最近実務でPythonを使ってWebスクレイピングしたので
そこで得た知見をまとめてみます。
バージョンはPython3.7を使用します。
サンプルコードはWindowsかMacのどちらかであれば動作する想定です。
Webスクレイピングの手法に関して
Seleniumを使ってブラウザを自動操作して行う手法と
Beautiful Soupというライブラリを使用して行う手法があります。
今回はSeleniumを使った手法を紹介します。
Seleniumを使うパターン
今回の例では、こちらの性格診断サイトを題材に、
ローカルにある3人のデータを診断してみようと思います。
データはこちらから
対象サイトの調査
診断サイトを見てみると、
- 問題が1ページあたり6問ある。
- 次へボタンを押すと次のページへ
- 全部で10ページ、60問ある。
のがわかると思います。
また、診断サイトの選択肢を開発者ツールで見てみると
以下のような感じになっていると思います。
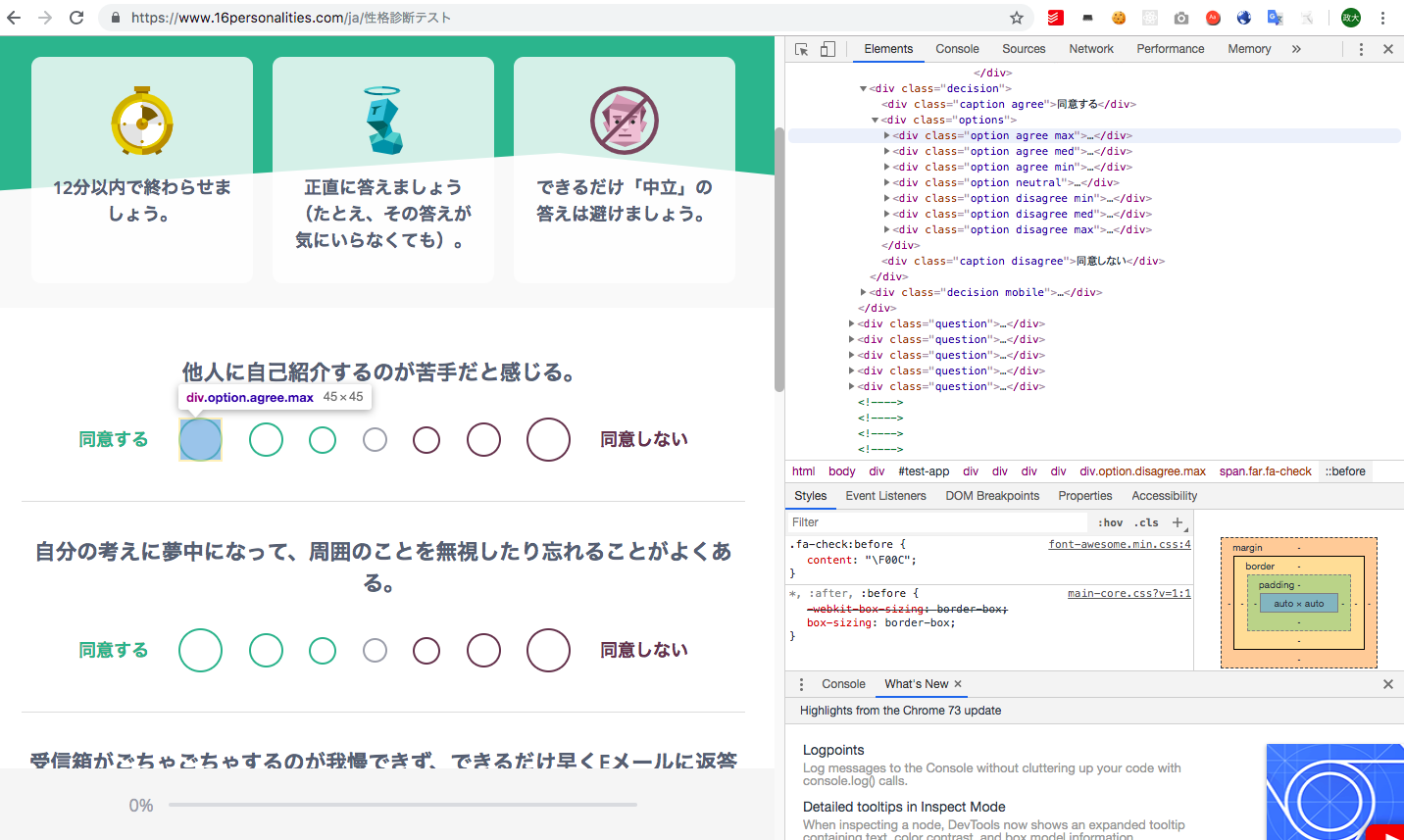
- 1問あたり選択肢は7つある。
- 選択肢の左から、「agree max」、「agree med」、「agree min」、「neutral」、「disagree min」、「disagree med」、「disagree max」というクラスが設定されている。
- 選択肢1行に対してそれぞれdecisionクラスが設定されている。また、decisionとmobileクラスが設定されているものが非表示で存在している。
次へボタンをどんどん押していき、結果画面を見てみると
以下のようになっていると思います。
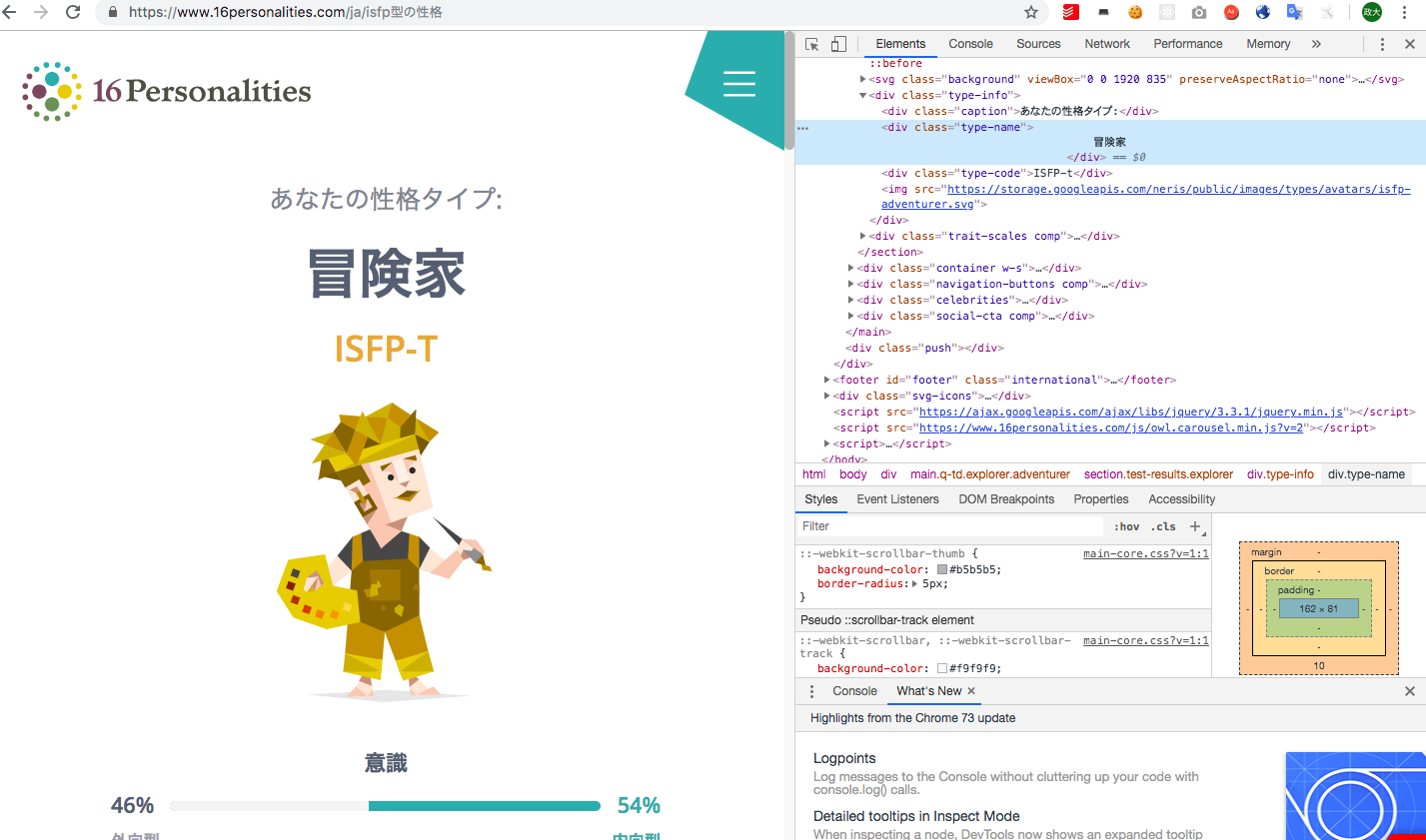
- 「type-name」というクラスが設定されている部分に性格タイプ名が表示されている。
- 「type-code」というクラスが設定されている部分にタイプコードが表示されている。
サンプルデータについて
- 一つのcsvファイルにつき、一人分のデータが設定されている。
- データの数値は以下のように対応している。
| データ | クラス名 |
|---|---|
| 3 | agree max |
| 2 | agree med |
| 1 | agree min |
| 0 | neutral |
| -1 | disagree min |
| -2 | disagree med |
| -3 | disagree max |
今回はサンプルデータをもとに選択肢を選んでいき、
最終的に結果画面の性格タイプ名とタイプコードを取得しようと思います。
準備
使用したいブラウザに合わせたdriverをダウンロードする必要があります。
今回の例ではChromeを使用しますので、以下のサイトから環境にあったものをダウンロードしてください。
http://chromedriver.storage.googleapis.com/index.html
.
├── chromedriver // ドライバーはプログラムと同じ階層に配置する
├── chromedriver.exe
├── data // サンプルcsvデータはここに格納する
│ ├── John.csv
│ ├── Kate.csv
│ └── Mike.csv
└── selenium_sample.py // 今回作成するプログラム
また、seleniumのモジュールがない場合はseleniumをpip installしてください。
pip install selenium
実装
まずはコード全体を載せておきます。
import glob
import os
import os.path
import time
from selenium import webdriver
# アクセスするURL
TARGET_URL = "https://www.16personalities.com/ja/%E6%80%A7%E6%A0%BC%E8%A8%BA%E6%96%AD%E3%83%86%E3%82%B9%E3%83%88"
# Seleniumで要素を取得するためにCSSセレクタで指定するときと同じ文字列を宣言しておく
DECISION_MAP = {
3 : ".agree.max",
2 : ".agree.med",
1 : ".agree.min",
0 : ".neutral",
-1 : ".disagree.min",
-2 : ".disagree.med",
-3 : ".disagree.max",
}
# WindownsとMacでドライバーが違うのでそれぞれ定義しておく
DRIVER_WIN = "chromedriver.exe"
DRIVER_MAC = "./chromedriver"
# 各動作間の待ち時間(秒)
INTERVAL = 3
# ブラウザ起動
driver_path = DRIVER_WIN if os.name == "nt" else DRIVER_MAC
driver = webdriver.Chrome(executable_path=driver_path)
driver.maximize_window()
time.sleep(INTERVAL)
# ファイル名の配列取得
data_list = glob.glob("data/*.csv")
for csv_file in data_list:
# 対象サイトへアクセス
driver.get(TARGET_URL)
time.sleep(INTERVAL)
# ファイルを開く
with open(csv_file) as f:
# 一行ずつの値のリストにする −3~3までの整数のリスト
lines = [int(line.strip()) for line in f.readlines()]
# 1ページ6問ずつなので6こずつループする
for i in range(0, len(lines), 6):
# 選択行を取得する
decisions = driver.find_elements_by_css_selector(".decision:not(.mobile)")
for j in range(i, i + 6):
# DECISION_MAP[lines[j]] -> lines[j]が-3~3のどれかの値なのでその値をキーに .agree.maxなどの値を取得
decisions[j % 6].find_element_by_css_selector(DECISION_MAP[lines[j]]).click()
time.sleep(INTERVAL)
# 6問入力したらボタンを押下する
driver.find_element_by_tag_name("button").click()
time.sleep(INTERVAL)
# 結果画面のデータを取得
type_name = driver.find_element_by_class_name("type-name").text
type_code = driver.find_element_by_class_name("type-code").text
url = driver.current_url
# ファイル名から診断対象の人の名前を取得
file_name = os.path.basename(csv_file)
person, ext = os.path.splitext(file_name)
print(f"{person}さんの性格タイプは{type_name}(タイプコード:{type_code})です。\n 詳細:{url}")
time.sleep(INTERVAL)
# ブラウザを閉じる
driver.quit()
Johnさんの性格タイプは建築家(タイプコード:INTJ-A)です。
詳細:https://www.16personalities.com/ja/intj%E5%9E%8B%E3%81%AE%E6%80%A7%E6%A0%BC
Kateさんの性格タイプは擁護者(タイプコード:ISFJ-T)です。
詳細:https://www.16personalities.com/ja/isfj%E5%9E%8B%E3%81%AE%E6%80%A7%E6%A0%BC
Mikeさんの性格タイプはエンターテイナー(タイプコード:ESFP-T)です。
詳細:https://www.16personalities.com/ja/esfp%E5%9E%8B%E3%81%AE%E6%80%A7%E6%A0%BC
Seleniumの使い方
webdriverをインポートし、webdriver.Chrome(executable_path="ドライバのパス")とすることで
ブラウザが立ち上がり、Chromeインスタンスが返ります。
ここで作成されたChromeインスタンス(ここではdriver)を使って色々操作していきます。
# Windowsで実行した場合はDRIVER_WIN, Macで実行した場合はDRIVER_MACの値がdriver_pathに入る
driver_path = DRIVER_WIN if os.name == "nt" else DRIVER_MAC
driver = webdriver.Chrome(executable_path=driver_path)
Webページへのアクセス
driver.get(URL)とすることで、指定したURLへアクセスできます。
driver.get(TARGET_URL)
要素の取得
driver.find_element_by_◯◯とすることで、要素を取得できます。
driver.find_elements_by_◯◯とすることで、要素のリストを取得できます。
また、複数要素が取得できる状態でdriver.find_element_by_◯◯を実行すると
一番最初の要素だけが取得できます。
| メソッド名 | 取得方法 |
|---|---|
| find_element_by_tag_name | タグ名 |
| find_element_by_class_name | クラス名 |
| find_element_by_id | ID |
| find_element_by_css_selector | CSSセレクター |
| find_element_by_name | Name属性 |
個人的にはfind_element_by_css_selectorを使うことが多いですが
指定の仕方が他にもたくさんあって使い分けられると便利だと思います。
以下のサイトがとてもわかりやすいのでおすすめです。
https://kurozumi.github.io/selenium-python/locating-elements.html
また、取得した要素からもfind_element_by_〇〇が使えるので
そこから子要素を取得したりもできます。
for i in range(0, len(lines), 6):
# 選択行を取得する .decisionが付いているものの中で.mobileが付いていないものを取得
decisions = driver.find_elements_by_css_selector(".decision:not(.mobile)")
for j in range(i, i + 6):
# 取得した要素からfindを使っている
decisions[j % 6].find_element_by_css_selector(DECISION_MAP[lines[j]]).click()
time.sleep(INTERVAL)
# 6問入力したらボタンを押下する
driver.find_element_by_tag_name("button").click()
time.sleep(INTERVAL)
クリック
取得要素.click()でその要素をクリックします。
テキスト取得
取得要素.textでタグ内のテキストを取得できます。
Seleniumの使い所
個人的にはSeleniumを使用するパターンは
今回のサイトのように、JavaScript等で
画面内の要素が動的に変化する場合に強いのかなと考えています。
一方でクライアントのスペックが低い等でブラウザでの描画が遅れたりすると
待ち時間の制御が難しいかもしれないです。
今回は簡単なのでtime.sleep()を使用しましたが、本来はSeleniumのWaitなどで制御できた方が良さそうですね。
Beautiful Soupを使用した手法もどこかで紹介できればと思います。