はじめに
- Tellus GPUサーバ(高火力コンピューティング)での機械学習環境構築について、手順を記載
- 動作確認として以下の3つの項目を確認
- PyTorchを用いたディープラーニングモデルのGPU学習
- MLFlowを用いた実験記録閲覧
- QGISを用いたサーバ内データ確認
検証環境
| Item | Version |
|---|---|
| OS | Ubuntu 18.04 |
| OpenSSH | 7.6p1 |
GPUサーバの申込み(Tellus経由)
Tellus
- Tellus
- 日本初の衛生データプラットフォーム
- データの取得だけでなく、開発環境の無償提供もしている(JupyterLab or GPUサーバ)
GPUサーバについて
- さくら高火力コンピューティングラインナップ
- 普通に借りようとすると100万円くらい
- レンタル期間はあるが期間内であれば使用時間制限はない
- 最終アクセスから1ヶ月アクセスしていないとレンタル終了とみなされる
- google colaboratoryだと90分/12時間ルールが存在
| Item | Spec |
|---|---|
| OS | Ubuntu 18.04(64bit) |
| GPU | NVIDIA Tesla V100 (32GB) ×1 |
| CPU | Xeon 4Core 3.7GHz 1CPU |
| Disk | MLC SSD 480GB ×2 |
| Memory | 64GB |
申し込みの流れ
- Tellusに会員登録(無料)後、開発環境の申込みを行う
- 費用は無料
- 期間は1ヶ月, 3ヶ月 or それ以上(要相談)が選択できる
- 利用期間終了後であれば更新できる
- 申し込んでからしばらく経つと運営からログインIDの連絡が来る
- サーバの空き具合によって前後するが約1ヶ月程度
環境構築(GPU)
基本はCUDA Toolkit/GPUカードドライバー導入手順の手順に従う
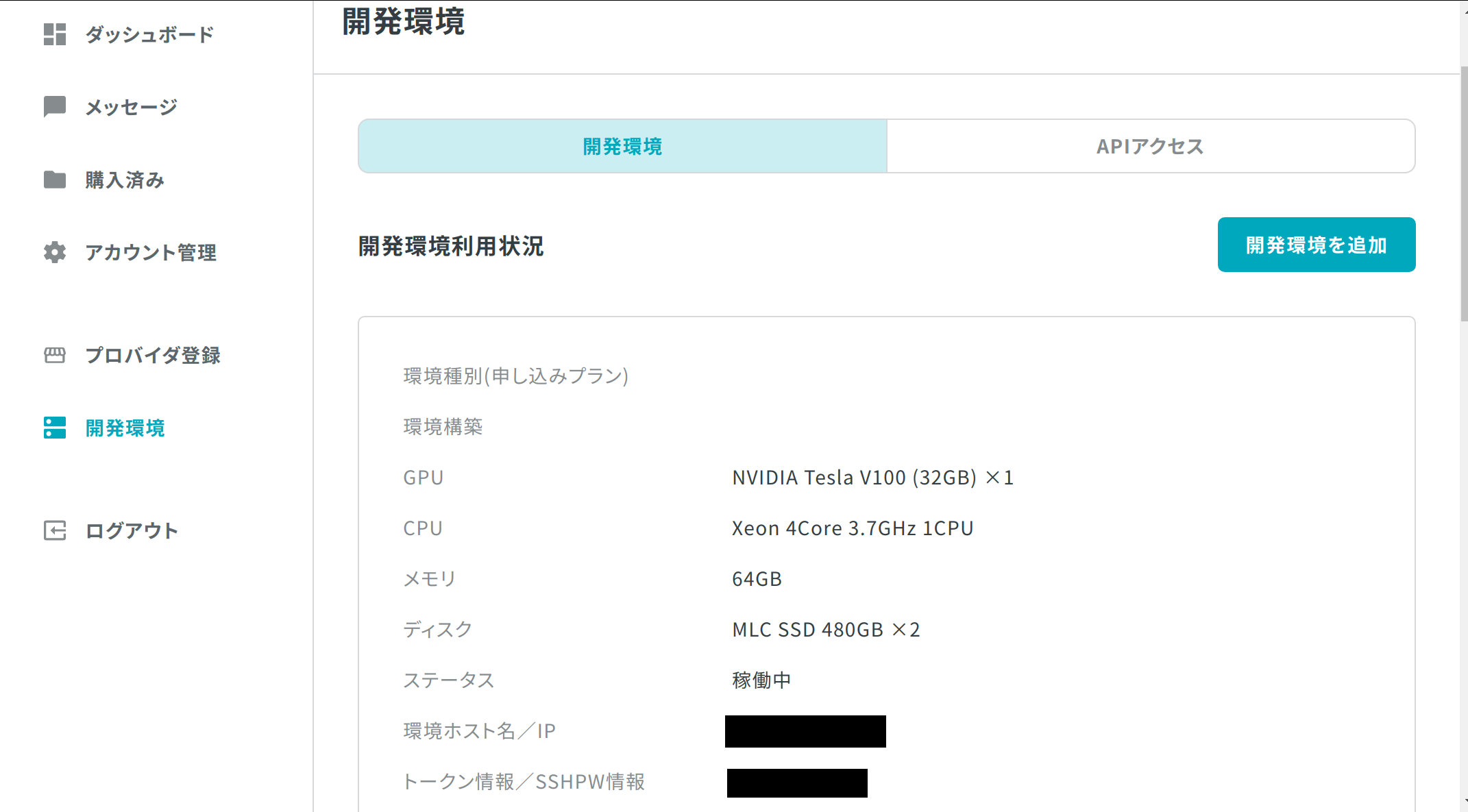
サーバ情報
Tellusアカウントのダッシュボード → 開発環境を参照
| Item | 対応項目 |
|---|---|
| サーバIP | 環境ホスト名/IP |
| ログインID | 運営からメールで送られてくる |
| 初期パスワード | トークン情報/SSHPW情報 |
サーバへの接続
-
~/.ssh/configにサーバへの接続情報を記載
~/.ssh/config
Host tellus
HostName [環境ホスト名/IP]
User [ログインID]
IdentityFile ~/.ssh/id_rsa
- Terminal上で
ssh tellusと入力、パスワードを聞かれるので初期パスワードを入力すれば接続完了
パッケージのアップデートとインストール
GPUドライバを入れる前の下準備
sudo apt update
sudo apt upgrade
apt install build-essential
apt install dkms
CUDA Toolkit
- CUDA Toolkit Archive
- 2020/09/09現在での最新版のCUDAは11.0
- PyTorch 1.6(最新版)で対応しているのは10.2までなのでダウングレードが必要
- runfile以外を使用すると、バージョン指定しても何故か11.0がインストールされたので必ずrunfile(local)を使用すること
- runfile実行時にsudoを抜かすとインストールに失敗したので追加
wget http://developer.download.nvidia.com/compute/cuda/10.2/Prod/local_installers/cuda_10.2.89_440.33.01_linux.run
sudo sh cuda_10.2.89_440.33.01_linux.run
chmod +x cuda_10.2.89_440.33.01_linux.run
sudo ./cuda_10.2.89_440.33.01_linux.run --toolkit --samples --samplespath=/usr/local/cuda-samples --no-opengl-libs
- 環境変数の設定ファイル作成後、ログアウトし再度ログイン
/etc/profile.d/cuda.sh
export CUDA_HOME="/usr/local/cuda"
export PATH="$CUDA_HOME/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/lib:$CUDA_HOME/lib64:$LD_LIBRARY_PATH"
export CPATH="/usr/local/include:$CUDA_HOME/include:$CPATH"
export INCLUDE_PATH="$CUDA_HOME/include"
/etc/profile.d/cuda.csh
export CUDA_HOME="/usr/local/cuda"
export PATH="$CUDA_HOME/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/lib:$CUDA_HOME/lib64:$LD_LIBRARY_PATH"
export CPATH="/usr/local/include:$CUDA_HOME/include:$CPATH"
export INCLUDE_PATH="$CUDA_HOME/include"
CUDA Driver
- CUDA Driver Download
- CUDA ToolkitでインストールできるDriverは古いため別途インストール
- Toolkitと同じく実行時にsudoを追加
wget https://us.download.nvidia.com/tesla/440.95.01/NVIDIA-Linux-x86_64-440.95.01.run
chmod +x NVIDIA-Linux-x86_64-440.95.01.run
sudo ./NVIDIA-Linux-x86_64-440.95.01.run --no-opengl-files --no-libglx-indirect --dkms
cuDNN
- NVIDIA cuDNN
- 会員登録が必要(無料)
- クライアント側でダウンロードし、scpでサーバへ転送
- 転送後、解凍し中身を所定のディレクトリに移す
client
scp -r cudnn-10.2-linux-x64-v8.0.3.33.tgz tellus:~/
server
tar xvzf cudnn-10.2-linux-x64-v8.0.3.33.tgz
sudo mv cuda/include/cudnn.h /usr/local/cuda/include/
sudo mv cuda/lib64/* /usr/local/cuda/lib64/
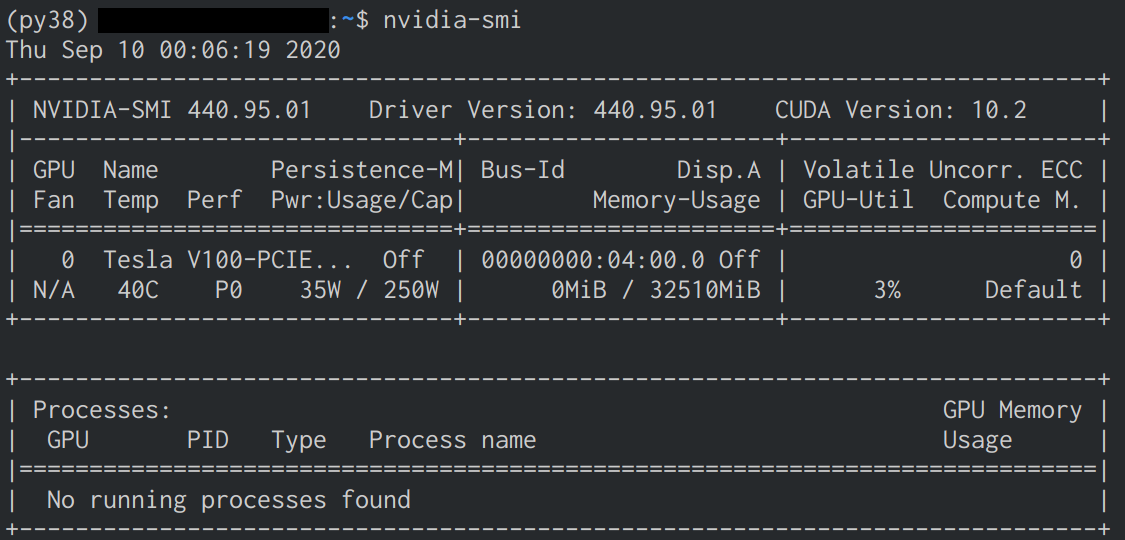
インストール確認
-
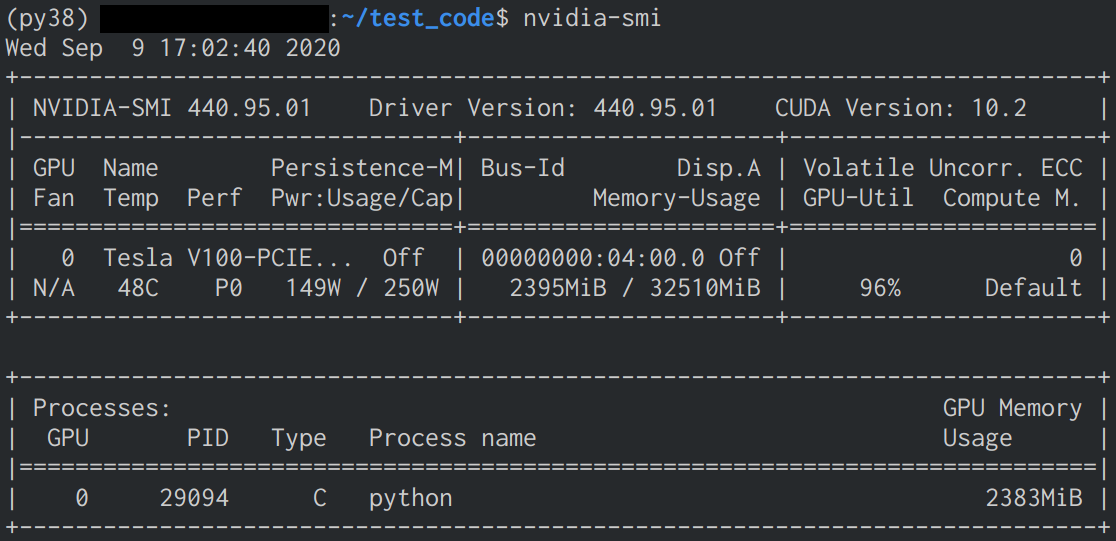
nvidia-smiで確認 - インストールに成功していると下の画像のような表示が確認できる
環境構築(Python)
Anaconda
- Anaconda
- インストール後、環境を作るかはお好みで
wget https://repo.anaconda.com/archive/Anaconda3-2020.07-Linux-x86_64.sh
sudo bash Anaconda3-2020.07-Linux-x86_64.sh
conda update -n base conda
- 環境を作った際、そのままだと動かなかったので
.bashrcに以下を追加(py38は環境名)
.bashrc
export PYTHONPATH="/home/[ログインID]/anaconda3/envs/py38/lib/python3.8:/home/[ログインID]/anaconda3/envs/py38/lib/python3.8/site-packages:$PYTHONPATH"
PyTorch
- PyTorch get-started
- conda以外を使用する場合はPackage部分を変えてコマンドを確認
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
MLFlow
- MLFlow
- 機械学習の実験管理ライブラリ
conda install -c conda-forge mlflow
-
mlflow uiと入力するとlocalhost:5000にUIが立ち上がり、ブラウザで実験結果の確認が出来る
-
サーバ側でUIを立ち上げた時にクライアント側のブラウザで閲覧出来るようにするため、
~/.ssh/configにLocalForwardの設定を追加する
~/.ssh/config
Host tellus
HostName [環境ホスト名/IP]
User [ログインID]
IdentityFile ~/.ssh/id_rsa
LocalForward [クライアント側のポート番号] localhost:5000
QGIS
- QGIS
- GeoTiffやShapefileなどの地理情報付きデータのビューワ
- 地理情報がついていない普通の画像も閲覧可能
- 最新版(3.14.15)だと動かなかったので3.10.8を使用
- libprotobuf-lite.so.23がないというエラー
conda install -c conda-forge qgis=3.10.8
動作確認
GPU学習
- CPUとGPUの2つのモードで実行し、処理時間に差が出るか確認
- コード実行時に
nvidia-smiでGPUのMemoryとVolatileを確認 - コードはPyTorchのCIFAR10 Tutorialを参考に下記の部分を変更
- モデルはResNet-18
- バッチサイズを1024、Worker数を8(= サーバのコア数)
- CPU実行は
device = torch.device("cpu")に書き換えて実行
cifar10.py
import os
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.models as models
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10
from tqdm import tqdm
batch = 1024
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def dataloader(is_train: bool, transform: transforms.Compose) -> DataLoader:
dataset = CIFAR10(root='./data', train=is_train, download=True, transform=transform)
return DataLoader(dataset, batch_size=batch, shuffle=is_train, num_workers=os.cpu_count())
def model() -> nn.Module:
model = models.resnet18(pretrained=True)
model.fc = nn.Linear(512, 10)
return model.to(device)
def training(net: nn.Module, trainloader: DataLoader, epochs: int) -> None:
# loss function & optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(epochs): # loop over the dataset multiple times
running_loss = 0.0
bar = tqdm(trainloader, desc="training model [epoch:{:02d}]".format(epoch), total=len(trainloader))
for data in bar:
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data[0].to(device), data[1].to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
bar.set_postfix(device=device, batch=batch, loss=(running_loss / len(trainloader)))
print('Finished Training')
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainloader = dataloader(True, transform)
net = model()
training(net, trainloader, 3)
CPU結果

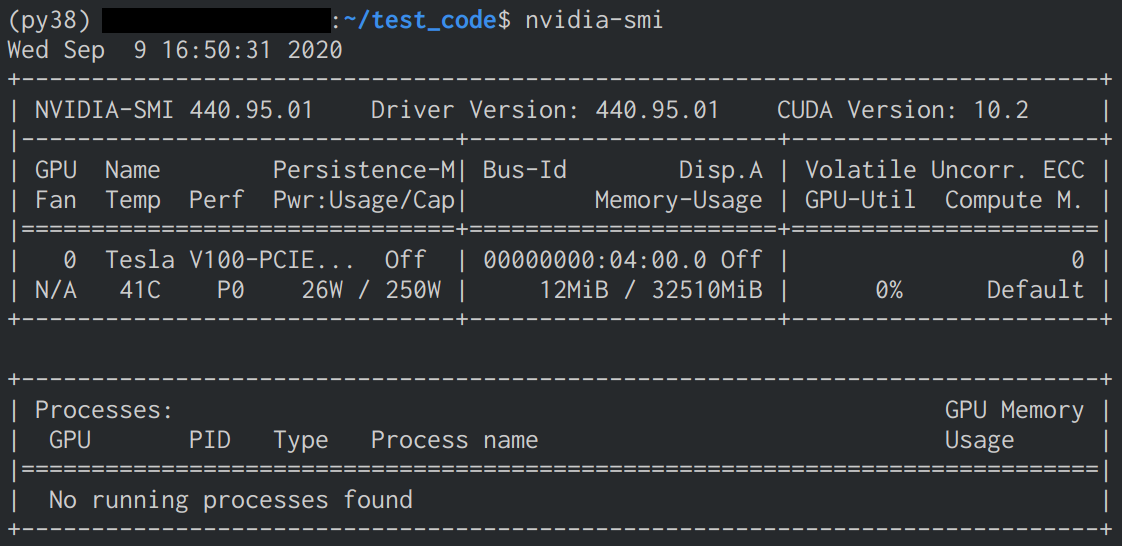
GPU結果

- GPU使用により約36倍高速化したことを確認
- GPU使用時にMemoryとVolatileの数値が変化したことを確認
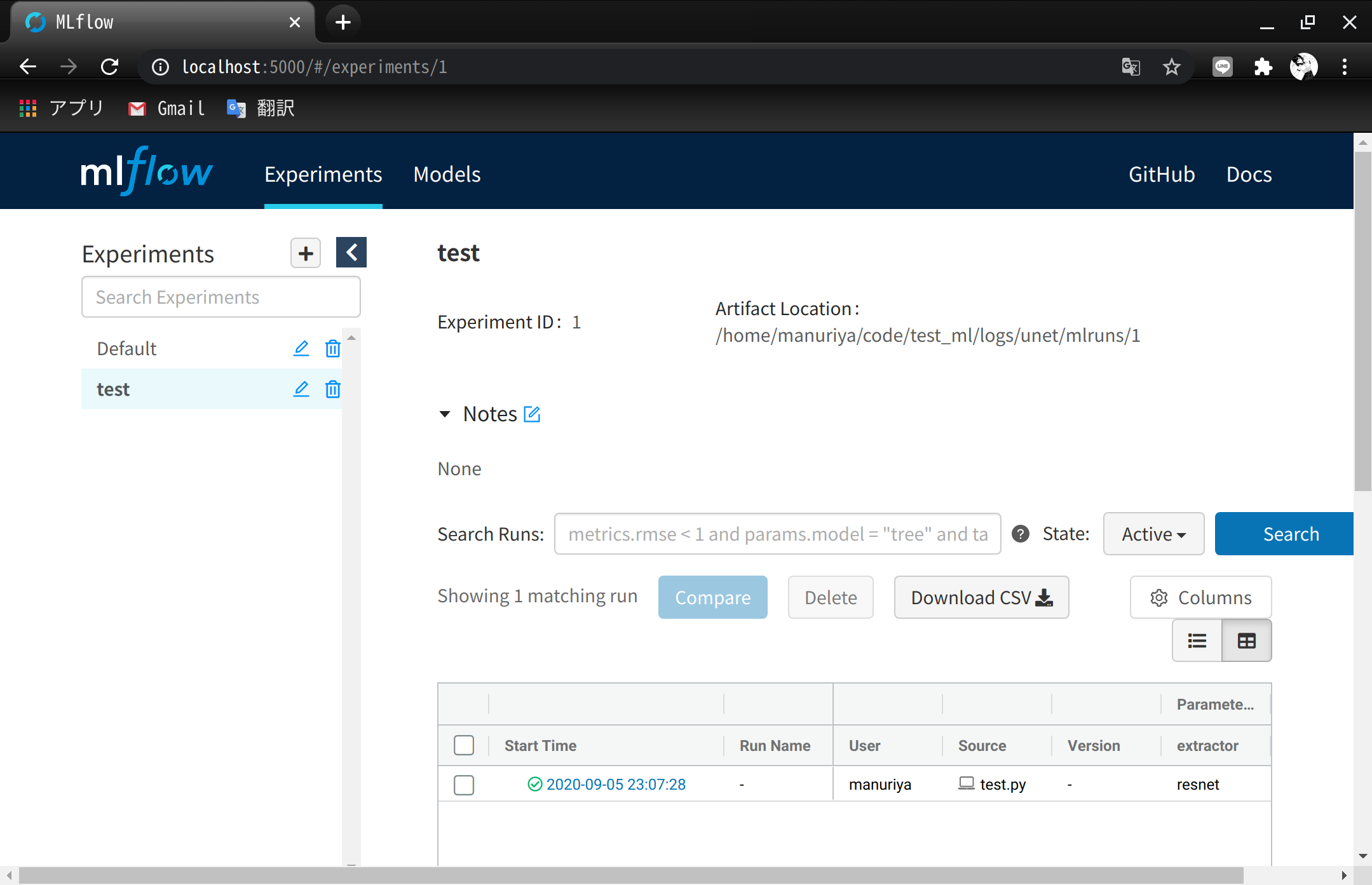
MLFlow
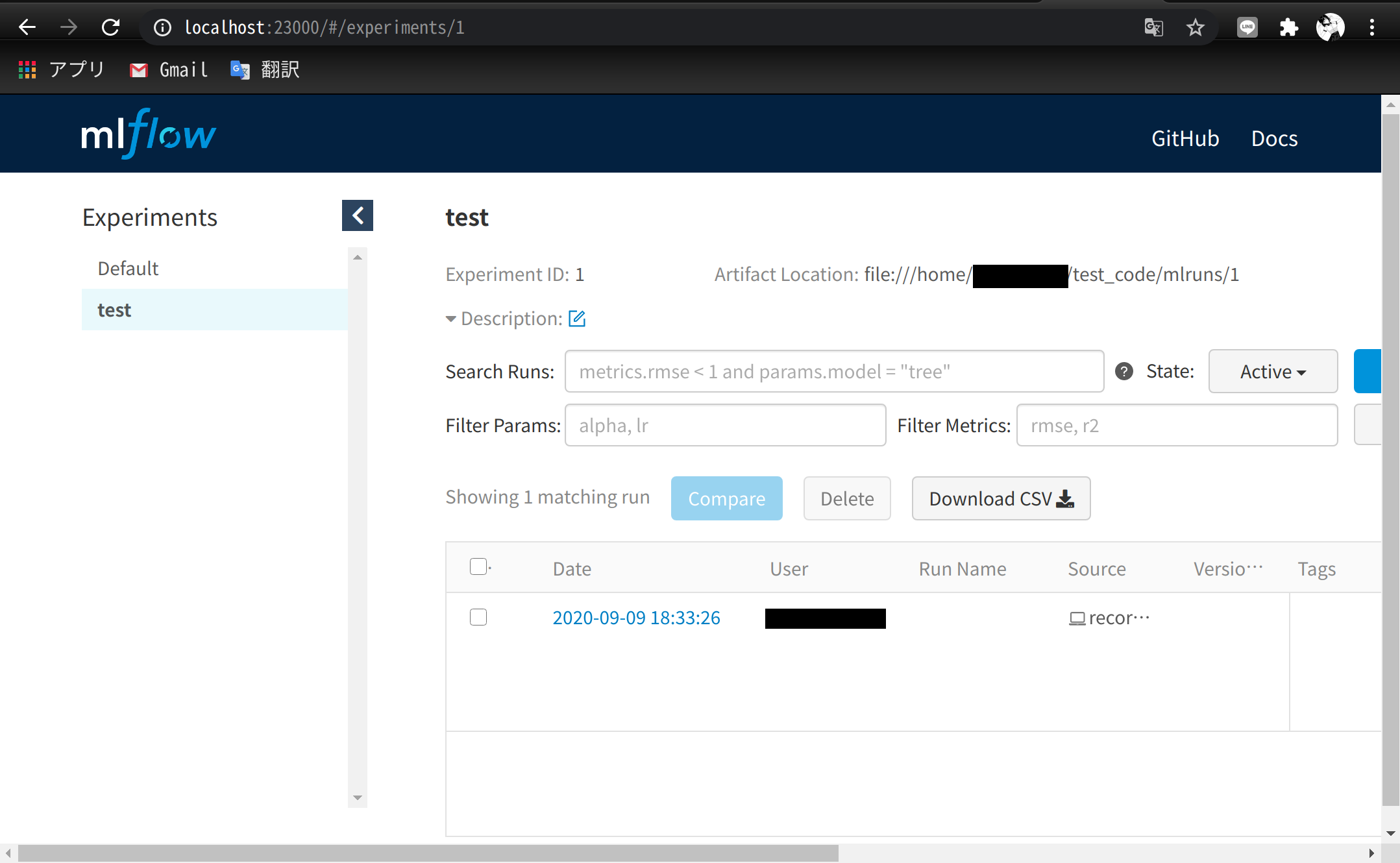
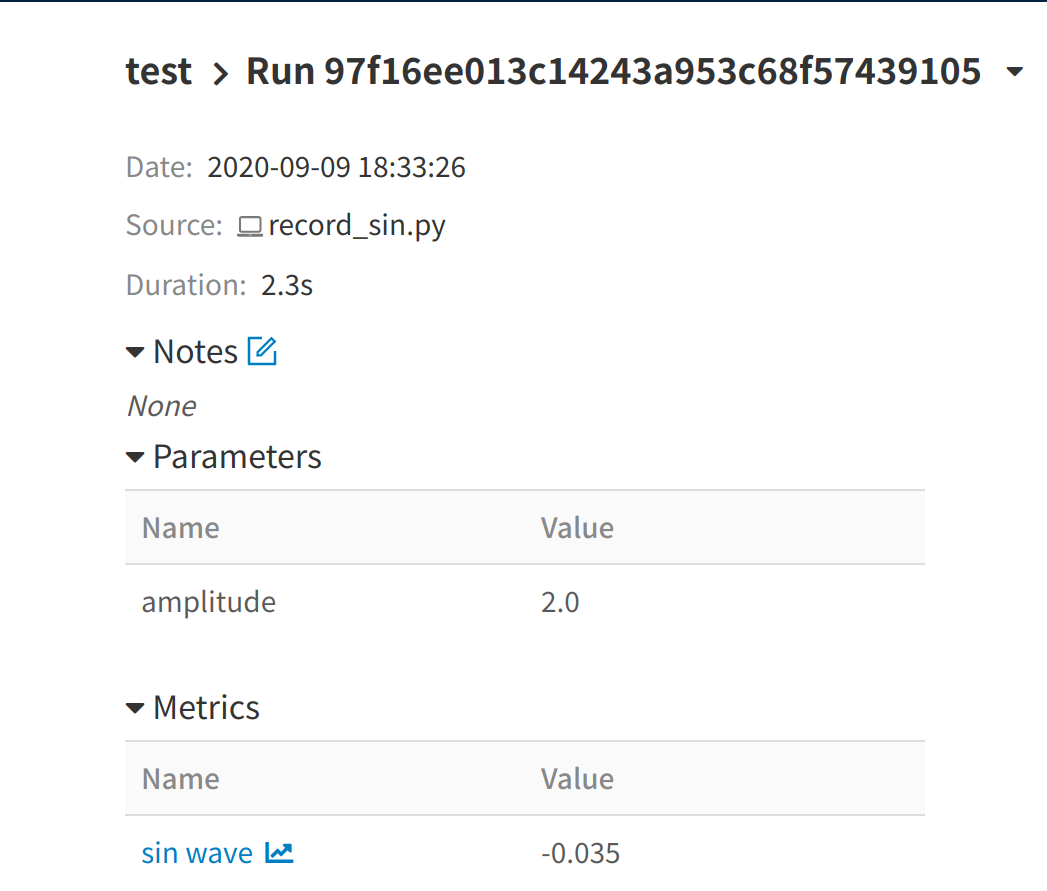
- サーバ上の実験記録がクライアント側のブラウザで閲覧できるか確認
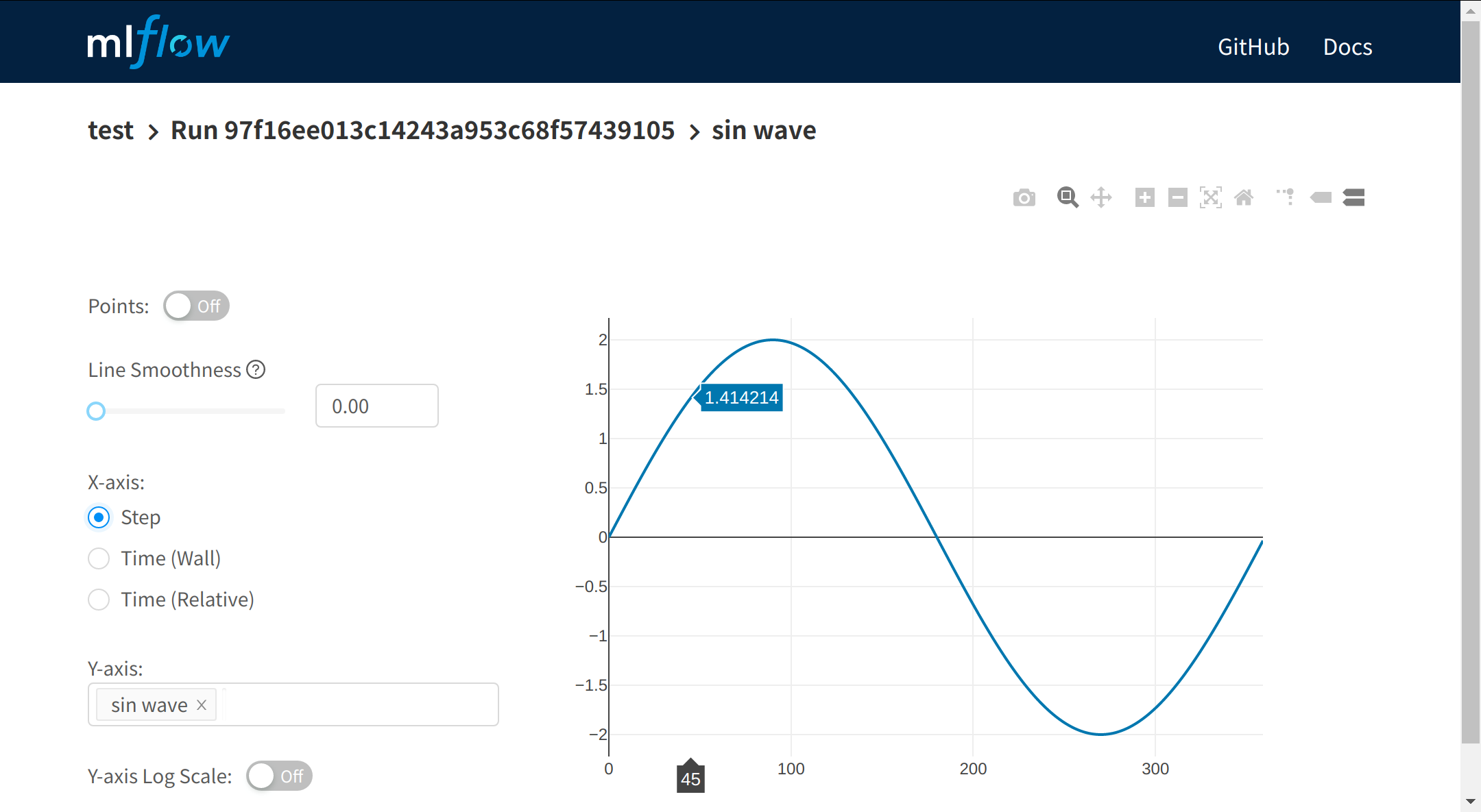
- 実験コードは振幅を2倍にしたSin波形のグラフ保存
- LocalForwardのポート番号は23000で確認
record_sin.py
from math import pi, sin
import mlflow
mlflow.set_experiment('test')
amplitude = 2.0
with mlflow.start_run() as _:
mlflow.log_param('amplitude', amplitude)
for i in range(360):
sin_val = amplitude * sin(i * pi / 180.)
mlflow.log_metric('sin wave', sin_val, step=i)
~/test_code/
python record_sin.py
mlflow ui
結果画像
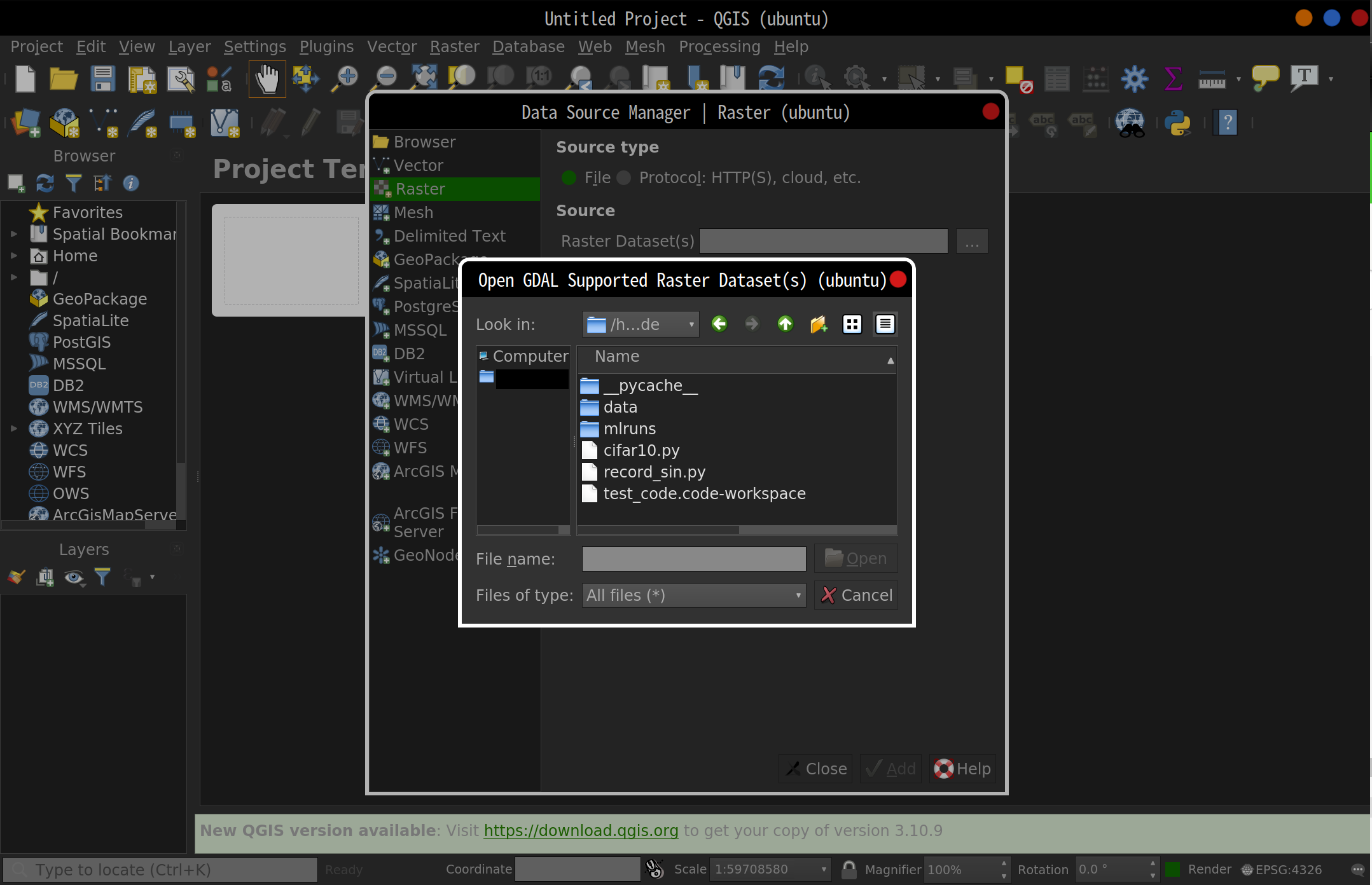
QGIS
- Data Source Managerでサーバ側のコード(test_code)が閲覧できるか確認
ssh -X tellus
qgis
- 先程の
cifar10.pyとrecord_sin.pyがあることを確認
VSCodeの使用
- sshが使えるのでVSCodeのRemote Developmentも使用可能
- VSCodeでjupyter notebookファイルを作成する場合はipykernelのインストールが必要
conda install -c conda-forge ipykernel
おわりに
- CUDA Toolkitインストールでdebファイルを選んで無駄な時間を使ったので手順をまとめました
- QGISの部分は他のビューワに置き換えてもほぼ同じ手順でいけるはず
- 高火力コンピューティングに限らず他のGPUサーバでもある程度使える手順かと思います