はじめに
以前書いた記事の発展版。
RAGを各クラウドマネージドサービスごとにやってみる。CognitiveSearchとの比較のためVertexAI SearchとKendraをやっていくとして、今回はVertexAI Search。
Azure : Azure OpenAI + CognitiveSearch (ベース)
GCP : Palm2 + VertexAI Search 【←今回】
AWS : Bedrock + Kendra
(準備)
- VertexAI Search インデクス作成
- ファイルの準備、ドキュメントアップロード
- APIの権限(IAM)付与
(コード)
①質問からクエリ作成
②ドキュメント検索
③②をコンテキストとして質問から回答生成
なお、LLM(Palm2)モデル利用、認証設定などは上記、過去記事参照。
LiteLLMでのVertexAIのモデル定義
https://docs.litellm.ai/docs/providers/vertex
なお、chat-bison-32kとchat-bisonでは回答内容が結構違うので両方比較するのがよい。
VertexAI Search インデクス作成
VertexAI SearchはGCPのインデックスサービス(AzureのCognitive Searchに対応)。LLMと組み合わせたアプリを作ったりもできる。ひとまずRAGのretrieverとして最低限使えるレベルを目指す。
GCPコンソールの「検索と会話」→「データストア」からアクセス可能。
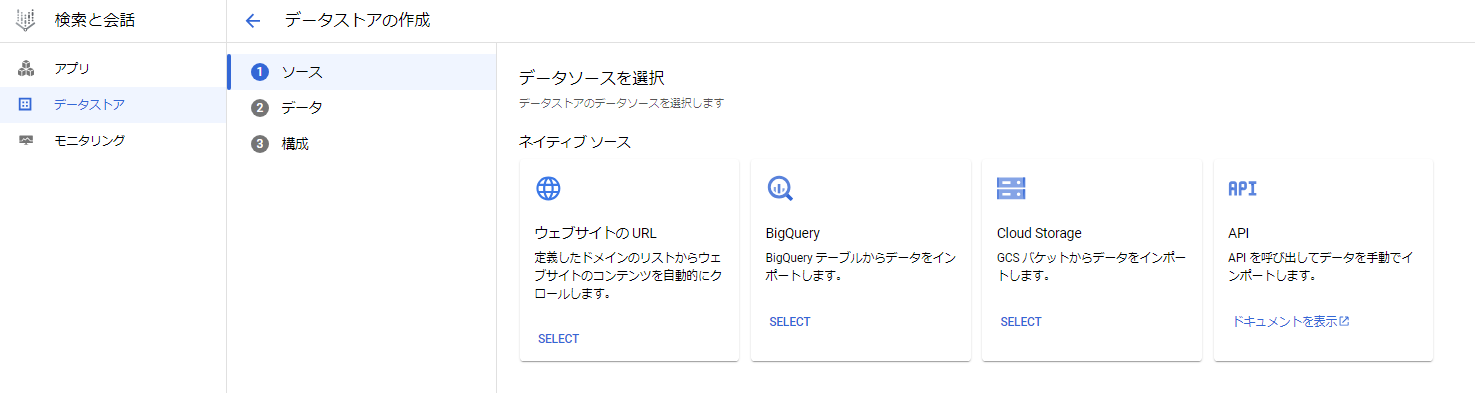
データストアの作成から、新規ドキュメントのインポートができる。
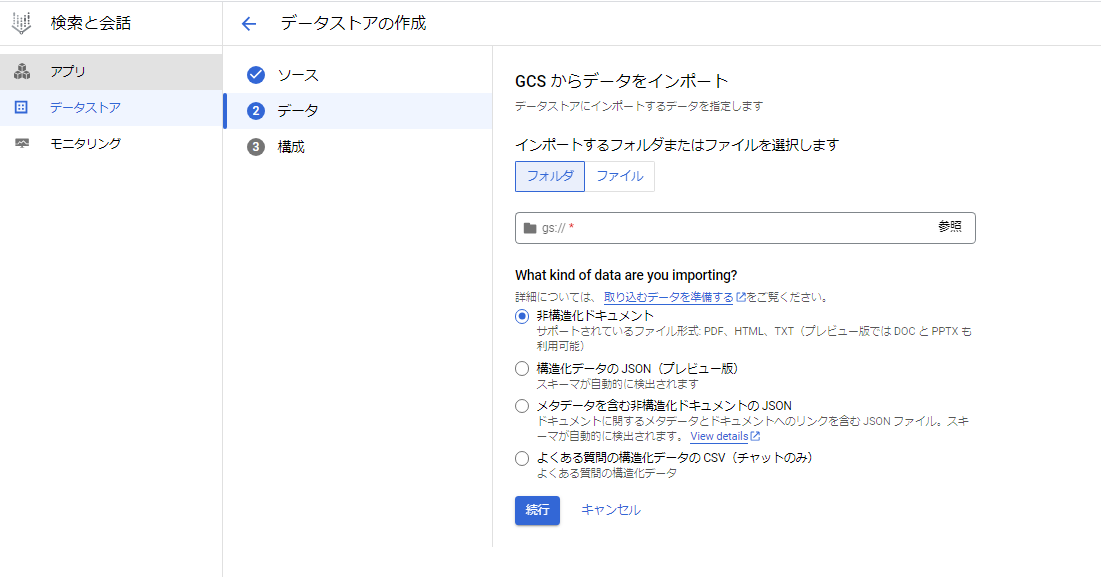
GCS(オブジェクトストレージ)から取り込む。
ファイルの準備
GCS上のバケット内に取り込むファイルとメタデータファイルを配置する。
メタデータはjsonファイルで作成する。
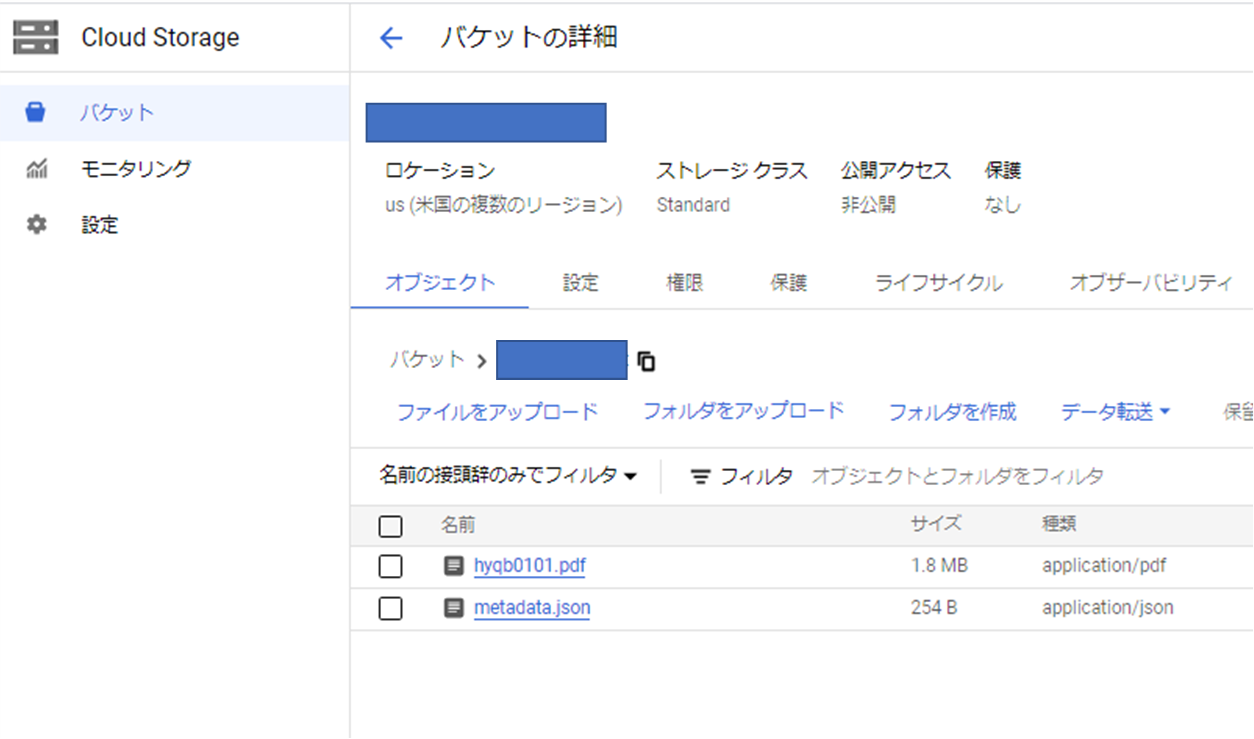
メタデータの形式例
メタデータの項目名は注意が必要。ソースファイルのリンクをLLMに扱わせたい場合には、「source」という項目名は予約されており、gs://~のgcsアドレスが自動で格納されるてしまうので使用せず、下記のように「sources」などと変えてURLを設定する。また取込で使用する実ファイルのパスを"uri":"gs://~"で設定する。
{"id":"doc-0","structData":{"title":"文書のタイトル","description":"","sources":"https://storage.cloud.google.com/<bucketname>/hyqb0101.pdf"},"content":{"mimeType":"application/pdf","uri":"gs://<bucketname>/hyqb0101.pdf"}}
取込
「ファイル」を選択し、メタデータ(json)のgcsパスを指定(gs://は省く)して、「メタデータを含む非構造化ドキュメントのJSON」を選択してインポートする。
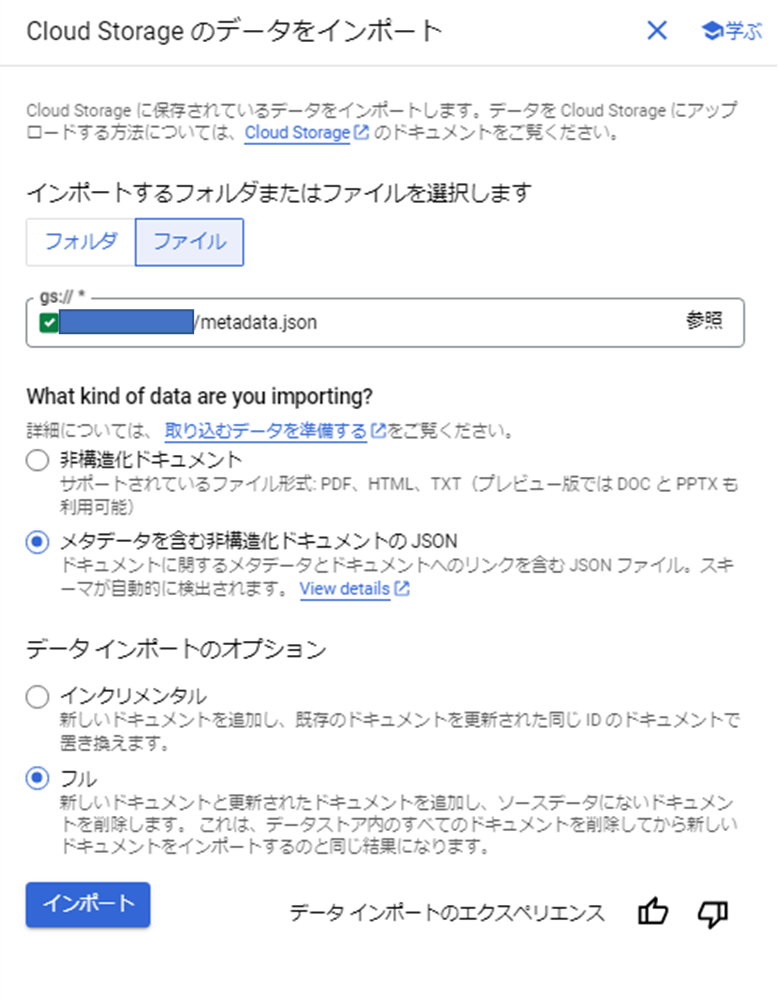
メタデータの場合、即座にインポート完了する。
データストアID、リージョン情報が表示されるので控えておく。
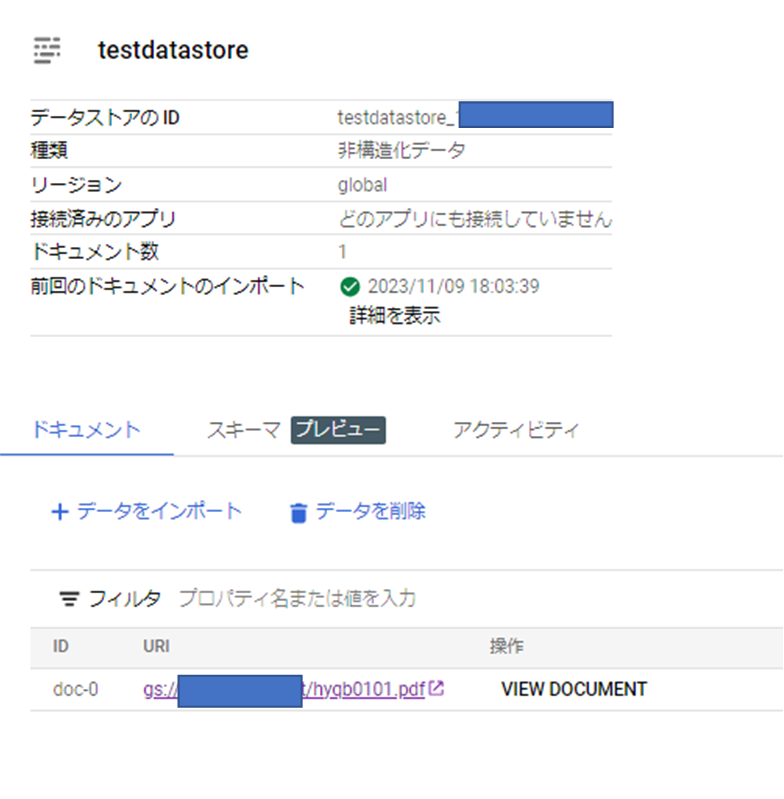
APIの権限(IAM)
APIでの利用権限を設定する必要がある。モデル利用のために作成したVertex AIユーザが割当たっているSAに「ディスカバリ エンジン サービス エージェント」のロールを付与する。
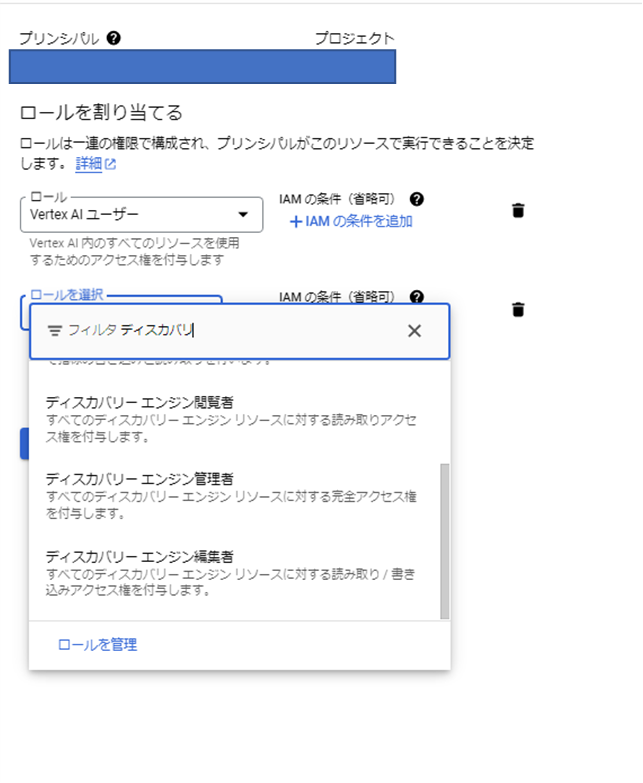
権限付与後のロール

コード作成
基本部分は過去記事参照。RAG部分について解説。
LangchainのVertexAI Search Retrieverを使用する。
VertexAI Search Retriever
https://python.langchain.com/docs/integrations/retrievers/google_vertex_ai_search
ライブラリインストール
pip install --upgrade pip
pip install google-cloud-aiplatform==1.36.0 google-cloud-discoveryengine==0.11.2 langchain==0.0.327 pydantic==1.10.8 typing-inspect==0.8.0 typing_extensions==4.5.0
モジュールインポート
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.retrievers import GoogleVertexAISearchRetriever
Retriever設定
わかりづらいのが以下。
extractive segment:抽出セグメント
extractive answers:抽出回答
抽出回答 (Extractive answers) は、検索結果から関連性が高い一部分を抜粋したものです。Google 検索でいうところの「強調スニペット」がこれにあたり、検索結果の中でも最も関連性が高いと思われるドキュメントの一部抜粋を最上部に表示しています。
抽出セグメント (Extractive segments) は、抽出回答よりさらに長く抜粋したもので、LLM にインプットして新たな回答文を生成する時などに用います。
参考
とのこと。一般的なRAGでのチャンクサイズ分割と比較したいので、抽出回答を使ってみる。
(抽出セグメントだと1つしか参照できないようなので。)
またVertexAI SearchのAPI設定を入れる。
# VertexAI Search
retriever = GoogleVertexAISearchRetriever(
project_id="",
location_id="global",
data_store_id="",
get_extractive_answers=True,
max_extractive_segment_count=1,
max_extractive_answer_count=3,
)
ここは詳細は割愛するが、まず質問からクエリ作成する。
LLMにプロンプトで指示をし、クエリ(キーワード)化。
(”与えられたテキストから質問部分だけを抜き出し、さらにそこからキーフレーズを抽出してキーフレーズのみを返してください。”のようなプロンプト指示。)
maketag_chain = LLMChain(llm=llm, prompt=maketag_PROMPT)
keyword = maketag_chain(messages)
レスポンスがMultiCandidateTextGenerationResponse型で返るため、Stringで受け取り、text=部分を抽出する。(ここはChatGPTに聞いたコードをそのまま使った)
※Azure OpenAI / Bedrockと異なってめんどくさいところ。回避策ありそうだが、ひとまず泥臭く。
keyword_str = keyword['text']
keyword_matched = re.search(r"text='(.*?)',", keyword_str)
keyword_extracted_text = keyword_matched.group(1)
VertexAI Searchへの検索部分。
get_relavant_documentsでクエリ実行し、結果(参照ドキュメント)を取得。
vsr=retriever.get_relevant_documents(keyword_extracted_text)
取得した内容をあらかじめ設定のプロンプトテンプレートにcontextとして埋め込み、質問回答生成の
クエリをPalm2に投げる。結果は上記と同じくパースするとともに、streamlit表示用に改行コードを変換してタグ表示。(Azure OpenAIやAWS Bedrockだとやはりこれも不要。Palm2だけ少し特殊。)
llm_chain = LLMChain(prompt=PROMPT,llm=llm,verbose=True)
response = llm_chain({"context": vsr, "question": messages} )
content_str = response['text']
matched = re.search(r"text='(.*?)',", content_str)
extracted_text = matched.group(1)
formatted_text = extracted_text.replace("\\n", " <br/> ")
st.markdown(formatted_text, unsafe_allow_html=True)
なお、RetrievalQAWithSourcesChainを使う場合はこんな感じ。こちらだとレスポンスのsourcesにgs://~~のアドレスが入ってくる。
retrieval_qa_with_sources = RetrievalQAWithSourcesChain.from_chain_type(
llm=Palm2_llm, chain_type="stuff", retriever=retriever
)
retrieval_qa_with_sources({"question": text})
以上でVertexAI SearchをRAGのretrieverとして利用して、ドキュメントからPalm2に回答をさせることができる。
参考