実家に帰ると必ず言われることがあります。
![]() 父「いつ結婚するんだ?」
父「いつ結婚するんだ?」
![]() 母「結婚まだ?」
母「結婚まだ?」
![]() 妹「いつ結婚するの?」
妹「いつ結婚するの?」
![]() 姪「結婚しないの?」
姪「結婚しないの?」
![]() 姪2「結婚しないの?」
姪2「結婚しないの?」
![]() 妹の旦那「結婚した方がいいよ」
妹の旦那「結婚した方がいいよ」
![]() 「・・・・」
「・・・・」
![]() 自分「うるさーーーーい!結婚出来ないのは自分が悪いんじゃなくて、世の中が悪いんだ!」
自分「うるさーーーーい!結婚出来ないのは自分が悪いんじゃなくて、世の中が悪いんだ!」
世の中は、結婚後に対してネガティブな記事で溢れかえってる気がしませんか?
結婚のネガティブな記事のせいで結婚する気になれなくなっている人が多いと思うんです。
それをデータで証明してやろうじゃありませんか!
Pythonでネガポジ判定
![]() と、言うわけで、下記のポジティブ・ネガティブ判定してくれるコード(Python)を参考にポジネガ判定ツールを作ってみました。
と、言うわけで、下記のポジティブ・ネガティブ判定してくれるコード(Python)を参考にポジネガ判定ツールを作ってみました。
https://news.mynavi.jp/article/zeropython-58/
![]()
![]() カタカタカタ
カタカタカタ![]()
![]() チーン。はい、できました。まず、マイナビニュースで紹介されてる「走れメロス」で試してみたところ、全く同じスコアになりました。
チーン。はい、できました。まず、マイナビニュースで紹介されてる「走れメロス」で試してみたところ、全く同じスコアになりました。
https://www.aozora.gr.jp/cards/000035/files/1567_14913.html
ポジティブ 0.29 0.20 {'p':118, 'n':83, 'e': 208}
この調子で、結婚に関する記事に対してネガポジ判定をしてみたいと思います。
判定に使う辞書はマイナビニュースの記事と同じく「東北大学の乾・岡崎研究室の「日本語評価極性辞書」の名詞編」を使います。。。が・・・・
http://www.cl.ecei.tohoku.ac.jp/index.php?Open%20Resources%2FJapanese%20Sentiment%20Polarity%20Dictionary
この辞書では「結婚」に対してポジティブ(p)設定に、「離婚」はネガティブ(n)設定になっています。
これでは結婚に対しての評価にはならないので、下記のワード(婚を含むワード)は無視する設定にしました。
冠婚葬祭 e 〜がある・高まる(存在・性質) 結婚 p 〜する(行為) 結婚相手 e 〜である・になる(状態)客観 結婚披露宴 p 〜がある・高まる(存在・性質) 婚約 p 〜する(行為) 新婚旅行 e 〜に行く(場所) 政略結婚 n 〜する(行為) 離婚 n 〜する(行為)
ずるくないよね・・・?
そして、記事をスコアに応じて5段階評価にし、結果を一覧化します。(下記コード)
式は「スコア」=「ポジティブスコア」―「ネガティブスコア」
「超ポジティブ(0.3以上)」「ポジティブ(0.1以上)」「どっちでもない(-0.1以上)」「ネガティブ(-0.3以上)」「超ネガティブ(-0.3未満)」
![]() 下記はアレンジを加えた部分。
下記はアレンジを加えた部分。
with open("list.txt", "a", encoding="utf8", errors="replace") as file:
if posi >= 0.3:
judge = "超ポジティブ"
elif posi >= 0.1:
judge = "ポジティブ"
elif posi >= -0.1:
judge = "どっちでもない"
elif posi >= -0.3:
judge = "ネガティブ"
elif posi < -0.3:
judge = "超ネガティブ"
else:
judge = "判定不能"
print("判定", judge)
file.write('{0}\t{1}\t{2}\t{3}\t{4:.2f}\t{5:.2f}\t{6}\n'.format(theme,title,judge,posi,res["p"] / cnt,res["n"] / cnt,res))
file.close()
引数themeには検索ワード、titleには記事のタイトルを入れます。
まずは「結婚前」で検索した結果を判定してみました・・・
https://wedding.mynavi.jp/contents/press/detail/post-63/
ポジティブ 0.11801242236024845 0.23 0.11 {'p': 37, 'n': 18, 'e': 106}
『ポジティブ』判定・・・
![]() 「まぁ結婚前はこんなもんだろう」
「まぁ結婚前はこんなもんだろう」
次いで、「夫婦」で検索して出てきたURLを判定してみました。
https://wedding.mynavi.jp/contents/news/2016/09/ng1/
『ネガティブ』判定・・・
![]() 「ほれ見た事か!結婚した途端にネガティブになったぞ!!」(なぜか嬉しい)
「ほれ見た事か!結婚した途端にネガティブになったぞ!!」(なぜか嬉しい)
とりあえず4件やってみて、次のようなデータになりました。

テキストの見方(タブ区切り):検索ワード、記事タイトル、判定結果、スコア(ポジ-ネガ)、ポジ(割合)、ネガ(割合)、全てのワード
これをいったんグラフ化してみます。
![]() Pythonで帯グラフを作成
Pythonで帯グラフを作成![]()
Pythonでデータを帯グラフにしてみる
ネットで調べると帯グラフを作成する人は少ないようで、参考になる作り方がネットにあまり転がってない気がしました。
上で作成した「list.txt」テキストの見方(タブ区切り):検索ワード、記事タイトル、判定結果、スコア(ポジ-ネガ)、ポジ(割合)、ネガ(割合)、全てのワードのうち、使うのは検索ワード、判定結果のみです。
import numpy as np
import matplotlib.pyplot as plt
jtypes=['超ポジティブ','ポジティブ','どっちでもない','ネガティブ','超ネガティブ']
color = ['#e41a1c','#ff7f00','#40cf40','#779ed8','#377eb8']
list_file = open('list.txt', 'r', encoding="utf-8")
data ={}
for line in list_file:
channel,title,j_type,point,per1,per2,allword = line.split("\t")
if channel not in data:
data[channel]= np.zeros(len(jtypes))
for kk in range(len(jtypes)):
if j_type == jtypes[kk] :
data[channel][kk] += 1
list_file.close()
values_arr=[]
tick_labels = []
np.array([])
for key,value in data.items():
values_arr.append(value)
tick_labels.append(key)
xx, yy = len(values_arr), len(jtypes)
data_arr = np.array(values_arr)
normalized = data_arr / data_arr.sum(axis=1, keepdims=True)
cumulative = np.zeros(xx)
tick = np.arange(xx,0,-1)
for y in range(yy):
plt.barh(tick, normalized[:, y], left=cumulative, color=color[y], label=jtypes[y])
cumulative += normalized[:, y]
plt.xlim((0, 1))
plt.yticks(tick, tick_labels, fontname="meiryo")
lg = plt.legend(bbox_to_anchor=(1.0, 1.0), loc='upper left', prop={"family":"meiryo"})
plt.title("ポジネガ判定分布", fontname="meiryo")
plt.show()
4件のデータから得られたグラフはこれです。
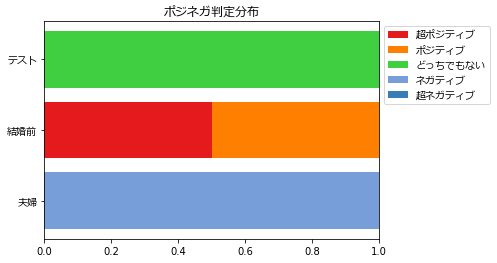
データ数が少ないので、各検索ワードにつき10記事を判定してみます。
また、結婚以外にも様々なワードで現れた検索結果を試してみます。
「独身」「コロナウイルス」「コロナ後」「月曜日」「土曜日」
(各ワードにつき10記事)
![]()
![]() カタカタカタ
カタカタカタ![]()
![]() チーン。はい、出ました!
チーン。はい、出ました!
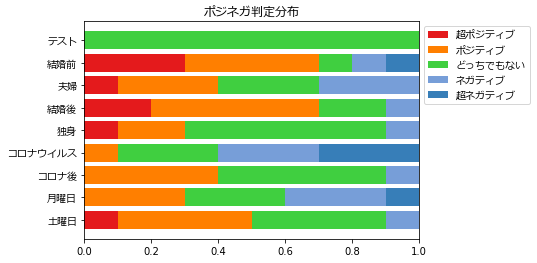
「結婚前」と「結婚後」は70%が「超ポジティブ」「ポジティブ」と言う結果となりました。
他の項目と比べても、「結婚」に対してポジティブな記事が多いのは明らかですね。
「独身」も思ったよりポジティブな記事が多い!(なぜか嬉しい)
「コロナウイルス」に関しては60%が「超ネガティブ」「ネガティブ」と判断されたのに対して、
「コロナ後」はネガティブな記事が少ないのは興味深いです。
「月曜日」が比較的ネガティブな記事が多いのに対して「土曜日」がポジティブなのも面白いですね。
結婚前も結婚後も「結婚」に対してはネガティブな要素は少ないと分かりました・・・。
「世の中は、結婚後に対してネガティブな記事で溢れかえってはいませんでした!」
別の言い訳を探してみますorz
既婚者と独身者では、既婚者の方が圧倒的に幸せを感じている見方が強いようですね。
https://comemo.nikkei.com/n/nac91dd2ea623
![]() ちなみに、僕は幸せですけどね(泣いてない)
ちなみに、僕は幸せですけどね(泣いてない)