概要
この記事は、Databricksを使用してExcel形式の設計書からプログラムの変数を生成する方法についての検証結果を共有します。Excelの設計書が表形式で記述されていることを前提に、3つの異なる類型からデータを取得する方法を検証しています。これらの類型は、行方向に情報を保持する表、列方向に多数のプログラム情報を保持する表、および列方向に単一のプログラム情報を保持する表です。
また、プログラムのセクションでは、Excelファイルの配置、ライブラリのインストール、openpyxlの動作確認、クラスの定義、Excelの表から情報の取得、辞書型変数とリスト型変数を文字型に変換する方法について説明しています。これらの手順は、Excelの設計書からプログラムの変数を効率的に生成するための基本的なフレームワークを提供します。``
Excel の類型と情報の取得方針
類型について
Excel の設計書が表で記述されていることを前提として、次の類型からデータを取得する方法を検証しました。
| # | 類型 | 実装方針 |
|---|---|---|
| 1 | 行方向に情報を保持する表 | 項目とその値が行方向に記述されるため、セル位置を指定して値を取得する。 |
| 2 | 列方向に多数のプログラム情報を保持する表 | 多数のプログラムに関する情報が行方向に記述されるため、表から取得するレコードを特定して指定したプログラムの値を取得する。 |
| 3 | 列方向に単一のプログラム情報を保持する表 | 単一のプログラムに関する情報が行方向に記述されるため、表から必要に応じてフィルタリングして列の値を取得する。 |
1. 行に情報を保持する表の例

2. 列方向に多数のプログラム情報を保持する表の例

3. 列方向に単一のプログラム情報を保持する表の例
プログラム
事前準備
excelというフォルダを作成して Excel ファイルを配置

ライブラリのインストール
ライブラリのノートブックスコープでインストールします。
%pip install openpyxl -q
dbutils.library.restartPython()

openpyxl の動作確認
配置した Excel ファイルを参照できることを確認します。シートの一覧とpattern1シートの A1 セルの値を表示します。
import os
current_directory = os.getcwd()
file_dir = current_directory
file_dir += "/excel"
file_name = "ソースの情報.xlsx"
file_path = f"{file_dir}/{file_name}"
sheet_name = "pattern1"
from openpyxl import load_workbook
wb = load_workbook(filename=file_path)
sheet_names = wb.sheetnames
print(sheet_names)
ws = wb[sheet_name]
cell_value = ws['A1'].valu
print(cell_value)

クラスの定義
クラス定義はこちら
import pandas as pd
class excel_operations:
"""
A class that provides various operations for working with Excel files.
Attributes:
pdf (DataFrame): A pandas DataFrame to store the data from the Excel file.
"""
def __init__(self):
self.pdf = pd.DataFrame()
def get_worksheet_instance(
self,
file_dir,
file_name,
sheet_name,
):
"""
Returns the worksheet instance from the specified Excel file.
Args:
file_dir (str): The directory where the Excel file is located.
file_name (str): The name of the Excel file.
sheet_name (str): The name of the worksheet.
Returns:
Worksheet: The worksheet instance.
"""
from openpyxl import load_workbook
file_path = f"{file_dir}/{file_name}"
wb = load_workbook(filename=file_path)
return wb[sheet_name]
def create_pdf_from_excel(
self,
file_dir,
file_name,
sheet_name,
dtype=str,
tbl_start_cel="",
):
"""
Creates a pandas DataFrame from the specified Excel file.
Args:
file_dir (str): The directory where the Excel file is located.
file_name (str): The name of the Excel file.
sheet_name (str): The name of the worksheet.
dtype (type, optional): The data type to be used for the columns. Defaults to str.
tbl_start_cel (str, optional): The location of the table start cell. Defaults to "".
"""
from openpyxl.utils.cell import coordinate_from_string
skiprows = 0
if tbl_start_cel:
_, row_num = coordinate_from_string(tbl_start_cel)
skiprows = row_num - 1
self.pdf = pd.read_excel(
f"{file_dir}/{file_name}",
dtype=dtype,
sheet_name=sheet_name,
skiprows=skiprows,
)
def get_cell_value(
self,
worksheet_instance,
cell_location,
):
"""
Returns the value of the specified cell in the worksheet.
Args:
worksheet_instance (Worksheet): The worksheet instance.
cell_location (str): The location of the cell (e.g., "A1").
Returns:
Any: The value of the cell.
"""
return worksheet_instance[cell_location].value
def get_cell_values(
self,
worksheet_instance,
cell_info,
):
"""
Sets instance variables with values from multiple cells in the worksheet.
Args:
worksheet_instance (Worksheet): The worksheet instance.
cell_info (dict): A dictionary mapping variable names to cell locations.
"""
# for cel_k, cell_loc in cell_info.items():
# exec(f"self.{cel_k} = self.get_cell_value(worksheet_instance,cell_loc)")
for cel_k, cell_loc in cell_info.items():
setattr(self, cel_k, self.get_cell_value(worksheet_instance, cell_loc))
def set_val_from_pandas_df(
self,
var_names_and_tgt_col_names,
):
"""
Sets instance variables with values from the specified columns in the pandas DataFrame.
Args:
var_names_and_tgt_col_names (dict): A dictionary mapping variable names to target column names.
"""
for val_n, col_n in var_names_and_tgt_col_names.items():
setattr(self, val_n, self.pdf[col_n][0])
def list_var_to_str(
self,
list_val,
additional_space_num=0,
unquoted_values=[],
):
"""
Converts a list variable to a string representation.
Args:
list_val (list): The list variable.
additional_space_num (int, optional): The number of additional spaces to add. Defaults to 0.
unquoted_values (list, optional): The list of values that should not be quoted. Defaults to [].
Returns:
str: The string representation of the list variable.
"""
add_space = " " * additional_space_num
list_val = [str(list_s) if list_s in unquoted_values else f'"{str(list_s)}"' for list_s in list_val]
str_var = (
"[\n"
+ f"{add_space}" + "\n".join([f'{add_space} {list_s.rstrip(",")},' for list_s in list_val])
+ f"\n{add_space}]"
)
return str_var
def dict_var_to_str(
self,
dict_val,
additional_space_num=0,
unquoted_keys=[],
):
"""
Converts a dictionary variable to a string representation.
Args:
dict_val (dict): The dictionary variable.
additional_space_num (int, optional): The number of additional spaces to add. Defaults to 0.
unquoted_keys (list, optional): The list of keys that should not be quoted. Defaults to [].
Returns:
str: The string representation of the dictionary variable.
"""
add_space = " " * additional_space_num
modifed_dict_val = {}
for dict_k, dict_v in dict_val.items():
if dict_k in unquoted_keys:
modifed_dict_val[f'"{dict_k}"'] = dict_v
else:
modifed_dict_val[f'"{dict_k}"'] = f'"{dict_v}"'
str_var = (
"[\n"
+ f"{add_space}\n".join(
[f"{add_space} {dict_k}: {dict_v}," for dict_k, dict_v in modifed_dict_val.items()]
)
+ f"\n{add_space}]"
)
return str_var
def get_col_values_from_pandas_df(
self,
tgt_col,
dropna_cols=[],
):
"""
Returns the values of the specified column in the pandas DataFrame.
Args:
tgt_col (str): The target column.
dropna_cols (list, optional): The list of columns to drop if they contain NaN values. Defaults to [].
Returns:
list: The values of the target column.
"""
pandas_dataframe = self.pdf
tmp_pdf = pandas_dataframe.copy()
if dropna_cols:
tmp_pdf = tmp_pdf.dropna(subset=dropna_cols)
return tmp_pdf[tgt_col].tolist()
def set_vals(
self,
tgt_col_cond,
):
"""
Sets instance variables based on conditions specified for target columns.
Args:
tgt_col_cond (dict): A dictionary mapping variable names to a list of conditions.
"""
for val_n, val_conds in tgt_col_cond.items():
for val_c in val_conds:
method = val_c["method"]
parameters = val_c["parameters"]
for para_k, para_n in parameters.items():
if isinstance(para_n, str) and para_n.startswith("self."):
parameters[para_k] = eval(para_n)
method_to_call = getattr(self, method)
setattr(self, val_n, method_to_call(**parameters))
def get_renamed_cols(
self,
tgt_cols,
start_num=1,
col_name_suffix="col_",
):
"""
Returns a dictionary mapping original column names to renamed column names.
Args:
tgt_cols (list): The list of target column names.
start_num (int, optional): The starting number for renaming columns. Defaults to 1.
col_name_suffix (str, optional): The suffix to be added to the renamed column names. Defaults to "col_".
Returns:
dict: A dictionary mapping original column names to renamed column names.
"""
renamed_cols = {}
for num, col_n_aft in enumerate(tgt_cols):
col_num = start_num + num
col_name_bef = f"{col_name_suffix}{str(col_num)}"
renamed_cols[col_name_bef] = col_n_aft
return renamed_cols
Excel の表から情報の取得
1. 行に情報を保持する表
処理に利用する変数を定義します。
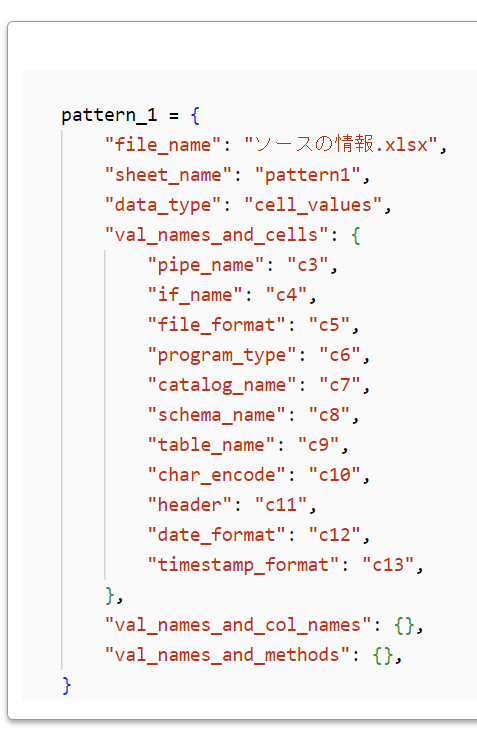
pattern_1 = {
"file_name": "ソースの情報.xlsx",
"sheet_name": "pattern1",
"data_type": "cell_values",
"val_names_and_cells": {
"pipe_name": "c3",
"if_name": "c4",
"file_format": "c5",
"program_type": "c6",
"catalog_name": "c7",
"schema_name": "c8",
"table_name": "c9",
"char_encode": "c10",
"header": "c11",
"date_format": "c12",
"timestamp_format": "c13",
},
"val_names_and_col_names": {},
"val_names_and_methods": {},
}
クラスをインスタンス化します。
excel_opr = excel_operations()

openpyxl にて Excel のシートから指定したセル位置の値を変数にセットします。最後にセットした変数の値を表示します。
excel_sheet = excel_opr.get_worksheet_instance(
file_dir,
pattern_1["file_name"],
pattern_1["sheet_name"],
)
excel_opr.get_cell_values(
excel_sheet,
pattern_1["val_names_and_cells"],
)
for key in pattern_1["val_names_and_cells"].keys():
print(key + ": " + str(eval(f"excel_opr.{key}")))

2. 列方向に多数のプログラム情報を保持する表
pattern_2 = {
"file_name": "ソースの情報.xlsx",
"sheet_name": "pattern2",
"data_type": "table",
"tbl_start_cel": "A2",
"val_names_and_cells": {},
"val_names_and_col_names": {
"pipe_name": "パイプライン名",
"if_name": "IF名",
"file_format": "ファイル形式",
"program_type": "プログラム種類",
"catalog_name": "カタログ名",
"schema_name": "スキーマ名",
"table_name": "テーブル名",
"char_encode": "文字コード",
"header": "ヘッダー有無",
"date_format": "日付の形式",
"timestamp_format": "タイムスタンプの形式",
},
"val_names_and_methods": {},
}

クラスをインスタンス化します。
excel_opr = excel_operations()

Pandas にて Excel のシートからデータフレームを作成して、データフレームの値を変数にセットします。最後にセットした変数の値を表示します。
excel_opr.create_pdf_from_excel(
file_dir=file_dir,
file_name=pattern_2["file_name"],
sheet_name=pattern_2["sheet_name"],
dtype=str,
tbl_start_cel=pattern_2["tbl_start_cel"],
)
excel_opr.set_val_from_pandas_df(
pattern_2["val_names_and_col_names"],
)
for key in pattern_2["val_names_and_col_names"].keys():
print(key + ": " + eval(f"excel_opr.{key}"))

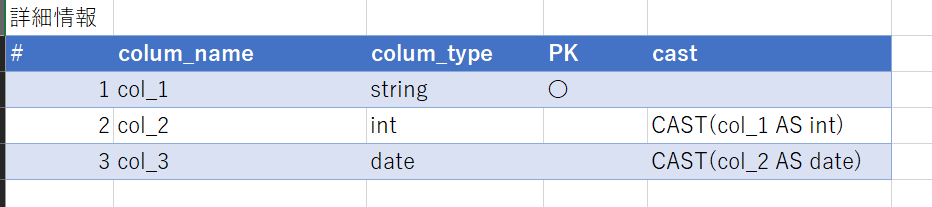
3. 列方向に単一のプログラム情報を保持する表
処理に利用する変数を定義します。
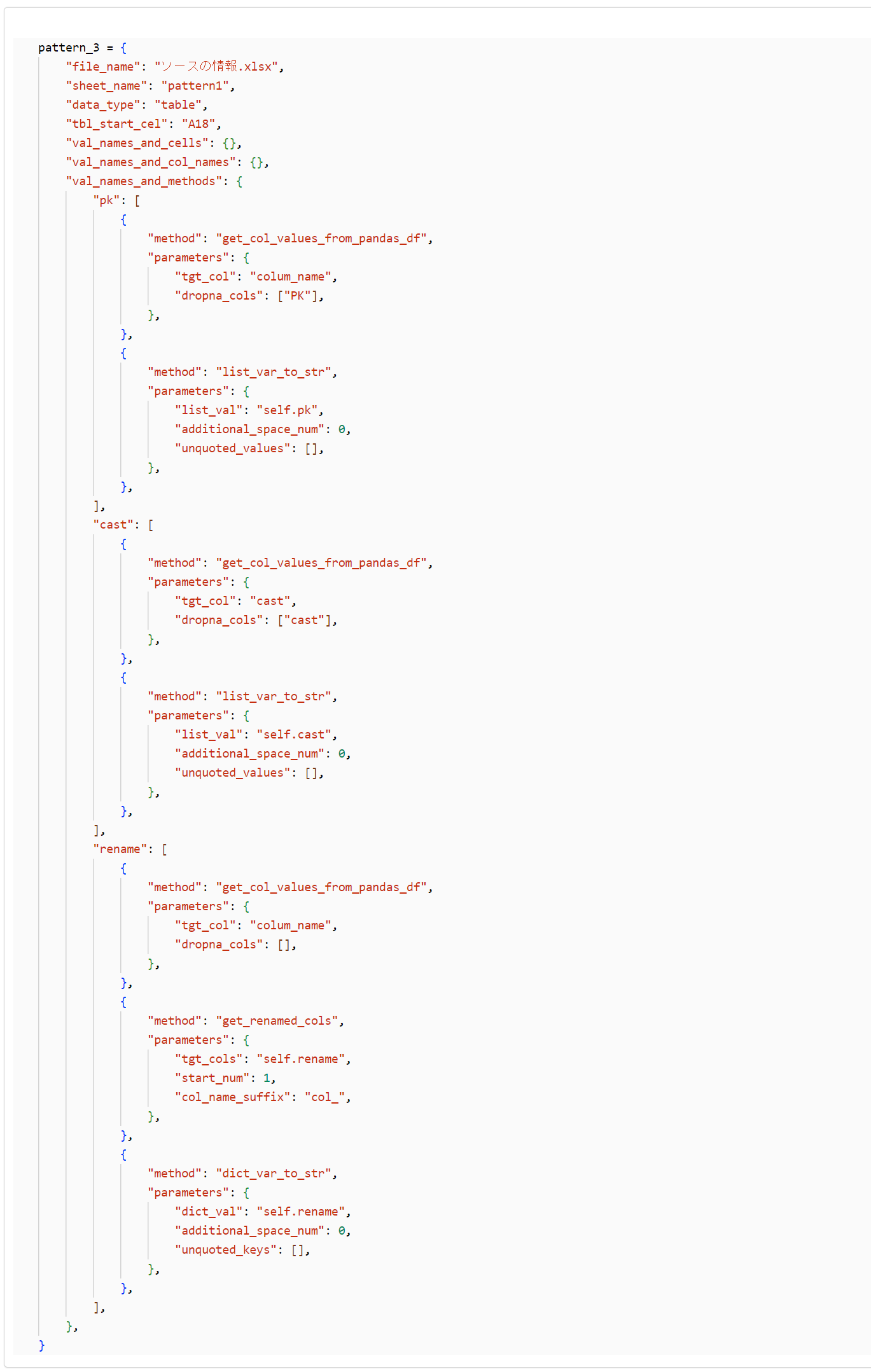
pattern_3 = {
"file_name": "ソースの情報.xlsx",
"sheet_name": "pattern1",
"data_type": "table",
"tbl_start_cel": "A18",
"val_names_and_cells": {},
"val_names_and_col_names": {},
"val_names_and_methods": {
"pk": [
{
"method": "get_col_values_from_pandas_df",
"parameters": {
"tgt_col": "colum_name",
"dropna_cols": ["PK"],
},
},
{
"method": "list_var_to_str",
"parameters": {
"list_val": "self.pk",
"additional_space_num": 0,
"unquoted_values": [],
},
},
],
"cast": [
{
"method": "get_col_values_from_pandas_df",
"parameters": {
"tgt_col": "cast",
"dropna_cols": ["cast"],
},
},
{
"method": "list_var_to_str",
"parameters": {
"list_val": "self.cast",
"additional_space_num": 0,
"unquoted_values": [],
},
},
],
"rename": [
{
"method": "get_col_values_from_pandas_df",
"parameters": {
"tgt_col": "colum_name",
"dropna_cols": [],
},
},
{
"method": "get_renamed_cols",
"parameters": {
"tgt_cols": "self.rename",
"start_num": 1,
"col_name_suffix": "col_",
},
},
{
"method": "dict_var_to_str",
"parameters": {
"dict_val": "self.rename",
"additional_space_num": 0,
"unquoted_keys": [],
},
},
],
},
}
クラスをインスタンス化します。
excel_opr = excel_operations()

Pandas にて Excel のシートからデータフレームを作成して、データフレームの値を変数にセットします。最後にセットした変数の値を表示します。
excel_opr.create_pdf_from_excel(
file_dir=file_dir,
file_name=pattern_3["file_name"],
sheet_name=pattern_3["sheet_name"],
dtype=str,
tbl_start_cel=pattern_3["tbl_start_cel"],
)
excel_opr.set_vals(pattern_3["val_names_and_methods"])
for key in pattern_3["val_names_and_methods"].keys():
print(key + ": " + eval(f"excel_opr.{key}"))

関連機能
辞書型変数とリスト型変数を文字型に変換
クラスをインスタンス化します。
excel_opr = excel_operations()

リスト型の変数を文字型に変換します。
# リストを str 型に変換
list_val_01 = [
"a",
"b",
"c",
]
list_str = excel_opr.list_var_to_str(list_val_01)
print("type:",type(list_str))
print("value:",list_str)
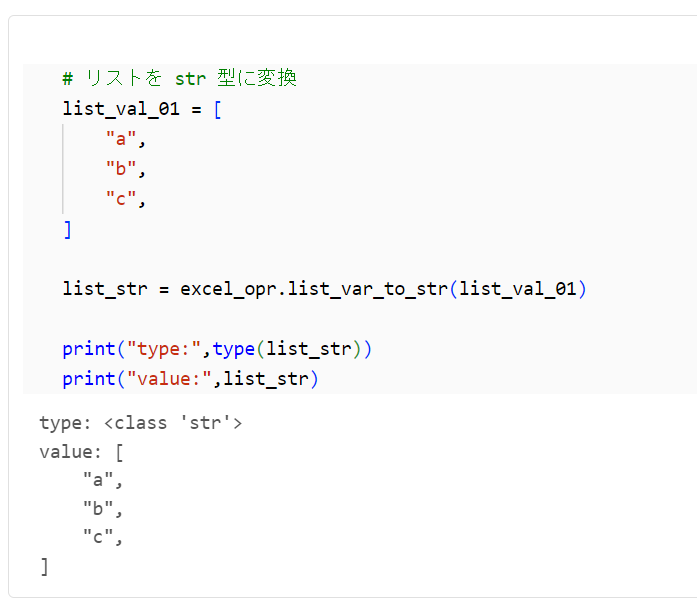
リスト型の変数を文字型に変換します。
# 辞書型変数を str 型に変換
dict_val_01 = {
"key_01": "a",
"key_02": "b",
"key_03": "c",
}
dict_str = excel_opr.dict_var_to_str(dict_val_01, 0, ["key_02"])
print("type:",type(list_str))
print("value:", list_str)
まとめ
本記事では、Excel形式の設計書からプログラムの変数を生成する方法について検証しました。具体的には、Excelの設計書が表で記述されていることを前提として、行方向に情報を保持する表、列方向に多数のプログラム情報を保持する表、列方向に単一のプログラム情報を保持する表の3つの類型からデータを取得する方法を検証しました。
また、それぞれの類型に対応するためのプログラムを作成し、それぞれのプログラムが正しく動作することを確認しました。これにより、Excel形式の設計書からプログラムの変数を効率的に生成することが可能となりました。
さらに、関連機能として、辞書型変数とリスト型変数を文字型に変換する機能も提供しました。これにより、取得したデータをさらに加工して利用することが可能となりました。
これらの検証結果とプログラムは、Excel形式の設計書を用いたシステム開発において、設計書からプログラムの変数を効率的に生成するための参考となることでしょう。