はじめに
AWS Re:Invent 2021 で Amazon SageMaker の新しい機能がいくつか発表されましたが、この記事ではその中の Amazon SageMaker Inference Recommender について こちらのサンプルコード を実行しながら何ができるのかを紐解いていきたいと思います。以降では、Amazon SagMaker ノートブックインスタンスを使用してサンプルノートブックを実行していきます。
サンプルノートブックは Amazon SageMaker Studio で実行しました。SageMaker Studio のセットアップ方法は こちらの記事 で紹介しています。
Amazon SageMaker Inference Recommender 概要
AWS ブログ などによると、Inference Recommender は、SageMaker の推論エンドポイントとして選択可能な多数のインスタンスの中から、自分がデプロイしたいモデルに最適なインスタンスをおすすめしてくれる機能のようです。従来、コストとパフォーマンスのバランスが取れるインスタンスを見つけるためには、自分で複数の推論エンドポイントを起動してテストする必要がありましたが、それが自動化できるようです。なんだか便利そうですが、簡単に使えるものなのか、サンプルノートブックを実行しながら確認していきましょう。
サンプルノートブックを実行してみる
こちらのサンプルノートブック を開きます。
デプロイ対象のモデルの準備
サンプルノートブックでは、学習済みの Tensorflow ResNet50 のモデルを使っています。自分で学習したモデルを使いたい場合は model.tar.gz を差し替えればよさそうです。
import os
import tensorflow as tf
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras import backend
tf.keras.backend.set_learning_phase(0)
model = tf.keras.applications.ResNet50()
# Creating the directory strcture
model_version = "1"
export_dir = "./model/" + model_version
if not os.path.exists(export_dir):
os.makedirs(export_dir)
print("Directory ", export_dir, " Created ")
else:
print("Directory ", export_dir, " already exists")
model_archive_name = "model.tar.gz"
payload_archive_name = "payload.tar.gz"
# Save to SavedModel
model.save(export_dir, save_format="tf", include_optimizer=False)
サンプルによると、model.tar.gz の中には学習済みモデルだけではなく推論用のコードを含める必要があるようです。以下のファイルたちをまとめて model.tar.gz を作成しています。
./model/
./model/1/
./model/1/assets/
./model/1/variables/
./model/1/variables/variables.index
./model/1/variables/variables.data-00000-of-00001
./model/1/saved_model.pb
./code/
./code/inference.py
./code/requirements.txt
推論データの準備
自動テストの際に使用する入力データを payload.tar.gz として準備しています。画像を 4つ用意して、それらを payload.tar.gz として圧縮しています。
!cd ./sample-payload/ && tar czvf ../payload.tar.gz *
データを Amazon S3 にアップロード
作成した model.tar.gz と payload.tar.gz を Amazon S3 にアップロードします。このあたりは SageMaker の学習ジョブなどと同様のお作法ですね。
sample_payload_url = sagemaker.Session().upload_data(
payload_archive_name, bucket=bucket, key_prefix=prefix + "/inference"
)
model_url = sagemaker.Session().upload_data(
model_archive_name, bucket=bucket, key_prefix=prefix + "/reset50/model"
)
こんな感じでファイルがアップロードされます。
s3://sagemaker-us-east-1-xxx/sagemaker/inference-recommender/inference/payload.tar.gz
s3://sagemaker-us-east-1-xxx/sagemaker/inference-recommender/reset50/model/model.tar.gz
CPU times: user 1.58 s, sys: 725 ms, total: 2.3 s
Wall time: 2.36 s
モデルに関する設定
ここからが Inference Recommender を使うための設定になります。まず、Inference Recommender に渡すモデルの情報の設定を確認します。モデルの情報とは、たとえば以下のような選択肢があります。
- 機械学習ドメイン:COMPUTER_VISION, NATURAL_LANGUAGE_PROCESSING, MACHINE_LEARNING
- 機械学習タスク:CLASSIFICATION, REGRESSION, OBJECT_DETECTION, OTHER
- モデル名:resnet50, yolov4, xgboost など
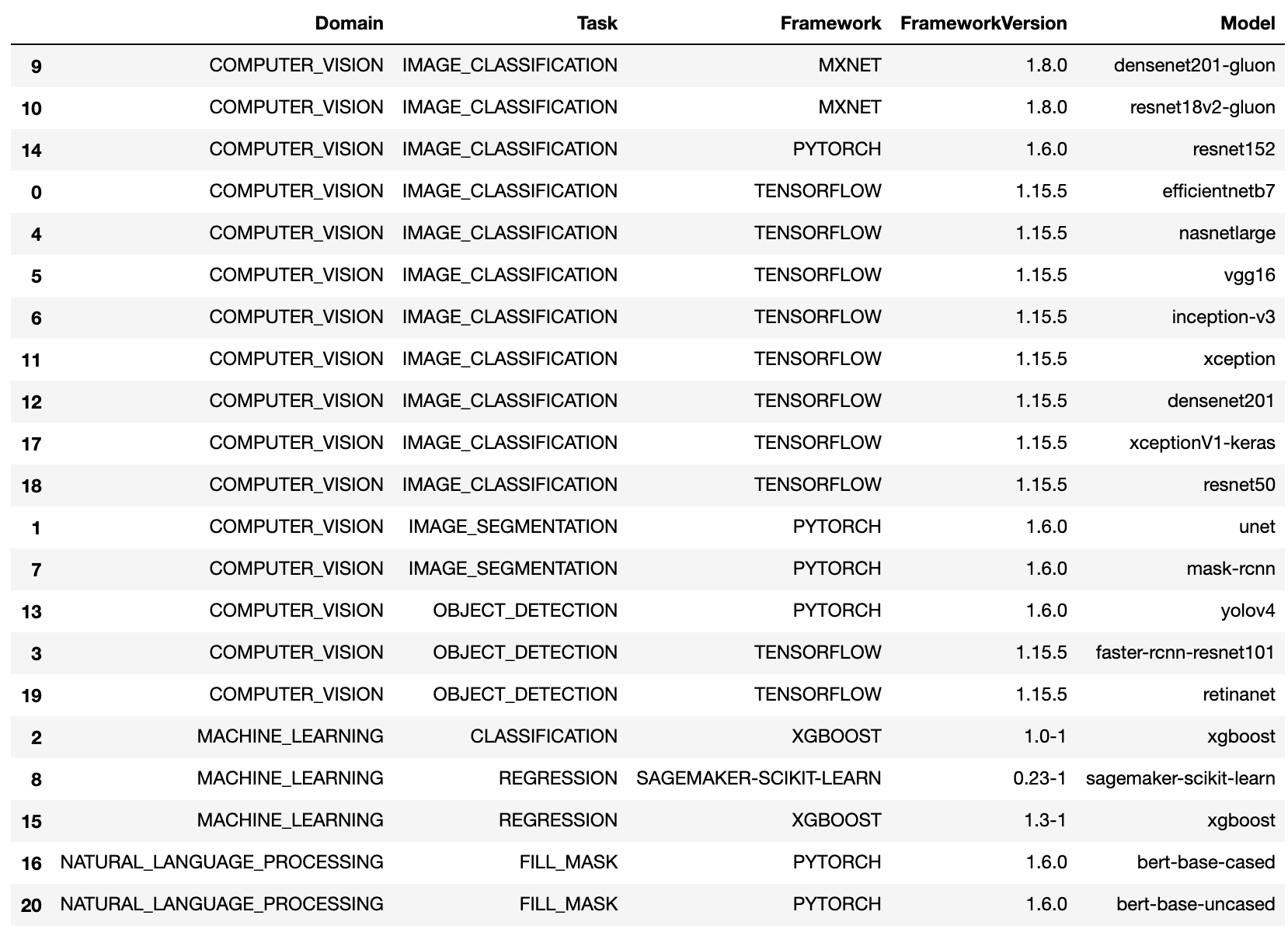
実際にどのような選択肢があるかは、list_model_metadata API を使って取得することができます。選択肢の中にデプロイしたいモデルそのものがない場合は、最も近そうなオプションを選べば OK です。サンプルは Tensorflow の ResNet50 なので、ドメインとして COMPUTER_VISION を、タスクとしてIMAGE_CLASSIFICATION を選択しています。
なお、2022年1月現在では、list_model_metadata API を実行すると以下のように表示されます。最新のフレームワークバージョンには対応していないようです。
コンテナの準備
Inference Recommender がテストに使用するコンテナイメージを指定する必要があります。サンプルでは、SageMaker ビルトインイメージの URI を取得しています。Amazon ECR にプッシュすれば自前のコンテナも使えそうです。
dlc_uri = image_uris.retrieve(
framework_name,
region,
version=framework_version,
py_version="py3",
instance_type=instance_type,
image_scope="inference",
)
モデルを Amazon SageMaker Model Registry に登録
Inference Recommender は、モデルが Amazon SageMaker Model Registry にパッケージとして登録されていることを前提としているようです。コンテナ、モデルの URL などを受け取るモデルパッケージバージョンでは、ドメイン、タスク、フレームワーク、フレームワークバージョン、NearestModelName、SamplePayloadUrlなどのモデルに関する情報を保存します。Model Registry に登録されている情報は、Amazon SageMaker Studio の UI か list_model_package_groups API を使って確認することができます。
SamplePayloadUrl と SupportedContentTypes は、必須パラメタです。また、より良いレコメンドのために、Domain, Task, Framework, FrameworkVersion, NearestModelName を指定するのが推奨されています。SupportedRealtimeInferenceInstanceTypes にはテストを実行したいインスタンスのリストを指定します。
Inference Recommender Default Job の起動
デフォルトジョブを起動してテストを実行します。デフォルトジョブを実行すると、おすすめのインスタンスタイプで負荷テストを実施した結果が出力されます。このジョブの実行に必要なのは、前の手順で Model Registry にモデルを登録した際の ModelPackageVersionArn だけでよく、結果は 1時間以内に返ってきます。
default_response = client.create_inference_recommendations_job(
JobName=str(default_job),
JobDescription="Job Description",
JobType="Default",
RoleArn=role,
InputConfig={"ModelPackageVersionArn": model_package_version_response["ModelPackageArn"]},
)
レコメンド内容の確認
デフォルトジョブの結果は以下のような JSON 形式で取得できます。サンプルでは重要な部分を抜き出して DataFrame に変換しています。
{
'JobName': 'job-name',
'JobDescription': 'job-description',
'JobType': 'Default',
'JobArn': 'arn:aws:sagemaker:region:account-id:inference-recommendations-job/resource-id',
'Status': 'COMPLETED',
'CreationTime': datetime.datetime(2021, 10, 26, 20, 4, 57, 627000, tzinfo=tzlocal()),
'LastModifiedTime': datetime.datetime(2021, 10, 26, 20, 25, 1, 997000, tzinfo=tzlocal()),
'InputConfig': {
'ModelPackageVersionArn': 'arn:aws:sagemaker:region:account-id:model-package/resource-id',
'JobDuration': 0
},
'InferenceRecommendations': [{
'Metrics': {
'CostPerHour': 0.20399999618530273,
'CostPerInference': 5.246913588052848e-06,
'MaximumInvocations': 648,
'ModelLatency': 263596
},
'EndpointConfiguration': {
'EndpointName': 'endpoint-name',
'VariantName': 'variant-name',
'InstanceType': 'ml.c5.xlarge',
'InitialInstanceCount': 1
},
'ModelConfiguration': {
'Compiled': False,
'EnvironmentParameters': []
}
},
{
'Metrics': {
'CostPerHour': 0.11500000208616257,
'CostPerInference': 2.92620870823157e-06,
'MaximumInvocations': 655, 'ModelLatency': 826019},
'EndpointConfiguration': {
'EndpointName': 'endpoint-name',
'VariantName': 'variant-name',
'InstanceType': 'ml.c5d.large',
'InitialInstanceCount': 1
},
'ModelConfiguration': {
'Compiled': False,
'EnvironmentParameters': []
}
},
{
'Metrics': {
'CostPerHour': 0.11500000208616257,
'CostPerInference': 3.3625731248321244e-06,
'MaximumInvocations': 570,
'ModelLatency': 1085446
},
'EndpointConfiguration': {
'EndpointName': 'endpoint-name',
'VariantName': 'variant-name',
'InstanceType': 'ml.m5.large',
'InitialInstanceCount': 1
},
'ModelConfiguration': {
'Compiled': False,
'EnvironmentParameters': []
}
}],
'ResponseMetadata': {
'RequestId': 'request-id',
'HTTPStatusCode': 200,
'HTTPHeaders': {
'x-amzn-requestid': 'x-amzn-requestid',
'content-type': 'content-type',
'content-length': '1685',
'date': 'Tue, 26 Oct 2021 20:31:10 GMT'
},
'RetryAttempts': 0
}
}
重要な部分のみを表示したのがこちらです。ベンチマーク結果やコスト情報が記録されています。この中から最もバランスが良いと思われる設定を選択すれば良いわけです。

カスタムロードテスト(Advanced Job の実行)
サンプルの最後に、本番環境の要件、インスタンスタイプの選択(最大 10個指定可能)、環境変数の調整、より広範な負荷テストの条件を指定して Advanced ジョブを実行しています。Advanced ジョブはトラフィックパターンやインスタンスタイプの数にもよりますが、デフォルトジョブよりも長い通常2時間程度かかります。
サンプルでは、環境変数 OMP_NUM_THREADS に [2、4] をセットしてエンドポイントをチューニングし、レイテンシー要件を100ミリ秒に制限しています。
以下の 2つのレコメンドを取得できました。OMP_NUM_THREADS=2 の方がコストが約半分で、パフォーマンスもそれほど低下していないのでよさそうな雰囲気がします。

まとめ
Amazon SageMaker Inference Recommender のサンプルノートブックを実行しながら、Inference Recommender がどんな機能なのかを確認しました。モデルと推論の入力データを Amazon S3 にアップロードし、モデルを Amazon SageMaker Model Registry にパッケージとして登録したのち、Default ジョブか Advanced ジョブを実行すればレコメンドを取得できることがわかりました。
どのインスタンスを使って推論エンドポイントを作れば良いのか、今使っているインスタンスが最適なのかを悩んでいる場合、Inference Recommender がお役に立つかもしれません。