はじめに
2021年の AWS re:Invent で Amazon SageMaker のリネージ機能 が進化したようなのですが、そもそもリネージ機能ってそんなのあったの!?と思ったのでサンプルノートブックを見ながら理解していこうと思います。ちなみに、このリネージ機能は クロスアカウントにも対応 しています。
サンプルノートブックは Amazon SageMaker Studio で実行しました。SageMaker Studio のセットアップ方法は こちらの記事 で紹介しています。
Amazon SageMaker Lineage とは
Amazon SageMaker Lineage は、データの準備からモデルのデプロイまでの機械学習ワークフローの各フェーズに関する情報を保存する機能です。この情報を使用して、ワークフローステップを再現し、モデルとデータセットの関係を特定して、モデルのガバナンスと監査標準を確立することができます。
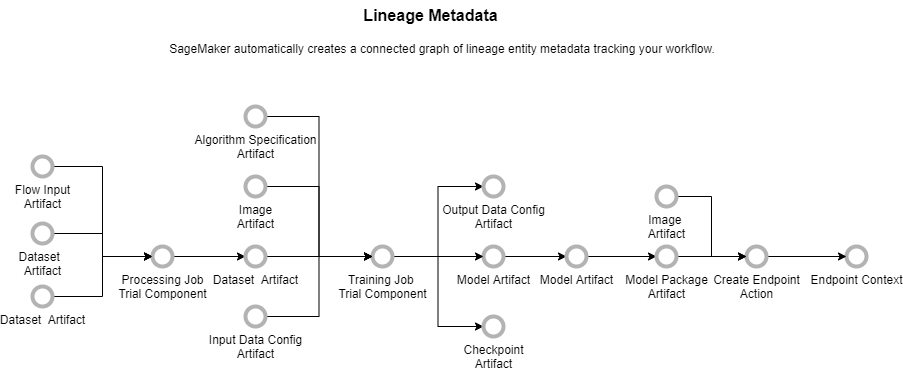
このリネージ機能に新たにクエリ機能が追加されたのですが、これは Amazon SageMaker 内で発生したイベントをグラフ構造で追跡できる機能です。この機能を使ってレポートを作成したり、モデルを比較したり、イベント間の関係性を探ったりが可能になります。たとえば、モデルがどう作成されてどこにデプロイされたかを簡単に知ることができます。
サンプルノートブックを見てみる
こちらのサンプルノートブック を見てみましょう。
このノートブックでは、Amazon SageMaker Lineage API を使用して、リネージグラフ全体のマルチホップ関係をクエリする方法を紹介しています。マルチホップ関係とは、モデル -> エンドポイント、学習ジョブ -> モデル のような直接の関係ではなくより広範囲の関係のことを言うようです。マルチホップクエリを使用すると、エンドポイント -> データセットのようなリネージグラフ全体における端っこ同士のような遠い関係を知ることができます。
ノートブックでは、まず Amazon SageMaker Experiments を使ってモデルを学習し、学習したモデルを Amazon SagMaker Model Registry に登録しています。さらに、登録したモデルを推論エンドポイントにデプロイして、リネージ機能を試す準備が完了です。
使用するライブラリはこちらです。リネージのコンポーネントとそれらをクエリするためのライブラリがあるようです。
from sagemaker.lineage.context import Context, EndpointContext
from sagemaker.lineage.action import Action
from sagemaker.lineage.association import Association
from sagemaker.lineage.artifact import Artifact, ModelArtifact, DatasetArtifact
from sagemaker.lineage.query import (
LineageQuery,
LineageFilter,
LineageSourceEnum,
LineageEntityEnum,
LineageQueryDirectionEnum,
)
次に LineageQuery と LineageFilter という 2つの API を使って、Lineage Graph を検索します。LineageQuery で使用するパラメタはこちらです。
-
start_arns: クエリの開始点として使われる ARN のリスト -
direction: クエリの方向 -
include_edges: True の場合、頂点だけでなくエッジも返す -
query_filter: クエリのフィルタ
LineageFilter で使用するパラメタはこちらです。
-
entities:LineageQueryの実行結果をフィルタする際のエンティティタイプ(Artifact, Association, Action)のリスト -
sources:LineageQueryの実行結果をフィルタする際のソースタイプ(Endpoint, Model, Dataset)のリスト
なお Context は SageMaker エンドポイントが作成される際に自動的に作成され、Artifact は SageMaker でモデルが作成される際に自動的に作成されます。
以下のコードでは、エンドポイントを開始点としてリネージをクエリしています。クエリフィルタとしてアーティファクトとデータセットを指定しています。
# Define the LineageFilter to look for entities of type `ARTIFACT` and the source of type `DATASET`.
query_filter = LineageFilter(
entities=[LineageEntityEnum.ARTIFACT], sources=[LineageSourceEnum.DATASET]
)
# Providing this `LineageFilter` to the `LineageQuery` will construct a query that traverses through the given context `endpoint_context`
# and find all datasets.
query_result = LineageQuery(sagemaker_session).query(
start_arns=[endpoint_context.context_arn],
query_filter=query_filter,
direction=LineageQueryDirectionEnum.ASCENDANTS,
include_edges=False,
)
# Parse through the query results to get the lineage objects corresponding to the datasets
dataset_artifacts = []
for vertex in query_result.vertices:
dataset_artifacts.append(vertex.to_lineage_object().source.source_uri)
pp.pprint(dataset_artifacts)
上記コードを実行すると、以下のように意図通りエンドポイントに関連するデータセットの情報を得ることができました。
['s3://sagemaker-us-east-1-<account-id>/experiments-demo/validation.csv',
's3://sagemaker-us-east-1-<account-id>/experiments-demo/train.csv']
それ以降のクエリではエンドポイントに関連するモデルや学習ジョブの Trial Component を検索しています。
以下のコードではクエリの開始点を変えて、モデルアーティファクトを起点として、関連するエンドポイントとデータセットを検索しています。ひとつ目の LineageQuery では direction に DESCENDANTS を設定することで モデル -> エンドポイント 方向のリネージを取得できるはずなのですが、出力されませんでした。BOTH を指定すると両方向のリネージを取得できるはずなのですが、やはりエンドポイントは取得できず。なぜだ。
query_filter = LineageFilter(
entities=[LineageEntityEnum.ARTIFACT],
sources=[LineageSourceEnum.ENDPOINT, LineageSourceEnum.DATASET],
)
query_result = LineageQuery(sagemaker_session).query(
start_arns=[model_artifact.artifact_arn], # Model is the starting artifact
query_filter=query_filter,
# Find all the entities that descend from the model, i.e. the endpoint
direction=LineageQueryDirectionEnum.DESCENDANTS,
include_edges=False,
)
associations = []
for vertex in query_result.vertices:
associations.append(vertex.to_lineage_object().source.source_uri)
query_result = LineageQuery(sagemaker_session).query(
start_arns=[model_artifact.artifact_arn], # Model is the starting artifact
query_filter=query_filter,
# Find all the entities that ascend from the model, i.e. the datasets
direction=LineageQueryDirectionEnum.ASCENDANTS,
include_edges=False,
)
for vertex in query_result.vertices:
associations.append(vertex.to_lineage_object().source.source_uri)
pp.pprint(associations)
ここで、direction に設定する ASCENDANTS と DESCENDANTS について確認しておきましょう。
例として、Dataset -> Training Job -> Model -> Endpoint のようなエンティティ関係グラフを考えたとき、エンドポイントはモデルの子孫であり、モデルはデータセットの子孫となります。同様に、モデルはエンドポイントの祖先です。 directionは、クエリが start_arns にあるエンティティの子孫と祖先のどちらを返すかを指定するために使用します。start_arns にモデルが設定され、direction が DESCENDANTS の場合、クエリはエンドポイントを返します。direction が ASCENDANTS の場合は、クエリはデータセットを返します。
SDK ヘルパー関数
リネージを検索するためにはここまで紹介してきた LineageQuery API を使う方法だけではなく、機能は限られますが、EndpointContext、ModelArtifact、DatasetArtifact クラスに用意されている、LineageQuery API のラッパーであるヘルパー関数を使う方法があります。
以下のコードを実行すると、EndpointContext を使って、エンドポイントに関連するデータセットと学習ジョブを取得しています。
# Find all the datasets associated with this endpoint
datasets = []
dataset_artifacts = endpoint_context.dataset_artifacts()
for dataset in dataset_artifacts:
datasets.append(dataset.source.source_uri)
print("Datasets : ", datasets)
# Find the training jobs associated with the endpoint
training_job_artifacts = endpoint_context.training_job_arns()
training_jobs = []
for training_job in training_job_artifacts:
training_jobs.append(training_job)
print("Training Jobs : ", training_jobs)
# Get the ARN for the pipeline execution associated with this endpoint (if any)
pipeline_executions = endpoint_context.pipeline_execution_arn()
if pipeline_executions:
for pipeline in pipelines_executions:
print(pipeline)
以下のコードは、ModelArtifact を使って、モデルに関連刷るデータセットとエンドポイントを取得しています。この方法だとモデルからエンドポイントを取得することができました。
# Here we use the `ModelArtifact` class to find all the datasets and endpoints associated with the model
dataset_artifacts = model_artifact.dataset_artifacts()
endpoint_contexts = model_artifact.endpoint_contexts()
datasets = [dataset.source.source_uri for dataset in dataset_artifacts]
endpoints = [endpoint.source.source_uri for endpoint in endpoint_contexts]
print("Datasets associated with this model : ")
pp.pprint(datasets)
print("Endpoints associated with this model : ")
pp.pprint(endpoints)
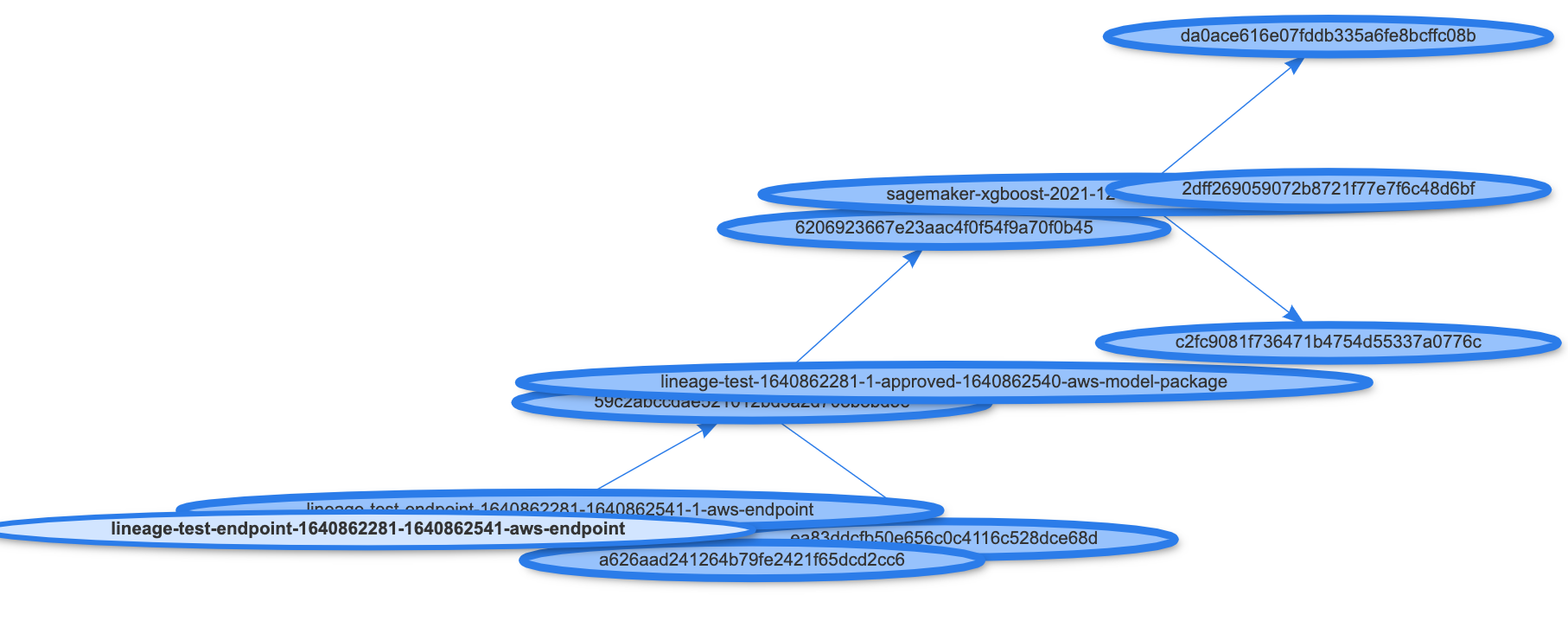
リネージグラフの可視化
サンプルで用意されている visualizer.py には、リネージグラフの可視化のためのヘルパークラス Visualizer() が用意されています。これにより StartArns からの系統関係を持つグラフが表示されます。query_lineage API をコールすることでStartArns からのリネージエンティティ関係が可視化されます。(ノードをドラッグできるのですが綺麗に並べ直すとかができず、ちょっと持てあまします。正しい見方があれば知りたい)
from visualizer import Visualizer
query_response = sm_client.query_lineage(
StartArns=[endpoint_context.context_arn], Direction="Ascendants", IncludeEdges=True
)
viz = Visualizer()
viz.render(query_response, "Endpoint")
まとめ
Amazon SageMaker Lineage を使って、モデルやエンドポイントなどを起点に、関連するアーティファクトや学習ジョブの情報を検索する方法をご紹介しました。この機能を使うとこのエンドポイントにはどのモデルがデプロイされていて、そのモデルはどのようなデータやアルゴリズムで作られたのかを一気に知ることができます。