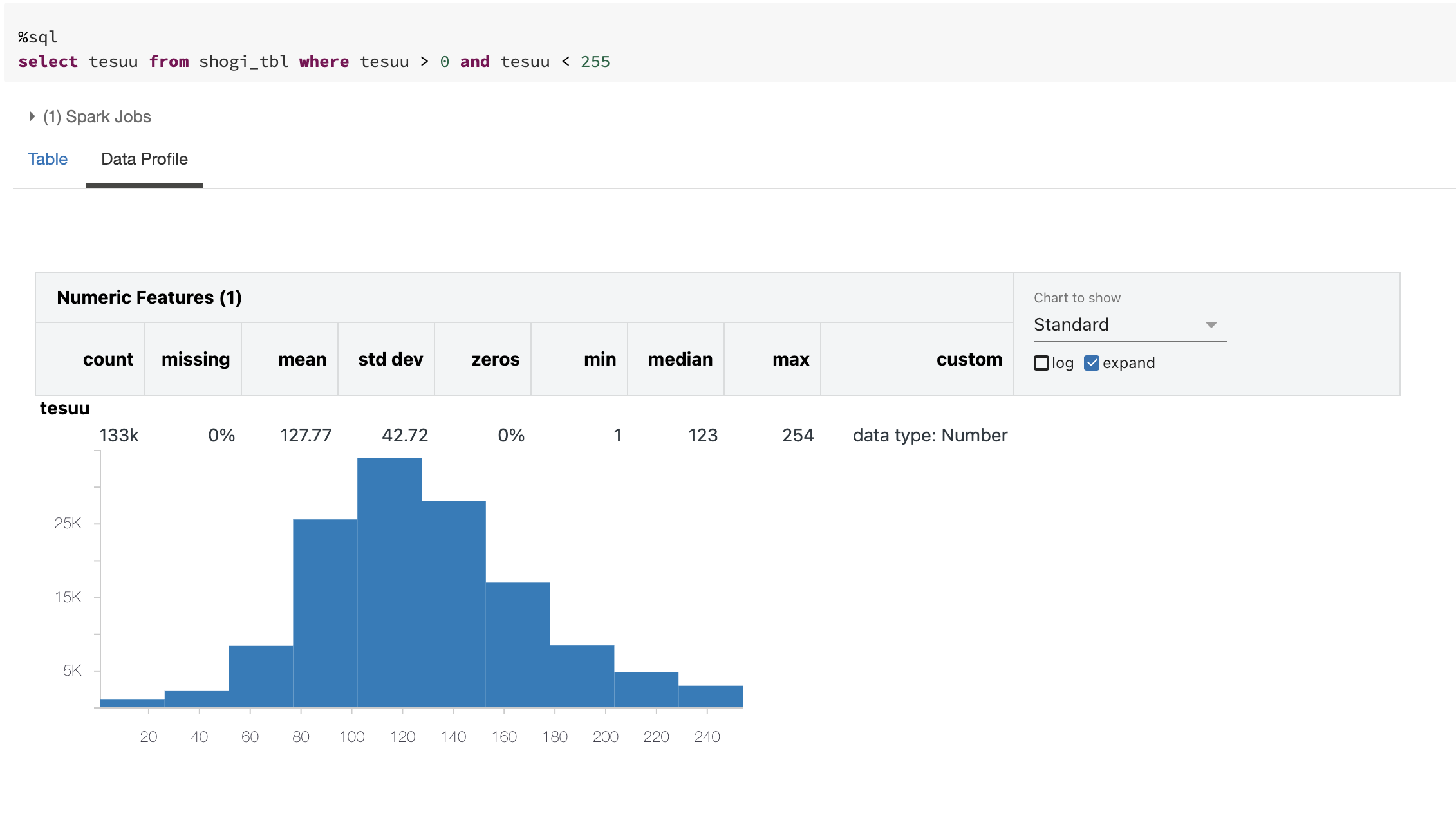
データプロファイル機能を使って、0手と255手を除いた基本データを確認してみます。平均127手、標準偏差42,中央値123手のようです。
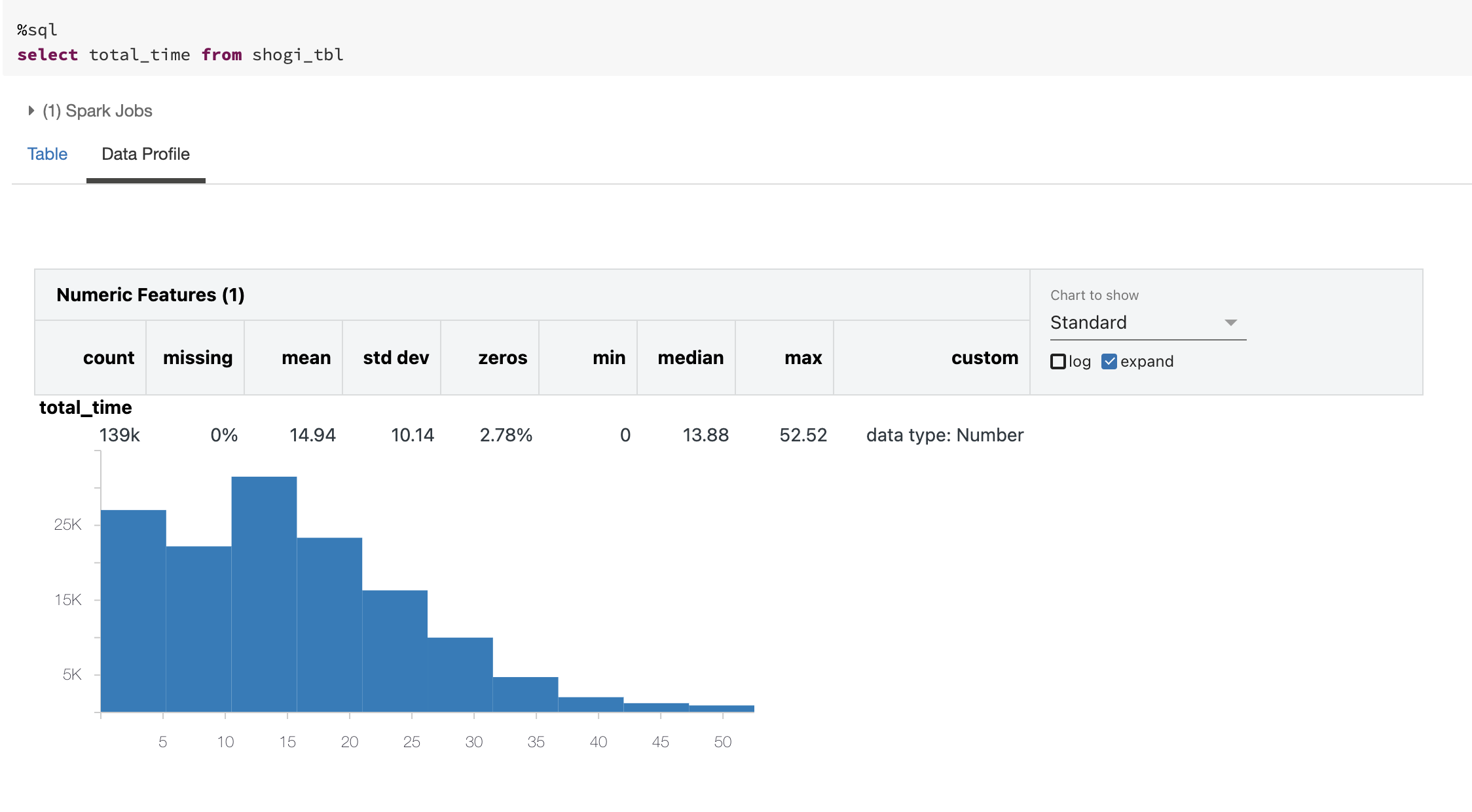
対局時間
同様に対局時間についてもデータプロファイルで確認してみると平均15分で、最大52分というのもあります。
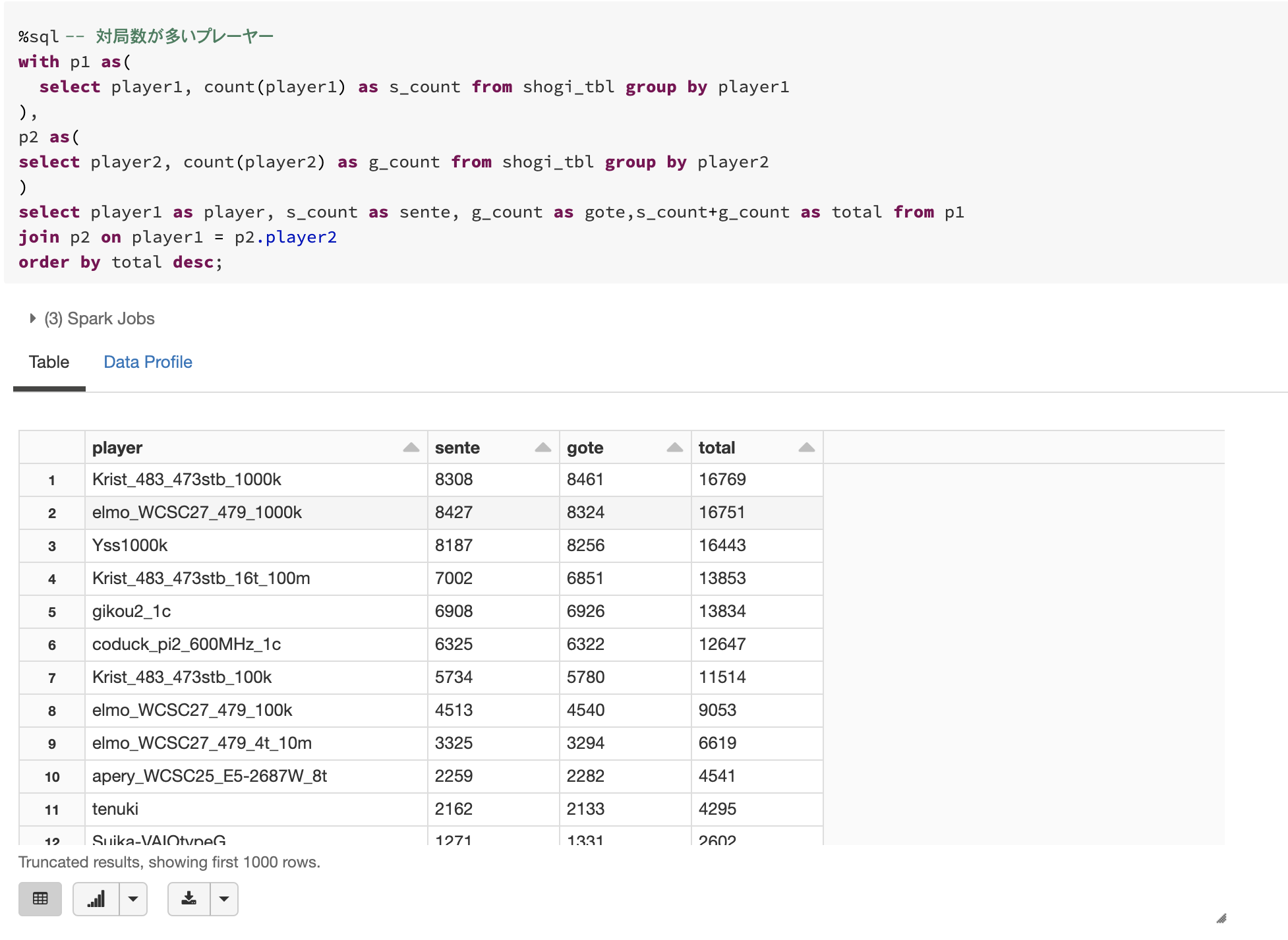
対局数の多いプレーヤー
どのプレーヤーが対局数が多いかチェックしてみます。Krist_483_472stb_1000kさんが、なんと__16769局__も指しておりトップでした。
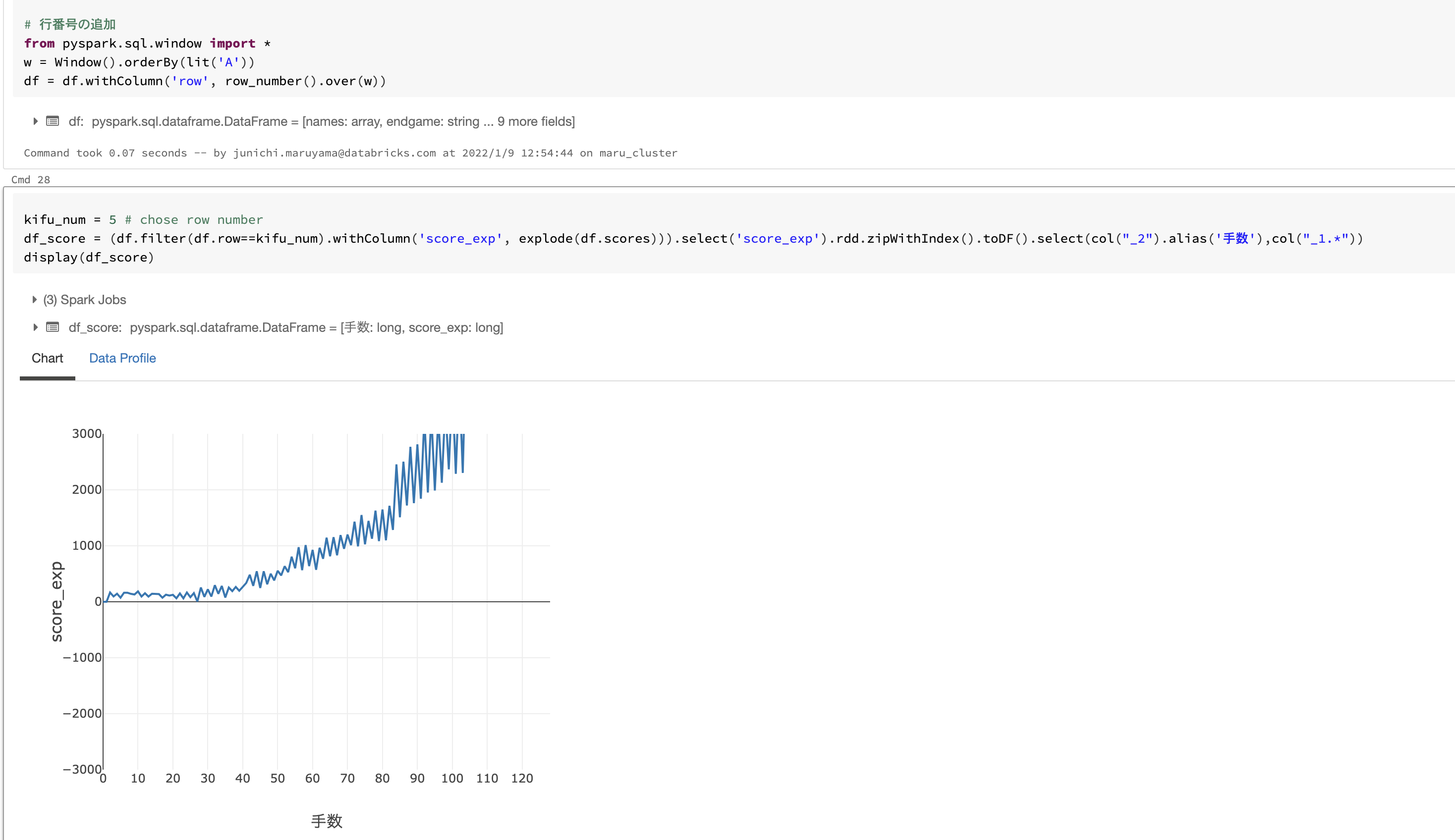
対局時のスコア推移位
scoreデータもあったため、データを指定するとスコア推移が確認できるようにしてみました。
まとめ
今回は2020年データ(約14万件)のみ利用しましたが、どの分析も数秒で表示できましたので、もっと多くのデータでも問題なく分析できそうです。また他にももっと深い考察ができるかと思いますので、今後じっくりチェックしてみたいと思います。
サンプルノートブックも公開しておりますので、是非Spark&DeltaLakeを使った高速分析をお試しください。