はじめに
猫好きのみなさんこんにちは。2匹の猫の写真を入力すると、どちらの猫なのかを答えてくれる機械学習モデルを作りたくなることってありますよね。本記事では、猫好き的機械学習の Hello World! である(個人の見解です)猫を見分ける画像分類モデルを作ります。
以前、Amazon Rekognition Custom Labels というサービスを使って、ノーコードで猫を見分けるモデルを作る方法 をご紹介しました。
今回は、去年の AWS re:Invent で発表された Amazon SageMaker JumpStart を使ってサクッと猫を見分ける機械学習モデルを作ってみようと思います。Amazon SageMaker JumpStart は、コーディングなしで学習済みモデルをそのままサクッとデプロイしたり、学習済みモデルを fine-tune してサクッとデプロイしたりできる Amazon SageMaker Studio の機能です。機械学習の詳しい知識やコーディング経験がなくても、独自の機械学習モデルを作れるようになっています。
今回使用するのは以下のオレンジ色っぽいタマとグレーっぽいミケの画像で、それぞれ 20 枚ほど用意しました。はたして、Amazon SageMaker JumpStart はタマとミケを見分けるモデルを作れるのでしょうか!?

Amazon SageMaker JumpStart を使う
Amazon SageMaker JumpStart を始めるには、まず Amazon SageMaker Studio をセットアップ する必要があります。以下の説明は、Amazon SageMaker Studio を起動した状態から始めます。
Launcher から Amazon SageMaker JumpStart を開始
初めて Amazon SageMaker Studio を開始するとこのような Launcher が表示されます。表示されていない場合は、左上の [アイコン + Amazon SageMaker Studio] と書かれた部分をクリックすると、Launcher が表示されます。
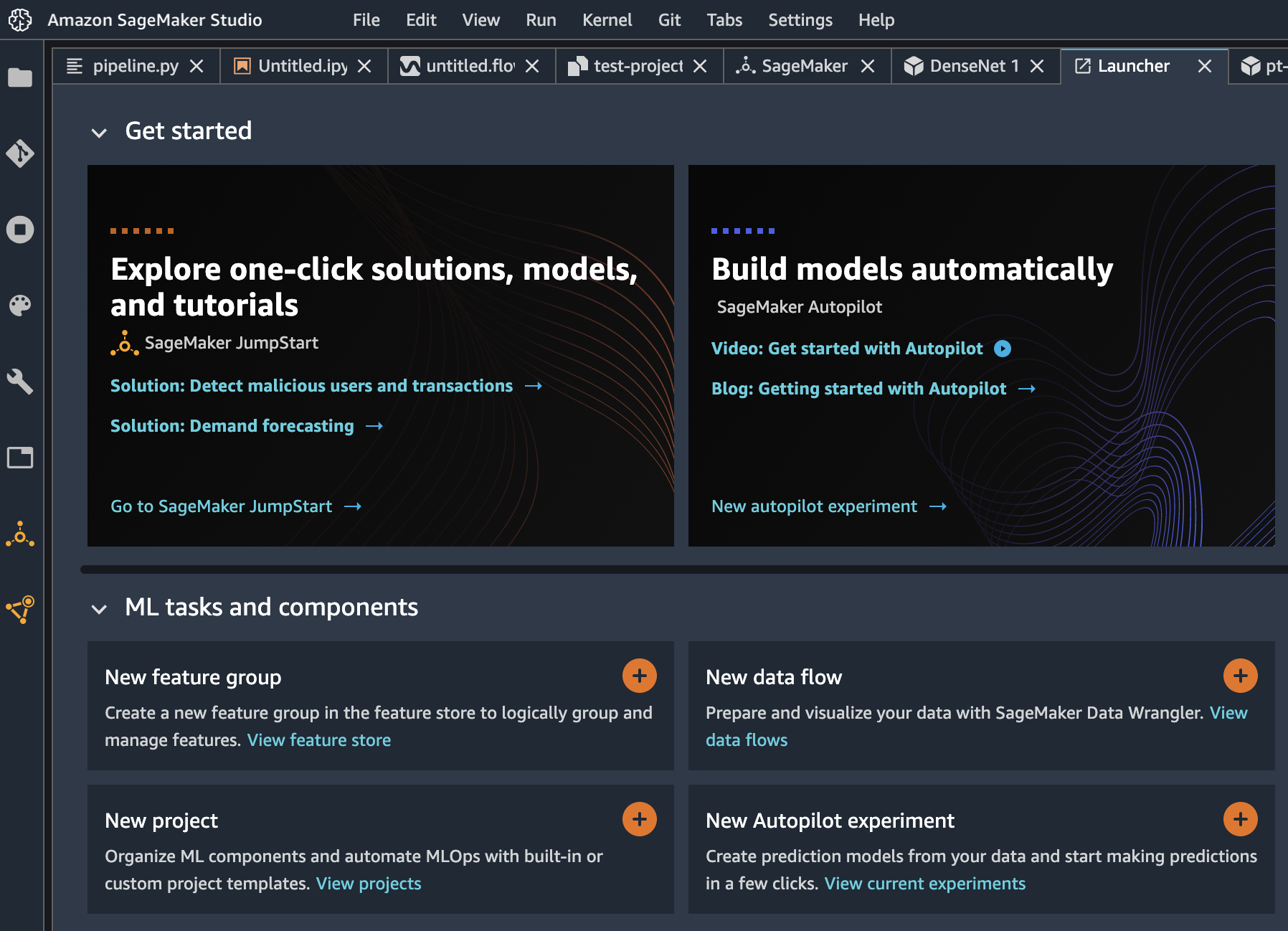
Launcher の左上の [Explore one-click solution, models, and tutorials] をクリックすると、以下の項目が表示されるので、自分のやりたいことができそうなものを選択します。

#2 と #3 は学習済みモデルに対して自分のデータセットを使って fine-tune することができます。
今回は、猫の画像分類をやりたいので、#3 の Vision models を使います。
| # | 項目 | 概要 |
|---|---|---|
| 1 | Solutions | AWS CloudFormation を使ってデプロイ可能なソリューション(金融取引の不正検知、設備の予知保全など) |
| 2 | Text models | 自然言語処理モデル |
| 3 | Vision models | 画像認識モデル |
| 4 | SageMaker algorithms | Amazon SageMaker のビルトインアルゴリズムのサンプルノートブック |
| 5 | Example notebooks | スポットインスタンスを使用したモデルの学習や、分散学習など、Amazon SageMaker の便利機能を使うためのサンプルノートブック |
| 6 | Blogs | Amazon SageMaker の便利機能を紹介する AWS blog |
| 7 | Video tutorials | Amazon SageMaker の便利機能を紹介する動画 |
Vision models の右にある [View all] をクリックすると、使用可能なモデルが表示されます。2021年2月現在、Tensorflow Hub もしくは PyTorch Hub の Image Classification と Object Detection の学習済みモデルが並んでいて、Image Classification は Fine-tune に対応していますが、Object Detection は Fine-tune に対応していません。
学習済みモデルを Fine-tune する
今回は、ベースの学習済みモデルとして PyTorch の DenseNet 169 を使ってみます。検索窓にキーワードを入れるとモデルを見つけやすいです。所望のモデルをクリックします。

クリックすると、モデルの詳細画面に遷移します。[Deploy] ボタンをクリックすると、学習済みモデルがデプロイされた推論用エンドポイントが起動します。[Deployment Configuration] をクリックすると、エンドポイントで使用したいインスタンスタイプとエンドポイント名をカスタムできます。
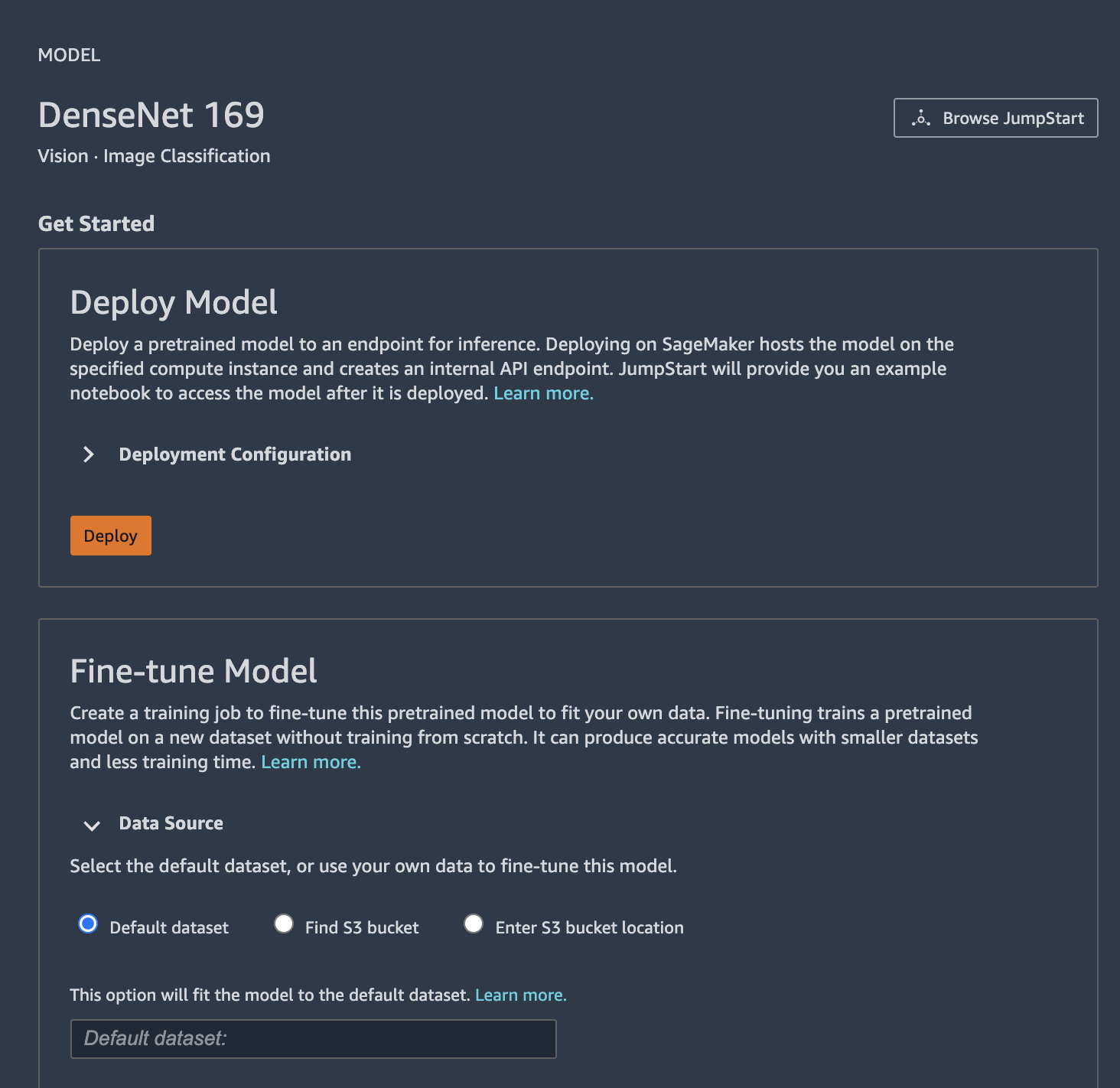
モデルの詳細画面を一番下までスクロールすると、モデルの fine-tune のために必要なデータセットに関する説明があります。Image Classification モデルを fine-tune する場合は、ラベル名に相当するフォルダを作成し、その中にラベルに対応する JPG 画像を入れ、 Amazon S3 にアップロードする必要があります。ラベルの順番はアルファベット順に 0 から順番に割り振られます。

Fine-tune Model の項目で、fine-tune で使用したい画像が保存されている Amazon S3 パスを指定します。デフォルトの設定のままだとうまく学習できない可能性が高いので、[Hyper-parameters] をクリックして展開してハイパーパラメタを設定します。今回は以下の設定にしました。すべての設定が終わったら、[Train] をクリックします。
| Hyper-parameter | Value |
|---|---|
| Epochs | 1000 |
| Learning Rate | 0.01 |
| Batch Size | 4 |
学習ジョブが開始すると、左側に JumpStart の学習ジョブ一覧ウィンドウが表示され、右側には起動した学習ジョブの詳細情報が表示されます。今回の設定だと、学習に 30 分ほどかかりました。学習ジョブのステータスが [Complete] になったら、下の [Deploy Model] の項目の [Deployment Configuration] を必要に応じて変更して [Deploy] をクリックします。
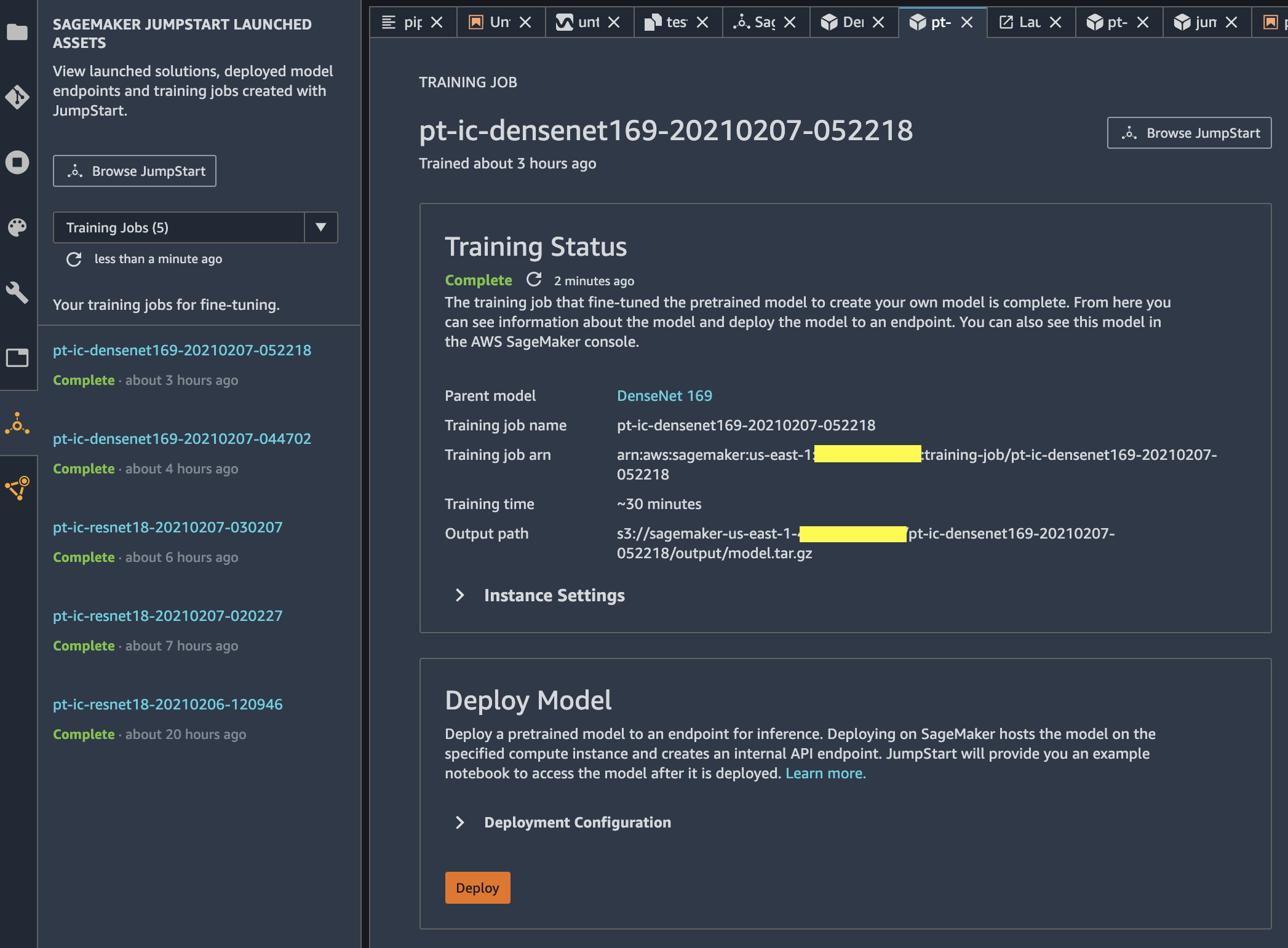
すると、左側に JumpStart のエンドポイント一覧が表示され、右側には起動した推論用エンドポイントの詳細情報が表示されます。エンドポイントのステータスが [In Service] になったら、エンドポイントに推論リクエストを投げられるようになります。

どういう風に推論リクエストを投げれば良いの!?と思われた方、ご安心ください。[Use Endpoint from Studio] のエリアにある [Open Notebook] をクリックすると、エンドポイントに推論リクエストを投げるサンプルノートブックが起動します。
サンプルノートブックを使って推論を実行
サンプルノートブックをカスタマイズして推論を実行します。左側に縦に並んでいるアイコン郡の一番上にある、フォルダの形をしたアイコンをクリックしてファイルブラウザを表示します。ルートディレクトリに DemoNotebooks というフォルダができているので、それをクリックします。次に、推論に使用したい JPG 画像を DemoNotebooks にドラッグ&ドロップでアップロードします。

また、画像と同じ位置に、ラベル情報をアルファベット順で記載したテキストファイルを作成しておきます。
Mike
Tama
なお、ラベル名とラベルIDのリストは、学習ジョブが Amazon S3 にアップロードした model.tar.gz の中に class_label_to_prediction_index.json として保存されているので、そちらを利用しても OK です。
{"Mike": 0, "Tama": 1}
画像を読み込む部分を以下のように書き換えます。
input_img1 = 'filename1' # アップロードした JPG 画像名
input_img2 = 'filename2' # アップロードした JPG 画像名
ImageLabels = 'label.txt' # ラベルが記載されたテキストファイル名
with open(input_img1, 'rb') as file: images[input_img1] = file.read()
with open(input_img2, 'rb') as file: images[input_img2] = file.read()
with open(ImageLabels, 'r') as file: class_id_to_label = file.read().splitlines()[0::]
サンプルノートブックは、上位 5 つのラベルを表示していましたが、今回は猫が 2 匹しかいないので、最後のセルのラベル情報取得部分を以下のように書き換えます(配列のインデックスを 5 から 2 に変更)。
# top5_prediction_ids = sorted(range(len(model_predictions)), key=lambda index: model_predictions[index], reverse=True)[:5]
top5_prediction_ids = sorted(range(len(model_predictions)), key=lambda index: model_predictions[index], reverse=True)[:2]
推論結果を表示してみます。確率の高い順でラベルが表示されています。オレンジ色っぽい猫が Tama(タマ)で、グレーっぽい猫が Mike(マイクじゃなくてミケ)という結果になりました。期待するモデルを作成できました!

推論の実行には boto3 を使っているので、同じコードを使って Lambda からも簡単に推論を実行することができます。
推論環境を自分で構築する場合、画像にどのような前処理(正規化・標準化など)が必要か気になると思います。SageMaker コンソールなどで学習ジョブの詳細画面を表示すると、「ハイパーパラメータ」の部分に「sagemaker_submit_directory」というキーがあり、値として source.tar.gz の S3 パスが書かれています。ここにはモデルの学習で使用されたソースコードが保存されているので、これを確認することで画像にどのような前処理が行われたかを把握することができます。
推論用エンドポイントの削除
エンドポイントの詳細画面の一番下にある [Delete Endpoint] のエリアにある [Delete] をクリックするとエンドポイントを削除することができます。これを忘れると、エンドポイントの料金がかかり続けるので、不要になったら必ず削除することをおすすめします。
さいごに
Amazon SageMaker JumpStart を使って、猫を見分ける機械学習モデルを作りました。画像を準備して Amazon S3 にアップロードして、それを指定してモデルを学習し、学習済みモデルをデプロイするところまでは GUI 操作のみで行い、推論する時はサンプルノートブックをちょっとカスタムするだけでやりたいことがサクッとできました。