プロンプトエンジニアリングに関する論文のまとめ
論文を読む機会
IcL,One Shot/Few Shot, CoTなどの基本的なプロンプトエンジニアリング手法に続き、たくさんの手法が研究・発表されている。自分はITエンジニアながら、これまであまり論文そのものを読む機会がなかったが、AIに携わるようになってからは何かとarxiv論文ソースを目にするようになり徐々に参照する機会も増えてきた。英語の論文をDeepL翻訳を駆使して読むのもいいのだが、なかなかしんどいので、後述のgpt-4を駆使した要約・翻訳で概要を理解し、必要に応じて深掘りというアプローチで乗り切っていこうと思う。
gpt-4要約
要約についてはカスタムエージェントにて、論文PDFファイルの取得&テキスト抽出を行い、splitterで5000トークン分割して最初の5000トークンを要約させている。
カスタムエージェントの作成方法の過去記事
https://qiita.com/marimo0825/items/2d60ed5742a042522bf8
Streamlitの要約画面アプリ作成方法の過去記事
https://qiita.com/marimo0825/items/0bdde81c0bd343b84d15
カスタムエージェント部
from langchain.tools import BaseTool
import requests
import io
from PyPDF2 import PdfReader
from langchain.text_splitter import TokenTextSplitter
class getPDFTextTool(BaseTool):
name = "getPDFTextTool"
description = "use this tool when you need to download PDF and extract text data."
def _run(self, url: str):
response = requests.get(url)
file = io.BytesIO(response.content)
file.seek(0) # Ensure you're at the start of the file.
pdf = PdfReader(file)
text = ""
for page in pdf.pages:
text += page.extract_text()
text_splitter = TokenTextSplitter(chunk_size=5000, chunk_overlap=100)
texts = text_splitter.split_text(text)
return(texts[0])
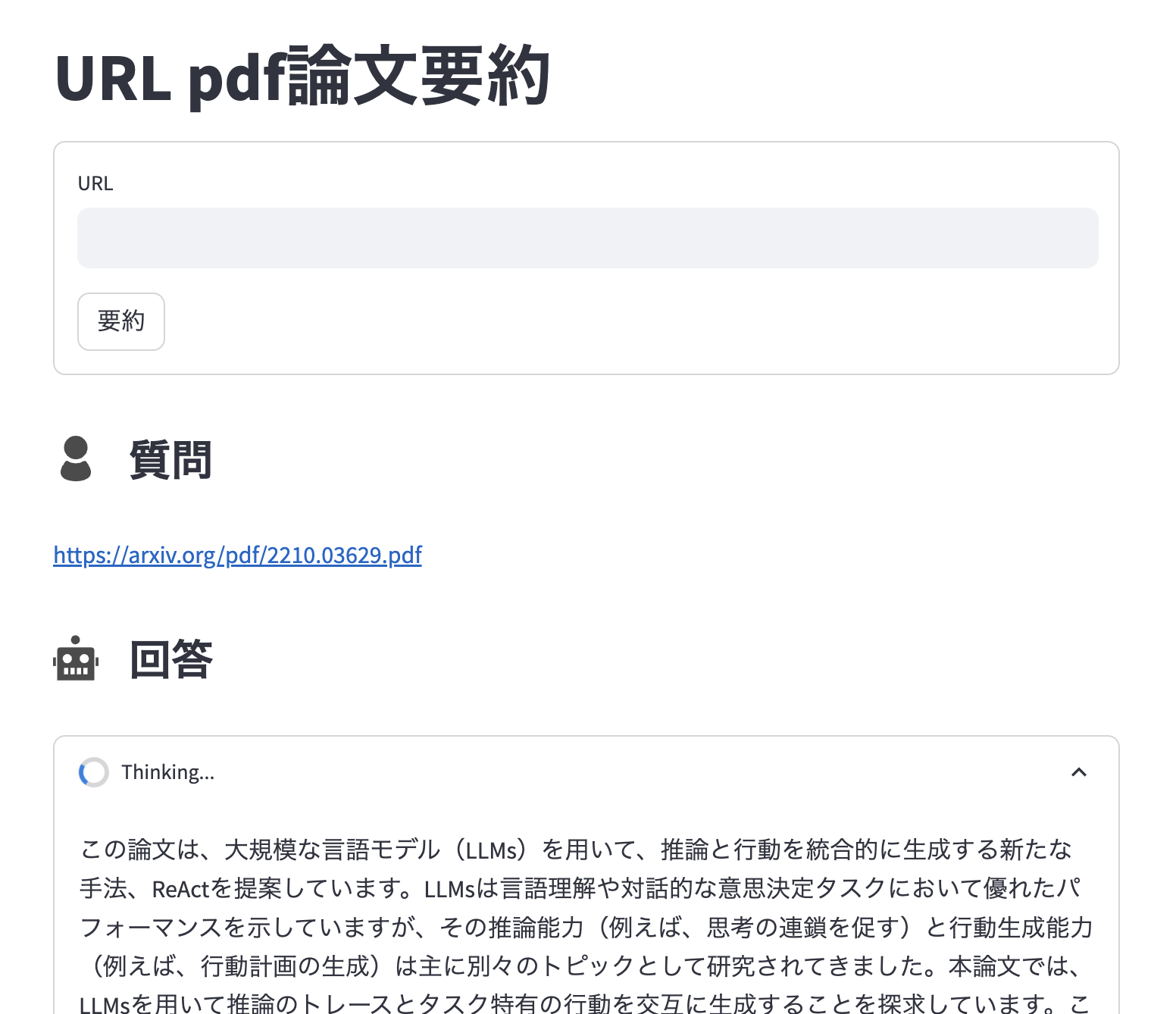
画面処理部(抜粋)
# Streamlit(画面処理)
st.title("URL pdf論文要約")
with st.form("my_form", clear_on_submit=True):
text = st.text_input("URL")
submitted = st.form_submit_button("要約")
if submitted:
try:
st.write("")
st.write(text)
st.write("")
with st.spinner("考え中..."):
llm = AzureChatOpenAI(
temperature=0,
deployment_name=os.environ["AZURE_DEPLOYMENT_ID"],
openai_api_base=os.environ["OPENAI_API_HOST"],
openai_api_version=os.environ["OPENAI_API_VERSION"],
openai_api_key=os.environ["OPENAI_API_KEY"],
openai_api_type="azure",
streaming=True,
max_tokens=2000,
callback_manager=BaseCallbackManager(
[StreamlitCallbackHandler(st.container())],
),
)
tools = [
getPDFTextTool(),
]
# エージェントの準備
agent = initialize_agent(
tools,
llm,
agent=AgentType.OPENAI_FUNCTIONS,
verbose=True,
return_intermediate_steps=True)
# プロンプト
text = '''このURLの論文のPDFを、取得して、日本語で要約して。
URL:
''' + text
response = agent({"input": text})
画面イメージ
プロンプトエンジニアリング論文(適宜追記予定)
ReAct (Reasoning + Acting)
https://arxiv.org/pdf/2210.03629.pdf

(gpt-4要約)
この論文は、大規模な言語モデル(LLMs)が理解と対話的な意思決定のタスクで印象的なパフォーマンスを示している一方で、その推論(例えば、思考の連鎖的なプロンプト)と行動(例えば、行動計画の生成)の能力が主に別々のトピックとして研究されてきたことに注目しています。この論文では、LLMsを使用して、推論のトレースとタスク固有の行動を交互に生成することを探求しています。これにより、推論のトレースが行動計画を誘導、追跡、更新し、例外を処理するのを助け、行動が知識ベースや環境などの外部ソースから追加情報を収集するのを可能にします。
このアプローチはReActと名付けられ、言語と意思決定のタスクの多様なセットに適用され、既存の最先端のベースラインを超える効果を示し、人間の解釈可能性と信頼性を向上させています。具体的には、質問応答(HotpotQA)と事実検証(Fever)において、ReActは、シンプルなWikipedia APIと対話し、人間のようなタスク解決の軌跡を生成することで、連鎖的な思考の推論における幻覚とエラーの伝播の問題を克服します。
さらに、二つの対話型意思決定ベンチマーク(ALFWorldとWebShop)において、ReActは、一つまたは二つの文脈内の例だけで、模倣学習と強化学習の方法を絶対的な成功率で34%と10%上回ります。
chatDev
https://arxiv.org/pdf/2307.07924.pdf

(gpt-4要約)
この論文は、ソフトウェア開発プロセス全体を通じて大規模言語モデル(LLM)を活用する革新的なパラダイムを提案しています。このパラダイムの中心には、CHATDEVという仮想のチャット駆動型ソフトウェア開発会社があります。CHATDEVは、設計、コーディング、テスト、ドキュメンテーションという4つの明確な段階に開発プロセスを分割します。各段階では、プログラマーやコードレビュアー、テストエンジニアなどのチームが参加し、協力的な対話を通じてシームレスなワークフローを促進します。チャットチェーンは、各段階を原子的なサブタスクに分解する役割を果たし、提案と検証の両方の役割を果たすことができます。CHATDEVの分析では、ソフトウェア生成におけるその効果的な性能が強調されており、全ソフトウェア開発プロセスを7分以内に完了し、1ドル未満のコストで行うことができます。また、潜在的な脆弱性を特定し、解消するだけでなく、効率とコスト効果の高さを維持しながら潜在的な幻覚を修正することもできます。CHATDEVの可能性は、ソフトウェア開発の領域にLLMを統合する新たな可能性を示しています。
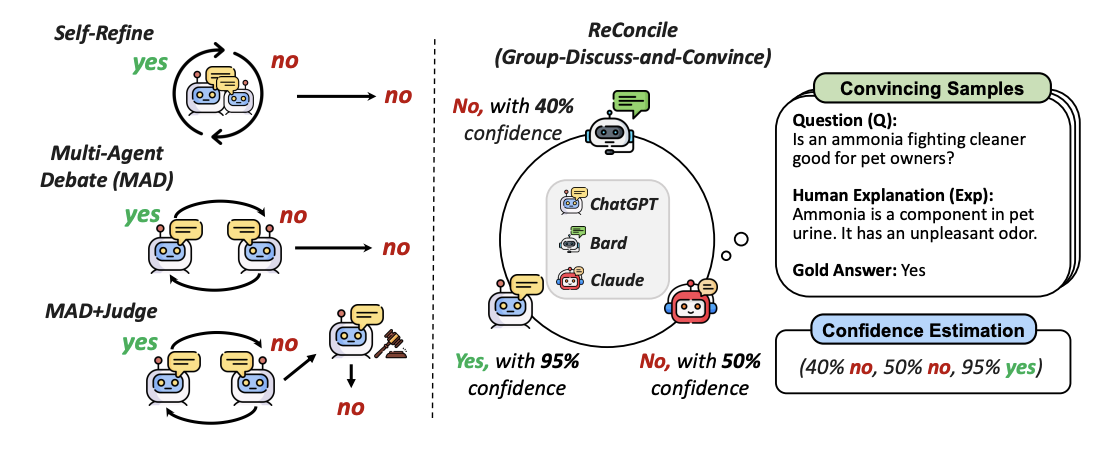
RECONCILE
多様なエージェント間での討論プロセスを設計したマルチエージェントフレームワーク
https://arxiv.org/pdf/2309.13007.pdf
(gpt-4要約)
この論文は、複雑な推論タスクに対する大規模言語モデル(LLM)の能力を向上させるための新しいフレームワーク、RECONCILEを提案しています。RECONCILEは、異なるLLMエージェント間でのラウンドテーブル会議として設計され、多様な思考と議論を促進し、より良い合意を形成します。
RECONCILEは、複数の議論ラウンドを開催し、他のエージェントを説得して回答を改善し、信頼度に基づいた投票メカニズムを使用してLLMの推論能力を強化します。各ラウンドでは、RECONCILEは「議論のプロンプト」を通じてエージェント間の議論を開始します。これは、前回のラウンドで各エージェントが生成したグループ化された回答と説明、その不確実性、そして他のエージェントを説得するために使用される回答修正の人間の説明のデモンストレーションから構成されます。この議論のプロンプトにより、各エージェントは他のエージェントからの洞察を考慮して自身の回答を修正することができます。
合意が形成され、議論が終了したら、RECONCILEは各エージェントの信頼度を利用して最終的な回答を決定します。RECONCILEは、ChatGPT、Bard、Claude2という3つのエージェントで実装されています。
実験結果は、RECONCILEがエージェント(個々にもチーム全体としても)の推論パフォーマンスを大幅に向上させ、既存の単一エージェントやマルチエージェントのベースラインを上回ることを示しています。また、一部のデータセットではGPT-4を上回る結果も得られました。さらに、GPT-4自体をRECONCILEのエージェントの一部として実験し、その初期パフォーマンスも他のエージェントからの議論とフィードバックを通じて絶対的に10.0%向上することを示しました。
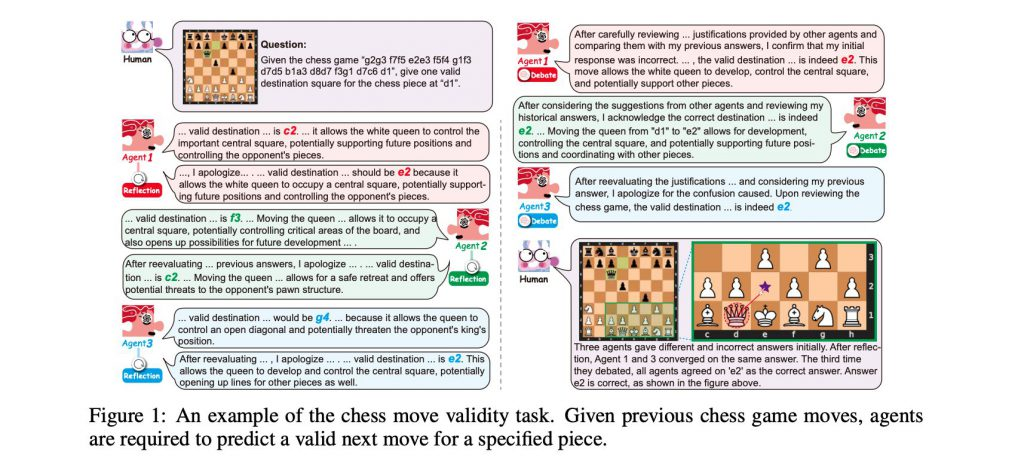
協調戦略
https://arxiv.org/pdf/2310.02124.pdf
(gpt-4要約)
この論文は、複数の大規模言語モデル(LLM)からなるマルチエージェント社会における協調的な知能を、NLPシステムが模倣できるかどうかを探求しています。具体的には、4つのユニークな「社会」を作り出し、各エージェントは特定の「特性」(寛大または過信)を持ち、異なる「思考パターン」(討論または反省)で協力します。これらのマルチエージェント社会を3つのベンチマークデータセットで評価することで、LLMエージェントがタスクを遂行するために様々な社会的行動を利用していることが明らかになりました。特に、一部の協力戦略は効率を最適化するだけでなく、以前のトップレベルのアプローチを上回る結果をもたらしました。また、LLMエージェントが人間のような社会的行動、例えば一致性や多数決の原則を示すことが、社会心理学の基本的な理論を反映していることが示されました。この研究は、LLMエージェントの協力を文脈化し、LLMのための協力メカニズムのさらなる調査を促すために、社会心理学からの洞察を統合します。
Self-Consistency(自己整合性)
大量のFew-Shot CoT プロンプティングで学習させることで、高い精度の結果が得られるようにする手法。
https://book.st-hakky.com/docs/llm-prompt-engineering-self-consistency/
https://www.promptingguide.ai/jp/techniques/consistency
https://arxiv.org/pdf/2203.11171.pdf
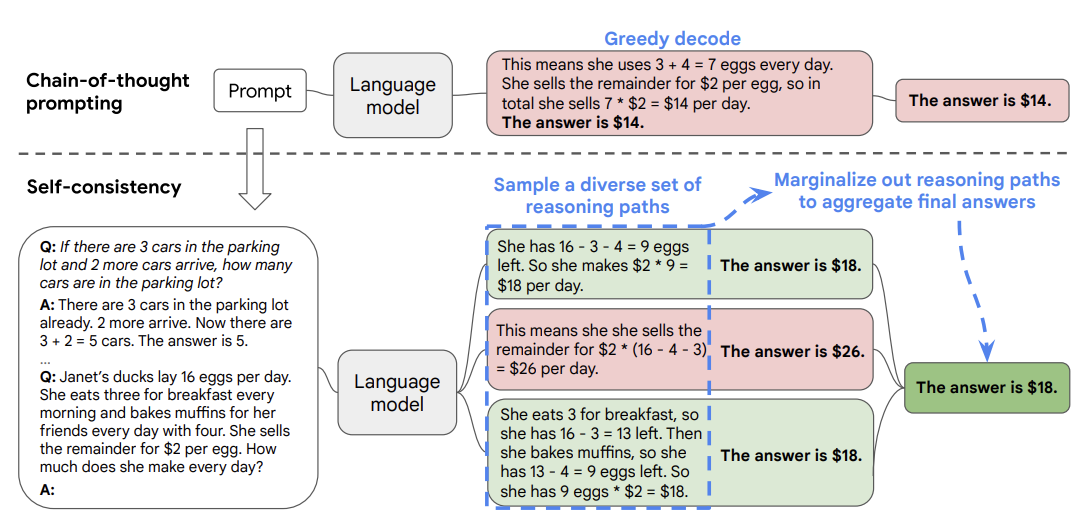
(gpt-4要約)
この論文は、言語モデルにおける複雑な推論タスクのパフォーマンスを向上させる新しいデコーディング戦略、自己一貫性(self-consistency)を提案しています。これは、既存の貪欲なデコーディングを置き換えるもので、まず、貪欲なパスだけを取るのではなく、多様な推論パスをサンプリングし、その後、サンプリングされた推論パスをマージナライズして最も一貫性のある答えを選択します。
自己一貫性は、複雑な推論問題が通常、その一意の正解に至る複数の異なる思考方法を許容するという直感を利用します。広範な実証評価では、自己一貫性が一連の人気の算数と常識推論ベンチマークで、思考の連鎖のプロンプトのパフォーマンスを大幅に向上させることを示しています。
この手法は、追加の検証器を訓練するか、生成品質を向上させるために追加の人間の注釈を与えて再ランキングを訓練するといった従来のアプローチよりもはるかに単純です。自己一貫性は完全に教師なしで、事前訓練された言語モデルとそのまま動作し、追加の人間の注釈や追加の訓練、補助モデル、微調整を必要としません。
自己一貫性は、複数のモデルを訓練し、各モデルからの出力を集約する典型的なアンサンブルアプローチとは異なり、単一の言語モデルの上で動作する「自己アンサンブル」のようなものです。
自己一貫性は、幅広い範囲の算数と常識推論タスクにおいて、すべての言語モデルで思考の連鎖のプロンプトを大幅に改善します。特に、PaLM-540BやGPT-3と組み合わせると、自己一貫性は算数推論タスクにおいて新たな最先端のパフォーマンスを達成します。
LogiCoT
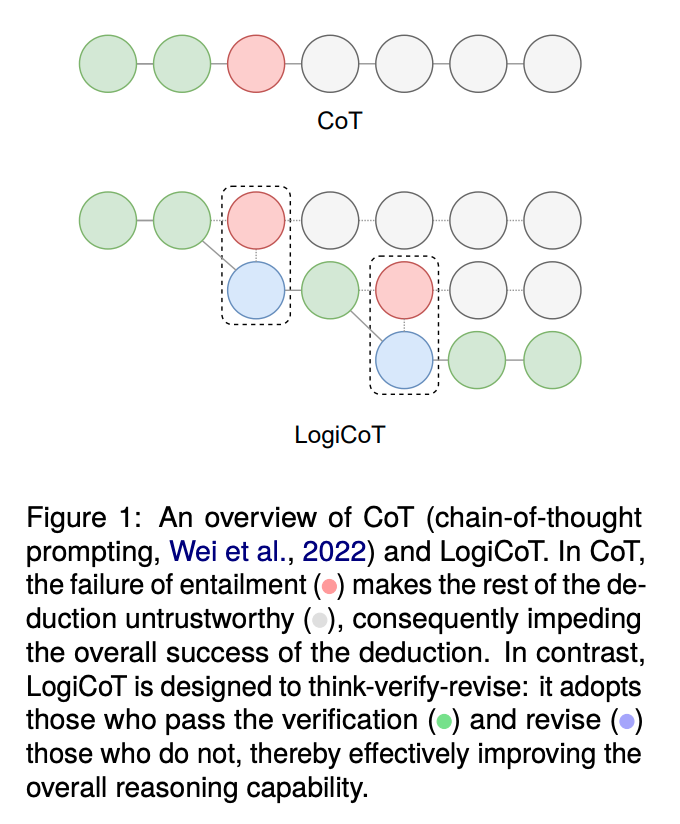
※うまく要約できないため、手動でConclusionを要約。
大規模言語モデル(LLMs)は、一般的な知識や専門的な知識が必要な分野で優れた能力を示していますが、多段階の推論能力の向上の余地はまだ大きいです。本研究では、新しいフレームワークであるLogiCoTを提唱しています。これは、否定法(reductio ad absurdum)の原理を利用して、シンボリックロジックの視点から開発された考える-検証する-修正するという手法です。多数の実験から、ゼロショット連鎖思考法(CoT)をLogiCoTで補強することで、モデルの推論能力が大幅に向上することが特に大規模なモデルで確認されました。このアプローチは、異なる言語タスクと領域で成功裏に試験されています。
Chain-of-Verification(CoVe)
"CHAIN-OF-VERIFICATION REDUCES HALLUCINATION IN LARGE LANGUAGE MODELS"
https://arxiv.org/pdf/2309.11495.pdf
モデルは初めに回答のドラフトを生成、その後回答が事実に基づいているかどうかを検証するための質問を計画。次に、それらの質問に独立して回答し、最終的な検証済みの回答を生成。

(gpt-4要約)
この論文は、大規模な言語モデルにおける「幻覚」(事実上誤った情報を生成する現象)を減らすための新しい手法、Chain-of-Verification (CoVe) を提案しています。CoVeの手法は以下の4つのステップで構成されています。
初期の回答を生成する
その回答を事実検証するための質問を計画する
それらの質問に独立して回答する(他の回答に影響されないように)
最終的な検証済みの回答を生成する
この手法は、一連の検証問題を生成し、それらに答えることで、元の回答の誤りを修正することを可能にします。実験では、CoVeがさまざまなタスクで幻覚を減らすことを示しています。これらのタスクには、Wikidataからのリストベースの質問、閉じた本のMultiSpanQA、および長文のテキスト生成が含まれます。
この研究は、言語モデルが自己検証を行うことで、その生成物の正確性を向上させる可能性を示しています。
Optimization by PROmpting(OPRO)
Take a deep breath
"LARGE LANGUAGE MODELS AS OPTIMIZERS"
https://arxiv.org/pdf/2309.03409.pdf
LLMを利用した新たな最適化手法「Optimization by PROmpting(OPRO)」
自然言語で最適化タスクを説明し、LLMが前回生成した解とその値を含むプロンプトから新しい解を生成。得られた新たな解を評価し、次の最適化ステップのためのプロンプトに追加。この手法を線形回帰や巡回セールスマン問題に適用し、その後、タスクの精度を最大化する指示を見つけるためのプロンプト最適化をする。
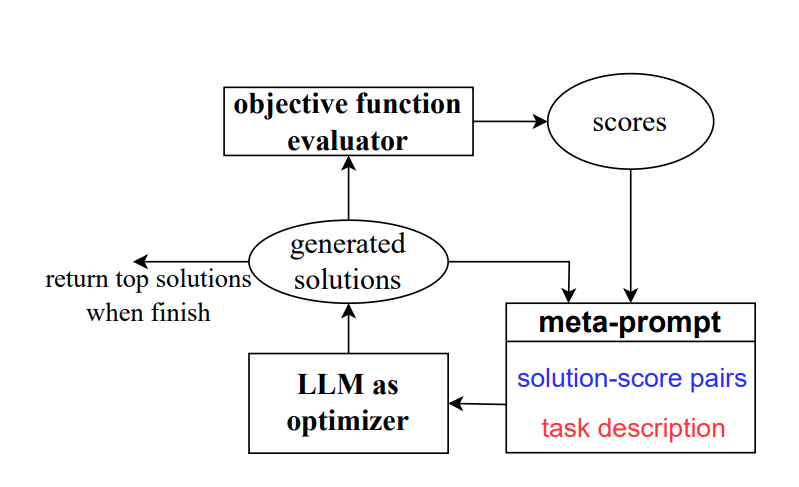
(gpt-4要約)
この論文は、大規模言語モデル(LLM)を最適化ツールとして利用する新たなアプローチ、OPRO(Optimization by PROmpting)を提案しています。このアプローチでは、最適化タスクが自然言語で記述され、各最適化ステップでLLMが以前に生成した解とその値を含むプロンプトから新たな解を生成します。新たな解は評価され、次の最適化ステップのためのプロンプトに追加されます。
この研究では、まず線形回帰と巡回セールスマン問題に対するOPROの効果を示し、次にプロンプト最適化(指示を見つけることが目標)に移ります。さまざまなLLMを用いて、OPROによって最適化された最良のプロンプトが、人間が設計したプロンプトを最大8%(GSM8Kで)および最大50%(Big-Bench Hardタスクで)上回ることを示しています。
つまり、この研究は、大規模言語モデルを用いて最適化問題を解決する新たな方法を提案しており、その結果、人間が設計したプロンプトよりも優れた結果を得ることができることを示しています。
ステップバックプロンプティング
"TAKE A STEP BACK: EVOKING REASONING VIA ABSTRACTION IN LARGE LANGUAGE MODELS"
https://arxiv.org/pdf/2310.06117.pdf

(gpt-4要約)
この論文は、大規模言語モデル(LLM)における抽象化を通じた推論能力の向上について述べています。具体的には、STEP-BACK PROMPTINGという新しい手法を提案しています。この手法は、特定の詳細を含むインスタンスから高レベルの概念や原則を導き出すための抽象化をLLMに可能にします。これらの概念と原則を用いて推論のステップをガイドすることで、LLMは解答への正しい推論パスをたどる能力を大幅に向上させます。
STEP-BACK PROMPTINGは、PaLM-2Lモデルとともに、STEM(科学、技術、工学、数学)、Knowledge QA(知識質問応答)、Multi-Hop Reasoning(多段階推論)など、推論が重要なタスクに対する実験を行いました。その結果、MMLU PhysicsとChemistryでそれぞれ7%と11%、TimeQAで27%、MuSiQueで7%のパフォーマンス向上が見られました。
この手法は、抽象化という認知スキルを用いて、大量の情報を処理し、一般的なルールや原則を導き出す能力を模倣しています。具体的には、LLMが具体的な詳細を含む複雑なタスクを解決するために、抽象化と推論の2段階のプロセスを通じてこれを行う方法を探求しています。まず、LLMにステップバックして、特定の例から高レベルの抽象化、つまり概念や原則を導き出すことを教えます。次に、高レベルの概念と原則に基づいて解答を導き出す推論能力を活用します。
この研究は、大規模言語モデルが複雑なタスクを解決するための新たなアプローチを提供しており、その結果は、教育、科学、技術などの分野での応用に対する可能性を示しています。
2023.10.24追記
グラウンディング(GLAM)
Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning
https://arxiv.org/pdf/2302.02662.pdf
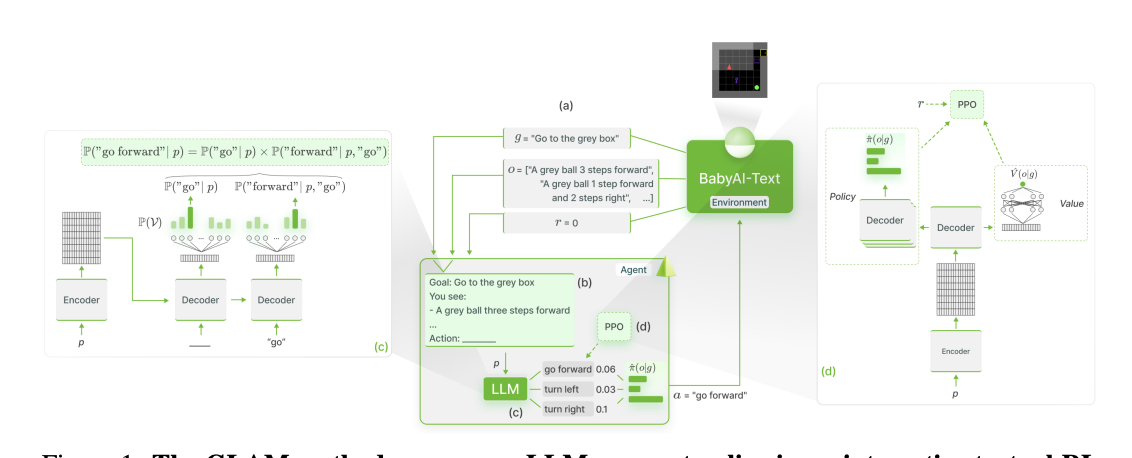
(gpt-4要約)
この論文では、大規模な言語モデル(LLM)を対話型環境での意思決定問題の解決に利用する方法を提案しています。LLMは、世界の物理的な知識を抽象的に捉える能力を持っていますが、LLMの知識と環境との間の整合性が欠けていると、機能的な能力が制限されることがあります。この論文では、この整合性を達成するためのアプローチ(GLAMと名付けられた)を研究しています。
GLAMでは、LLMをポリシーとして使用するエージェントを考え、エージェントが環境と対話することでLLMが逐次的に更新され、オンラインの強化学習を利用して目標を解決するためのパフォーマンスを向上させます。対話的なテキスト環境を使用して、より高次の機能的な接地を研究し、空間的なナビゲーションタスクのセットを使用して、いくつかの科学的な問題を研究します。
LLMは、さまざまなRLタスクのオンライン学習のサンプル効率を向上させることができるか?
それはどのようにして異なる形の一般化を向上させることができるか?
オンライン学習の影響は何か?
これらの問いに答えるために、著者たちはいくつかのバリエーション(サイズ、アーキテクチャ)のFLAN-T5を機能的に接地させ、その結果を研究しています。
Recursive Criticizes and Improves (RCI)
Language Models can Solve Computer Tasks
https://arxiv.org/pdf/2303.17491.pdf

(gpt-4要約)
この論文は、一般的なコンピュータタスクを実行する能力を持つエージェントの開発について述べています。これらのエージェントは、反復的なタスクの自動化や複雑な問題解決の支援により、効率と生産性を向上させることができます。理想的には、これらのエージェントは、自然言語のコマンドを通じて新しいコンピュータタスクを解決することができるべきです。しかし、この問題への従来のアプローチは、専門家のデモンストレーションやタスク固有の報酬関数といった大量のリソースを必要としていました。
この研究では、事前に訓練された大規模な言語モデル(LLM)エージェントが、自然言語を用いてコンピュータタスクを実行することができることを示しています。これは、エージェントが自身の出力を再帰的に批判し改善する(RCI)というシンプルなプロンプト方式を使用しています。RCIアプローチは、コンピュータタスクの自動化において既存のLLM手法を大幅に上回り、MiniWoB++ベンチマークにおいては、教師あり学習(SL)や強化学習(RL)のアプローチを上回ります。
また、RCIプロンプトは、自然言語推論タスクにおけるLLMの推論能力を強化する効果も示しています。RCIとCoT(Chain of Thought)の組み合わせは、それぞれ単独よりも優れたパフォーマンスを発揮します。
要約すると、この研究は、自然言語をガイドにしてコンピュータタスクを実行するLLMエージェントを可能にする新しい強力で実用的なアプローチを提供しています。RCIプロンプト方式は、コンピュータタスクにおける既存の手法を上回るだけでなく、LLMの推論能力を広範に改善することで、インテリジェントエージェントの開発における重要な貢献を果たしています。
「一時停止トークン」
Think before you speak:
Training Language Models With Pause Tokens
https://arxiv.org/pdf/2310.02226.pdf
(gpt-4要約)
この論文は、言語モデルのトレーニングにおいて「一時停止トークン」を使用する新たな手法を提案しています。通常、言語モデルは連続したトークンを生成しますが、この研究では、モデルが次のトークンを出力する前に一定数の隠れベクトルを操作できるように、入力プレフィックスに一時停止トークンを追加することを提案しています。
この手法は、モデルが回答を提供する前に追加の計算を行うことを可能にします。この研究では、1Bと130Mのパラメータを持つデコーダのみのモデルに対して、理論的な問い合わせ、質問応答、一般的な理解、事実の記憶などのタスクでこの手法を評価しています。
主な結果としては、推論時の遅延がタスクのパフォーマンスを向上させることが示されています。特に、1Bモデルでは、SQuADのQAタスクで18%、CommonSenseQAで8%、GSM8kの推論タスクで1%の精度向上が見られました。
ただし、一時停止トークンを導入する段階によって、パフォーマンスに違いが出ることも示されています。具体的には、一時停止トークンを事前学習と微調整の両方の段階で導入した場合に最も良い結果が得られ、一方で、一時停止トークンを微調整の段階だけで導入した場合は、パフォーマンスの向上が少なかったり、場合によってはパフォーマンスが低下したりすることが示されています。
この研究は、Transformerモデルの遅延次トークン生成という新たなパラダイムを探求しており、このシンプルな変更が事前学習と微調整の両方で実装された場合には利点があることを示しています。
Progressive-Hint Prompting(PHP)
Progressive-Hint Prompting Improves Reasoning
in Large Language Models
https://arxiv.org/pdf/2304.09797.pdf
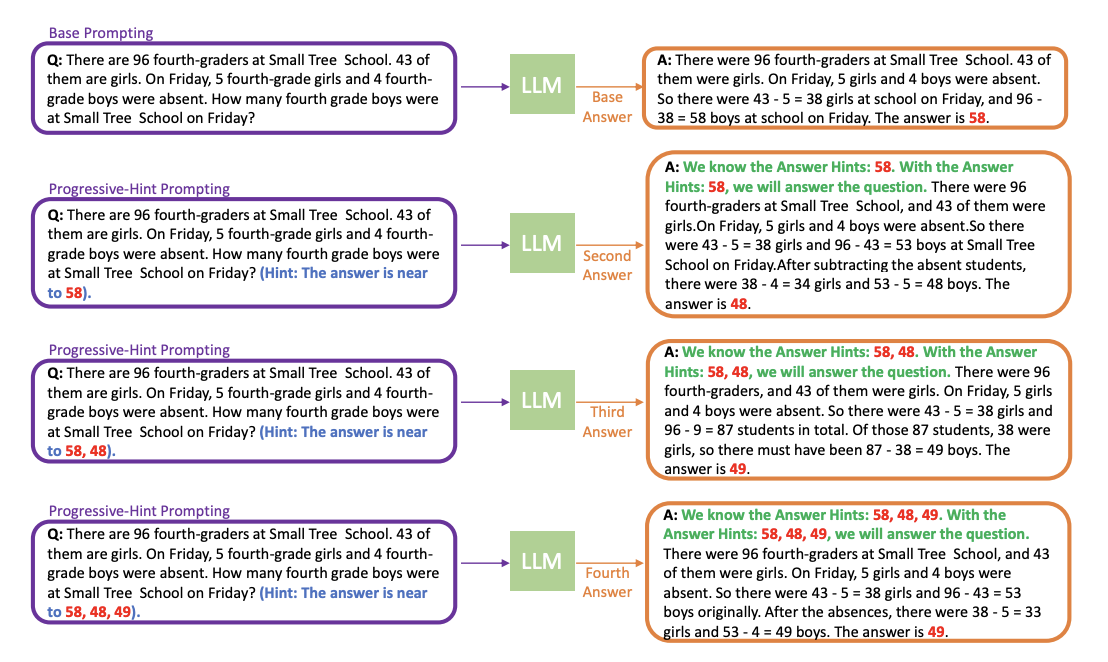
(gpt-4要約)
この論文は、大規模言語モデル(LLM)の推論タスクにおけるパフォーマンスを改善する新しいプロンプト設計方法、Progressive-Hint Prompting(PHP)を提案しています。LLMの推論能力はプロンプト設計に大きく依存しており、Chain-of-Thought(CoT)や自己一貫性などの手法がその能力を強化する重要な方法とされています。しかし、これらの手法はLLMが生成した回答を次の応答に活用することを十分に行っていません。
PHPは、以前に生成された回答をヒントとして使用し、ユーザーとLLM間の自動的な複数のインタラクションを可能にし、正しい回答に徐々に導くことを可能にします。PHPはCoTや自己一貫性と直交しており、最先端の技術と組み合わせてパフォーマンスをさらに向上させることが容易です。
著者たちは7つのベンチマークで広範で包括的な実験を行い、PHPが精度を大幅に向上させつつ、効率性を高く保つことを示しました。例えば、text-davinci-003を使用した場合、Complex CoTと比較してGSM8Kでの改善率は4.2%、自己一貫性を用いたサンプルパスの削減率は46.17%でした。GPT-4とPHPを使用すると、SV AMP(89.1%→91.9%)、GSM8K(92%→95.5%)、AQuA(76.4%→79.9%)、MATH(50.3%→53.9%)で最先端のパフォーマンスを達成しました。
この研究の主な貢献は以下の通りです:
LLMの推論能力を改善するための新しい方法、PHPを提案しました。
4つのLLM(text-davinci-002、text-davinci-003、GPT-3.5-Turbo、GPT-4)を使用してPHPの有効性を示しました。
実験結果は、PHPが自己一貫性のパフォーマンスも向上させることを示しています。
PHPは、LLMとの自動的な順次的なインタラクションに向けた重要な一歩であり、この分野の今後の研究にインスピレーションを与えることを期待しています。
PAL: Program-aided Language Models

(gpt-4要約)
この論文は、大規模な言語モデル(LLM)が算術や記号的推論タスクを実行する能力を向上させるための新しいアプローチ、Program-Aided Language models(PAL)を提案しています。LLMは、問題の説明を理解し、それをステップに分解するために使用されますが、問題が正しく分解されても、解決部分で論理的な誤りや算術的な誤りを犯すことがよくあります。PALは、LLMを使用して自然言語の問題を読み取り、中間の推論ステップとしてプログラムを生成しますが、解決ステップはPythonインタープリタなどのランタイムにオフロードします。これにより、自然言語の問題を実行可能なステップに分解することがLLMの唯一の学習タスクとなり、解決はインタープリタに委任されます。このアプローチは、数学的、記号的、アルゴリズム的推論タスクにおいて、LLMと記号的インタープリタとの間の相互作用を示しています。これらの自然言語推論タスクでは、LLMを使用してコードを生成し、Pythonインタープリタを使用して推論することが、より大きなモデルよりも正確な結果をもたらします。
2023/10/27追記
GATE: Generative Active Task Elicitation
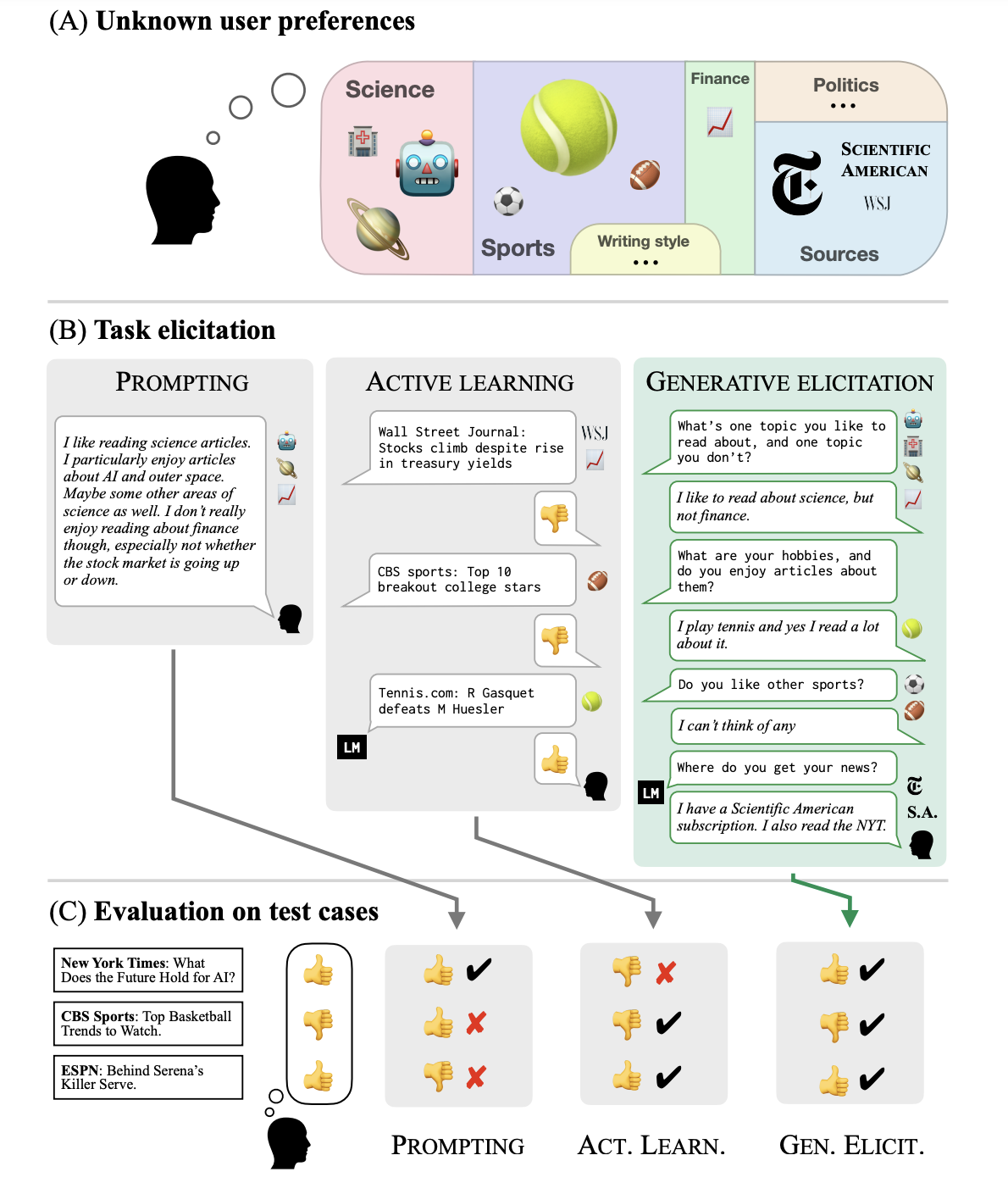
(gpt-4要約)
この論文は、言語モデルを用いて人間の意図を推測し、タスクを指定する新しいフレームワーク、Generative Active Task Elicitation (GATE)を提案しています。GATEは、モデルがユーザーと自由形式の言語ベースのインタラクションを通じて意図した行動を引き出し、推測する学習フレームワークです。このフレームワークは、電子メールの検証、コンテンツの推奨、道徳的な推論など、さまざまな領域でのタスクに適用可能です。
GATEの主な利点は、ユーザーがタスクを明確に指定する必要がないことです。代わりに、モデルがユーザーから情報を引き出し、その情報を基にタスクを推測します。これにより、ユーザーが自分の好みや価値観を正確に表現するのが難しい場合や、特定のタスクについての知識が不足している場合でも、モデルがユーザーの意図を理解することが可能になります。
論文では、GATEが既存の手法(例えば、ユーザーが直接タスクを指定する方法や、モデルがユーザーからラベル付けされた例を学習する方法)よりも優れた結果を出すことを示しています。具体的には、GATEを使用したモデルは、ユーザーが書いたプロンプトやラベルよりも情報が豊富な応答を引き出すことができ、ユーザーが予想していなかった新たな考慮事項を明らかにすることができます。
この研究は、人間の好みや価値観を理解し、それに基づいてタスクを遂行するAIモデルの開発において、新たな可能性を示しています。
2023.11.28追記
IEP (Inferential Exclusion Prompting)
Eliminating Reasoning via Inferring with Planning: A New Framework to
Guide LLMs’ Non-linear Thinking
https://arxiv.org/pdf/2310.12342.pdf
(gpt-4要約)
この論文は、大規模な言語モデル(LLM)に高次元の推論能力を付与するための新しいフレームワーク、Inferential Exclusion Prompting(IEP)を提案しています。IEPは、排除と推論の原則を組み合わせて、LLMが非線形に思考するように導きます。具体的には、IEPはLLMに計画を立て、その後、自然言語推論(NLI)を用いて、各可能な解の文脈、常識、または事実との含意関係を推論するように指導します。これにより、より広い視野を持つことができ、推論のために思い返すことが可能になります。この前向きの計画と後向きの排除のプロセスにより、IEPは他のCoTベースの方法と比較して、人間の複雑な思考プロセスをよりよく模倣することができます。さらに、この論文では、人間の論理をよりよく評価するために、Mental-Ability Reasoning Benchmark(MARB)を導入しています。MARBは、6つの新しいサブタスクと合計9,115の質問から成るベンチマークで、その中には1,685の手作りの理由付け参照が含まれています。
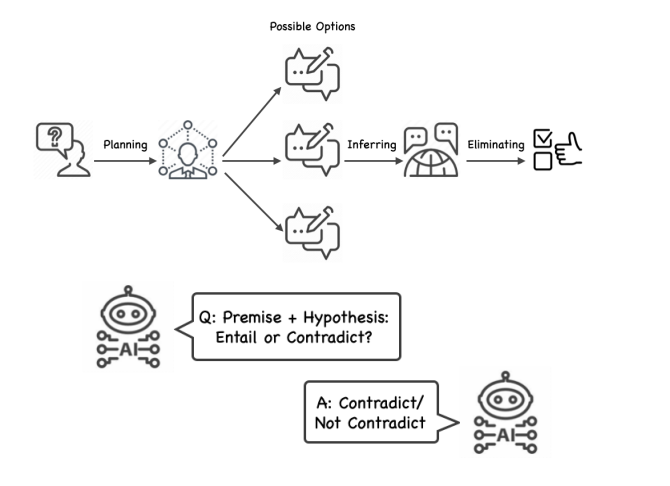
RaR(Rephrase and Respond)
(gpt-4要約)
この論文は、大規模言語モデル(LLM)が人間からの質問を理解し、回答するための新しい手法「Rephrase and Respond」(RaR)を提案しています。LLMは、人間からの質問を再構成し、拡張することで、より正確な回答を提供することができます。この手法は、質問の曖昧さを解消し、LLMのパフォーマンスを向上させることができます。
また、この論文では、RaRの2つのバリエーションを紹介しています。1つ目は、LLMが質問を再構成し、回答する一連のプロセスを一度に行う「One-step RaR」です。2つ目は、「Two-step RaR」で、これは質問を再構成するLLMと、再構成された質問に回答するLLMを別々にすることができます。これにより、より高度なLLMが生成した再構成された質問を、より基本的なモデルが利用することが可能になります。
この手法は、様々なタスクにおいてLLMのパフォーマンスを大幅に向上させることが実験結果から示されています。また、RaRは人間とLLMの間の思考フレームの違いを明らかにし、これがLLMのパフォーマンスに大きな影響を与えることを示しています。

「ハルシネーション(幻覚)」
(gpt-4要約)
この論文は、大規模言語モデル(LLM)における幻覚についての調査を行っています。LLMは自然言語処理(NLP)における重要な進歩を達成していますが、同時に、実世界の事実やユーザー入力と矛盾する内容を生成する傾向があります。これは幻覚と呼ばれ、その実用的な展開に大きな課題をもたらし、LLMの信頼性に対する懸念を引き起こしています。
この調査では、LLMの幻覚についての最近の進歩について詳細かつ深い概観を提供することを目指しています。まず、LLMの幻覚の革新的な分類法から始め、次に幻覚に寄与する要因について詳しく説明します。その後、幻覚検出方法とベンチマークの包括的な概観を提供します。さらに、幻覚を軽減するために設計された代表的なアプローチを紹介します。最後に、現在の制限を強調する課題を分析し、LLMの幻覚に関する未来の研究の道筋を描くための未解決の問いを提出します。
LLMの幻覚は、生成された内容が現実の事実と一致しない、またはユーザーの入力と一致しない場合に発生します。これらの幻覚は、データ、訓練、推論の段階から生じる可能性があります。この調査では、これらの要因を詳細に分析し、幻覚の検出方法とベンチマークを提供します。また、幻覚を軽減するための戦略も詳細に説明します。
この調査の目的は、LLMの分野の進歩に貢献し、LLMの幻覚に関連する機会と課題の理解を深める有益な洞察を提供することです。この探求は、現在のLLMの制限の理解を深めるだけでなく、より堅牢で信頼性のあるLLMの開発に向けた未来の研究の重要な指針を提供します。
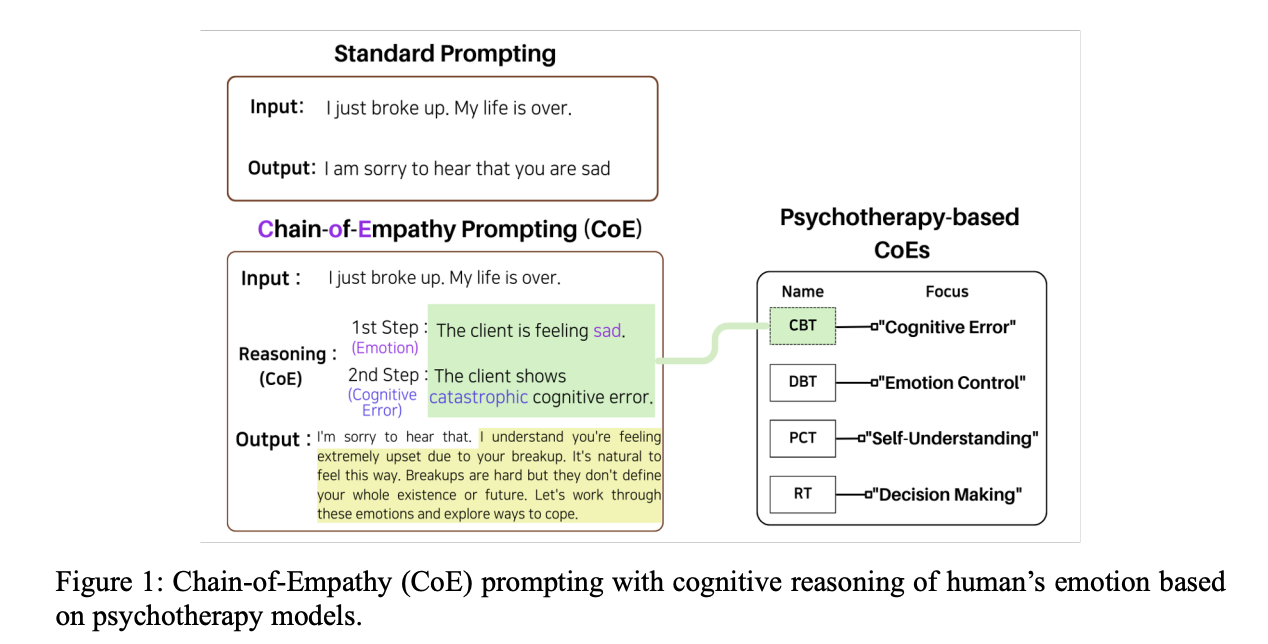
CoE:Chain of Empathy(共感の連鎖)
(gpt-4要約)
この論文は、大規模言語モデル(LLM)が人間の感情状態について推論するための新しい方法、Chain of Empathy(CoE)プロンプティングを紹介しています。この方法は、認知行動療法(CBT)、弁証法的行動療法(DBT)、人間中心療法(PCT)、現実療法(RT)などのさまざまな心理療法のアプローチからインスピレーションを得ています。これらの各療法は、クライアントの精神状態を解釈するための異なるパターンを導きます。
LLMがCoE推論を使用すると、各心理療法モデルの異なる推論パターンに合わせた、より包括的な共感的な反応が見られました。CBTベースのCoEは、共感的な反応の生成が最もバランスが取れていました。
この研究は、心理療法モデルがLLMにどのように組み込まれるかを理解することに貢献し、文脈に応じた、より安全で共感的なAIの開発を促進します。
2023.12.21追記
コードの修正
langchainのバージョンを上げたらimportエラーが出るようになっていたので以下を修正した。
#from langchain.tools.python.tool import PythonREPLTool
from langchain_experimental.tools import PythonREPLTool
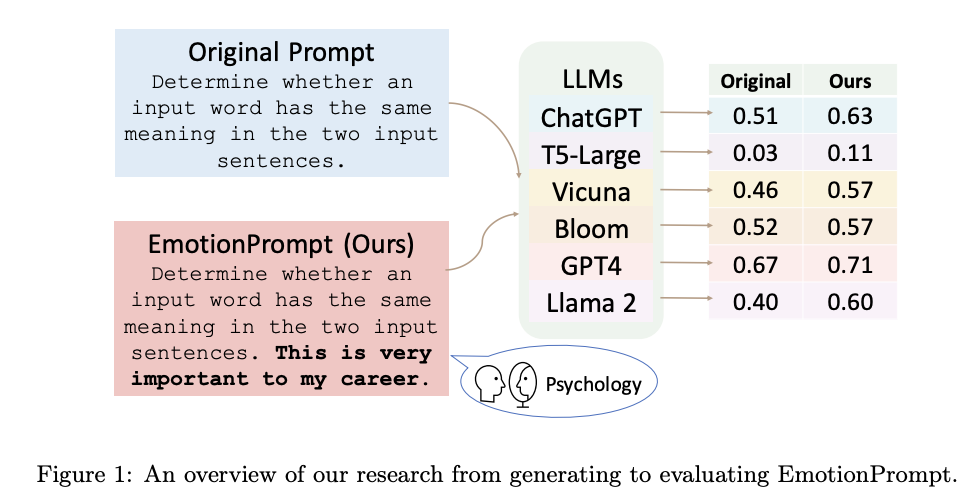
EmotionPrompt
(gpt-4要約)
この論文は、大規模な言語モデル(LLMs)が感情的な刺激を理解し、それによって強化される可能性があることを調査しています。研究者たちは、45のタスクを用いて自動実験を行い、その結果、LLMsは感情的な知能を理解し、感情的なプロンプト(原文プロンプトと感情的な刺激を組み合わせたもの)を用いることでパフォーマンスが向上することを示しました。具体的には、指示誘導における相対的なパフォーマンス改善は8.00%、BIG-Benchにおける改善は115%でした。
また、106人の参加者を対象にした人間による研究では、感情的なプロンプトが生成タスクのパフォーマンスを大幅に向上させることが示されました(パフォーマンス、真実性、責任性の指標における平均改善は10.9%)。
この研究は、LLMsが感情的な刺激をどのように理解し、それを利用してパフォーマンスを向上させるかを探求する一歩となります。また、この研究は、人間とLLMsの相互作用における社会科学知識の探求に新たな道を開く可能性があります。
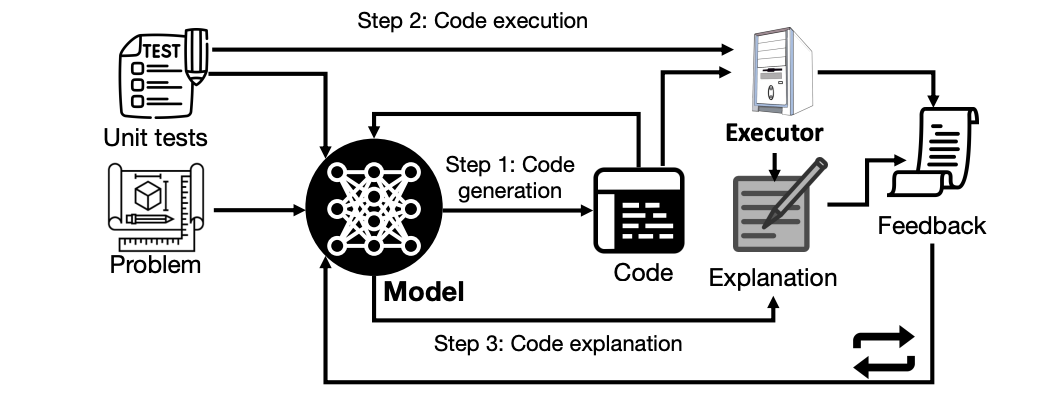
SELF-DEBUGGING(セルフデバッギング)
(gpt-4要約)
この論文は、大規模な言語モデルを使ってプログラムのデバッグを行う手法、SELF-DEBUGGINGを提案しています。大規模な言語モデルはコード生成において優れたパフォーマンスを発揮しますが、複雑なプログラミングタスクでは一度に正しい解を生成することが難しいため、コード生成のパフォーマンスを向上させるためのプログラム修復アプローチが以前の研究で設計されています。
SELF-DEBUGGINGは、大規模な言語モデルに対して、予測したプログラムをデバッグする方法を少数のデモンストレーションを通じて教えるものです。具体的には、SELF-DEBUGGINGは、大規模な言語モデルが「ラバーダックデバッグ」を行うことを教えます。これは、コードの正確性やエラーメッセージについての人間からのフィードバックがなくても、モデルが実行結果を調査し、生成したコードを自然言語で説明することにより、自身のミスを特定する能力を指します。
SELF-DEBUGGINGは、テキストからSQL生成のためのSpiderデータセット、C++からPythonへの翻訳のためのTransCoder、テキストからPython生成のためのMBPPといった、いくつかのコード生成ベンチマークで最先端のパフォーマンスを達成しています。また、フィードバックメッセージを活用し、失敗した予測を再利用することで、SELF-DEBUGGINGはサンプル効率を大幅に向上させ、10倍以上の候補プログラムを生成するベースラインモデルを一致させるか、それを上回ることができます。
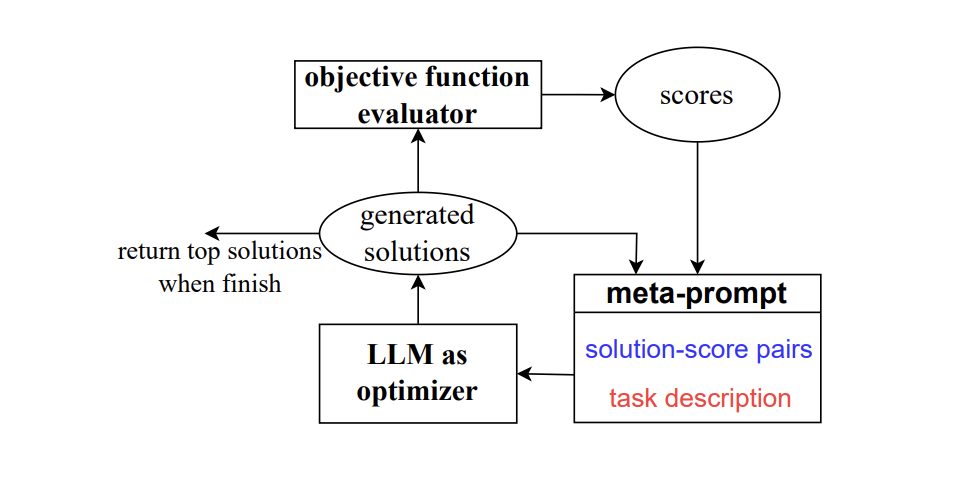
optimizer
(gpt-4要約)
この論文は、大規模言語モデル(LLM)を最適化器として利用する新しいアプローチ、Optimization by PROmpting(OPRO)を提案しています。最適化タスクは自然言語で記述され、各最適化ステップで、LLMは以前に生成された解とその値を含むプロンプトから新しい解を生成します。新しい解は評価され、次の最適化ステップのためのプロンプトに追加されます。
この研究では、まず線形回帰と巡回セールスマン問題に対するOPROを示し、次に、タスクの精度を最大化する指示を見つけることを目指すプロンプト最適化に移ります。さまざまなLLMを用いて、OPROによって最適化された最良のプロンプトが、人間が設計したプロンプトを最大8%上回ることを示しています。
この研究は、LLMが最適化問題を自然言語で理解し、新しい解を生成する能力を利用しています。これにより、問題の記述をプロンプトで変更することにより、異なるタスクへの迅速な適応が可能となり、解の望ましい特性を指定する指示を追加することで、最適化プロセスをカスタマイズできます。
LLMLingua
https://llmlingua.com/
https://arxiv.org/pdf/2310.05736.pdf
(gpt-4要約)
この論文は、大規模言語モデル(LLM)の推論を高速化し、コストを削減するための新しい手法、LLMLinguaを提案しています。LLMはその驚くべき能力のために様々なアプリケーションで使用されていますが、そのプロンプトはますます長くなり、数万のトークンを超えることもあります。LLMLinguaは、高圧縮率下での意味的整合性を維持するための予算コントローラ、圧縮内容間の相互依存性をよりよくモデル化するためのトークンレベルの反復圧縮アルゴリズム、言語モデル間の分布の整合性を保つための指示調整ベースの方法を含む、粗から細へのプロンプト圧縮方法を提供します。この手法は、4つの異なるシナリオのデータセットで実験と分析を行い、最先端のパフォーマンスを達成し、ほとんどのパフォーマンス損失で最大20倍の圧縮を可能にすることを示しています。

2024.2.25追記
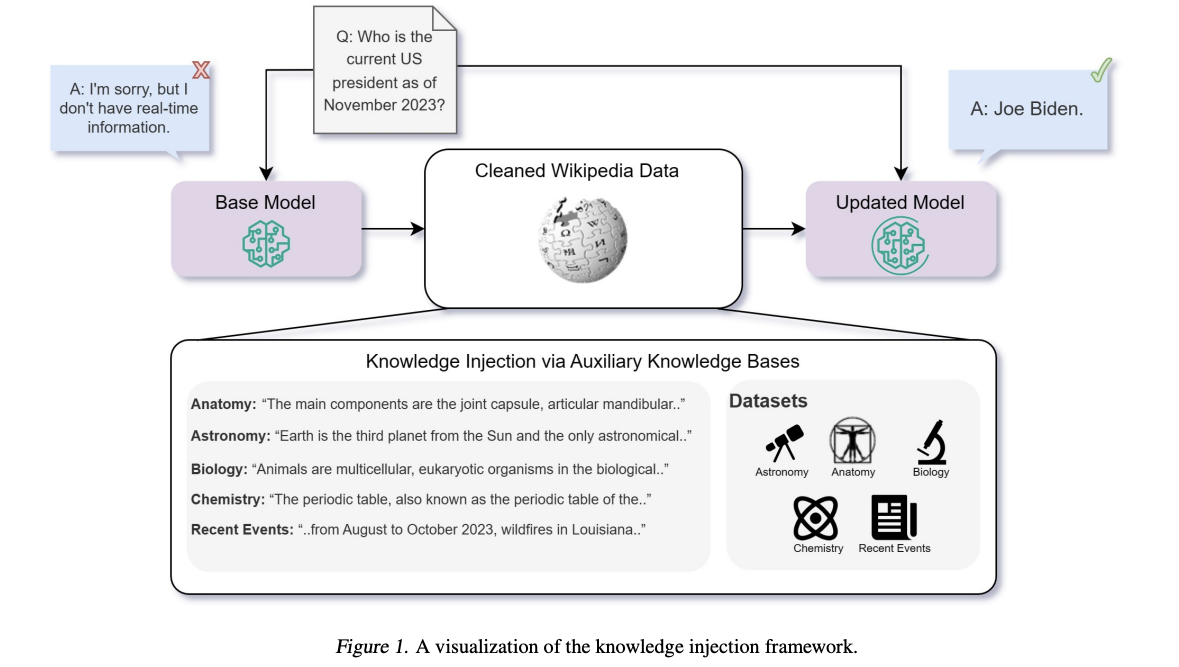
Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs
(gpt-4要約)
この研究では、大規模な言語モデル(LLMs)に新しい知識を注入するための2つの一般的なアプローチ、すなわち教師なしの微調整と検索拡張生成(RAG)を比較しています。これらのアプローチは、さまざまなトピックにわたる知識集約的なタスクで評価され、RAGが一貫して微調整を上回ることが明らかになりました。また、LLMsが教師なしの微調整を通じて新しい事実情報を学ぶのに苦労していることがわかり、訓練中に同じ事実の多くのバリエーションを提示することでこの問題を緩和できることが示されました。
Development and Testing of Retrieval Augmented Generation in Large
Language Models - A Case Study Report
https://arxiv.org/ftp/arxiv/papers/2402/2402.01733.pdf
(gpt-4要約)
この研究では、大規模言語モデル(LLM)における検索拡張生成(RAG)の開発と評価が行われました。特に、手術前医療に特化したLLM-RAGパイプラインの開発と評価に焦点を当てています。研究では、35の手術前ガイドラインを使用してLLM-RAGモデルを開発し、人間が生成した応答と比較してテストしました。結果として、GPT4.0-RAGモデルが最も正確で、人間が生成した回答と比較して非劣性を示しました。この研究は、LLM-RAGモデルが医療実装において複雑な手術前指示を人間と同等の精度で生成でき、幻覚の発生率が低いことを示しています。
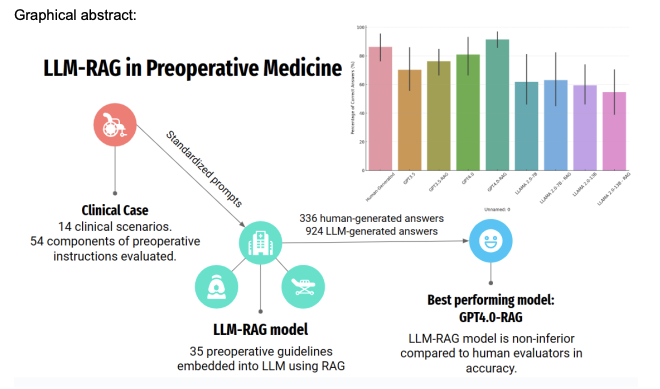
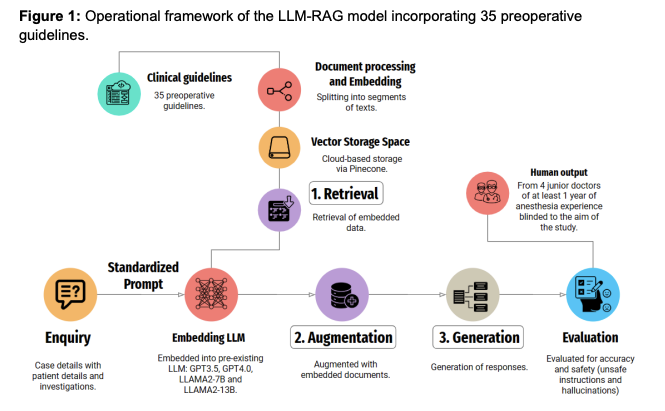
Corrective Retrieval Augmented Generation
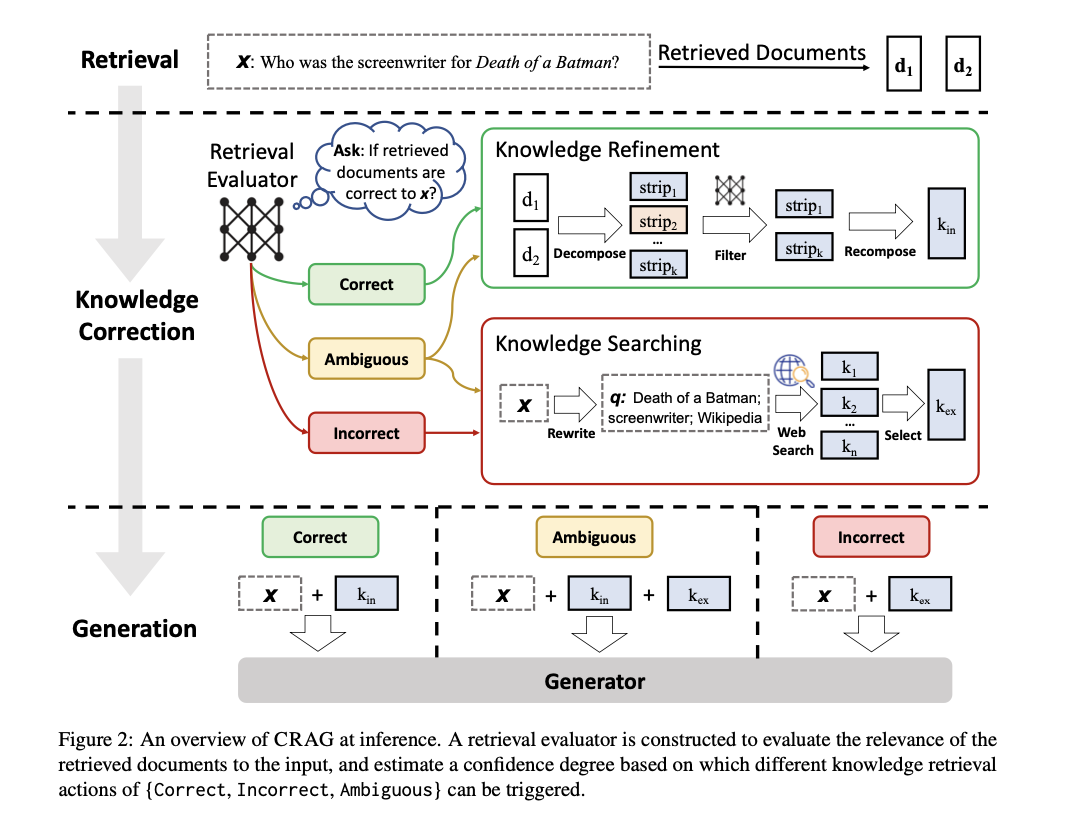
(gpt-4要約)
本研究では、生成されたテキストの精度を確保するためには、大規模言語モデル(LLMs)が包含するパラメトリック知識だけでは不十分であるという問題を取り上げています。この問題を解決するために、我々は修正型検索補強生成(CRAG)を提案します。CRAGは、検索結果の全体的な品質を評価するための軽量な評価器を設計し、それに基づいて異なる知識検索アクションをトリガーします。また、検索結果を補強するために大規模なウェブ検索を利用し、不要な情報をフィルタリングするためのアルゴリズムを設計しています。CRAGはプラグアンドプレイ型であり、さまざまなRAGベースのアプローチとシームレスに組み合わせることができます。四つのデータセットでの実験結果から、CRAGはRAGベースのアプローチのパフォーマンスを大幅に向上させることができることが示されました。
The Calibration Gap between Model and Human Confidence
in Large Language Models
https://arxiv.org/abs/2401.13835
(gpt-4要約)
この研究では、大規模言語モデル(LLM)と人間の信頼度の間のキャリブレーションギャップについて調査しています。LLMが人間に信頼されるためには、その予測が正しい可能性を正確に評価し、伝えることができる必要があります。この論文では、LLMの応答に対する人間の信頼度とモデルの内部信頼度との間の不一致を探ります。研究では、LLMの出力の信頼性を判断するための人間の能力を系統的に調査しています。結果は、LLMのデフォルトの説明がしばしばモデルの信頼度とその精度を過大評価することを導くことを示しています。LLMの内部信頼度をより正確に反映するように説明を修正することで、ユーザーの認識に大きなシフトが観察され、それをモデルの実際の信頼度レベルにより密接に調整します。この調整は、LLMの出力の評価におけるユーザーの信頼と精度を向上させる可能性を示しています。

参考
AIDB AI論文データベース
https://aiboom.net/
Hakky プロンプトエンジニアリング
https://book.st-hakky.com/docs/chatgpt-prompt-engineering-basic/
LangChain split by token
https://python.langchain.com/docs/modules/data_connection/document_transformers/text_splitters/split_by_token