はじめに
本記事は、Googleデータアナリティクスのプロフェッショナル認定証のプログラムより、参照させて頂いています。興味を持った方は、是非受講してみてください。

SQLのCOUNT と COUNT DISTINCT
データアナリストとして COUNT と COUNT DISTINCT は 「いくつか」という問いかけの答えを求める時に 使える関数です。
- COUNT は指定した範囲内の行数を 返すクエリですが COUNT DISTINCTは少し違います。
- COUNT DISTINCT は その範囲内の固有の値のみを返すクエリです。 基本的に、COUNT DISTINCTは 重複する値を数えません。
例えば、
- 何人の顧客が商品を購入したのか?
- 今月は何件の取引があったのか?
- このデータセットには いくつの日付があるのか?
データ分析の過程では、さまざまな場面で これらを使うことになります。
例えば、
- データクリーニングをしているときに データセットに何行あるかチェックするのに 必要かもしれません。
- 実際の分析中に COUNT や COUNT DISTINCT を使い いくつ、という問いかけに答えることも あるかもしれません。
例
靴下を製造している会社を 例にとって考えます。 2 つのテーブルがあります。
Warehouse (倉庫状況)テーブル
倉庫の ID や名称、 最大収容数や従業員総数、 倉庫の所在地を表す州名の 各列があります。

Orders(受注状況)テーブル
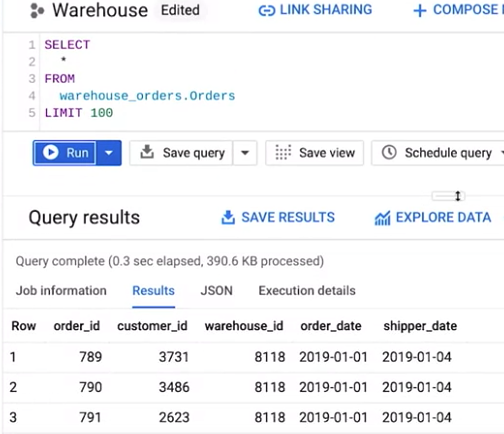
次に、Orders テーブルの 上位 100 行を取得します。
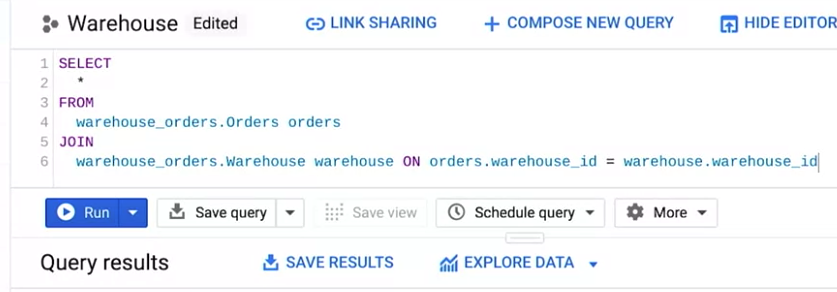
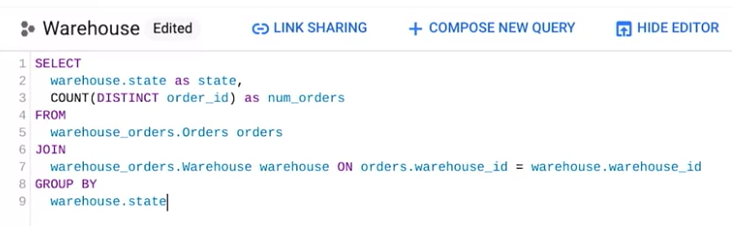
ここでは、州ごとの受注状況を レポートするために、 倉庫の詳細と受注の詳細の 両方が必要だとします。 そこで、この 2 つのテーブルを JOIN して 両方のデータを取得します。 ここで warehouse テーブルのエイリアスも 作成しておきましょう。 この場合、両方のテーブルに 対応するデータが必要なので JOIN は INNER JOIN の略語として使用します。
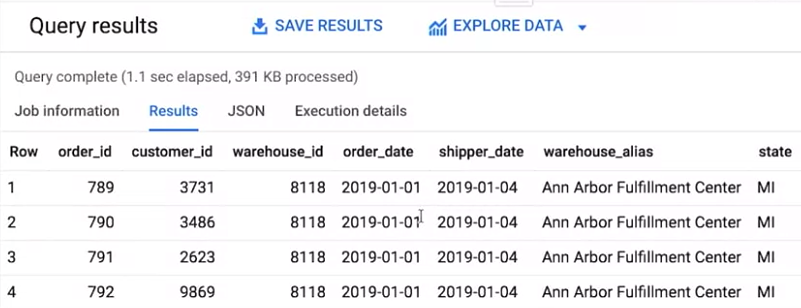
エイリアスを設定したところで FROM の前に来る SELECT 構文を 作成します。これを実行します。

すると、このように表示されます。 これで、両方のテーブルのデータが結合され 便利なエイリアスも作成できました。
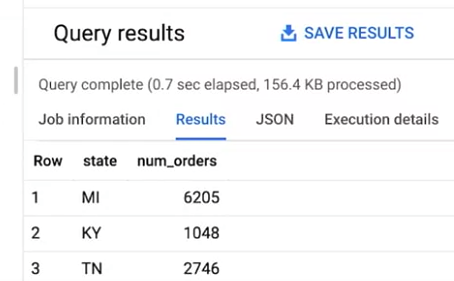
ここで、受注状況データの中に いくつの州があるのか、数えてみたいと思います。 これを行うには、COUNT と COUNT DISTINCT を使います。
まず、簡単な COUNT クエリを試してみましょう。 FROM 構文で、Orders テーブルと Warehouse テーブルを JOIN します。 この場合は SELECT で始めて 州の数をカウントします。

このクエリを実行して、何が得られるか 見てみましょう。 いや、ちょっと違うようですね。 このクエリは 9,000 以上の州を返していますが これは州を含む行を 1 つ 1 つ数えているからです。 しかし、ここでやりたいのは 個々の州を数えることです。
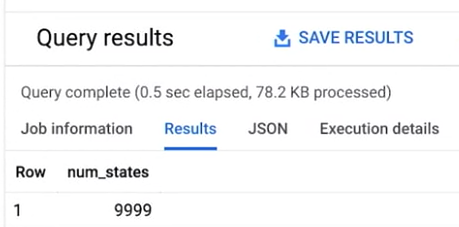
そこで COUNT DISTINCT を もう一度試してみましょう。 そして、倉庫テーブルの州列で グループ化してみます。
これで各州の行が 3 行になり Orders データから 1 つずつ表示されました。 受注数に対する COUNT DISTINCT は 先ほど実行したカウントを合計したものです。 3 つの合計は、9,999 となるはずです。