仕事でCloud DataFlowを使った際に、ざっくり調べた入門的なまとめ。
データ処理畑の有識者ではないので、なにか記載に誤りなど
あれば学びになるので教えていただけたら :)
Cloud DataFlowって?
GoogleCloudPlatformが提供するストリーム/バッチ方式でのデータ処理エンジン(Apache Beam)のフルマネージドサービスです。
と書くとなんのこっちゃ?って感じなので
大雑把に要素分解をすると
- ストリームデータ処理対応(ストリームデータについては後述)
- 任意のinput(pubsubやmysql,gcs)から得たデータの変換、GCS,BigQueryへのデータ流し込みをコードで書いてdeployするだけで実現できます。
- Cloud/PubSubとの連携が容易。(beamSDKの呼び出しを1〜3行書くだけ)
- Java,PythonのSDKが提供されています。
という感じ (*) 2018/02時点ではストリーム対応はJavaのみ
同じGCPのサービスであるCloud Pub/Subをメッセージバスとして利用し、
CloudIoTCore(MQTT ProtocolBridge),GCSやBigQueryといったデータストアと組み合わせる事で、例えば端末からのデータ送信の受け口・変換・集積を行う事ができます。
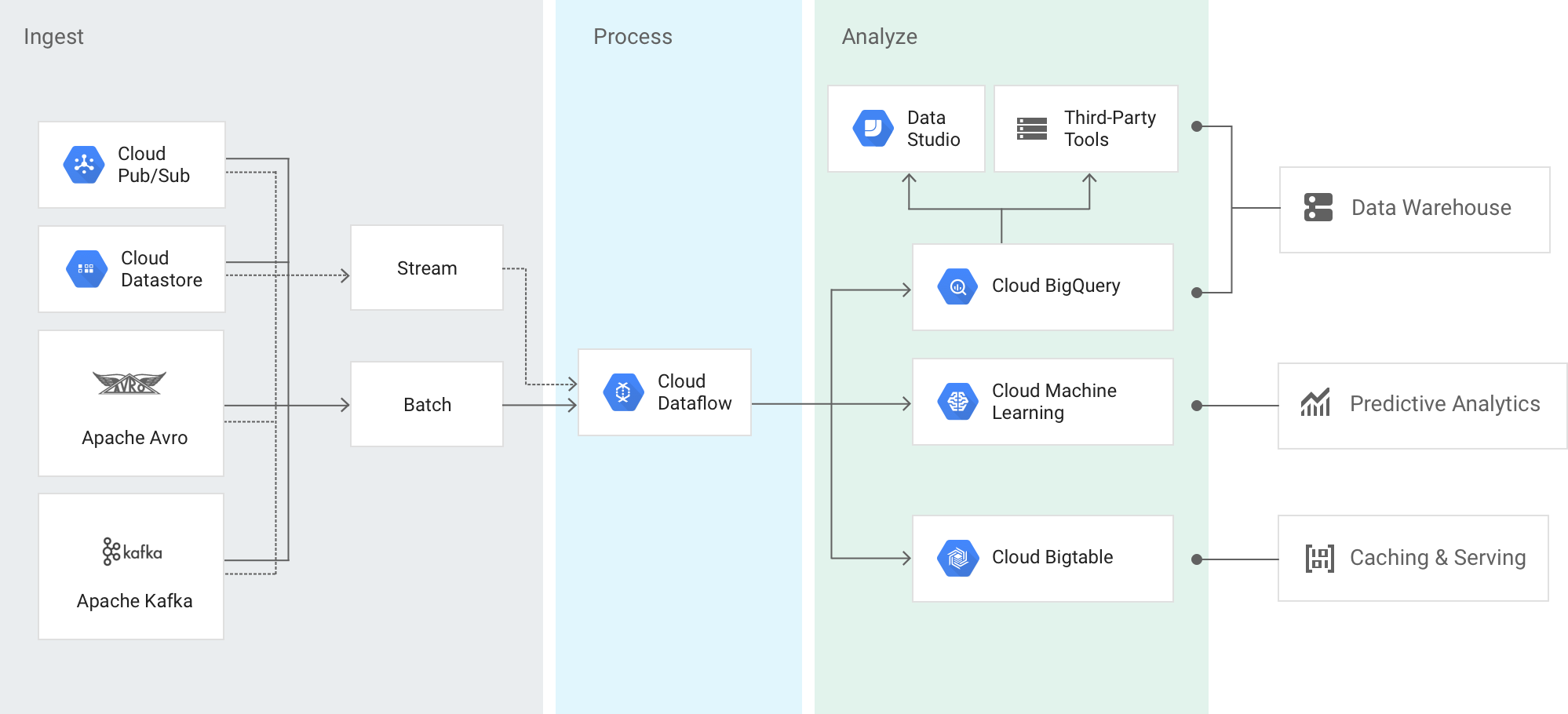
Googleのサンプル画像から見る大雑把な利用モデル。
Cloud DataFlow 実践
実際に使ってみないと分かりづらいので、今回はこんなフローを例に構築します。
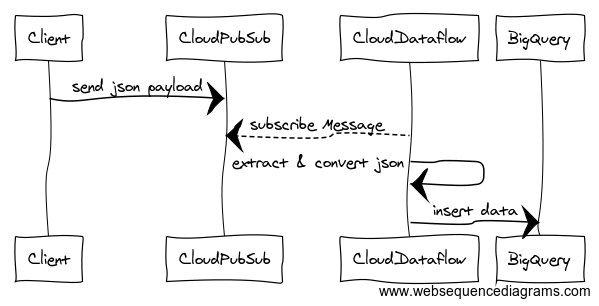
PubSub周りの連携を書きたかったので、入り口をCloudPubSubにしていますが、BigQuery内のテーブルAとテーブルBのデータを加工してテーブルCにロードするような挙動も勿論可能です。
開発環境の作り方
pom.xmlに以下を記載してSDKをダウンロードします。
<dependency>
<groupId>com.google.cloud.dataflow</groupId>
<artifactId>google-cloud-dataflow-java-sdk-all</artifactId>
<version>[2.2.0, 2.99)</version>
</dependency>
mavenいやだー、とかその辺がある方は公式に詳しい情報があるので確認してみてくださひ。
動作の設定についてのコードを書く
まず処理を行うパイプラインのオプションを設定します。
DataflowPipelineOptions options = PipelineOptionsFactory.create()
.as(DataflowPipelineOptions.class);
// 自分の使っているプロジェクト名を指定
options.setProject("your gcp porject");
// Dataflowがstagingに利用するGCSBucketを作って指定
options.setStagingLocation("gs://hoge/staging");
// Dataflowが一時利用するGCSBucketを作って指定
options.setTempLocation("gs://hoge/tmp");
// 実行するランナーを指定。GCP上で実行する場合はDataflowRunnerを指定。local実行の場合はDirectRunner
options.setRunner(DataflowRunner.class);
// streamingを有効にする
options.setStreaming(true);
// 動作時の名称を指定(同じ名称のジョブは同時に稼働できない
options.setJobName("sample");
公式にも説明がありますので、大雑把なところだけ。
(*) 上の例では、設定をコード上から分離したかったので、JavaのResourceBundleを使ってますが動作させるだけなら直値でも動きます。
Dataflow上でのプログラミングを構成する基礎概念
基本的にDataflowのジョブをプログラミングする上では以下の
概念を取り扱うことになります。
-
PipeLine
- 処理ジョブを表現するオブジェクト
- 基本的にPipeLineに処理の流れ(入力・変換・出力)を適用(apply)していく。
- 処理ジョブを表現するオブジェクト
-
PCollection
- データを表現するオブジェクト
-
変換
- 入力データを出力データに変換する処理部分
-
PipeLineI/O
- 入力ないし、出力の定義
基本的にPipeLineに自分の書いた変換処理とPipeLineI/O等の必要な処理を適用して
ジョブを構築する事になります。
inputの読み取り~outputまでのコードを書く
上の図に書いた3つの動作
- CloudPubSubからのメッセージ読み取り
- json(string)をBigQueryにoutputする形(BigQueryRow)に変換する
- BigQuery上のテーブルにロードする
をパイプラインに適用していきます。
//パイプライン(処理するジョブ)オブジェクトを生成
Pipeline p = Pipeline.create(options);
TableSchema schema = SampleSchemaFactory.create();
// 処理内容を適用する
// pubsubのsubscriptionからデータを読み出す
p.apply(PubsubIO.readStrings().fromSubscription("your pubsub subscription"))
// 5分間隔のwindowを指定(なくても可)
.apply(Window.<String>into(FixedWindows.of(Duration.standardMinutes(5))))
// pubsubからの入力に対する変換を設定 (実装は後述)
.apply(ParDo.of(new BigQueryRowConverter()))
// BigQueryへの書き込みを設定
.apply("WriteToBQ", BigQueryIO.writeTableRows()
//書き込み先テーブル名を指定
.to(TableDestination("dataset_name:table_name","description"))
//書き込み先のschemaをObjectで定義して渡す
.withSchema(schema)
//テーブルがなければ作成する(オプション)
.withCreateDisposition(BigQueryIO.Write.CreateDisposition.CREATE_IF_NEEDED)
//テーブル末尾にデータを挿入していく(オプション)
.withWriteDisposition(BigQueryIO.Write.WriteDisposition.WRITE_APPEND));
// 実行
p.run();
- 上記で設定したJsonObjectからBigQueryへの変換(
BigQueryRowConverter)の実装
ParDoを使った変換の場合、DoFnを継承し抽象メソッドであるprocessElementの中にデータの取り出し〜PCollectionへの変換を実装します。
package com.mycompany.dataflow_sample.converter;
import com.google.api.services.bigquery.model.TableRow;
import com.google.gson.Gson;
import com.mycompany.dataflow_sample.entity.SampleInputJson;
import org.apache.beam.sdk.transforms.DoFn;
public class BigQueryRowConverter extends DoFn<String,TableRow> {
@ProcessElement
public void processElement(ProcessContext dofn) throws Exception {
// 入力を受け取る
String json = dofn.element();
Gson gson = new Gson();
// jsonをobjectに変換
SampleInputJson jsonObj = gson.fromJson(json,SampleInputJson.class);
// jsonの内容をbigqueryのtableRowに変換していく
TableRow output = new TableRow();
TableRow attributesOutput = new TableRow();
TableRow attr2Output = new TableRow();
// 出力にデータをセットする
attributesOutput.set("attr1", jsonObj.attributes.attr1);
attributesOutput.set("attr2", jsonObj.attributes.attr2);
attr2Output.set("attr2_prop1",jsonObj.attributes.attr2.prop1);
attr2Output.set("attr2_prop2",jsonObj.attributes.attr2.prop2);
attributesOutput .set("attr2",attr2Output);
output.set("attributes", attributesOutput );
output.set("name", jsonObj.name);
output.set("ts", jsonObj.timeStamp/1000);
// 出力する
dofn.output(output);
}
}
- 上記の
SampleSchemaFactory.create()の実装
package com.mycompany.dataflow_sample.schema;
import com.google.api.services.bigquery.model.TableFieldSchema;
import com.google.api.services.bigquery.model.TableSchema;
import java.util.ArrayList;
import java.util.List;
public class SampleSchemaFactory {
public static TableSchema create() {
List<TableFieldSchema> fields;
fields = new ArrayList<> ();
fields.add(new TableFieldSchema().setName("name").setType("STRING"));
fields.add(new TableFieldSchema().setName("ts").setType("TIMESTAMP"));
fields.add(new TableFieldSchema().setName("attributes").setType("RECORD")
.setFields(new ArrayList<TableFieldSchema>() {
{
add(new TableFieldSchema().setName("attr1").setType("STRING"));
add(new TableFieldSchema().setName("attr2").setType("RECORD")
.setFields(new ArrayList<TableFieldSchema>() {
{
add(new TableFieldSchema().setName("prop1").setType("INTEGER"));
add(new TableFieldSchema().setName("prop2").setType("STRING"));
}
})
);
}
})
);
TableSchema schema = new TableSchema().setFields(fields);
return schema;
}
}
こんな感じ。
デプロイ/テスト
- デプロイ
先ほど書いたJavaのコードをビルドして実行するだけで実際にGCP上にジョブがデプロイされます。

- CloudPubSubからメッセージを送る
GCPのコンソール上からメッセージを送ります。

BigQueryにデータが挿入されていれば動作確認はOKです :)
ログの確認
コンソール上から作成したジョブをクリックし、詳細画面からログが確認できます。
stackdriverにも自動でログが転送されていますので、モニタリング、監視などはそちらを使うと良いです。

エラー(例外発生)時の挙動
DataflowJobを実行中にExceptionが発生した場合、PubSubにACKを送らないので再度データが取り出される事になります。
従って
- BigQueryへのロード部分等で処理がこけてもPubSubのメッセージが破棄されないので自動でリトライされる(通信レベルでのリトライの考慮は不要)
- 反面でデータが正しくない場合はエラーを吐き続ける事になるので、Validationをかけてエラーデータに移す、ロギングする、破棄する等のハンドリングを適切に行う必要がある。
サンプル
サンプルはこちらです。
パーティション切りたかったので、実行時点の日次を元に日別のテーブルを作成するように作ってあります。