為替レートを予測する学習モデルをつくります
前回の投稿で、時系列データの教師データを生成しました。
この教師データを用いて学習するモデルをつくります。
時系列データの学習モデル構築方法について、私は下記書籍で学び実践しました。
時系列データの学習モデル
先に、私が構築した学習モデルの例を図示します。下記のような構成です。
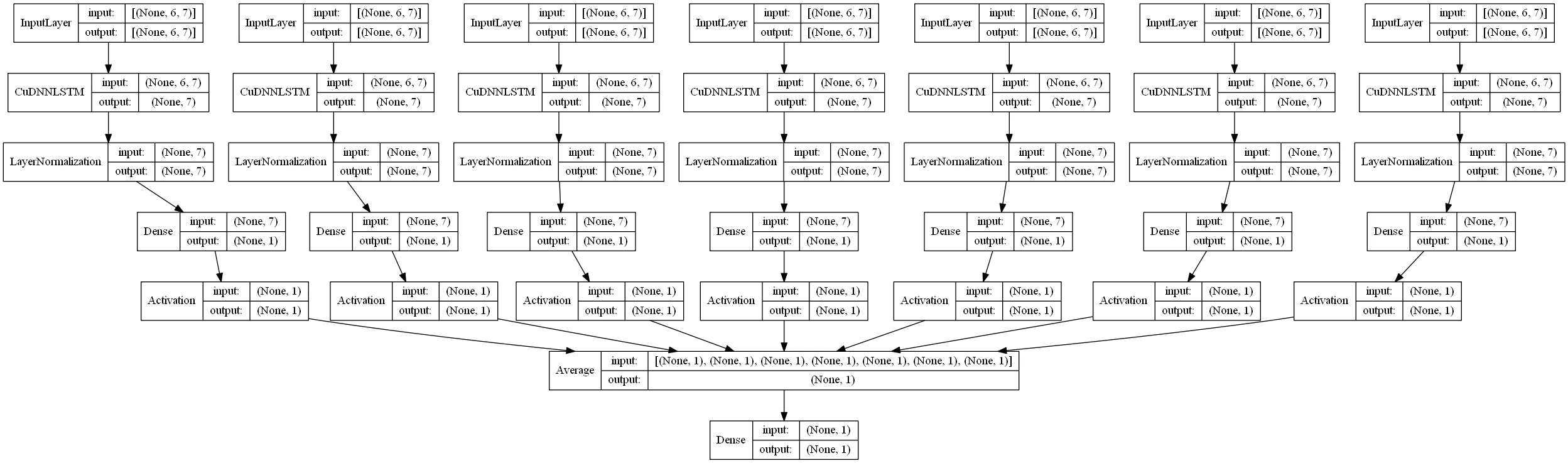
- 同じ特徴量毎、多種の通貨ペアをセットにして入力層とする
- それぞれの入力セットにLSTMの中間層を入れる
- LSTMの出力をレイヤー正規化(Layer Normalization)する
- 伝達関数でそれぞれの出力を変換する
- 結果を集約(Average)する
以上
ソースコードの例は下記のとおりです。Keras (機械学習やディープラーニングのモデル作成を容易にするオープンソースのライブラリ)を用いれば、簡単に実装できます。
# 入力を定義
x_inputs = []
x_outputs = []
input = Input(shape=(INPUT_SHAPE1, INPUT_SHAPE2))
for index in range(len(X_train)):
# 入力から結合前まで
x = CuDNNLSTM(len(X_train[index][0][0]), return_sequences=False)(input)
x = tf.keras.layers.LayerNormalization(axis=1)(x)
x = Dense(OUTPUT_NUM, kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01))(x)
x = Activation('relu')(x)
x = Model(inputs=input, outputs=x)
x_inputs.append(x.input)
x_outputs.append(x.output)
# 平均
z_outputs = Average()(x_outputs)
# 出力
z_output = Dense(1)(z_outputs)
# モデル定義とコンパイル
model = Model(inputs=x_inputs, outputs=z_output)
opt_adam=Adam(lr=0.01, beta_1=0.9, beta_2=0.999)
model.compile(loss="mse",
optimizer=opt_adam,
metrics=['mae','mse'])
上記モデルを人が為替レートを予測する手順のように記載すると、
- 通貨ペア毎、多種のテクニカルチャートを表示し目視確認する
- それぞれテクニカルチャート分析する
- 予測したい通貨ペアと相関のある通貨ペアの分析結果を統合し、最終的に判断する
となり、
なんとも人間的な分析手順を踏む、テクニカルチャート分析のノウハウ本に記載されているような学習モデルができあがりました。
当初は人間がやらないような分析にするために、複雑な多層構造にしましたが、過学習(学習期間は正答率90%、未学習は50%など)がなかなか解消されませんでした。
結局、個人投資家ができるテクニカルチャート分析は、最適化されているんだなと感じました。
DeepLearningが流行りだした10数年前から、学習モデルはどんどん複雑に、多階層になっていきましたが、ここ数年は逆にどんどん単純化していき、SmallLearning(少ないデータで高性能を)が主体となっているようです。私も個人でできる範囲でいろいろ検証しましたが、複雑化すると、過学習が克服しずらくなると実感しています。
検証するなら、単純なモデルから始めて、どんどん複雑にすることをお勧めします。
ですが、構築した学習モデルによる予測の精度は、通貨ペアにもよりますが、数時間後に上昇するか下降するかの精度では、せいぜい55%~65%程度です。
また、昨今のアメリカを起因とした市場の急変動は、数年分の時系列データを学習した学習モデルでは予測精度が落ちるようです(去年の大統領選まではよかった…)
そのため、下記書籍に記載されているように、「テクニカルチャート分析」+「ファンダメンタルズ分析」の必要性を大いに感じています。
![]() Coffee Break
Coffee Break
現在、テクニカルチャート分析と自動売買をAIに実行させ、ファンダメンタルズ分析は人が行う運用にしていますが、ゆくゆくはファンダメンタルズ分析もAIに実行させようとしています。
ですが、個人が使用できる生成AIや対話側AIは、ファンダメンタルズ分析の専用AIではないため、質問するたびに回答が変わったりします。正確性に欠けます。
あくまでもAIはCoPilotとして、情報収集(スクレイピング)や要約(ブロードリスニング)を実行し、判断は人間が行うのが妥当と考えています。
学習モデルの構成検討(失敗談/成功談)
【失敗談】CNNを使う
私が検討を始めた当初、CNN(畳み込みニューラルネットワーク)が流行っていたので、
為替レートの時系列データをわざわざ画像のように2次元的に配置して学習させてみたりしました。
CNNについては、下記記事が詳しく分かりやすく記載していますので、参照させて頂きます。
結果、それなりの予測精度(52%程度だったかな)はでましたが、LSTMなど、時系列データ向けの学習モデルの方が精度が高いことを実感しました。やはり記憶セルは意味があるようです。
【失敗談(成功談?)】パーセプトロンを使う
失敗談というより、RNN(リカレントニューラルネットワーク)の有効性を確認するため、基礎となる単純パーセプトロンや多層パーセプトロンを構築し、伝達関数を少しずつ変えて検証したりしました。
単純な構成だと予測精度は50%~51%程度が限界でした。
ただし、基礎を学ぶ意味では有意義であったと感じています。
下記の書籍が分かりやすく記載されていたので、オススメです。
【成功談】レイヤー正規化(Layer Normalization)を使う
私がDeepLearningの学習を始めた当初は、
レイヤー正規化という概念は普及されておらず(たぶん…私が無知だっただけかも…)、
バッチ正規化(Batch Normalization)しか知りませんでした。
正規化層を入れると、学習の安定性が増し、発散することが少なくなる一方、
精度が上がらないなと(55%ぐらい)思い悩んでいたところ、
レイヤー正規化という概念を知りました。
為替レートの時系列データ予測はこれだ!と思い、組み込んだのを覚えています。
結果、予測精度も上がりました(通貨ペアによっては60%ぐらいまで)
ちなみに、Keras を用いれば、Layer Normalizationは簡単に実装できます。
まとめ
前回の投稿より内容がずいぶん薄いですが、
為替レートを予測する学習モデルの作り方について、簡単に記載しました。
もっといろいろ検証したと思いますが、
過去にやったことが、PCや部屋中にとっ散らかって整理できていないので、
もし整理ができたら、追記します。
また、ここで私が記載した内容はすべて正解ではありません。
学習モデルの作り方について、少しでも参考にしていただけますと幸いです。
次は、「学習方法」について、投稿する予定です。
どんなに良い学習モデルでも学習方法が悪ければ、すぐに過学習が起きてしまいます。
重要な内容です。
よろしくお願いいたします。