はじめに
データを分析したり機械学習で学習させたりする前に、たいてい欠損値の補完や不要な列の削除などの前処理が必要です。ここでは、AWS Glue DataBrew を使ってデータの分析と前処理をする方法をご紹介します。
データの分析
Titanic のデータを使ってデータの分析をやってみます。
AWS コンソールにログインして DataBrew のコンソールにアクセスします。

データセットの作成
コンソール左側のメニューからデータセットを選択すると、ファイルを選択して直接アップロードしたり、Amazon S3 に保存してあるファイルを指定したり、その他のデータソースを選択してデータセットを作成することができます。

プロジェクトの作成
次に、作成したデータセットを指定してプロジェクトを作成します。今のところ IAM ロールは自分で作成する必要があります。データセットに登録した CSV ファイルが保存された S3 バケットへの GetObject の権限が必要になります。
プロジェクトを作成すると、このような進捗を示す画面が表示されます。他の AWS サービスと比べてポップな感じがします。日本語にもバッチリ対応しています。

データの内容が表示されました。データの分布など簡単な分析結果も表示されています。

データの分析
[プロフィール] タブを選択して、[データプロファイルを実行] をクリックします。
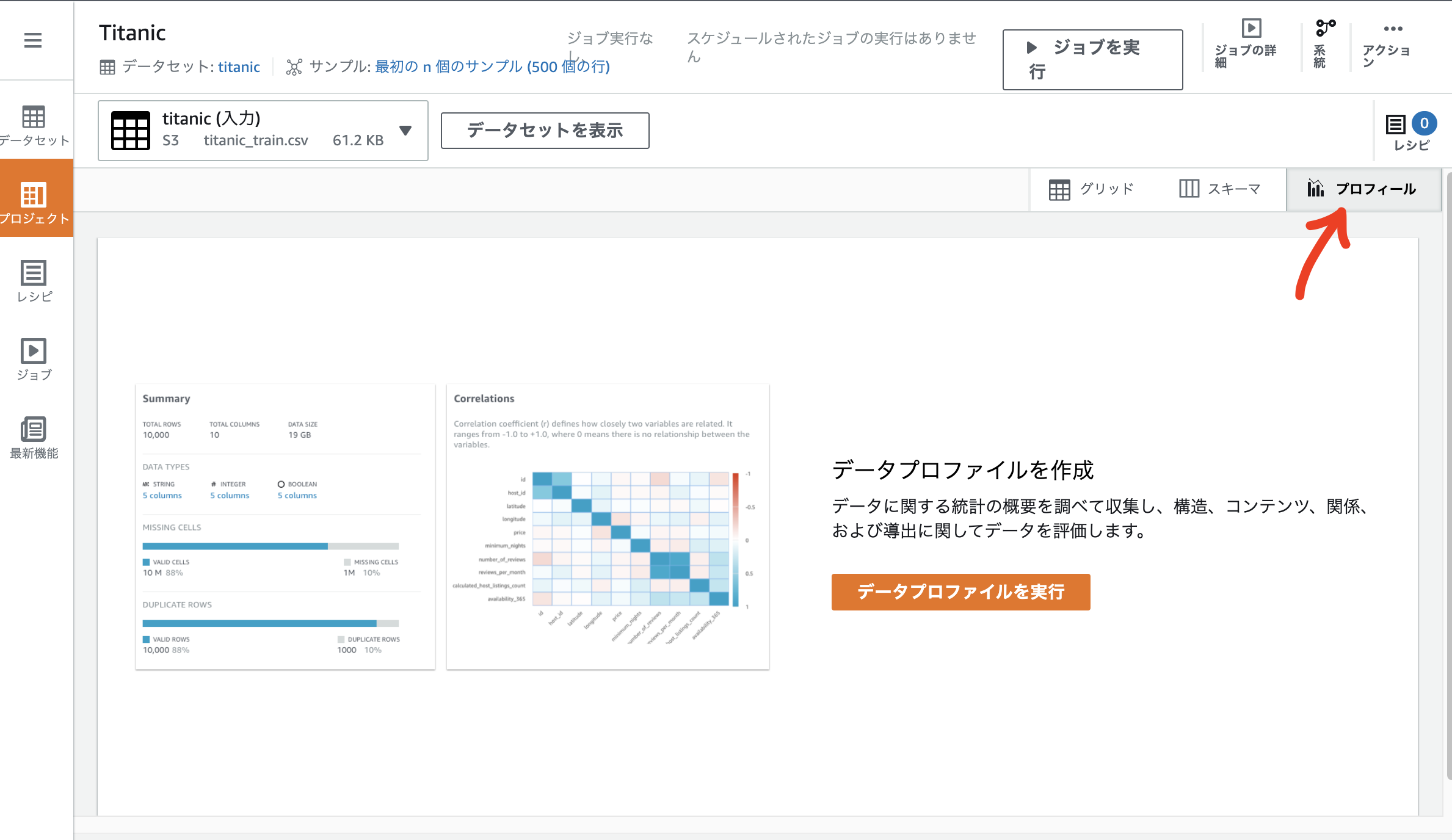
[ジョブを作成] 画面でデータの出力場所と IAM ロールを設定して、[ジョブを作成し実行する] をクリックして数分待つと、以下のような画面が表示されます。ジョブの実行がなかなか終わらない場合、リロードするとしれっと完了していることがあります。相関関係の図は、数値データに対してそれぞれ相関がどの程度あるかを確認することができます。Fare と Pclass に負の相関があることがわかります。

[列の統計] タブをクリックすると、各特徴量の分析結果を確認できます。Age には 20% ほど欠損値があることがわかりました。
スキーマの確認
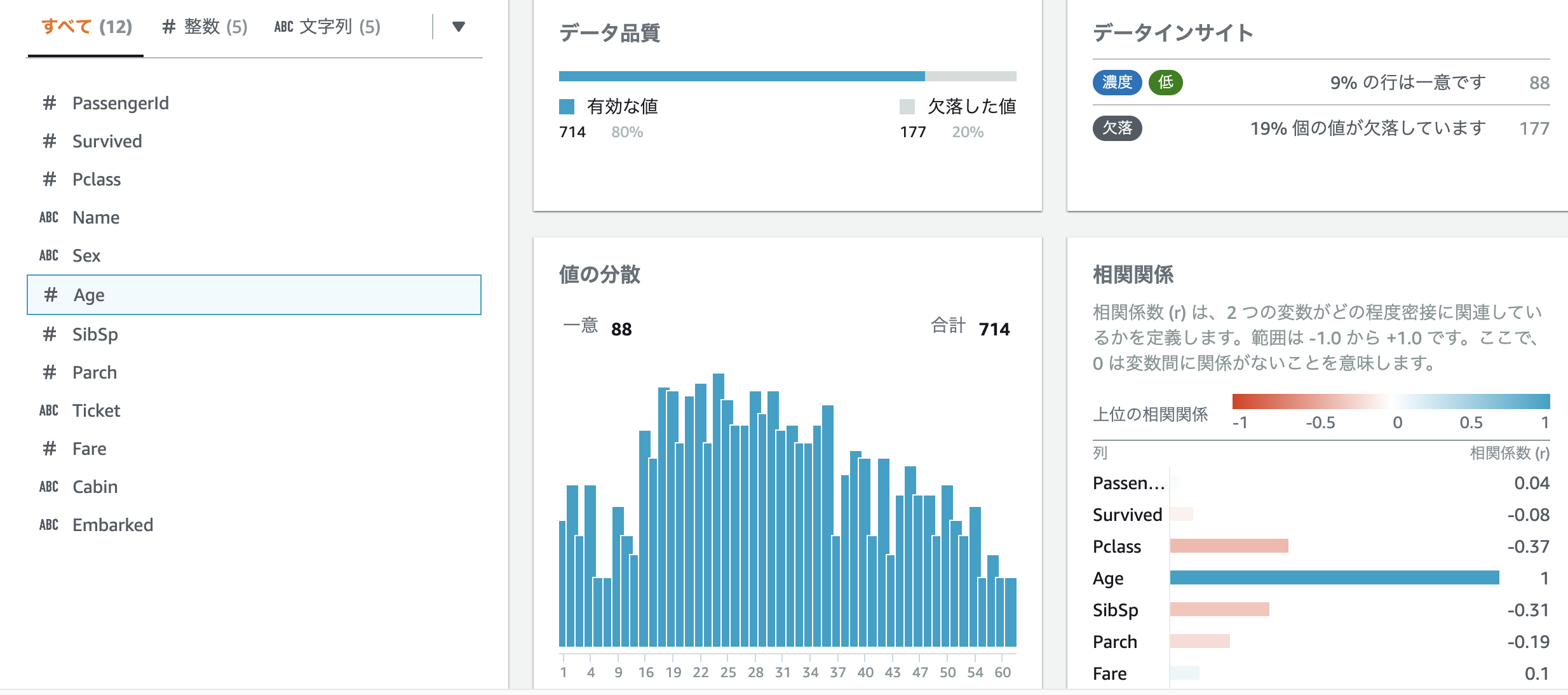
[スキーマ] タブを選択すると、各特徴量の統計データを確認することができます。また、表示/非表示 のスイッチを非表示にセットすると、[グリッド] タブでその特徴量が非表示になります。

欠損値がある Age を選択し、右側のペインで [推奨事項] タブをクリックすると、Age に対して適用すべき処理が表示されます。表示された項目をクリックして、その処理を適用することができます。列の順番や列の名前を変えることもできます。

データの前処理
列の削除
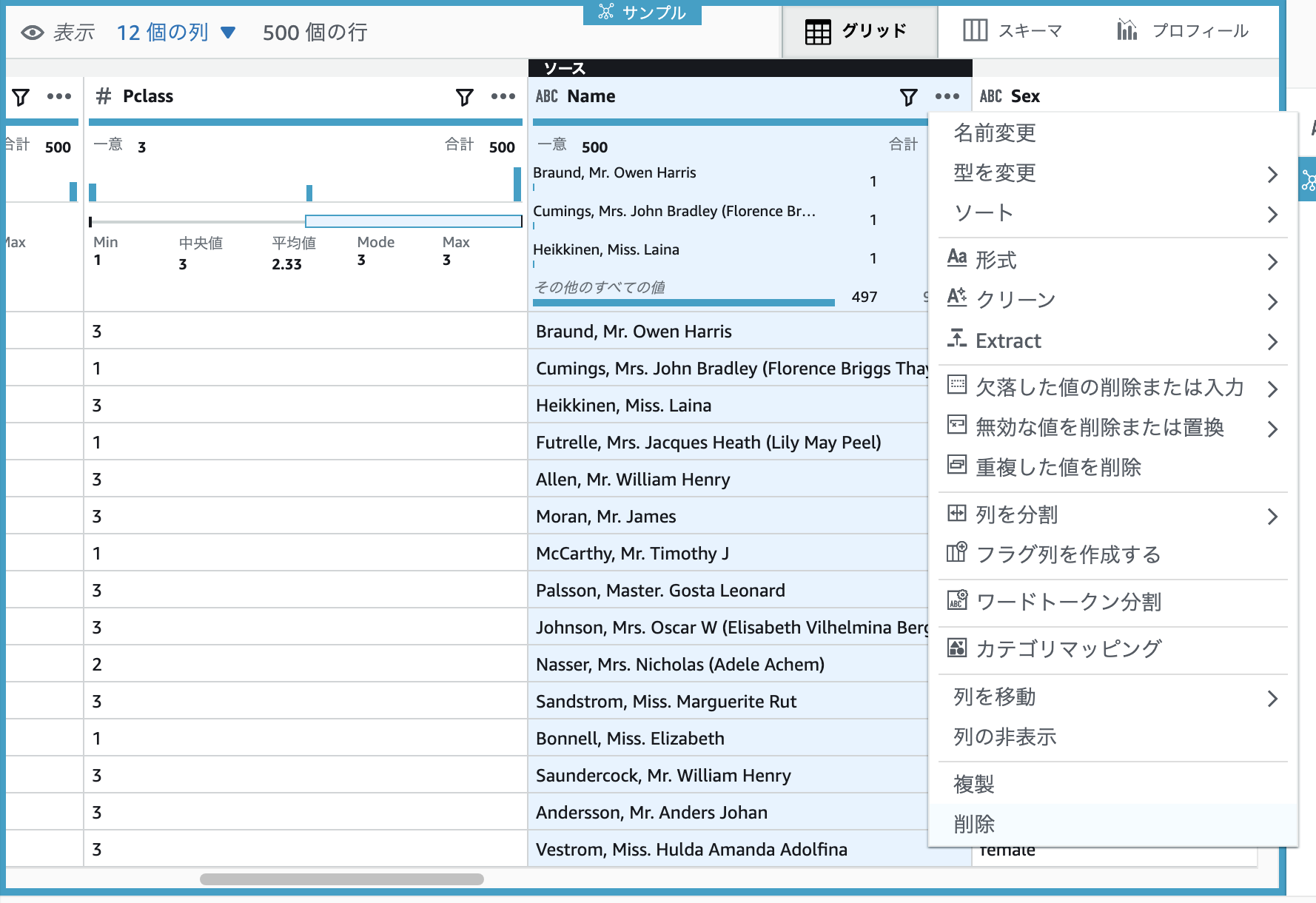
生存可否を予測するのに Name は不要なので、Name 列を削除してみます。[グリッド] タブを選択してデータ閲覧画面を表示し、Name 列の右側にある […] をクリックし、削除を選択し、[適用] をクリックます。
カテゴリデータを one-hot エンコーディング
Pclass はカテゴリデータなので、これを one-hot エンコーディングしてみます。Pclass 列の右側にある […] をクリックし、[One-Hot-Encode 列] を選択し、[適用] をクリックします。すると、Pclass 列の右側に、Pclass_1、Pclass_2、Pclass_3 列が追加されました。元の Pclass 列は不要なので削除しておきます。

レシピの確認
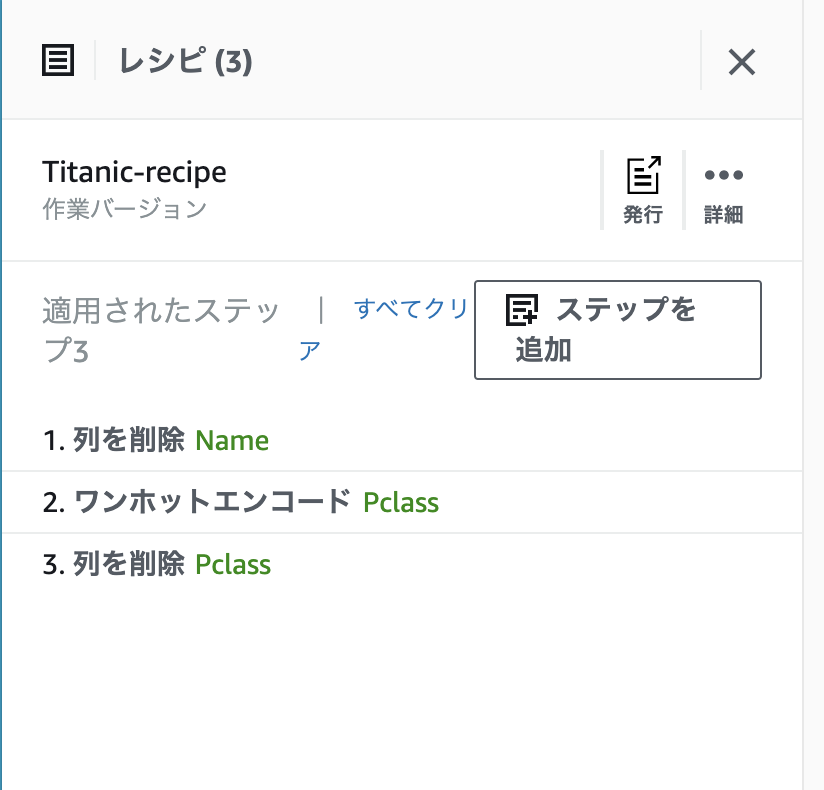
ここまでで、Name 列の削除、Pclass 列の one-hot エンコーディング、Pclass 列の削除を適用しました。これにより、[レシピ] 画面が以下のようになりました。ここで [発行] アイコンをクリックするとレシピを公開することができます。公開したレシピはコンソール左側の [レシピ] メニューに一覧表示されるようになります。
ジョブを実行(前処理の内容をデータに適用して保存)
レシピが空ではない状態で、コンソールの右上にある [ジョブを実行] をクリックし、ファイル出力場所の設定をして [ジョブを実行] をクリックします。すると、レシピの内容がデータセットに適用されて、指定した場所に保存されます。
データ系列の表示
コンソール右上の [系統] アイコンをクリックすると以下のような画面が表示されます。このプロジェクトでどのようなデータに対してどのような操作がされたかが可視化されています。各アイコンをクリックすると、それぞれの詳細を確認することができます。

さいごに
本記事では、AWS Glue DataBrew を使ってデータを分析、前処理する方法をご紹介しました。とっつきやすい UI で直感的な操作がやりやすく、前処理の内容をレシピという形で保存して他のデータセットに適用するなども簡単にできるようになっています。
Glue DataBrew に似たサービスとして、データの分析や前処理ができる Amazon SageMaker Data Wrangler がありますが、こちらは特徴量の重要度を算出できたりと機械学習っぽい機能がついているのと、前処理の内容を Python コードに Export できるようになっているので、最終的にコードに落としてシステムに前処理を組み込む前提なのかなという印象です。