Whisperとは
WhisperはOpenAIが公開している音声認識モデルであり、文字起こしに利用できる。これまで公開モデルを自前でデプロイする必要があったが、2023/9月にAzure OpenAI上においてはプレビュー公開され、APIとして利用することができるようになっている。文字起こしをした文章をChatGPT等のLLMと連携することで、音声による応答を行うこともできる。なお、Azure AIにはSpeech to Textという音声テキスト変換のモデルがあるが、Whisperの方が精度が高いと言われている。(AWSではAmazon Transcribe、GCPではGoogle Cloud Speech-to-Textが該当する)
Whisperモデルのデプロイ
Azure OpenAI Studioにてデプロイする。
なお、Whisperはプレビューにつき、2023/10時点では、米国中北部(North Central US)または西ヨーロッパ(West Europe)リージョンのみ。
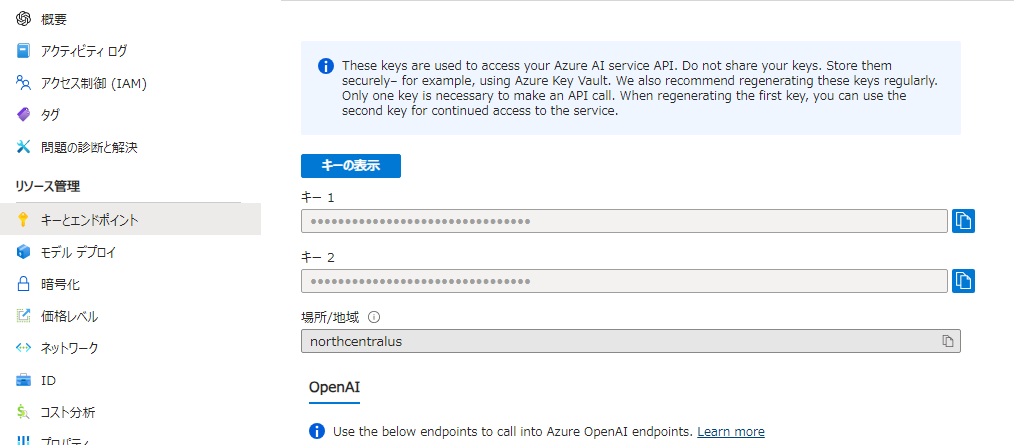
またAzure Portal上でキーとエンドポイントを控えておく。
利用
音声ファイルの用意
音声ファイルはWindows標準のボイスレコーダー等で録音したもの(.m4a)を使用した。

なお、こちらからAzure公式のサンプル音声ファイルを入手することもできる。
https://github.com/Azure-Samples/cognitive-services-speech-sdk/tree/master/sampledata/audiofiles
curl による利用
Azure公式のREST APIどおりであるが、以下のとおり。
curl 【エンドポイント】/openai/deployments/whisper/audio/transcriptions?api-version=2023-09-01-preview -H "api-key: 【キー】" -H "Content-Type: multipart/form-data" -F file="@./【ファイル名】"
実行結果
{'text': 'こんにちは。今日は10月28日。天気は晴れです。'}
python による利用
curlをそのままpythonのrequestsで実装しただけだが、requestsでは、"Content-Type": "multipart/form-data"は必要ない。requestsモジュールは、ファイルをfilesパラメーターとして提供すると自動的にContent-Typeを適切に設定する。(もしヘッダに設定してしまうと、レスポンスとしてエラー{'error': {'message': '', 'type': 'server_error', 'param': None, 'code': None}}が返ってくる。)
AZURE_OPENAI_KEY=""
AZURE_OPENAI_ENDPOINT="https://[].openai.azure.com"
FILE=""
import requests
url = AZURE_OPENAI_ENDPOINT + "/openai/deployments/whisper/audio/transcriptions?api-version=2023-09-01-preview"
headers = {
"api-key": AZURE_OPENAI_KEY,
}
# マルチパートエンコーディングとしてファイルを読み込み
with open(FILE, 'rb') as f:
file = {'file': (FILE, f)}
response = requests.post(url, headers=headers, files=file)
# レスポンスの表示
print(response.json())
実行結果
{'text': 'こんにちは。今日は10月28日。天気は晴れです。'}
注意
WhisperのAPI操作をするにあたって、Azure AIのSDK(Speech SDK)と間違えやすい。これはspeech to textのものであり、現時点ではWhisperの操作には使用できない。(マニュアルページがわかりづらい)
Azure OpenAI WhisperはREST APIしか正式に公開されていない。
https://learn.microsoft.com/ja-jp/azure/ai-services/openai/whisper-quickstart