概要
Databrick REST APIによりファイル(Python、HTML)をノートブックとしてインポートする方法を共有します。取り込み対象のノートブックを事前にbase64文字列に変換する必要があります。
詳細は下記のGithub pagesのページをご確認ください。
コードを実行したい方は、下記のdbcファイルを取り込んでください。
https://github.com/manabian-/databricks_tecks_for_qiita/blob/main/tecks/import_notebook_by_rest_api/dbc/import_notebook_by_rest_api.dbc
検証環境
databricks runtime: 8.1.x-scala2.12
Python version: 3.8.8
pyspark version: 3.1.1.dev0
手順
事前準備
dbfs上に、取り込み対象のPythonファイルとHTMLファイルを配置してください。手順が不明な方は、前述のGithub Pageにて確認してください。
Pythonファイルをインポートする手順
# DatabricksのURL
browserHostName = json.loads(dbutils.notebook.entry_point
.getDbutils()
.notebook()
.getContext()
.toJson()
)['tags']['browserHostName']
db_url = f"https://{browserHostName}"
token = "dapifa2d256602b49bbef4d0ac7c093cbaa2" # トークン。本来は、dbutils.secrets.get(scope = <SOCPE_NAME>, key = <TOKEN>)
import json
# 現在のノートブックのディレクトリ(ノートブック名を含む)を設定
notebook_current_path = json.loads(dbutils.notebook.entry_point
.getDbutils()
.notebook()
.getContext()
.toJson()
)['extraContext']['notebook_path']
# ノートブック名を除外した現在のノートブックのディレクトリを設定
notebook_current_dir = notebook_current_path[:notebook_current_path.rfind('/')]
# 現在のノートブックのディレクトリの下にディレクトリを設定する場合には事前に作成する必要がある。
notebook_import_dir = f'{notebook_current_dir}'
# ソースとなるファイルのパスを指定
html_file_path = "/dbfs/FileStore/qiita/import_notebook_by_rest_api/test_html.html"
import base64
import os
# htmlファイルの名前を取得
html_file_name = os.path.splitext(os.path.basename(html_file_path))[0]
# インポート先のパスとファイル名をセット
notebook_import_path = f'{notebook_import_dir}/{html_file_name}'
# htmlファイルの内容を取得
with open(html_file_path) as f:
file_value = f.read()
# htmlファイルの内容のbase64文字列を取得
html_file_encode_base64 = base64.b64encode(file_value.encode())
# インポート先のディレクトリを作成
dbutils.fs.mkdirs(notebook_import_dir)
import requests
response = requests.post(
f'{db_url}/api/2.0/workspace/import',
headers={
"Authorization": f'Bearer {token}'},
json={
"content": python_file_encode_base64,
"path": notebook_import_path,
"language": 'PYTHON',
"overwrite": 'true',
"format": 'SOURCE',
}
)
if response.status_code == 200:
print("success")
elif response.status_code == 403:
print(response.text)
else:
print("Error geting the job: {0}: {1}".format(response.json()["error_code"],response.json()["message"]))

HTMLファイルをインポートする手順
# DatabricksのURL
browserHostName = json.loads(dbutils.notebook.entry_point
.getDbutils()
.notebook()
.getContext()
.toJson()
)['tags']['browserHostName']
db_url = f"https://{browserHostName}"
token = "dapifa2d256602b49bbef4d0ac7c093cbaa2" # トークン。本来は、dbutils.secrets.get(scope = <SOCPE_NAME>, key = <TOKEN>)
import json
# 現在のノートブックのディレクトリ(ノートブック名を含む)を設定
notebook_current_path = json.loads(dbutils.notebook.entry_point
.getDbutils()
.notebook()
.getContext()
.toJson()
)['extraContext']['notebook_path']
# ノートブック名を除外した現在のノートブックのディレクトリを設定
notebook_current_dir = notebook_current_path[:notebook_current_path.rfind('/')]
# 現在のノートブックのディレクトリの下にディレクトリを設定する場合には事前に作成する必要がある。
notebook_import_dir = f'{notebook_current_dir}'
# ソースとなるファイルのパスを指定
html_file_path = "/dbfs/FileStore/qiita/import_notebook_by_rest_api/test_html.html"
import base64
import os
# htmlファイルの名前を取得
html_file_name = os.path.splitext(os.path.basename(html_file_path))[0]
# インポート先のパスとファイル名をセット
notebook_import_path = f'{notebook_import_dir}/{html_file_name}'
# htmlファイルの内容を取得
with open(html_file_path) as f:
file_value = f.read()
# htmlファイルの内容のbase64文字列を取得
html_file_encode_base64 = base64.b64encode(file_value.encode())
import json
# 現在のノートブックのディレクトリ(ノートブック名を含む)を設定
notebook_current_path = json.loads(dbutils.notebook.entry_point
.getDbutils()
.notebook()
.getContext()
.toJson()
)['extraContext']['notebook_path']
# ノートブック名を除外した現在のノートブックのディレクトリを設定notebook_current_dir = notebook_current_path[:notebook_current_path.rfind('/')]
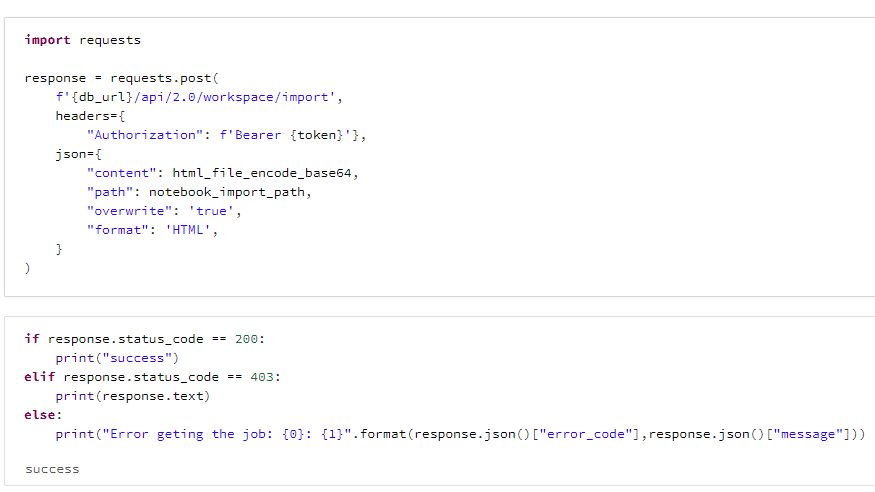
import requests
response = requests.post(
f'{db_url}/api/2.0/workspace/import',
headers={
"Authorization": f'Bearer {token}'},
json={
"content": html_file_encode_base64,
"path": notebook_import_path,
"overwrite": 'true',
"format": 'HTML',
}
)
if response.status_code == 200:
print("success")
elif response.status_code == 403:
print(response.text)
else:
print("Error geting the job: {0}: {1}".format(response.json()["error_code"],response.json()["message"]))
関連記事
ノートブックをGithub Pageにより共有する方法
Databricks(Azure Databricks)でGithub経由でノートブックを共有する方法 - Qiita