はじめに
前回、GCP VertexAI Search + Palm2でのRAGをやったので、今回は、AWS Kendra + Bedrock(Claude)でのRAGをやってみる。
Azure : Azure OpenAI + CognitiveSearch (ベース)
GCP : Palm2 + VertexAI Search (前回)
AWS : Bedrock + Kendra【←今回】
これで主要なパブクラの代表LLM+インデクスサービスでのRAG回答を比較することができるようになる。
(準備)
- AWS Kendra インデクス作成
- インデクス作成(Jupyter操作)
(コード)
大枠はベース&前回とほぼ同じなので、retrieverの設定部分のみ記載する。
AWS Kendra インデクス作成
Amazon Kendraとは
機械学習を活用した検索サービス。自然言語処理と高度な検索アルゴリズムを使用して、非構造化データ、構造化データを検索できる。(Azure Cognitive Search、GCP VertexAI Searchの対抗)
ただし、印象としてとても高い。(注意)
AWS Consoleによるインデクス作成方法
AWS ConsoleよりKendraを検索。

「Create an index」より新規インデクスを作成。

インデクス名を入力。またIAM roleは推奨どおり、新規作成として、role名を入力。
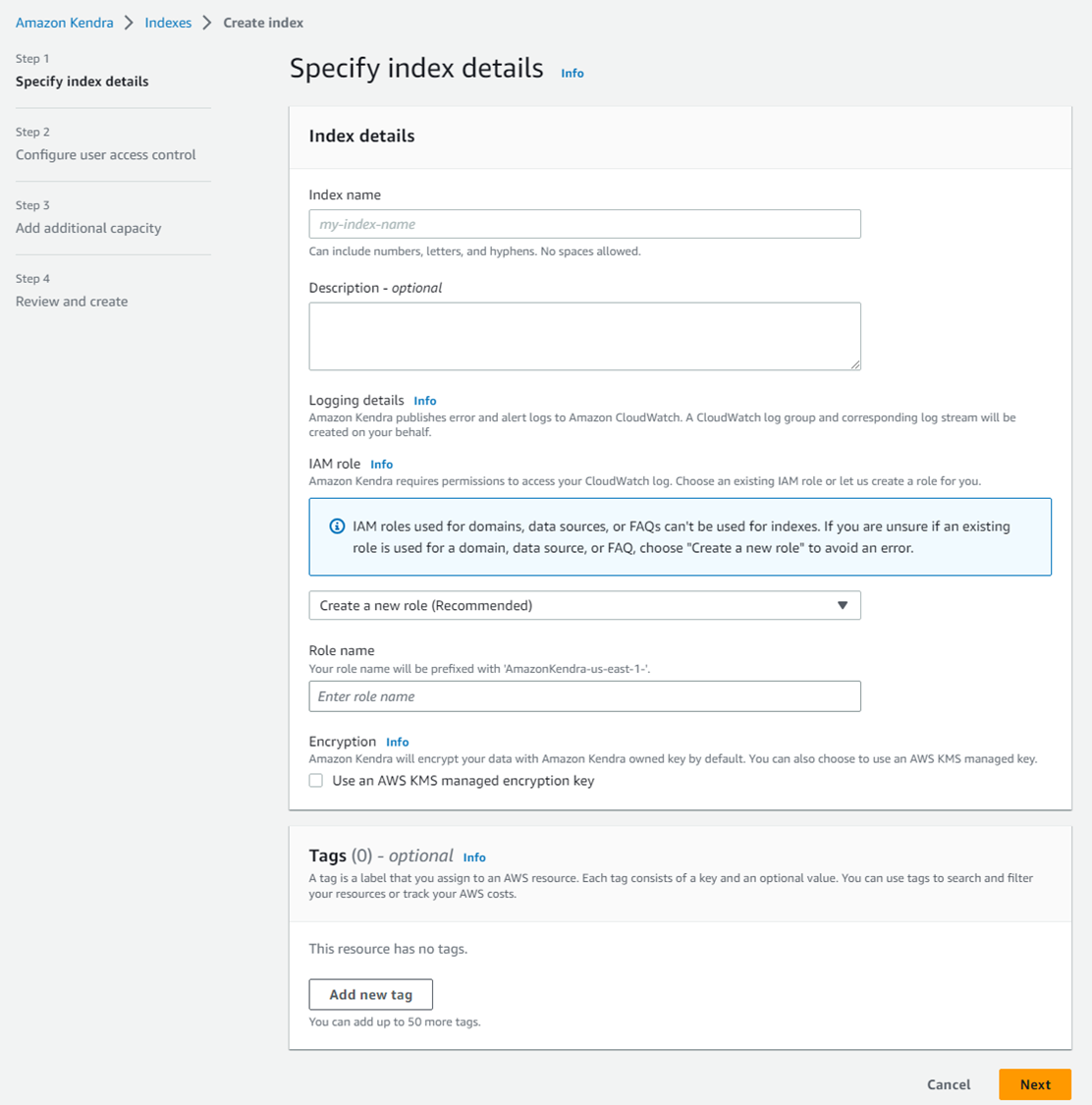
ここは特にデフォルトで。
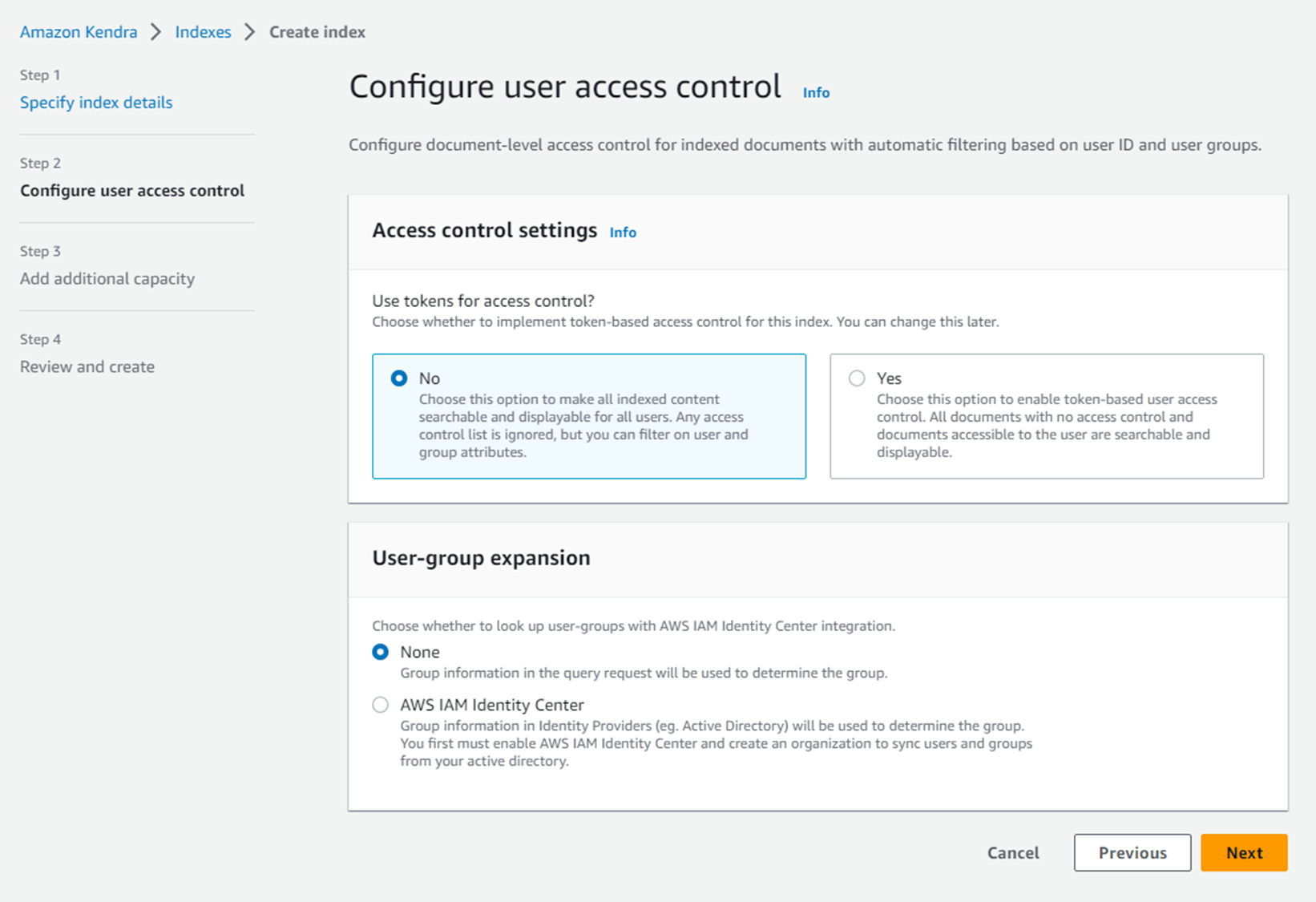
Developer editionを選択。

内容を確認して、Create。
PDFファイルのインデクス登録
jupyterでのAPIによる登録操作にて説明。
ライブラリのインストール(PDFハンドリング用)
その他必要に応じてインストール。
!pip install PyPDF2
認証情報、インデクスIDの設定とboto3セッション、kendraクライアントの初期化。
Index IDはAWS consoleのIndex settingsにて確認可能。
import boto3
# AWSの認証情報の設定
aws_access_key_id = ""
aws_secret_access_key = ""
aws_region_name = ""
# KendraのインデックスID
index_id = "" # index名ではない
# Boto3 のセッション作成
session = boto3.Session(
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
region_name=aws_region_name)
# Kendraクライアントの初期化
kendra = session.client('kendra')
jupyterにPDFファイルを配置して、ファイルパス、メタ情報(ソースURL、タイトル)を設定。
id_prefixは同一インデクスに複数ドキュメントを格納する場合のために一応用意。
PDFファイルを読み込む。
uploaded_file="./hyqb0101.pdf"
#chunk_size=1000
source="https://URL/file/test/hyqb0101.pdf"
title="PDFのタイトル"
id_prefix=""
import PyPDF2
from langchain.text_splitter import RecursiveCharacterTextSplitter
pdf_reader = PyPDF2.PdfReader(uploaded_file)
チャンクサイズ分割でも良いが、せっかくClaude(トークン最大サイズが大きめ)を使うのでPDFのページ単位で入れることにする。
Kendraのドキュメント特性についてはこちらを参照。
https://docs.aws.amazon.com/ja_jp/kendra/latest/dg/hiw-document-attributes.html
ソースURLと日本語検索オプションを追加。
またタイトルにはPDFのページ番号を追加。
documents = [{
'Id': id_prefix + str(i),
'Attributes' : [
{
'Key': "_source_uri",
'Value': {
'StringValue': source ,
}
},
{
'Key': "_language_code",
'Value': {
'StringValue': 'ja' ,
}
},
],
'Blob': page.extract_text(),
'ContentType': "PLAIN_TEXT",
'Title': title + " P." + str(i+1),
} for i, page in enumerate(pdf_reader.pages)]
なお、このdocumentsをそのまま指定して、kendra.bath_put_documentを実行したところ、以下のエラーが出た。
ValidationException: An error occurred (ValidationException) when calling the BatchPutDocument operation: 1 validation error detected: Value at "documents" failed to satisfy constraint: Member must have length less than or equal to 10
gpt-4様に聞くと、下記のとおりだそうなので、修正してもらったコードで実行。

RoleArnには作成したロールのもの(Index settingsで確認可能)を入れる。
batches = [documents[i:i + 10] for i in range(0, len(documents), 10)]
for batch in batches:
response = kendra.batch_put_document(
IndexId=index_id,
RoleArn="",
Documents=batch
)
これを実行するとインデクス登録できる。
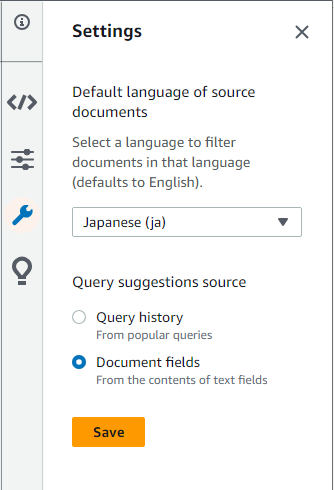
登録の確認は、「Search indexed content」から可能。Settingsで日本語フィルタを設定して検索できる。


コード作成
主にこれまでとの差分のみ。(LangChain + LLM Liteを使用してRetrievarによる問合せ)
まずKendra用のライブラリと環境変数(AWS_KENDRA_INDEX_ID)を設定。
import boto3 # for Kendra
from langchain.retrievers import AmazonKendraRetriever
os.environ["AWS_ACCESS_KEY_ID"] = ""
os.environ["AWS_SECRET_ACCESS_KEY"] = ""
os.environ["AWS_REGION_NAME"] = ""
os.environ["AWS_KENDRA_INDEX_ID"] = ""
boto3のセッションの作成とkendraクライアントの初期化。
session = boto3.Session(
aws_access_key_id = os.environ["AWS_ACCESS_KEY_ID"],
aws_secret_access_key = os.environ["AWS_SECRET_ACCESS_KEY"],
region_name =os.environ["AWS_REGION_NAME"])
kendra = session.client('kendra')
bedrockのモデルの場合のretriever設定。attribute_filterを設定し、retrieverにセットする。
top_kについてはデフォルトで3(引用ドキュメント数)だが、ヒットする検索結果に同一ドキュメントが含まれている場合、複数取得してしまう(?)ため、少し増やして7とした。
その他のAmazonKendraRetrieverのオプションについてはこちらを参照。
https://api.python.langchain.com/en/latest/retrievers/langchain.retrievers.kendra.AmazonKendraRetriever.html
elif LLMtype in ["bedrock/anthropic.claude-v2"]:
# AWS Kendra
attribute_filter = {"EqualsTo": {"Key": "_language_code","Value": {"StringValue": "ja"}}}
retriever = AmazonKendraRetriever(index_id=os.environ["AWS_KENDRA_INDEX_ID"],client=kendra, attribute_filter=attribute_filter, top_k=7)
ksr=retriever.get_relevant_documents(query=keyword['text'])
省略したが、LLM(Claude)により質問からクエリを生成し、上記で関連ドキュメントを検索、このドキュメントをコンテキストとしてLLM(Claude)にて回答を生成することができる。
まとめ
Kendra + BedrockでのRAGについてまとめた。Kendraへのretrieverのオプションは少なく、主にKendra(インデクス)側にてチューニングをする必要がありそう。またAzure Cognitive Searchとの差が(GCPに比べ)少ないので、両者の比較は容易だが、Kendraの費用が高いので注意が必要。