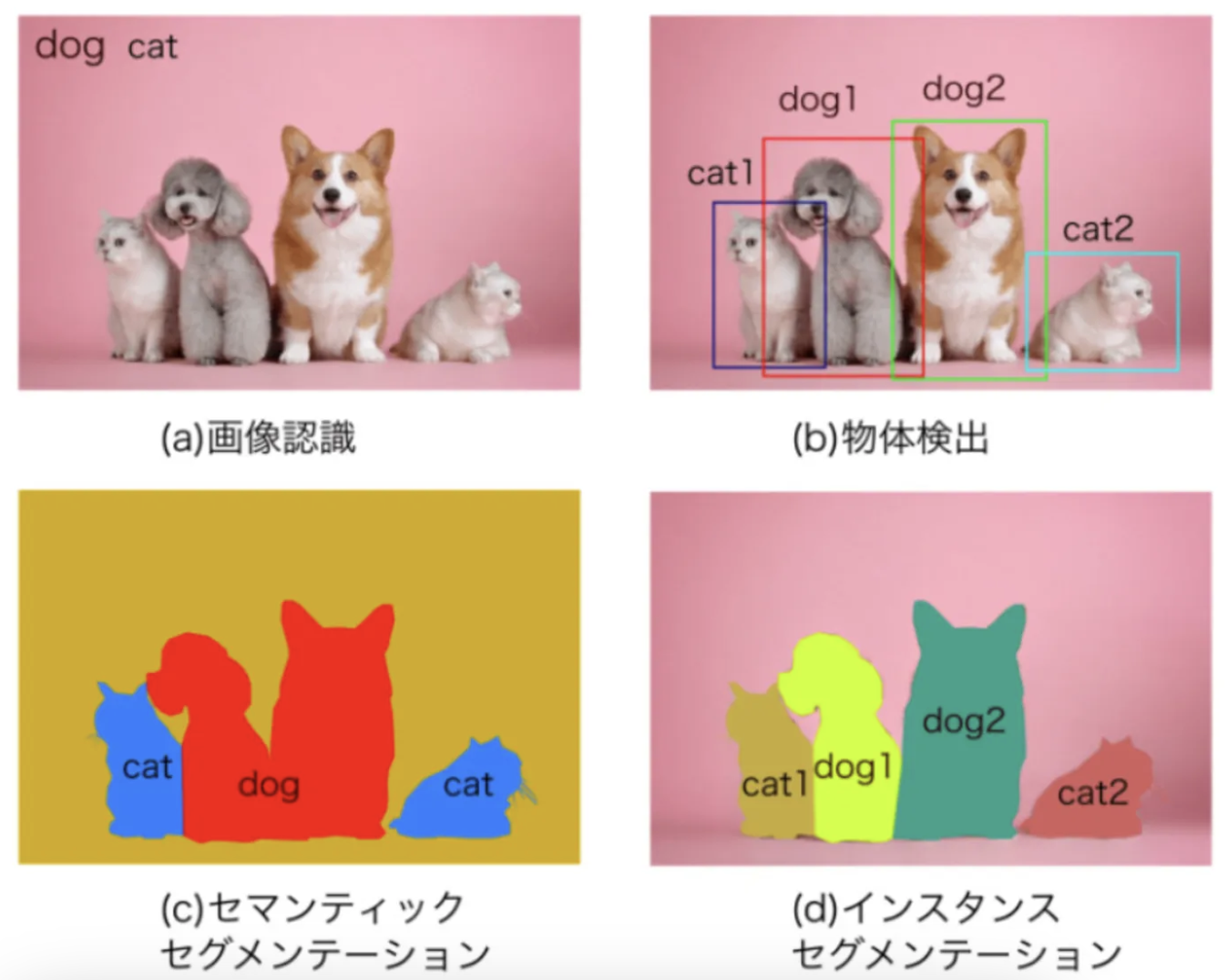
セマンティックセグメンテーション
『画像内の各ピクセルがどのクラスに属しているかを識別し、画像内の領域を分類する』
例えば、画像のどの部分が
- 「人」なのか
- 「車」なのか
- 「建物」なのか
物体や背景をピクセル単位で分類します。

アルゴリズム
セマンティックセグメンテーションに使用するアルゴリズム
- ピラミッドシーン解析 (PSP)
- DeepLab V3
ユースケース
- MRIやCTスキャンなどの医療画像の各ピクセルを解析し、健康な組織と異常な組織をピクセル単位で分類することができます。
- 自動運転車の視覚システムによって、安全に運転ができます。
インスタンスセグメンテーション
インスタンスセグメンテーションは、
『各オブジェクトの個別のインスタンスを識別する』
一方、セマンティックセグメンテーションは、同じクラスのオブジェクトを一括で分類します。
画像分類・物体検出との違い
画像分類
- 画像全体に対して1つのラベルを割り当てます。
- 例:「犬」や「猫」など、何が映っているかを判断しますが、画像内の具体的な位置情報は扱いません。
物体検出
- 画像内の複数の物体を検出し、それぞれの物体にバウンディングボックス(四角形の枠)を付けて、位置とクラス(例: 犬、猫)を同時に判定します。
セマンティックセグメンテーション
- 画像内の各ピクセルを特定のクラスに割り当てます。
- 例:画像内のすべての「犬」に対してピクセルごとにラベルを付け、形状や境界も明確にします。