以前 Spark を使ってたのですが今は使ってなくて,
そのうち忘れそうなので基本をメモしておくことにしました.
(全体的に聞きかじりの知識なので間違ってる点はコメント・編集リクエストを期待します)
使う
Jupyter + PySpark な環境が動く Docker イメージが用意されているので,ローカルで試すには便利です:
https://hub.docker.com/r/jupyter/pyspark-notebook/
PySpark とは,という話ですが,Spark 自体は Scala だけど,
Python で使えるやつがあってそれが PySpark だという話があります.
IPC でがんばってるという仕組みになっていたはずなので,
Scala <-> Python の変換のコストが結構でかいうんぬんみたいな話題もあります.
さて,使ってみましょう:
docker run -it -p 8888:8888 jupyter/pyspark-notebook
これを実行すると Terminal に 8888 番にトークンがついた URL が流れてくるので,
(To access the notebook, ... のあたり)
おもむろにアクセスすると Jupyter のページが出てきて,
Jupyter Notebook でコーディングできる簡単環境のできあがりです.
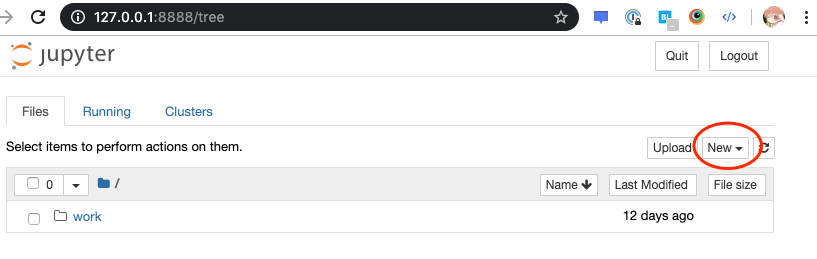
ここの New から Notebook: Python3 を選択すれば Notebook を開けます
試す
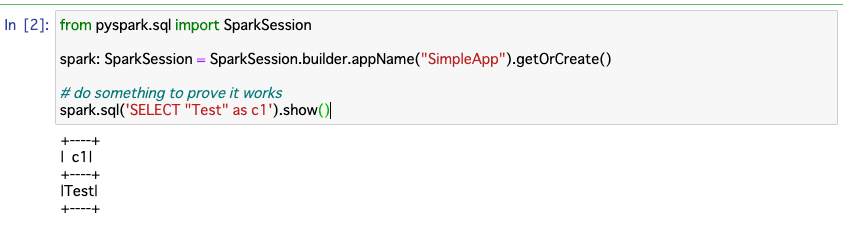
動くかどうかのテストコードは以下で,サンプルからとってきました (https://jupyter-docker-stacks.readthedocs.io/en/latest/using/specifics.html#in-a-python-notebook):
from pyspark.sql import SparkSession
spark: SparkSession = SparkSession.builder.appName("SimpleApp").getOrCreate()
# do something to prove it works
spark.sql('SELECT "Test" as c1').show()
SparkSession というやつはよくわからないけど,
Spark 自体のインスタンスみたいなものという認識です.
これを実行して表がでれば OK です:
データを扱う
こういうデータを対象にしてみましょう:
id |
name |
gender |
age |
|---|---|---|---|
| 1 | サトシ | male | 10 |
| 2 | シゲル | male | 10 |
| 3 | カスミ | female | 12 |
入力と定義
Python で素朴にデータを定義するとこうなりますね:
from typing import List, Tuple
Trainer = Tuple[int, str, str, int]
trainers: List[Trainer] = [
(1, 'サトシ', 'male', 10),
(2, 'シゲル', 'male', 10),
(3, 'カスミ', 'female', 12),
]
各行の型は Python の typing でいう Tuple[int, str, str, int] となりますね.
で,Spark でもスキーマの定義があります:
from pyspark.sql.types import StructField, StructType, StringType, IntegerType
trainers_schema = StructType([
StructField('id', IntegerType(), True),
StructField('name', StringType(), True),
StructField('gender', StringType(), True),
StructField('age', IntegerType(), True),
])
これで Spark 側での列のスキーマを定義できます.
Python で定義したデータを Spark の DataFrame に変換するにはこうします:
from pyspark.sql import DataFrame
trainers_df: DataFrame = spark.createDataFrame(
spark.sparkContext.parallelize(trainers),
trainers_schema
)
これで trainers_df という DataFrame ができました.
データソースとして CSV とか MySQL とかそういうものから読み込めるので,
実際にはコード上で定義するよりそういうデータソースから読み込むことになるでしょう.
(場合により後述する JDBC とか,Hadoop の設定が必要です)
これをダンプして確認したい場合はこうします:
trainers_df.show()
そうすると,表に整形されたテキストが数行出力されます:

+---+------+------+---+
| id| name|gender|age|
+---+------+------+---+
| 1|サトシ| male| 10|
| 2|シゲル| male| 10|
| 3|カスミ|female| 12|
+---+------+------+---+
集計と出力
ダンプではなく値をもらうには .collect() すればいいです:
result = trainers_df.collect()
print(result)
CSV に書き出すときはこういう雰囲気で DataFrame を書き出します:
trainers_df.coalesce(1).write.mode('overwrite').csv("path/to/output.csv")
入力同様,他にも S3, MySQL とか Elasticsearch とかいろいろ出力先がある雰囲気です.
.coalesce(1) はパーティションごとの分割されているデータを,
1つのパーティションに coalesce するというものです.
こうしないと,分割されたまま CSV 出力されます.
Hadoop の hdfs コマンドをつかって,
分割されたものを1つにまとめて取得するという手段もあります.
基本的に遅延評価になっていて,
.collect() みたいな操作をしてはじめて評価されるようになっているので,
そんなに頻繁に集計はしないはずです.
基本
これだけではただ表示しただけでまったく意味がないので適当な操作をしてみましょう:
trainers_df.createOrReplaceTempView('trainers');
male_trainers_df = spark.sql('''
SELECT *
FROM trainers
WHERE gender = 'male'
''')
male_trainers_df.show()
これはこういう結果を得ます:
id |
name |
gender |
age |
|---|---|---|---|
| 1 | サトシ | male | 10 |
| 2 | シゲル | male | 10 |
DataFrame.createOrReplaceTempView(name) は DataFrame を,
一時的な SQL の View として登録することができるものです.
これで spark.sql(query) で登録した View を対象に SQL の操作した結果の DF を得ることができるので,
こうすれば,全く臆することなく慣れ親しんだ SQL を使って Spark を使うことができて,
心理的障壁も学習コストも低いというマジックになっています.
View に登録しなくても,DataFrame のままコードで記述するという方法もあります:
male_trainers_df = trainers_df.filter(trainers_df['gender'] == 'male')
こっちのほうが使いやすいケースもあるのでケースバイケースですね.
応用
SQL を使うことができるのだから,基本的な操作では別に問題ないのですが,
たいてい Spark を使いたいケースというのはなにかユーザー定義の操作をしたい状況になっていそうですね.
たとえば自分が過去やりたかったケースとしては,
「記事本文を形態素解析して分かち書きする」というものがあって,
これは SQL だけでは実現しがたいですね.
ただ,Python 上であれば MeCab があるので,
MeCab のライブラリを使って形態素解析してやれば何も考えなくても分解されてやってくるので,
僕のように全然わかってなくてもとりあえず MeCab に投げればいけるという手段をとれます.
そういう操作を Spark 上で DataFrame に対して行うにはどうすればいいかというと,
UDF (User-Defined Function) を定義するといいです.
(※ DataFrame ではなく RDD というものに対しては直接 lambda を適用できるという技がありますが,
これはパフォーマンスが悪いというのがあります).
UDF を定義するには次のような定義を行います:
from pyspark.sql.functions import udf
@udf(StringType())
def name_with_suffix(name: str, gender: str) -> str:
return name + {'male': 'くん', 'female': 'さん'}.get(gender, '氏')
spark.udf.register('name_with_suffix', name_with_suffix)
UDF となる関数に @udf(ReturnType) デコレーターを適用することで,
その関数は UDF として定義できるようになります.
それを Spark SQL で使うには spark.udf.register(udf_name, udf) して登録すれば,
COUNT() とかと同じ用にそのまま使えます.
ちなみにデコレーターを使わなくても,udf_fn = udf(fn) すれば既存の関数を適用できます.
この例としてあげたものは gender に応じて,
name に gender に応じた suffix をつけるというものです.
この関数を UDF として適用してみましょう:
dearest_trainers = spark.sql('''
SELECT name_with_suffix(name, gender)
FROM trainers
''')
dearest_trainers.show()
結果はこうなります:
name_with_suffix(name, gender) |
|---|
| サトシくん |
| シゲルくん |
| カスミさん |
今回の例であれば SQL でも CASE を駆使して書けるというご意見がありますが,そのとおりです.
やりたいことによっては便利に使えるでしょう.
UDF
さて,前述した形態素解析して分かち書きするというものですが,
これはイメージとしてこのような関数になります
(実際には MeCab をカッコよく使います):
import re
# 半角/全角スペースや約物で文字列を分割する
@udf(ArrayType(StringType()))
def wakachi(text: str) -> List[str]:
return [
word
for word
in re.split('[ !…]+', text)
if len(word) > 0
]
これを適用するのも同じくそのまま使えば OK です.
サンプルコードを今一度データを変更しつつ書いてみます:
Trainer = Tuple[int, str, str, int, str]
trainers: List[Trainer] = [
(1, 'サトシ', 'male', 10, 'ポケモン ゲット だぜ'),
(2, 'シゲル', 'male', 10, 'このおれさまが せかいで いちばん! つよいって ことなんだよ!'),
(3, 'カスミ', 'female', 12, 'わたしの ポリシーはね… みず タイプ ポケモンで せめて せめて …せめまくる ことよ!'),
]
trainers_schema = StructType([
StructField('id', IntegerType(), True),
StructField('name', StringType(), True),
StructField('gender', StringType(), True),
StructField('age', IntegerType(), True),
])
trainers_df = spark.createDataFrame(
spark.sparkContext.parallelize(trainers),
trainers_schema
)
trainers_df.createOrReplaceTempView('trainers');
wakachi_trainers_df = spark.sql('''
SELECT id, name, wakachi(comment)
FROM trainers
''')
wakachi_trainers_df.show()
ここでポイントになるのは,
今回の UDF は str を受け取って List[str] として展開するということですね.
これを実行してみるとこうなります:
id |
name |
wakachi(comment) |
|---|---|---|
| 1 | サトシ | [ポケモン, ゲット, だぜ] |
| 2 | シゲル | [このおれさまが, せかいで, い... |
| 3 | カスミ | [わたしの, ポリシーはね, みず... |
展開されたセルはリストになっていて,
列のなかに更に列がある入れ子状態になっています.
これをそれぞれの str を列として展開したい場合どうすればいいかというと,
展開する関数を更に適用すればいいです:
from pyspark.sql.functions import explode
wakachi_trainers_df = spark.sql('''
SELECT id, name, explode(wakachi(comment))
FROM trainers
''')
wakachi_trainers_df.show()
explode という関数があるので,
これを適用すれば入れ子になった要素がそれぞれの列として展開されます:
id |
name |
col |
|---|---|---|
| 1 | サトシ | ポケモン |
| 1 | サトシ | ゲット |
| 1 | サトシ | だぜ |
| 2 | シゲル | このおれさまが |
| 2 | シゲル | せかいで |
| 2 | シゲル | いちばん |
| 2 | シゲル | つよいって |
| 2 | シゲル | ことなんだよ |
| 3 | カスミ | わたしの |
| 3 | カスミ | ポリシーはね |
| 3 | カスミ | みず |
| 3 | カスミ | タイプ |
| 3 | カスミ | ポケモンで |
| 3 | カスミ | せめて |
| 3 | カスミ | せめて |
| 3 | カスミ | せめまくる |
| 3 | カスミ | ことよ |
ジョイン
さらなるポイントとして DataFrame どうしの JOIN ができます.
普通の MySQL とかの JOIN と変わらずに結合につかうカラムを指定して,
それをもとに DataFrame を結合するものです.
サンプルコードを更に追加して JOIN を使ってみます:
Pkmn = Tuple[int, int, str, int]
pkmns: List[Pkmn] = [
(1, 1, 'ピカチュウ', 99),
(2, 1, 'リザードン', 99),
(3, 2, 'イーブイ', 50),
(4, 3, 'トサキント', 20),
(5, 3, 'ヒトデマン', 30),
(6, 3, 'スターミー', 40),
]
pkmns_schema = StructType([
StructField('id', IntegerType(), True),
StructField('trainer_id', IntegerType(), True),
StructField('name', StringType(), True),
StructField('level', IntegerType(), True),
])
pkmns_df = spark.createDataFrame(
spark.sparkContext.parallelize(pkmns),
pkmns_schema
)
pkmns_df.createOrReplaceTempView('pkmns');
trainer_and_pkmns_df = spark.sql('''
SELECT *
FROM trainers
INNER JOIN pkmns
ON trainers.id = pkmns.trainer_id
''')
trainer_and_pkmns_df.show()
id |
name |
gender |
age |
comment |
id |
trainer_id |
name |
level |
|---|---|---|---|---|---|---|---|---|
| 1 | サトシ | male | 10 | ポケモン ゲット だぜ | 1 | 1 | ピカチュウ | 99 |
| 1 | サトシ | male | 10 | ポケモン ゲット だぜ | 2 | 1 | リザードン | 99 |
| 3 | カスミ | female | 12 | わたしの ポリシーはね… みず タ... | 4 | 3 | トサキント | 20 |
| 3 | カスミ | female | 12 | わたしの ポリシーはね… みず タ... | 5 | 3 | ヒトデマン | 30 |
| 3 | カスミ | female | 12 | わたしの ポリシーはね… みず タ... | 6 | 3 | スターミー | 40 |
| 2 | シゲル | male | 10 | このおれさまが せかいで いちばん... | 3 | 2 | イーブイ | 50 |
ちなみに INNER JOIN, OUTER JOIN の他に種類がいっぱいあります.
こちらの記事がわかりやすいので引用します:
これで集合操作ができるので便利という感じです.
各 JOIN の概念はこのページのベン図がわかりやすいので引用します:
ポイントとしてやはり JOIN はコストがかかっていて遅いです.
クラスタを組んでたとしたら,各所に分散したデータから見つけて JOIN して戻してとかそういう操作が行われているようです.
ので,後述するパフォーマンスチューニングが必要になってきます.
パフォーマンス
現実のケースとして,膨大なデータセットと格闘するのはそうとう辛いものがあります.
というのも,4時間とかかかるものだったら,最後の方で落ちたらまたやり直しかとなって,
二回ミスると一日の業務時間を捧げたことになってしまって残業が確定します.
なので,そういうパフォーマンスを改善するために,JOIN の効率を上げるようにデータを削減したり,
パーティションの区切りかたを変えたり,
パーティションをなるべくクラスタ上に小さく断片化させないような工夫が必要です.
Broadcast Join というもので,あえて全クラスタにデータセットを重複して配置することで,
JOIN 時にデータセットの検索のコストを下げるとかそういうものもあります.
重要なテクニックとして,
各チェックポイント的なところで適宜 DataFrame を .cache() しておくことで,
パフォーマンスが劇的に改善されるというものもあります.
パフォーマンスについての公式ページを見るとそういうテクニックがあって参考になります:
MySQL
さて,よくあるのが MySQL のデータベースから読み込んでうんぬんしたいというのがあります.
このケースでは MySQL を扱うために JDBC の MySQL コネクタを用意する必要がありますが,
こちらのかたのエントリと,その Docker イメージが参考になります:
- https://cloudfish.hatenablog.com/entry/2018/08/03/191424
- https://hub.docker.com/r/cloudfish/pyspark-notebook/dockerfile
しかしながら,MySQL は Spark では扱いづらいみたいなところもあります.
(いろいろハマりポイントがあります)
実際
Spark が威力を発揮するのは:
- データがとにかくでかい
- 適用したい処理が互いに依存しない
- 各操作に副作用がなくて内部の操作で完結する (外の API への操作とかがない)
というものだと思っています.
あと Spark は複数台でクラスタを作って worker に仕事をさせるのがキモなので,
現実的には AWS におまかせするということで,Amazon EMR とか AWS Glue でやるのがよさそうですね.
ローカルだとクラスタを作らずに動くので,本気の巨大データを打ち込んでもパフォーマンスは出ずに恩恵にはあずかれないからです.
メモリの限界にぶち当たったり,
節約できても処理全体にバッチ流して二週間かかりますみたいな巨大データだと,
素朴なものでも自前で分割して複数プロセスにわけて実行とかすればできるかもしれないけど,
Spark にできることなら任せるのもよさげです.