学習率
『どれくらいのステップで機械学習モデルが学習していくか』
学習率の調整に失敗すると⋯
学習率が高すぎると、学習が不安定になります。具体的には、一度の更新で大きすぎるステップを取ってしまうため、最適な解を見つける前に飛び越えてしまうことがあります。その結果、収束しない、または精度が悪くなる可能性があります。

一方、学習率が低すぎると、モデルが誤差を適切に修正できなくなります。誤差とは、機械学習モデルが予測した結果と、実際の正解との間のズレのことです。

学習率の調整に成功すると
適切なステップ数で安定した学習が可能です。

エポック
『1つのトレーニングデータを1周したときを1とするとき、何回トレーニングデータを全て使い切ったかを表す数』
- 例えば、1,000件のデータを使ってモデルを訓練するとき、エポック数を10に設定すると、モデルは1,000件のデータを10回繰り返して学習することになります。
エポック数を増やす
モデルがトレーニングデータに複数回アクセスし、より多くの学習を行うため、精度が向上する可能性があります。エポックを増やすための時間やコストに余裕がある場合は、エポックを回すほど精度は高まります。
エポック数が多すぎると⋯(オーバーフィッティング)
モデルがトレーニングデータに過度に適合し、テストデータや実際のデータに対する汎化性能が低下する場合があります。
この現象が
『過学習』
です。

エポック数が少なすぎると⋯(アンダーフィッティング)
モデルが十分に学習せず、
『未学習・学習不足状態』
になります。

オーバーフィッティング
モデルがトレーニングデータに過剰に適合しすぎて、新しいデータに対して適切な予測ができなくなる状態を指します。これは、モデルがデータのノイズや例外的なパターンを学習してしまうことで起こり、汎用性が低下します。
アンダーフィッティング
モデルがデータの基本的な傾向やパターンを十分に学習できていない状態です。これは、モデルの複雑さが不十分で、重要な特徴を捉えられないため、トレーニングデータにも新しいデータにも適切に対応できません。
バッチサイズ
『機械学習モデルのトレーニング中に一度に処理するデータの量』
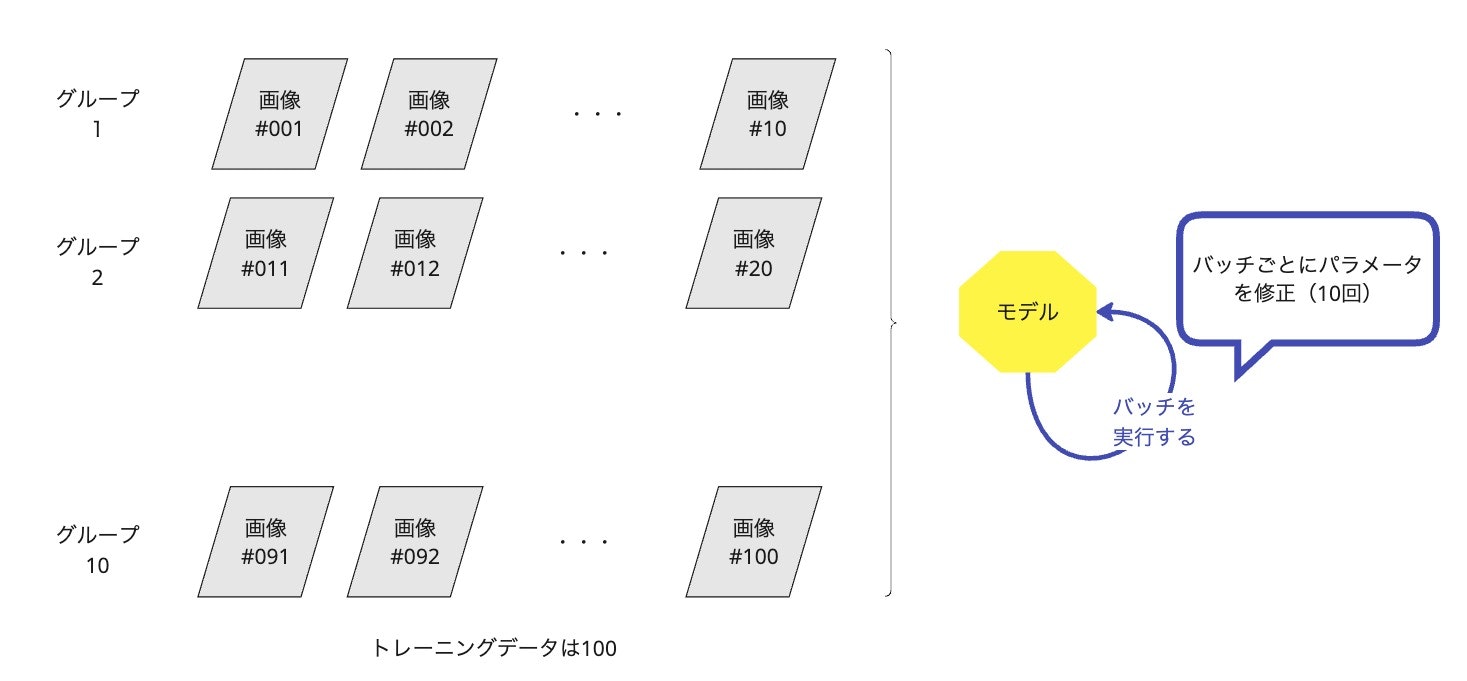
バッチサイズが大きいと⋯
学習速度が速くなるが、メモリ消費が増えます。
バッチサイズがトレーニングデータ全体のサイズと等しい場合、1エポックで1回だけ重みの更新が行われます。これにより学習の効率が低下することがあります。
バッチサイズが小さいと⋯
メモリ消費が少なく学習が安定しやすくなるが、速度が遅くなります。
バッチサイズがトレーニングデータ全体のサイズと等しい場合
1エポックで1回だけ重みの更新が行われます。
↓
これにより学習の効率が低下することがあります。
機械学習エンジニアは、今回紹介した学習率、バッチサイズ、エポック数を最適に調整することでモデルの性能が向上し、学習が効率的に進めることができます。
エポックによる過学習対策
一定のエポック数を過ぎると学習が停滞し、モデルの精度が向上しなくなることがわかりました。
学習減衰率
学習減衰率を導入することで、モデルの精度をさらに高めることができます。
これは、トレーニングが進むにつれて学習率を徐々に減少させる手法です。
- 前半:大きな学習率で迅速に損失を減少させる
- 後半:小さな学習率で細かな調整を行う
これにより、最適解に近づきます。
早期停止
早期停止(Early Stopping) を実施することで
『機械学習モデルのトレーニングにおいて、過学習(オーバーフィッティング)を防ぐ』
ことができます。
通常、モデルはエポックを繰り返すごとに学習を進め、パフォーマンスが向上します。
しかし、ある時点を過ぎると、モデルがトレーニングデータに過度に適合し、テストデータや実際のデータに対する汎化性能が低下する場合があります。
バリデーションデータセット
バリデーションデータセット を使用して、モデルがトレーニングデータに特化しすぎず、汎用的な性能 を維持できるようになります。
モデルが示している状態
適切な汎化
モデルがトレーニングデータに適応しすぎることなく(過適合を回避)、同時にデータ全体の本質的なパターンを捉えている状態を指します。この結果、トレーニングデータとテストデータの両方で低い誤差を達成します。
適切な汎化は、トレーニングデータとテストデータでの性能がバランスよく高い状態であり、モデルが適切に学習したことを示しています。
これは、 モデルのトレーニングとテストを繰り返し実施 することが必要になります。その結果、..
- トレーニングデータに対する誤差とテストデータに対する誤差が共に小さい
- モデルの予測精度が一貫して高い
過適合
トレーニングデータに過度に適応し、テストデータに対する誤差が大きい状態です。
過少適合
モデルがトレーニングデータにも十分適応しておらず、全体的な誤差が大きい状態です。
不安定な学習
トレーニングの途中で誤差が急激に変動し、収束しない状態です。