はじめに
2020年3月から6月にかけて開催されていたコンペ「Kaggle M5 Forecasting Accuracy / Uncertainty」に参加しました。結果としてUncetaintyで暫定4位を獲得することが出来ました。また、Accuracyでも暫定で銀メダルとなりました(正式な順位は7月15日頃に確定する予定 10月29日に表彰式が開催され、正式に4位となりました。)。
ここでは今回のコンペの概要と、私が工夫した点を紹介したいと思います。
コンペの内容について
コンペの概要
Kaggle M5 Forecastingは、米国3州(カリフォルニア州、テキサス州、ウィスコンシン州)に存在するウォルマート10店舗における、3049種類の商品の売上(販売数量)を予測するというコンペです。売上そのものを予測するAccuracyと、売上の分布を予測するUncertaintyの2つの部門があり、Accuracy部門では5,558チーム、Uncertainty部門では909チームが参加しました。
与えられるデータは3つのCSVファイルです。
- 売上 ・・・ 各店舗・各商品における過去5年間の日別販売数量
- カレンダー ・・・ 宗教行事やスポーツ等のイベント開催日とSNAP(連邦栄養補助プログラム)が利用できる日
- 価格 ・・・ 店舗ごと・商品ごとの週単位の販売価格
予測対象期間
コンペはValidation PhaseとEvaluationPhaseの2段階で行われました。
Validation Phaseでは、訓練データとして2011年1月29日から2016年4月24日までの約5年分の売上データが与えられ、その情報をもとにその後の4週間(2016年4月25日から5月22日)の売上(販売数量)を予測します。そのスコアはPublic Leaderboardの順位に反映されます。
その後、2020年6月1日からEvaluation Phaseとなり、Public Leaderboardのスコア算出に利用されていた2016年4月25日から5月22日の売上が公開され、その情報をもとにその後の4週間(2016年5月23日から6月19日)の売上(販売数量)を予測します。これがPrivate Leaderboard、つまり、最終的な順位に反映されます。
評価指標
評価指標はAccuracy部門とUncertainty部門で異なります。
詳細はコンペ主催者であるMOFCのサイトからダウンロードできる文書(「DOWNLOAD PDF」とありますが、実際はWord文書です)をご覧ください。ここでは簡単に雰囲気だけ記載します。
評価は個別店舗・個別商品の売上(販売数量)時系列データに対してだけ行われるのではなく、それらを州単位に集計したり、商品カテゴリー単位に集計したりして作成した合計販売数量の時系列データに対しても行われます。集計単位は店舗と商品の組み合わせで全12パターンあります。(全店舗・全商品で集計、州単位・全商品で集計、個別店舗単位・全商品で集計、全店舗・商品カテゴリー単位で集計、全店舗・商品分類単位で集計……などなど)
Accuracy部門の評価指標(WRMSSE: Weighted Root Mean Squared Scaled Error)
Accuracy部門では、10店舗における3049種類の商品ごとにこの先4週間の日々の販売数量を予測します。評価指標の基本的な考え方はRMSEですが、若干今回のコンペのために調整されています。
1点目の調整は、店舗・商品ごとに平均的な販売数量が異なるので、スケールを調整します。具体的には、翌日の販売数量を前日と同じであるとして予測した場合のRMSEで割るという調整を行います。
2点目の調整は重み付けです。12種類の時系列データそれぞれに対して上述のスケール調整されたRMSEを算出し、それらを重み付けして足し合わせます。重みはまず12種類の時系列データそれぞれに対して均等に配分され、その中で訓練データの最後の4週間の売上合計金額に応じて時系列データごとに配分されます。例えば、州単位・全商品の時系列データで言えば、カリフォルニア州・テキサス州・ウィスコンシン州の3つの時系列データが存在しますが、売上金額が大きい州にはより大きな重み付けがなされます。
Uncertainty部門の評価指標(WSPL: Weighted Scaled Pinball Loss)
Uncertainty部門は、予測分布の9分位点(0.5%点、2.5%点、16.5%点、25%点、50%点(中央値)、75%点、83.5%点、97.5%点、99.5%点)で評価されます。
基本的な考え方は各分位点のPinball Lossですが、Accuracy部門と同様にこのPinball Lossをスケール調整し、重み付けして足し合わせたものが評価指標となります。
当コンペの評価指標のポイント
今回の評価指標では個別商品の予測もさることながら、それらを店舗や商品カテゴリー単位で集計した値についても正しく予測できていないと高いスコアを出すことはできません。例えば、全店舗・全商品で集計した時系列データは1つしかありませんが、その時系列データに対しては全体の12分の1の重みが割り当てられます。一方で、個別店舗・個別商品の時系列データは30,490個存在するため、それぞれの時系列データは全体の12分の1のさらにおよそ30,490分の1の重みが割り当てられることになり、売上金額が小さな個別商品の時系列データの予測が多少間違っていても全体の評価指標に与える影響はそれほど大きくないことになります。
やったこと
今回私は分布の予測に興味があったのでUncertainty部門の予測を中心に取り組み、結果として出てくる分布の平均値をAccuracy部門の予測にするという方針で取り組みました。Uncertainty部門は集計した時系列データの分布も提出しなければならないため、評価指標の重み付けのことも考えると、結果的にこの戦略は正しかったように思います。
データ観察
データ観察についてはこちらのNotebookを参考にしました。
4-Visual-Overview:-Time-series-plotsあたりをご覧いただければ分かると思いますが、各商品は多くの日で全く売れていません。平均的に10個ぐらい売れている商品でも、在庫切れなのか、長期間(数カ月)にわたって全く売れていない期間が存在します。そのため、個別商品の売上分布は負の二項分布でモデルを作成するのがよいかなと思いました(他の方のソリューションではポアソン分布やTweedie分布が使われていたようです)。
一方、商品をカテゴリー単位や全商品で集計するとだいぶ様相が異なり、年単位や月単位の周期性は存在するものの、概ね正規分布のように振る舞います。そのため、こちらは正規分布、または、T分布でモデルを作成するのがよいと思いました。
まとめると、今回下記の2つのモデルを作成する方針にしました。
- 個別商品の時系列データを予測する負の二項分布のモデル
- 売上をカテゴリー単位や全商品で集計した時系列データを予測する正規分布(またはT分布)のモデル
モデル
私が作成したモデルのイメージはこちらです。
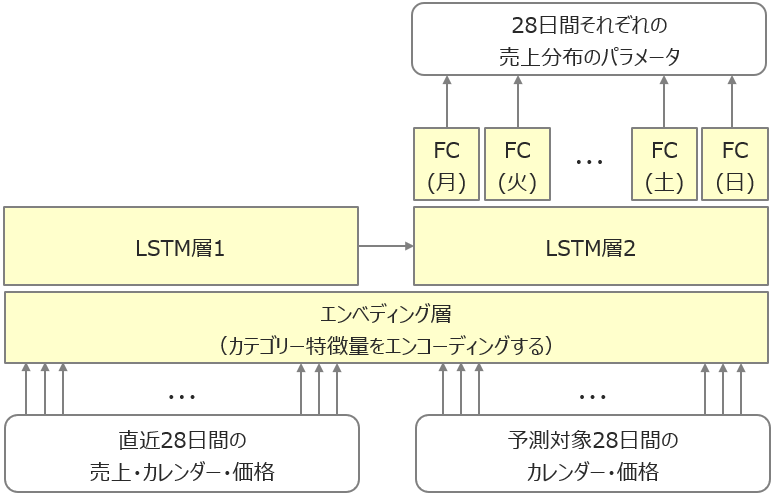
要は、直近28日間の売上・カレンダー・価格と予測対象28日間のカレンダー・価格を入力として、予測対象28日間の売上分布を出力するニューラルネットのモデルです。個別商品の売上を予測する負の二項分布のモデルも、カテゴリー単位や全商品で集計した売上を予測する正規分布・T分布のモデルも、ニューラルネットの構造は全く同じです。
最終出力層はもともとLSTMにしていたのですが、それだと曜日ごとの周期性がうまく表現できないようだったので、曜日ごとに専用のFC層にすることで対応しました。
ニューラルネットのパラメータは最尤推定で求めます。つまり、モデルが予測した分布において、実際の売上の負の対数尤度を求め、それが最小になるように学習します。
特徴量エンジニアリング
上記のようなモデル構造としたため、あまり特徴量エンジニアリングは行いませんでした。作成した特徴量はクリスマスかどうか、平日の祝日かどうか、価格トレンド(日付との相関係数)、などです。作成した特徴量を入力としてその日の売上を予測するモデルをLightGBMで作成し、モデルのImportanceやPermutation Importanceを見て特徴量選択を行いました。
もともとはラグ特徴量(直近N日間の売上の平均など)を作成していたのですが、ラグ特徴量は4週間先まで予測を行う場合に扱いが難しくなります。例えば、4週間先の予測を行う場合、その前日の売上データは分からないので、自身で予測した売上で再帰的にラグ特徴量を作成するなどしなければなりません。そのため、今回はラグ特徴量を利用しないことにしました。
平日の祝日かどうかの特徴量を作成するにあたって、Accuracy の Discussion に上がっていたFederal Holidays USA 1966-2020を使用しました。
全商品や商品をカテゴリーで集計する時系列を予測する正規分布(またはT分布)のモデルは、事前に売上データを時系列データごとにPowerTransformerで正規分布に近づけておきました。一方、個別商品の予測に利用する負の二項分布のモデルでは生の売上データを使用しており、前処理は行っていません。例えば、平均的に1個売れる商品と10個売れる商品では分布が大きく異なります。スケールを調整してしまうとそのような分布の形状が大きく崩れてしまうと考え、スケールの変換は行いませんでした。もう一つの理由は、9分位点を出す際に離散変数(整数)として出したかったからです。
Local CV
今回Local CVのスコアをどのように出すのか悩みました。scikit-learnのTimeSeriesSplitを使って、例えば、n_splits=5とすると、5年分の訓練データが6等分され、最初のFOLDの訓練データは1年分しかありません。そうなると多くの商品がまだ販売されていないですし、直近の分布とは大きく異なっていることが考えられ、あまり役に立ちません。
そこで、1カ月(4週間)を単位として、FOLDごとに時系列データを過去にさかのぼり、最後の4週間をテストデータ、その前の4週間をバリデーションデータ、さらにその前の4週間を訓練データとすることにしました。
例えば、4回のCVを行う場合の最初のFOLDであれば、5年分ある訓練データの最後の3カ月(12週間)分を削除します。その訓練データの中で、最後の4週間をテストデータ、その前の4週間をバリデーションデータ、残りを訓練データとします。次のFOLDは最後の2カ月を削除して訓練・バリデーション・テストに分割します。以下、同様です。
……という方針で進めていたのですが、バリデーションデータやテストデータの期間が4週間ではあまりに短く、各FOLDでearly stoppingするepochもぜんぜん違うし、スコアもぜんぜん違うという事になってしまいました。おそらく4週間ごとに分布が大きく異なっているからだと思われます。土壇場で2カ月を1単位とする方針に変更しました。しかし、変更しても状況はあまり変わらずでした。
他の方はどうしていたのか気になります。
Local CVで評価するスコアはテストデータのロスに対して重み付けしたものを利用しました。これによって、より重要度の高い時系列データに対して正しく予測できているのかを確認するようにしました。コンペの評価指標であるWSPLは処理に時間がかかりそうだったし、面倒だったので実装しませんでした。
seedガチャ問題
もう一つ悩んだこととして、seedによってスコアが大きく変動するという問題にぶちあたりました。商品をカテゴリー単位や全商品で集計し、正規分布またはT分布を出力するモデルは、時系列データのバリエーションが少ないので過学習に陥りやすく、おそらくそれが原因でseedガチャ問題にぶつかったのだと思います。隠れ層のノード数を減らしたり、dropoutを入れたり、weight_decayを入れたり、様々な過学習の対策を入れましたが、最後までこの問題は解決しませんでした。
seedガチャ問題の厄介なところは、「こうやったら性能が改善するだろう」という努力が果たして効果があったのか、それとも単にいいseedを引いただけなのか区別がつかなくなるところです。仕方ないのでハイパーパラメータサーチの際には、複数の異なるseedで出した結果の平均値で比較しました。
また、最終モデルの選択にあたっては、公開された Validation Phase の売上データ(2016年4月25日から5月22日の売上データ)は訓練には使用せずにモデルを作成し、様々なseedを試した中で最もPublicのスコアが高かったものを選択しました。Validation Phase の売上データを訓練に使用しないという判断はかなり迷いましたが、結果的にこの方針によってよいseedを選択することができました。
個別商品の予測に利用する負の二項分布のモデルでは、この問題は起きませんでした。
ターゲットエンコーディング
前述のとおり、個別商品を予測する負の二項分布モデルは前処理として売上のスケールは変換していませんでした。そのため、特に販売数が大きな商品の予測が正しく行えるのか不安に感じていました。そこで、ニューラルネットがスケールを調整するためのガイドとしてターゲットエンコーディングを追加しました。各時系列+曜日で全期間の売上の平均値を求め、最終FC層の手前に入力することにしました。リークを回避するためには、過去のデータのみでターゲットエンコーディングするべきだろうと思いますが、時間がなかったのでそのような考慮はせず、全期間の平均にしました。
結果的にこの特徴量は、全商品やカテゴリー単位で集計する正規分布のモデルでも有効でした。
Accuracyの予測の調整
Accuracy部門に提出する売上の予測は、モデルが予測した分布の平均値をもとに出しましたが、その値を州や商品カテゴリーで合計した時に、集計時系列の予測分布の平均値と一致するように予測値を調整しました。これによってAccuracyのスコアがやや向上しました。
これは Accuracy の Notebook にあった M5 - Witch Time からヒントを得ました。
その他の細かい工夫
より直近のデータを重視するため、2015年のデータは2倍に、2016年のデータは4倍にオーバーサンプリングしました。また、評価指標は売上高によって重み付けされるため、時系列データごとにロスに重み付けをすることを試しましたが、これは個別商品の負の二項分布のモデルでは有効でしたが、全商品やカテゴリー単位で集計する正規分布のモデルではスコアが悪化しました。
予測分布を見ていると、分散が小さいモデルのスコアが高いように見受けられたので、分散が小さくなるようにロスを調整しました。が、この点については明確な効果があったのかどうかは確認できていません。
実装上の工夫
今回、ニューラルネットの実装はPytorch、学習ループのフレームワークとしてPytorch-Lightning、実験管理にMLFlow Tracking、ハイパーパラメータのYAMLファイル入力にHydraを利用しました。
Pytorch-LightningとMLFlowの組み合わせはとても便利です。あまり自分で実装しなくても勝手にハイパーパラメータやロスのログを残してくれます。自分で独自のスコアを残したりしたい場合は、通常のMLFLowの実装(例えば、 mlflow.log_metric("foo", 1) など)とは異なり、 mlflow.tracking.MlflowClient のAPIを利用する事になりますが、それだけ分かっていれば特に難しいことはありません。
一方、Hydraは今回使ってみたものの、実装がHydraのフレームに縛られ、個人的によい印象は持ちませんでした(例えば、 logging.basicConfig() で設定した内容がHydraによって上書きされる、など)。
私が実装したソースコードはこちらで公開しています。
感想
Kaggleのコンペに本格的に参加したのは今回が初めてでしたが、まさか4位とは、未だに信じられません。Public Leaderboard ではコンペ期間中ずっと下から数えたほうが早かったので、最初にPrivateの順位を見たときには目を疑いました。
応援してくださった皆さん、このコンペの主催者の皆さん、共に戦ったKagglerの皆さん、本当にありがとうございました。
Accuracy は最初から諦めていたのですが、Uncertainty なら参加チームも少ないし、ワンチャン銅メダルぐらい取れるんじゃないかと思って参加しました。実際に参加してみるとデータ量とメモリ管理に苦労し、それでいて一向に Public Leaderboard は上がらず、心が折れそうになっていましたが、最後までがんばり続けたことで自分としては最高の結果を残すことができました。本当に嬉しいです。
今回のコンペを通して、時系列データの扱いについてはいろいろと勉強になりました。主催者がベースラインのモデルを公開していたり、Pyroの開発者がPyroのソリューションを公開してくれているので、それらを見ながら引き続き勉強していきたいと思います。