概要
Oracle Database から Databricks へ Azure Data Factory (ADF) のメタデータ駆動のコピーアクティビティによる多数のテーブルのデータ移行手順を共有します。オンプレミスにある Oracle Database からデータを移行する場合などに本手順の方法が有効です。メタデータ駆動のコピーアクティビティでは増分連携を実施できることから、データ移行だけでなく、日々のデータ連携にも利用できる便利な機能です。
メタデータ駆動のコピーアクティビティとは、Azure SQL Database のテーブルにデータ連携に必要な設定値を保持させて、自動で生成される3つのテンプレートパイプラインで実行することで、多数のテーブルを連携できる機能です。ADF のコピーアクティビティを利用するパイプラインであることから、コピーアクティビティで利用できる多くのデータストアからの連携が実施できます。
本手順ではターゲットとして、 Azure Databricks Delta Lake コネクタを利用しております。ソースが RDB であることから、ステージング設定が必要となります。
事前準備
次の事項を事前に実施する必要があります。本手順では詳細は省略します。
- リソースの作成
- Azure でのリソース作成
- Azure Data Factory の構築
- Azure SQL Database のデータベースの構築
- Databricks の構築
- Azure Storage(ステージング用)の構築
- ローカル環境でのリソース作成
- セルフホステッド統合ランタイムの構築
- Oracle Database の構築
- Azure でのリソース作成
- 認証認可関連の実行
- セルフホステッド統合ランタイムを ADF に登録
- Azure SQL Database への ADF のマネージド ID 登録
- Databricks への ADF のマネージド ID 登録
- Databricks にて Azure Storage へのアカウントキーを設定 *1
- データベース作成
- Oracle 上に HR スキーマのテーブルを作成
- Databricks 上に HR スキーマのテーブルを作成
- ADF にてリンクドサービスの作成
- Databricks のリンクドサービスを作成
- Azure SQL Database のリンクドサービスを作成
- Oracle Database のリンクドサービスを作成
*1 利用するストレージの種類によって Config のキーが異なることに注意が必要である。
Azure Blob Storage の場合には、以下を設定
fs.azure.account.key.<storage-account-name>.blob.core.windows.net
Azure Data Lake Storage Gen2 の場合には、以下を設定。
fs.azure.account.key.<storage-account>.dfs.core.windows.net
実行手順
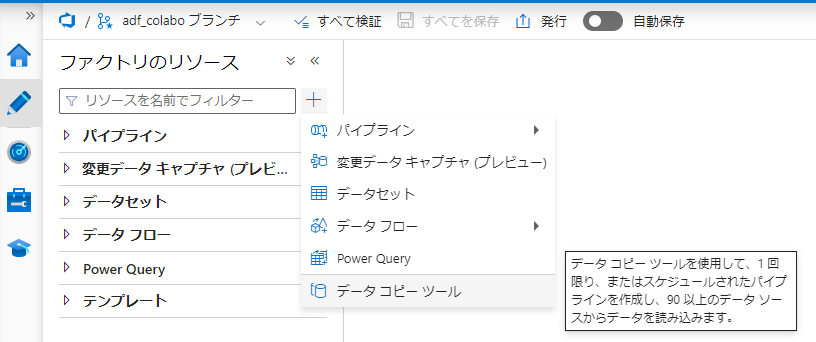
1. ADF の 作成者タブにて+ -> データコピーツールを選択
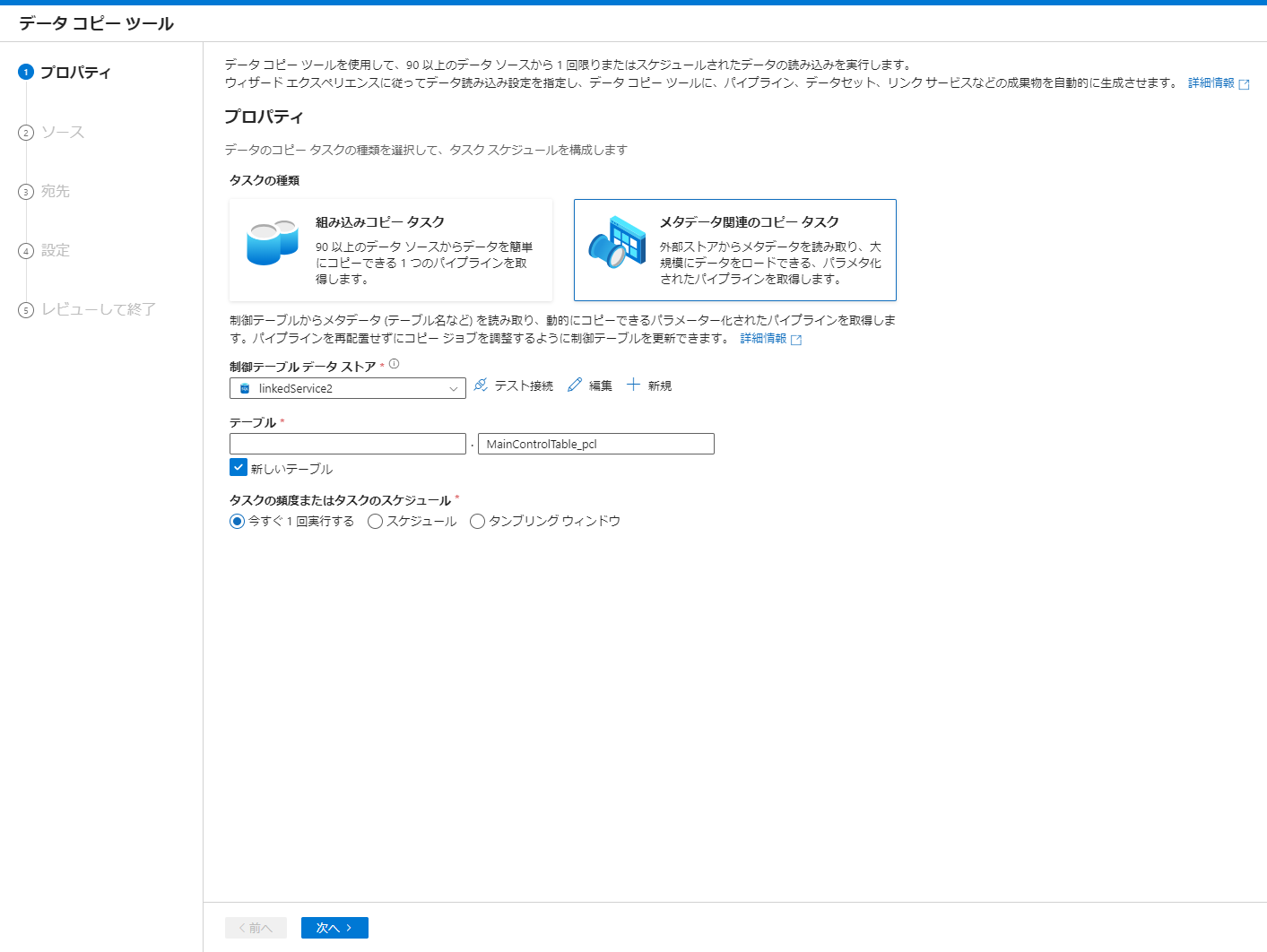
2. メタデータ関連のコピータスクを選択後、Azure SQL Database のリンクドサービスを選び次へをクリック
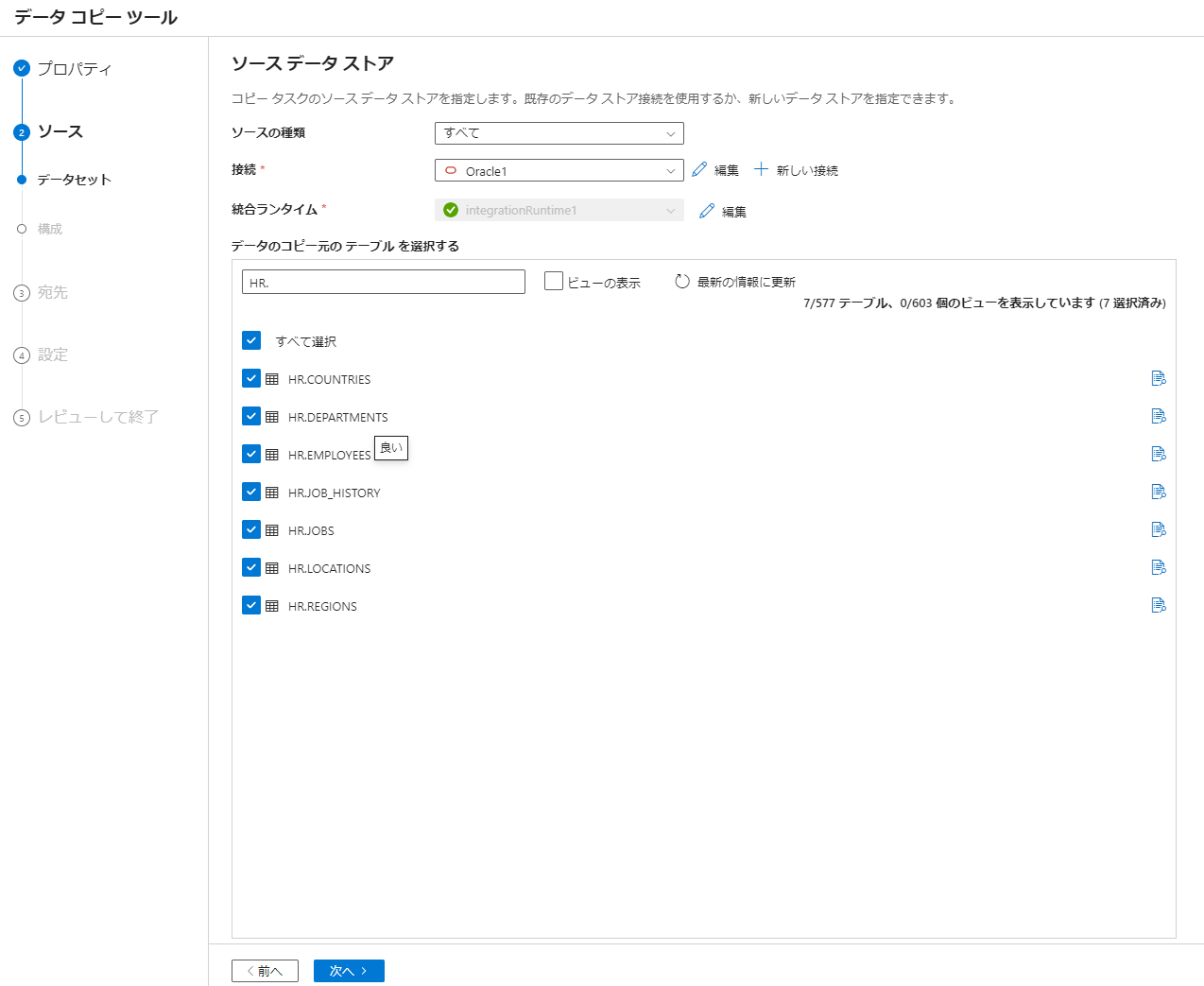
3. 接続にて Oracle Database のリンクドサービスを選択後、データを移行するテーブル(HR スキーマのテーブル)をチェックして次へを選択
特定のスキーマ(HR)のすべてのテーブルを選択する場合には、スキーマ名とトッド(HR.)により検索を行いすべて選択を選択します。
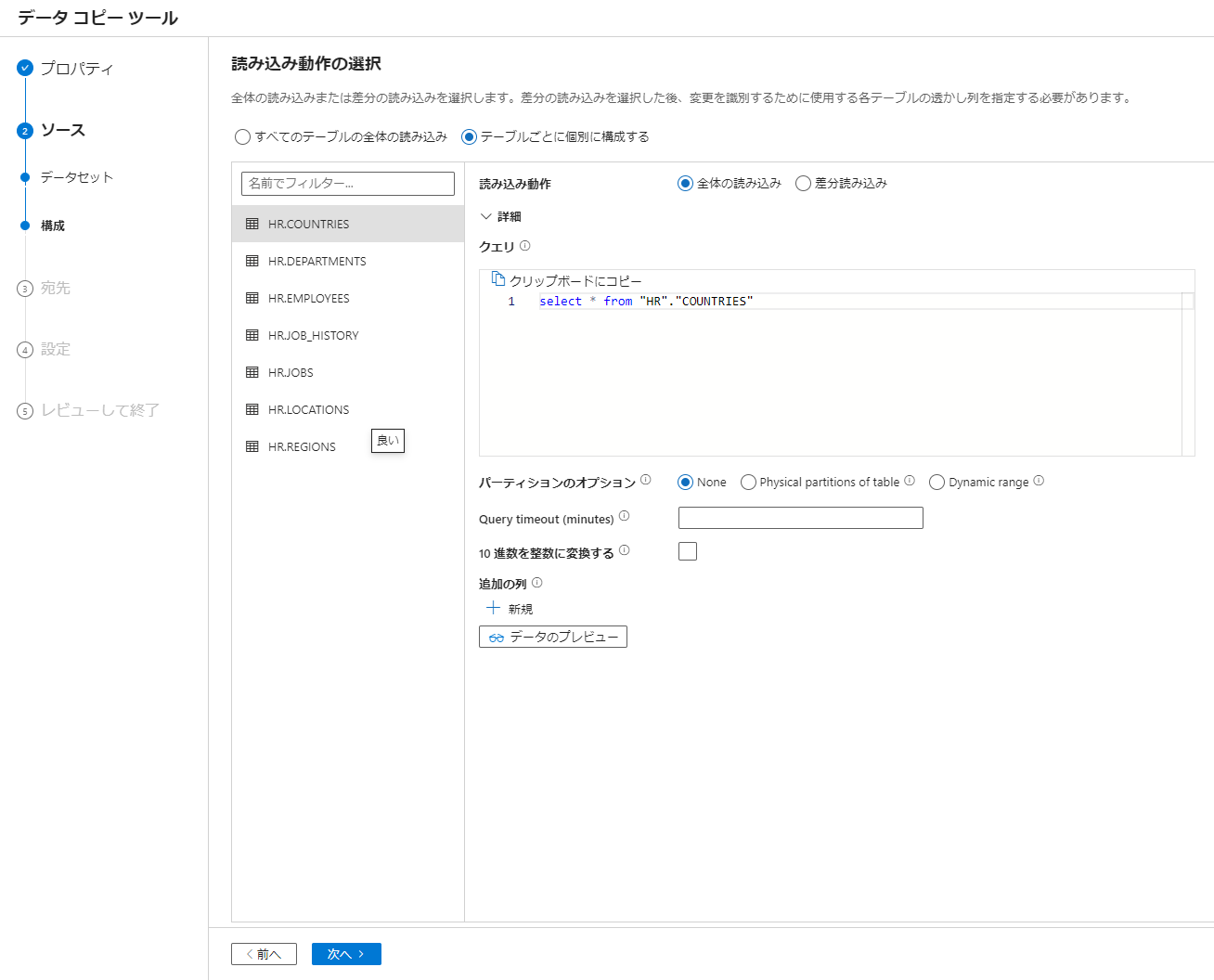
4. テーブルごとに個別に構成するをチェックして必要な設定を実施して次へを選択
本手順では設定値の変更を実施していません。
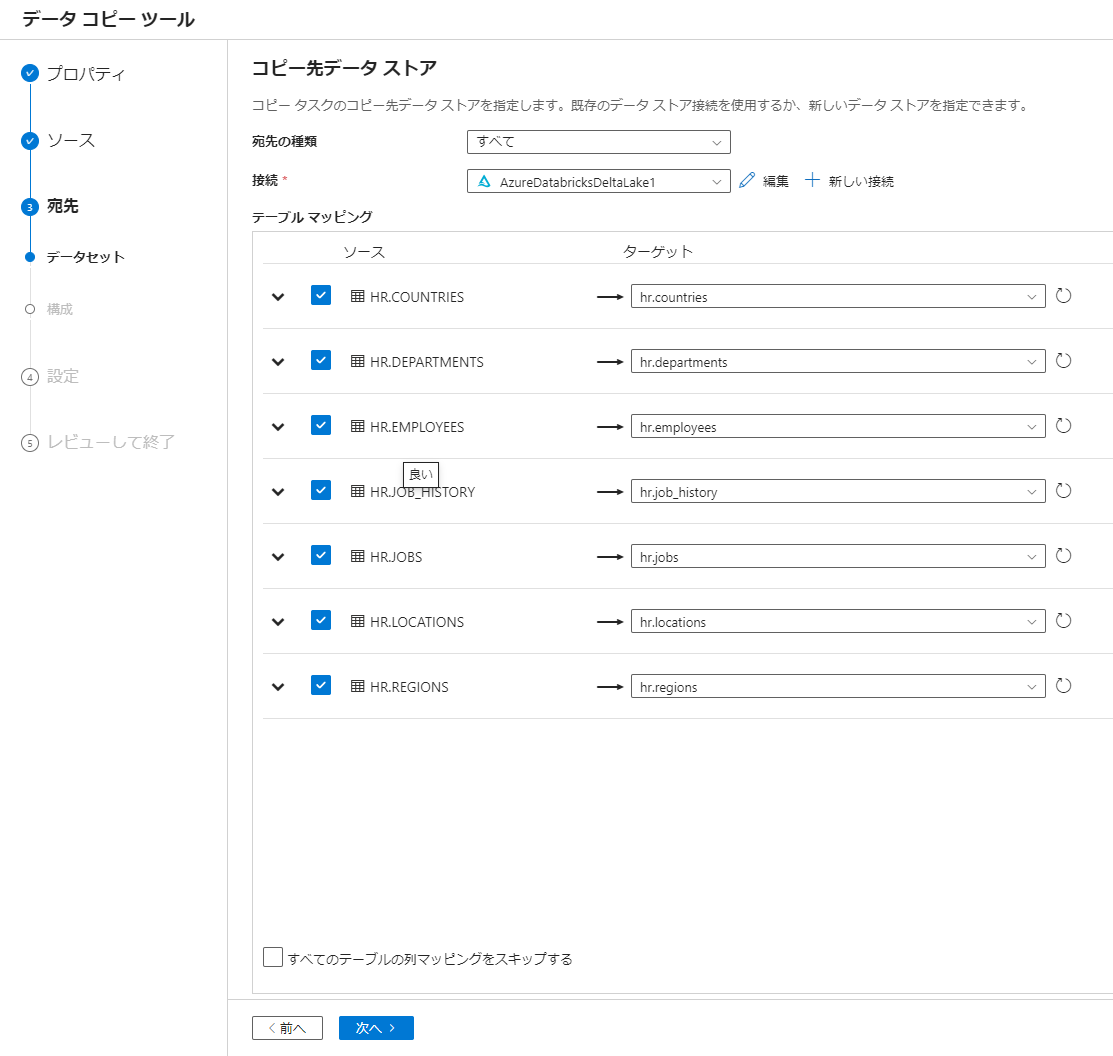
5. 接続にて Databricks Delta のリンクドサービスを選択後、テーブルのマッピングを確認して次へを選択
マッピングが同名のテーブルに対して自動で実施されるようです。
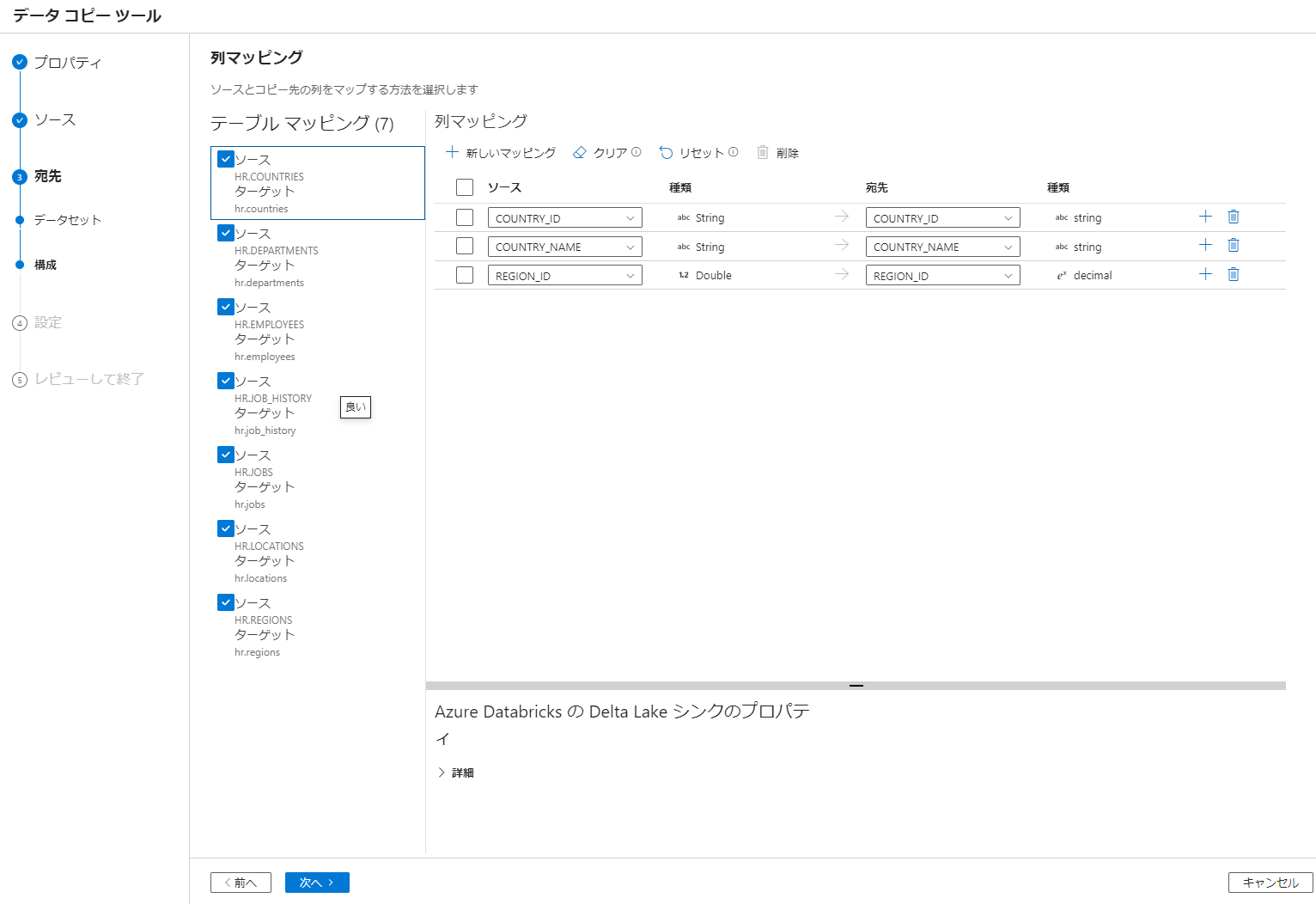
6. カラムのマッピングを確認して次へを選択
マッピングが同名のカラムに対して自動で実施されるようです。
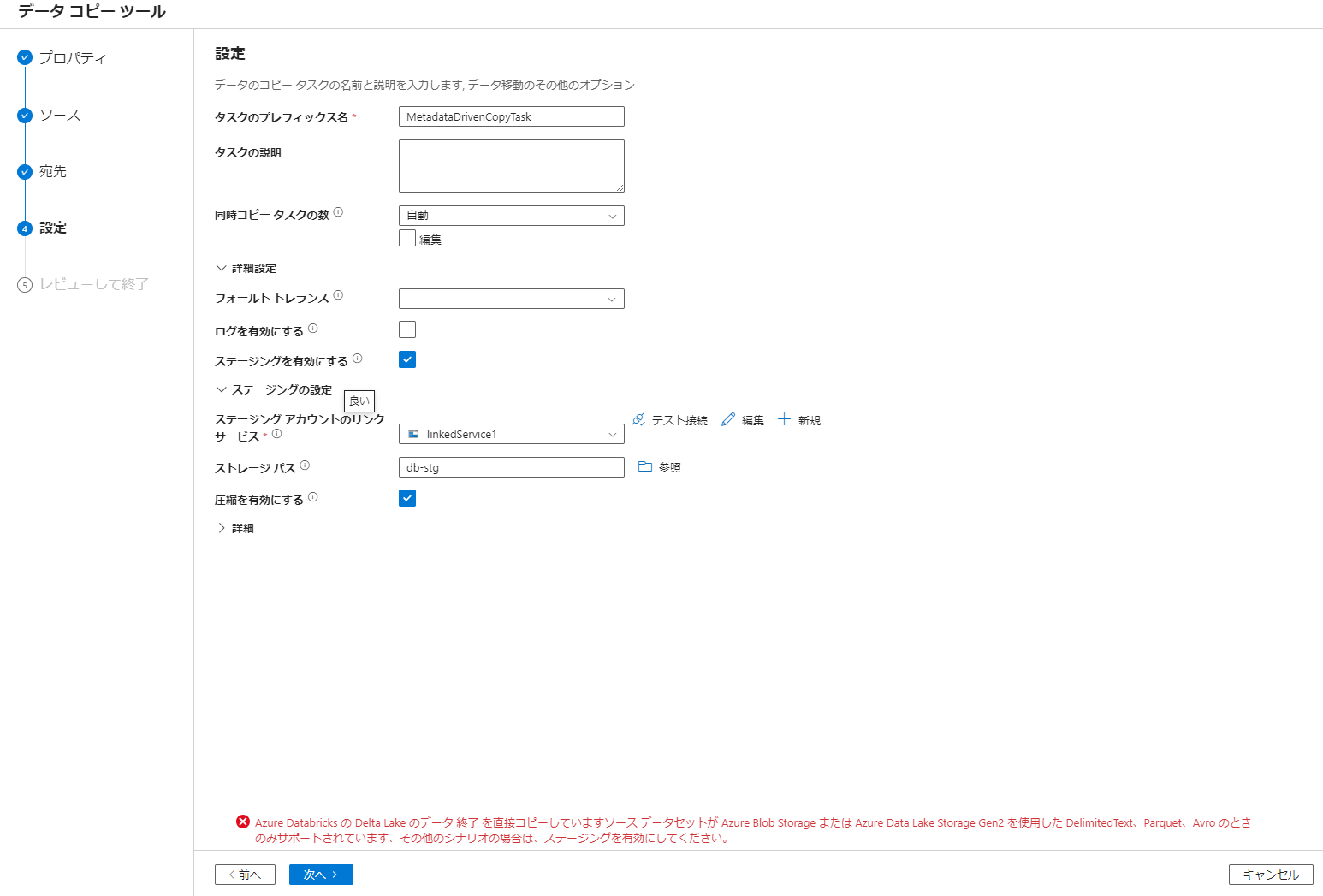
7. ステージングの設定後、次へを選択
8. 次へを選択
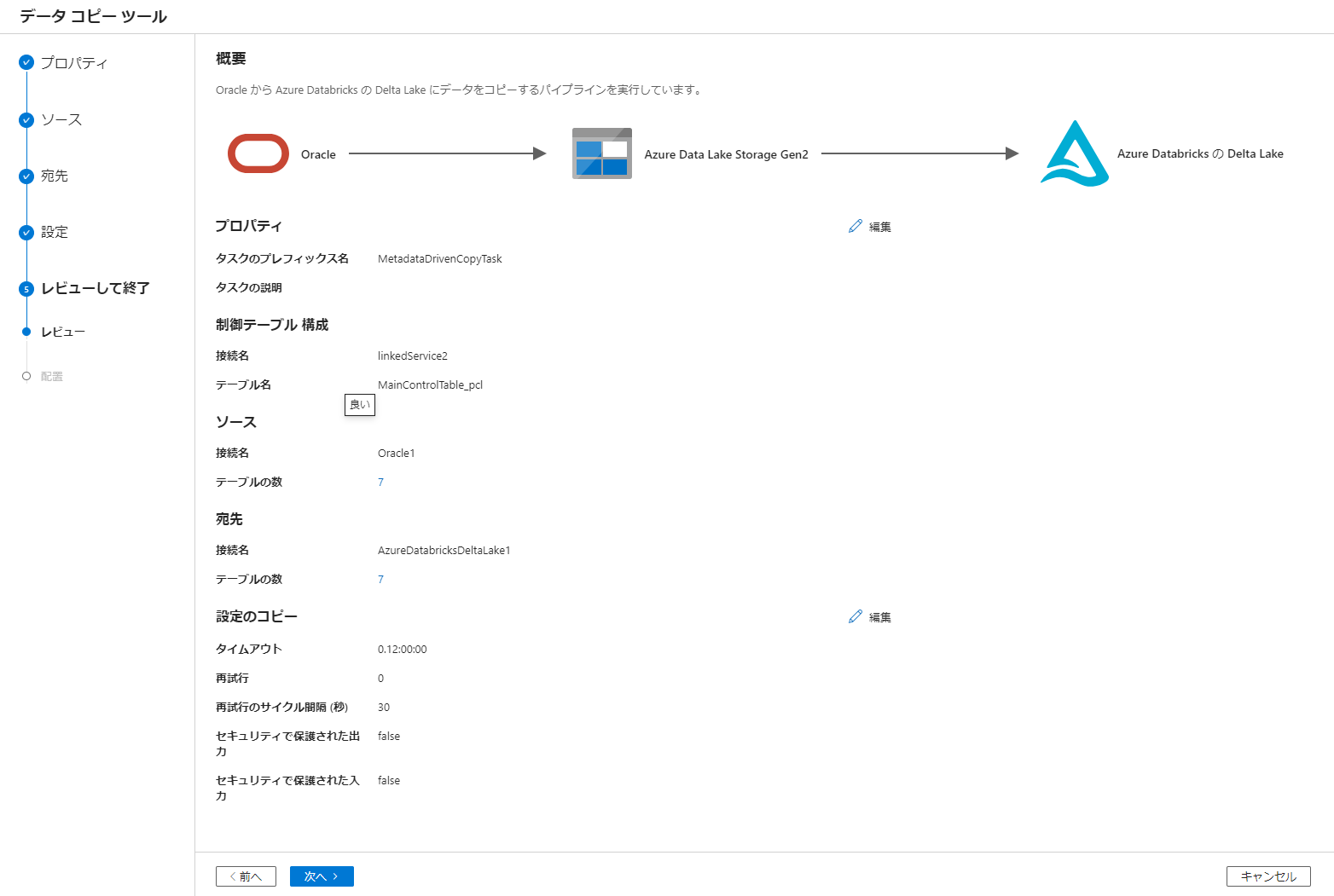
9. SQL スクリプトのダウンロードを選択して SQL ファイルをダウンロード後、パイプラインの表示とパイプライン実行のデバックをクリック
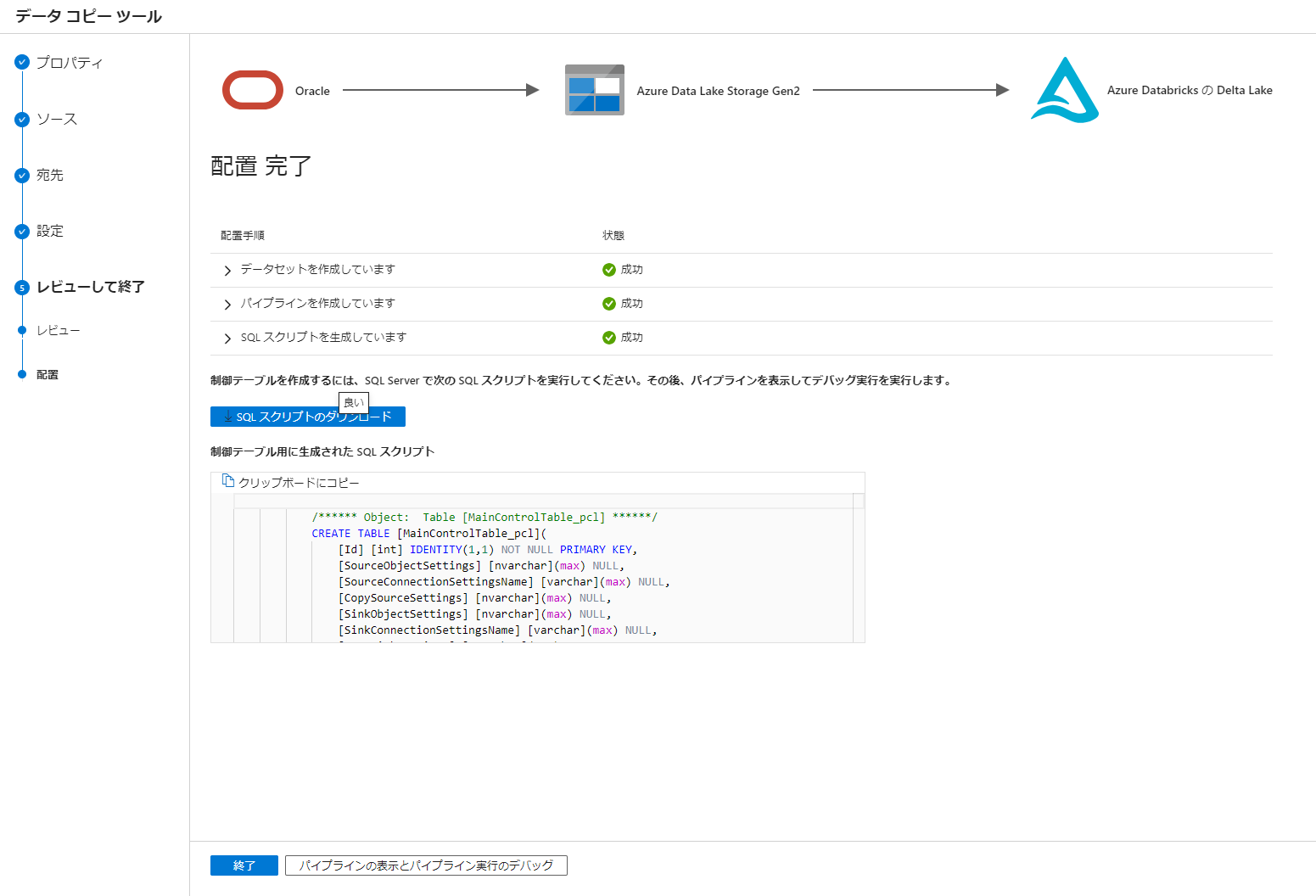
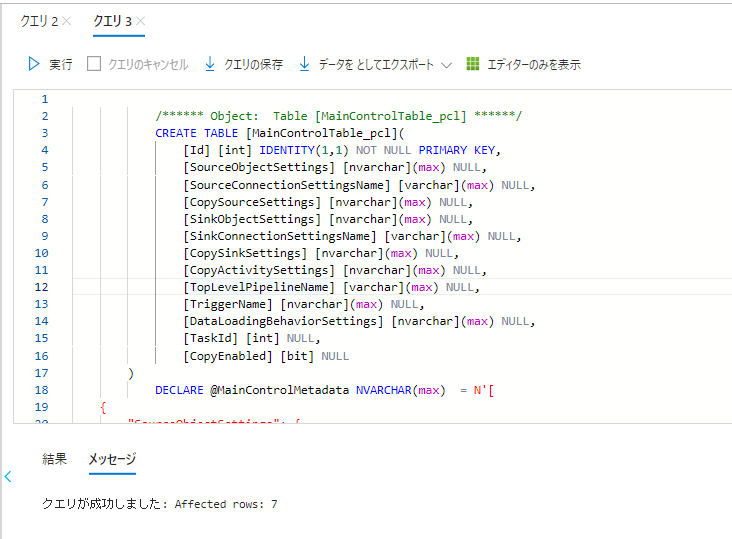
10. Azure SQL Database にてダウンロードした SQL を実行
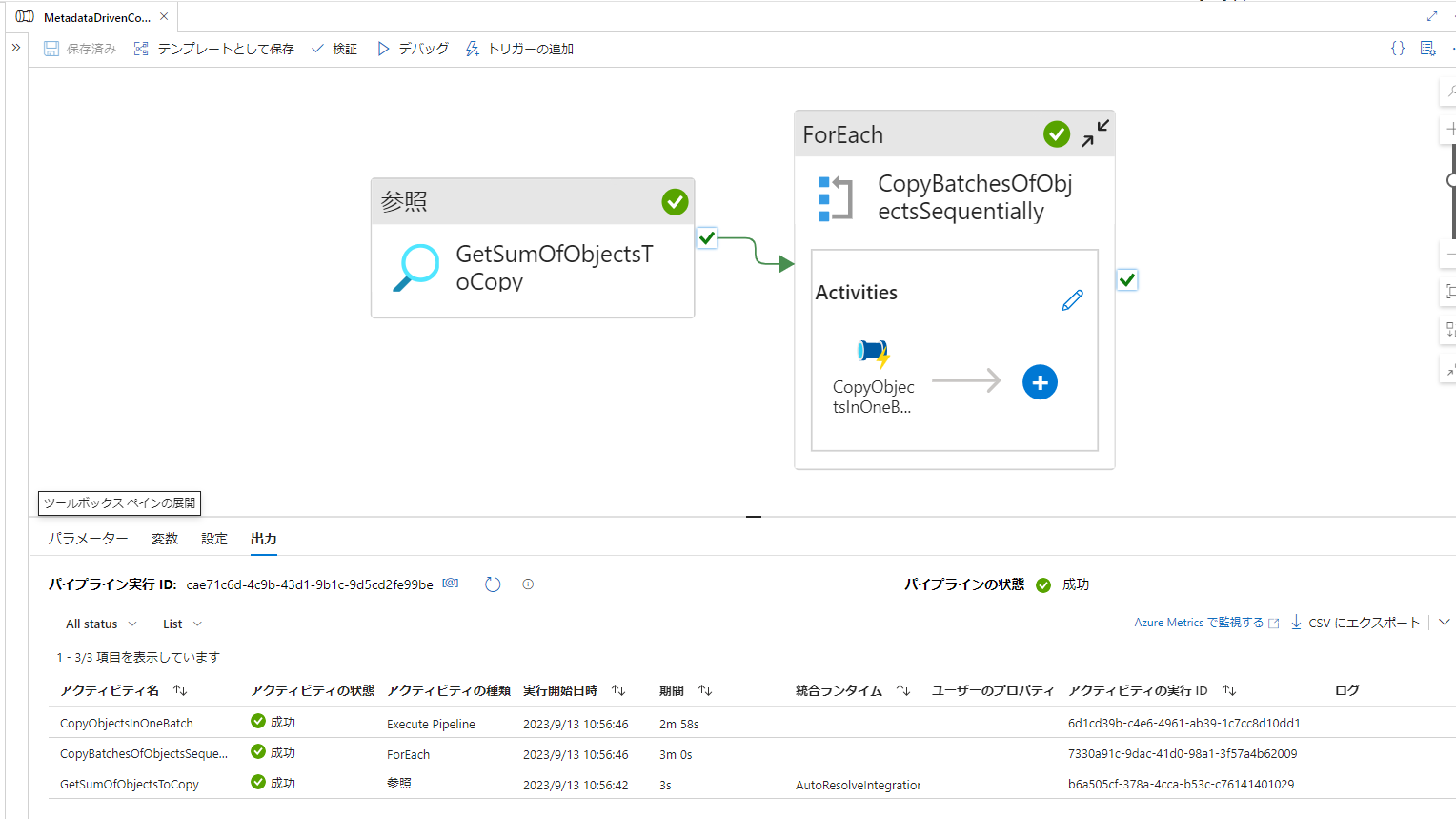
11. ADF にて生成されたパイプライン(例:MetadataDrivenCopyTask_pcl_TopLevel)をデバック実行後、正常終了することを確認
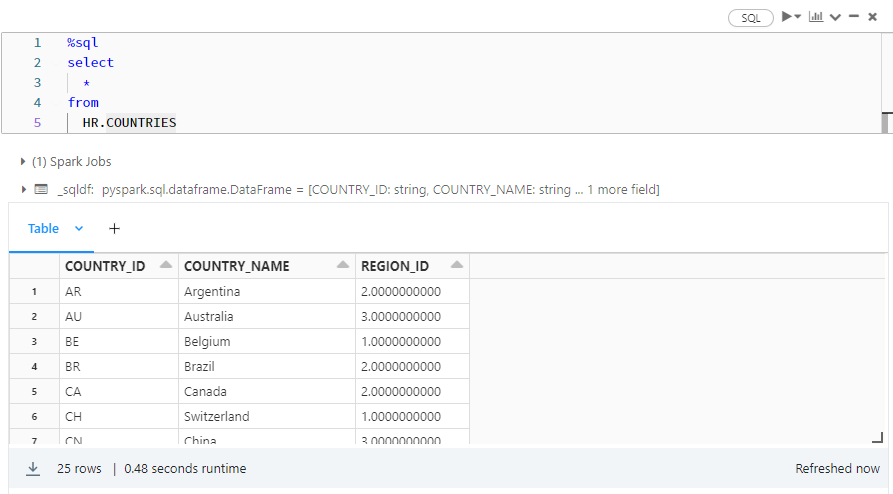
12. Databricks にてデータが連携されていることを確認
その他の検討事項
検討事項概要
-
差分読み込みに変更 - ROWID 例や監査列の付与
- パーティション分割による並列処理の実施
- カラムマッピングの省略
- テーブル読み込みの優先順位の設定
- コピーアクティビティの並列処理数の設定
- ステージング環境のライフサイクル管理の設定
1. 差分読み込みに変更
データ連携を一度で完了できない場合には、差分読み込みの利用を検討してください。本記事の手順 4 にて、差分読み込みをチェックすることで日付列などに基づき増分連携が実施できます。
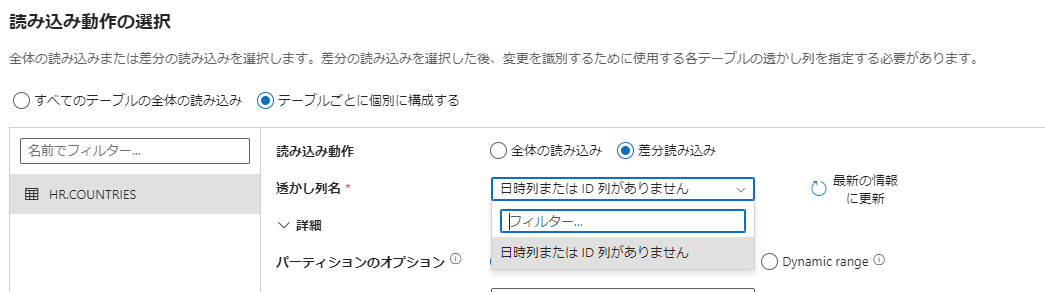
2. ROWID 例や監査列の付与
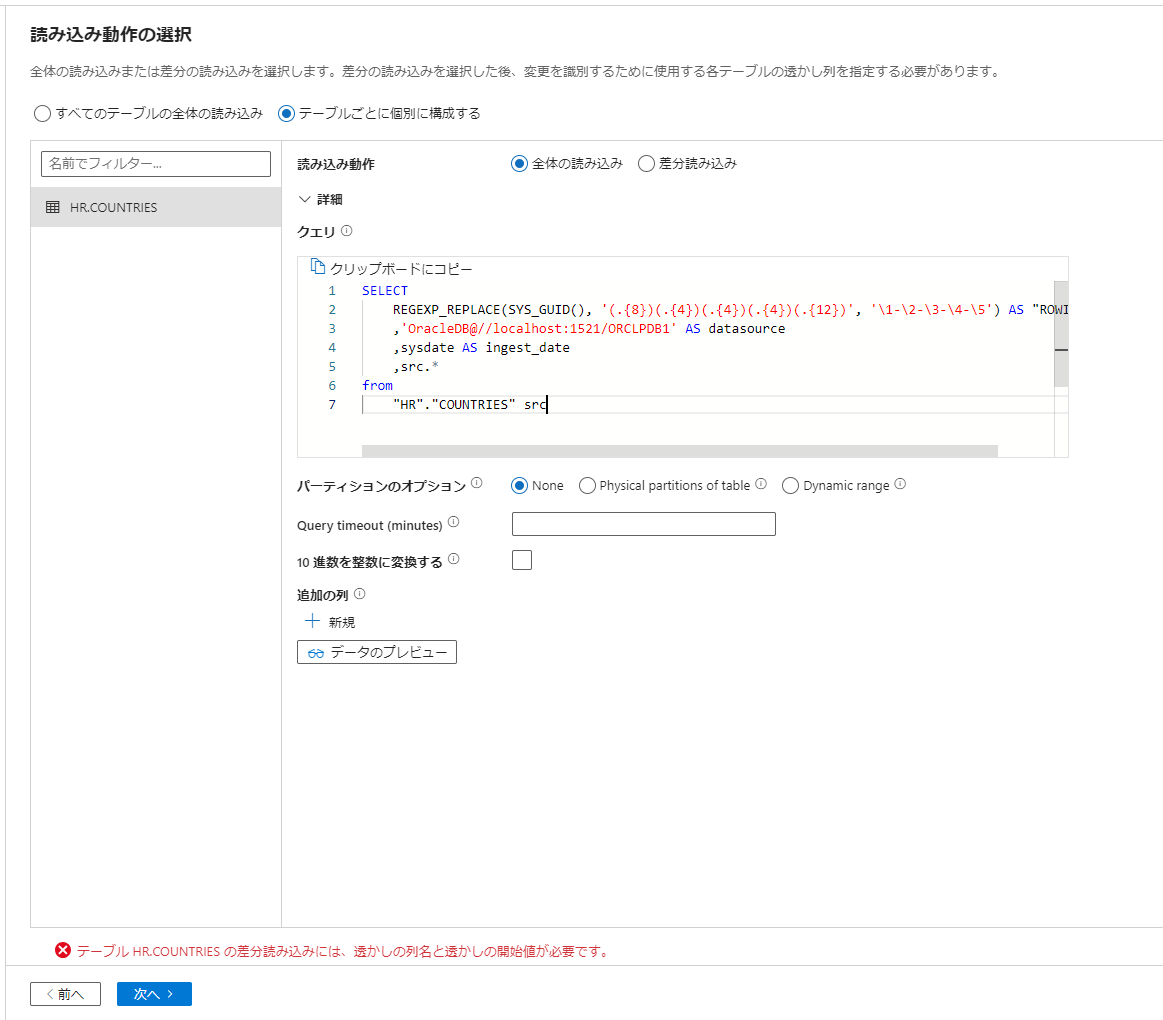
ROWID (データ移行後は ROWID の値を UUID で設定する想定)や監査列を付与する場合には本記事の手順 4 にてクエリを記述することで容易に実施できます。
SELECT
REGEXP_REPLACE(SYS_GUID(), '(.{8})(.{4})(.{4})(.{4})(.{12})', '\1-\2-\3-\4-\5') AS "ROWID"
,'OracleDB@//localhost:1521/ORCLPDB1' AS datasource
,sysdate AS ingest_date
,src.*
from
"HR"."COUNTRIES" src
3. パーティション分割による並列処理の実施
次のドキュメントを参考に並列処理の実施することを検討してください。
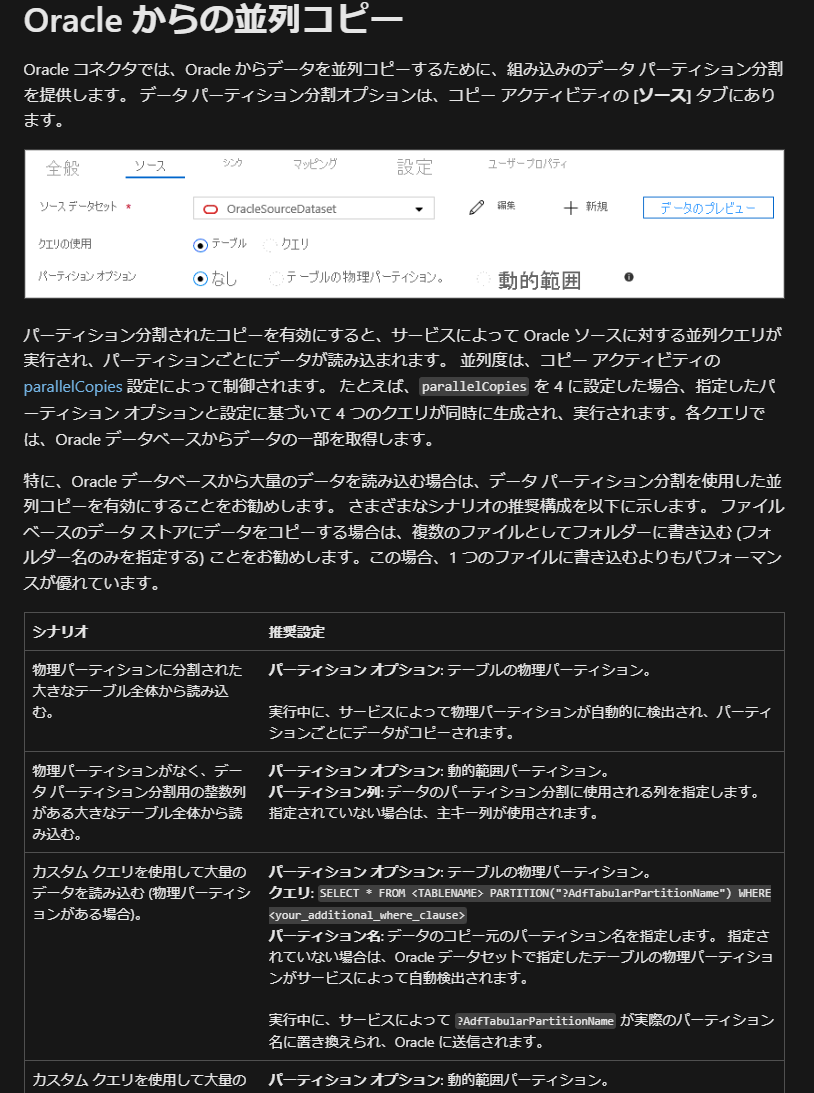
引用元:Oracle をコピー先またはコピー元としてデータをコピーする - Azure Data Factory & Azure Synapse | Microsoft Learn
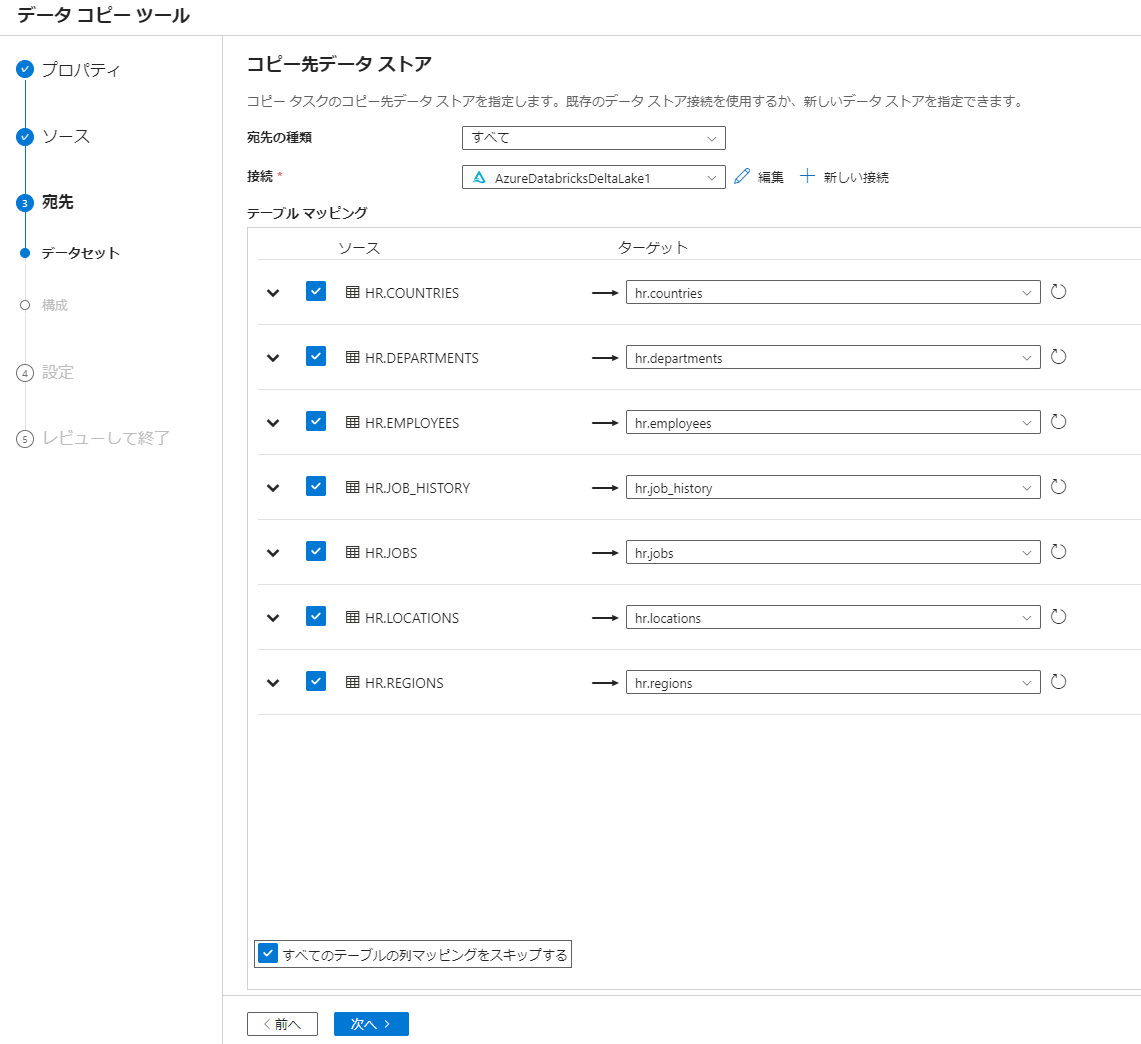
4. カラムマッピングの省略
ソースとターゲットのカラム名が同一である場合には、カラムマッピングを省略できます。省略する場合には、本記事の手順 5 にてすべてのテーブルの列マッピングをスキップするをチェックしてください。
5. テーブル読み込みの優先順位の設定
Azure SQL Database のコントロールテーブルのTaskIdにて同時実行するパイプラインを制御できるため、大規模なテーブルから連携する場合には優先順位を設定することを検討してください。
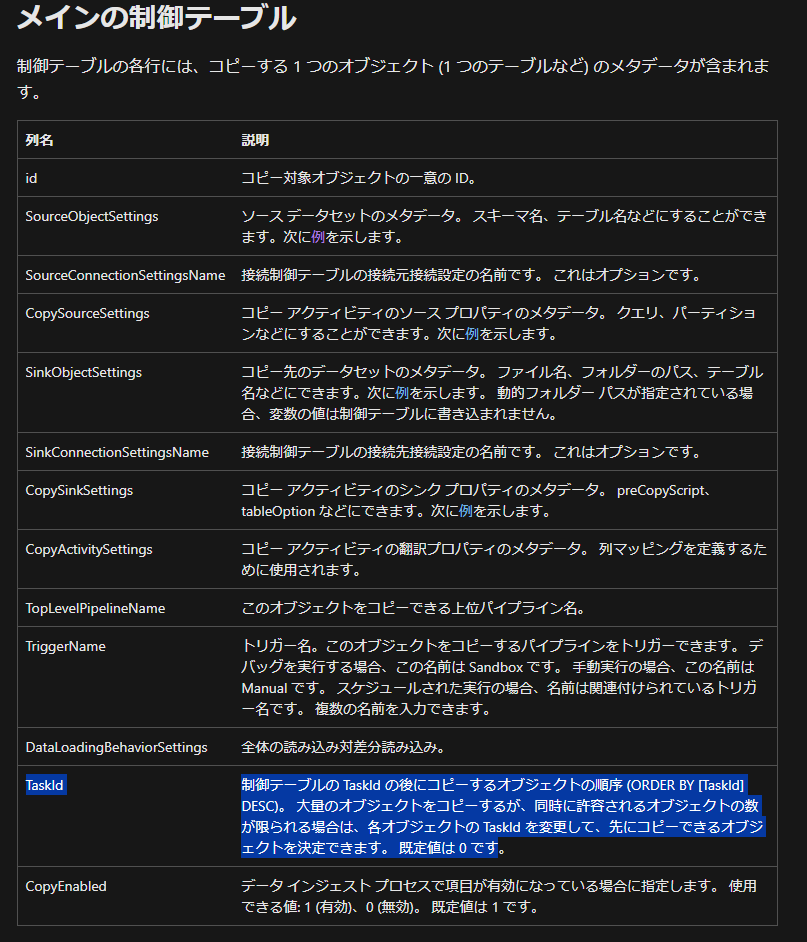
引用元:データのコピー ツールでメタデータ駆動型の方法を使用して大規模なデータ コピー パイプラインを作成する - Azure Data Factory | Microsoft Learn
6. コピーアクティビティの並列処理数の設定
MaxNumberOfConcurrentTasksパラメータにて同時に実行するパイプラインの個数を最適な処理時間となるように検討してください。
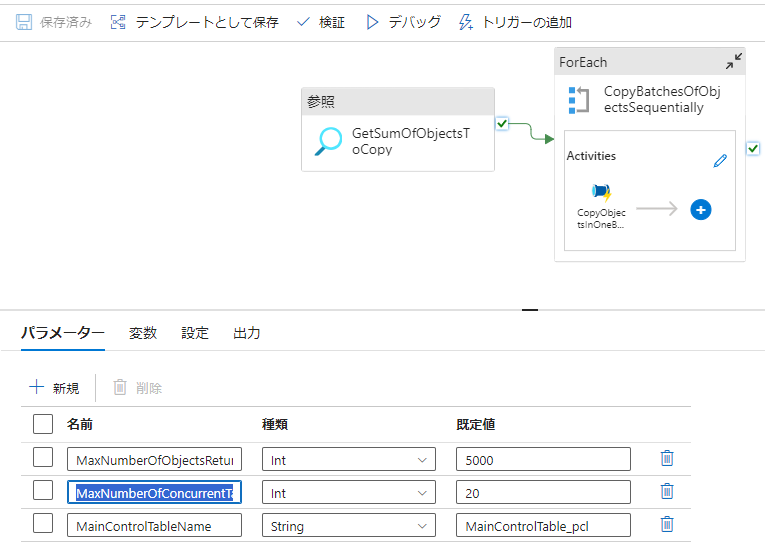
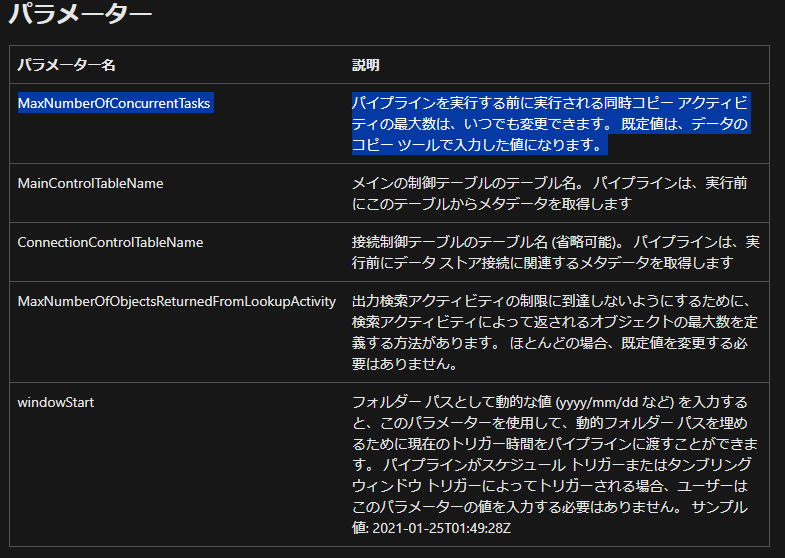
引用元:https://learn.microsoft.com/ja-jp/azure/data-factory/copy-data-tool-metadata-driven#parameters
7. ステージング環境のライフサイクル管理の設定
ステージングのストレージにてデータが削除されない事象を確認したたため、Azure Storage のデータライフサイクルの設定を検討してください。
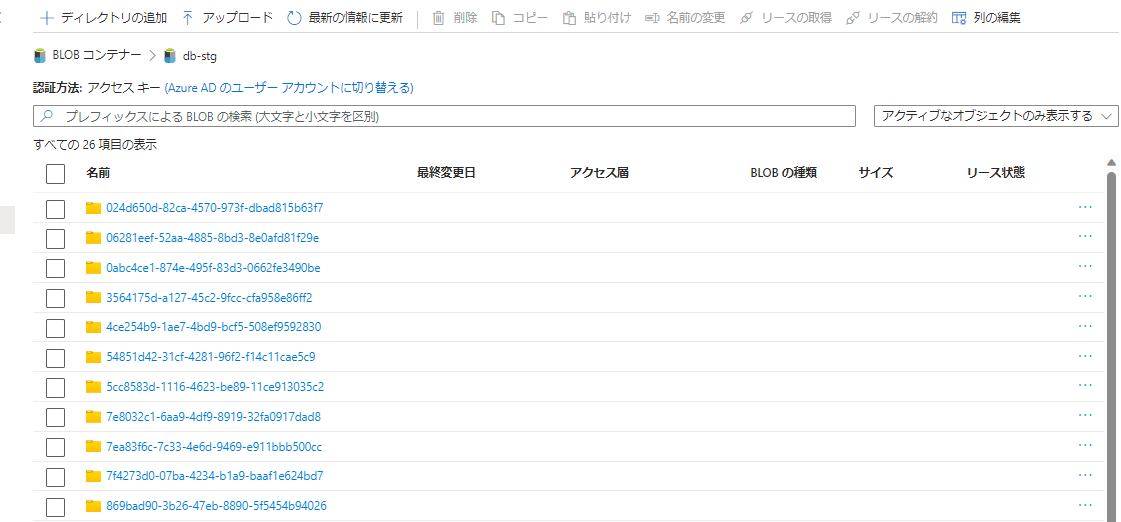
補足
Azure SQL Database のコントロールテーブルの json のサンプル値
{
"SourceObjectSettings": {
"schema": "HR",
"table": "COUNTRIES"
},
"SinkObjectSettings": {
"database": "hr",
"table": "countries"
},
"CopySourceSettings": {
"partitionLowerBound": null,
"partitionUpperBound": null,
"partitionColumnName": null,
"partitionNames": null
},
"CopySinkSettings": {
"importSettings": {
"type": "AzureDatabricksDeltaLakeImportCommand"
}
},
"CopyActivitySettings": {
"translator": null
},
"TopLevelPipelineName": "MetadataDrivenCopyTask_v50_TopLevel",
"TriggerName": [
"Sandbox",
"Manual"
],
"DataLoadingBehaviorSettings": {
"dataLoadingBehavior": "FullLoad"
},
"TaskId": 0,
"CopyEnabled": 1
}
Databricks での HR スキーマのテーブル定義
%sql
-- DROP SCHEMA HR CASCADE;
create schema HR
CREATE OR REPLACE TABLE HR.COUNTRIES (
COUNTRY_ID STRING,
COUNTRY_NAME STRING,
REGION_ID DECIMAL(28, 10)
)
USING DELTA;
CREATE TABLE HR.DEPARTMENTS (
DEPARTMENT_ID DECIMAL(4, 0),
DEPARTMENT_NAME STRING,
MANAGER_ID DECIMAL(6, 0),
LOCATION_ID DECIMAL(4, 0)
)
USING DELTA;
CREATE OR REPLACE TABLE HR.EMPLOYEES (
EMPLOYEE_ID DECIMAL(6, 0),
FIRST_NAME STRING,
LAST_NAME STRING,
EMAIL STRING,
PHONE_NUMBER STRING,
HIRE_DATE TIMESTAMP,
JOB_ID STRING,
SALARY DECIMAL(8, 2),
COMMISSION_PCT DECIMAL(2, 2),
MANAGER_ID DECIMAL(6, 0),
DEPARTMENT_ID DECIMAL(4, 0)
)
USING DELTA;
CREATE TABLE HR.JOB_HISTORY (
EMPLOYEE_ID DECIMAL(6, 0),
START_DATE TIMESTAMP,
END_DATE TIMESTAMP,
JOB_ID STRING,
DEPARTMENT_ID DECIMAL(4, 0)
)
USING DELTA;
CREATE TABLE HR.JOBS (
JOB_ID STRING,
JOB_TITLE STRING,
MIN_SALARY DECIMAL(6, 0),
MAX_SALARY DECIMAL(6, 0)
)
USING DELTA;
CREATE TABLE HR.LOCATIONS (
LOCATION_ID DECIMAL(4, 0),
STREET_ADDRESS STRING,
POSTAL_CODE STRING,
CITY STRING,
STATE_PROVINCE STRING,
COUNTRY_ID STRING
)
USING DELTA;
CREATE TABLE HR.REGIONS (
REGION_ID DECIMAL(28, 10),
REGION_NAME STRING
)
USING DELTA;