概要
Databricks のデータフレームにて Azure Event Hubs に対して Avro 形式でデータの書き込みと読み込みを実施する方法を共有します。
事前準備
Azure Event Hubs の SAS を取得
下記の記事を参考に SAS 認証により Databricks から Azure Event Hubs の SAS を取得してください。
- Databricks DLT にて Azure Event Hubs から SAS 認証によりデータを取得する方法 #dlt - Qiita
- Databricks のデータフレームにて Azure Event Hubs へ SAS 認証によりデータを書き込む方法 #AzureEventHubs - Qiita
Databricks にてデータベースオブジェクトを作成
カレントカタログを設定します。
%sql
USE CATALOG manabian_test_01;
スキーマを作成します。
%sql
CREATE SCHEMA IF NOT EXISTS eh_test_01;
ソースのテーブルを作成します。
%sql
CREATE OR REPLACE TABLE eh_test_01.table_01
AS
SELECT
1 AS id,
'John' AS string_col,
CAST('2025-01-01' AS TIMESTAMP) AS ingest_ts
;
SELECT * FROM eh_test_01.table_01;
処理時のチェックポイントに利用する Volume を作成します。
%sql
CREATE VOLUME IF NOT EXISTS eh_test_01.volume_01;
volume_path = "/Volumes/manabian_test_01/eh_test_01/volume_01"
dbutils.fs.rm(volume_path, True)
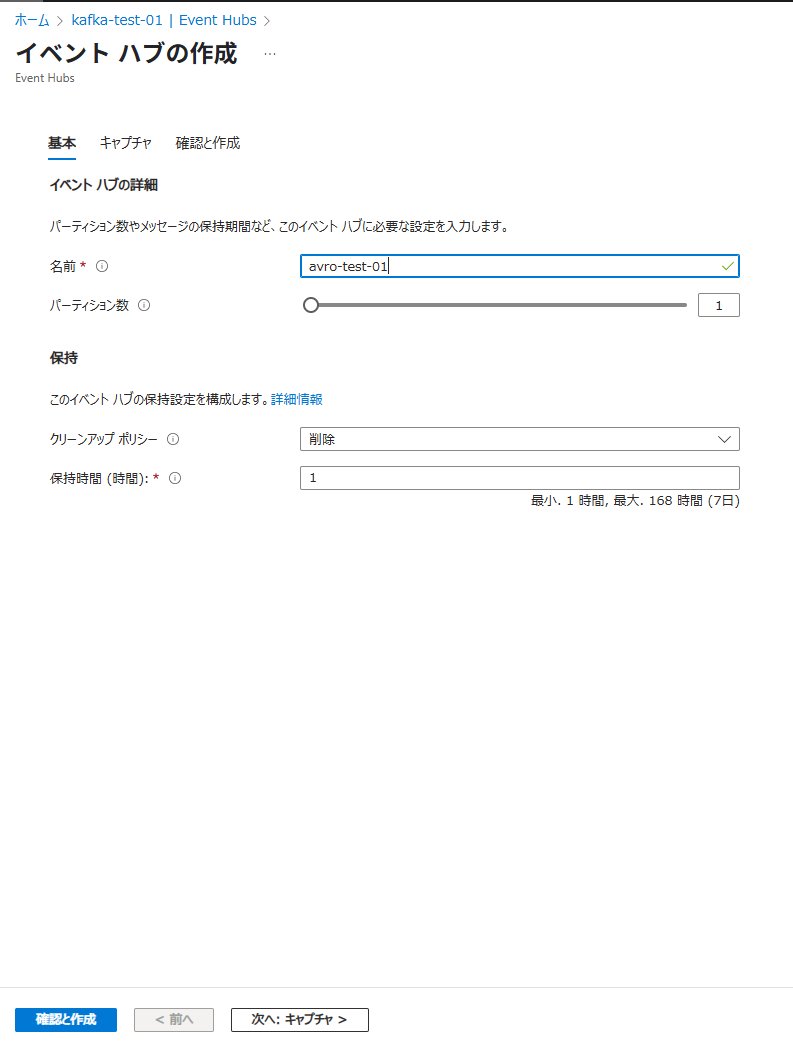
Azure Event Hubs にてavro-test-01という名称の Azure Event Hubs のインスタンスを作成
手順
1. Databricks にて Azure Event Hubs に対する書き込みの実施
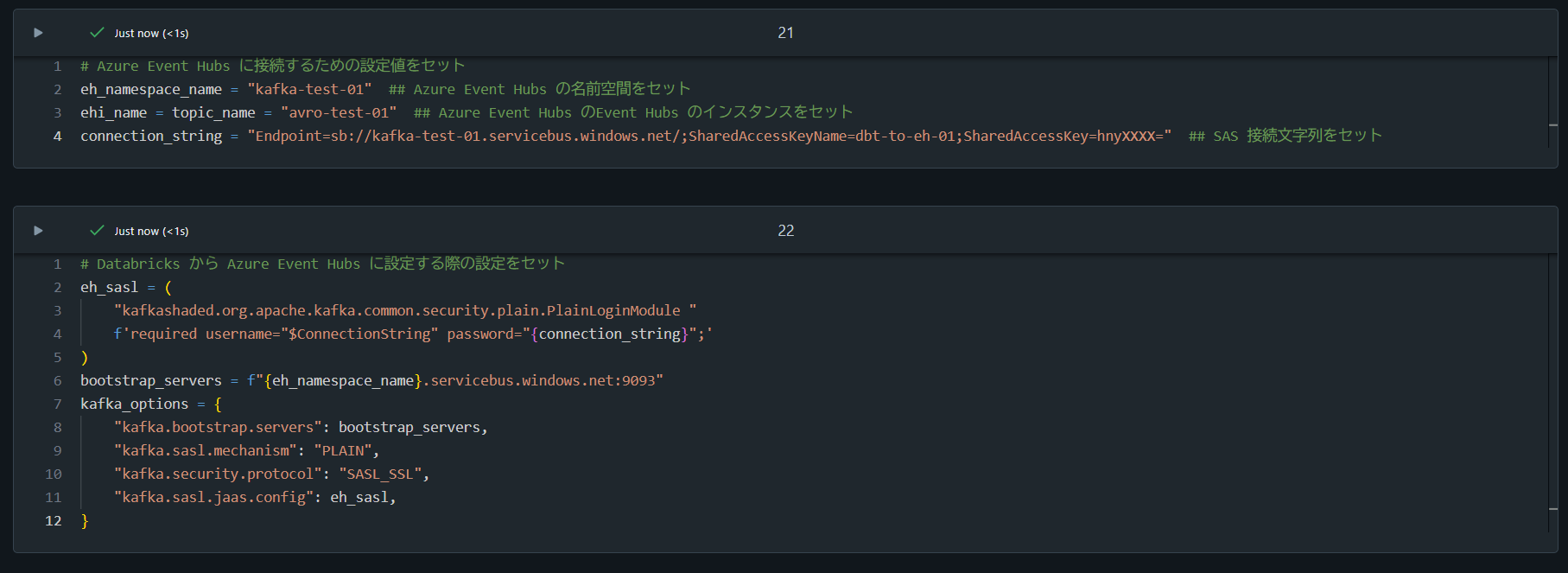
# Azure Event Hubs に接続するための設定値をセット
eh_namespace_name = "kafka-test-01" ## Azure Event Hubs の名前空間をセット
ehi_name = topic_name = "avro-test-01" ## Azure Event Hubs のEvent Hubs のインスタンスをセット
connection_string = "Endpoint=sb://kafka-test-01.servicebus.windows.net/;SharedAccessKeyName=dbt-to-eh-01;SharedAccessKey=hnyXXXX=" ## SAS 接続文字列をセット
# Databricks から Azure Event Hubs に設定する際の設定をセット
eh_sasl = (
"kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule "
f'required username="$ConnectionString" password="{connection_string}";'
)
bootstrap_servers = f"{eh_namespace_name}.servicebus.windows.net:9093"
kafka_options = {
"kafka.bootstrap.servers": bootstrap_servers,
"kafka.sasl.mechanism": "PLAIN",
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.jaas.config": eh_sasl,
}
2. Databricks から Azure Event Hubs から読み込みの実施
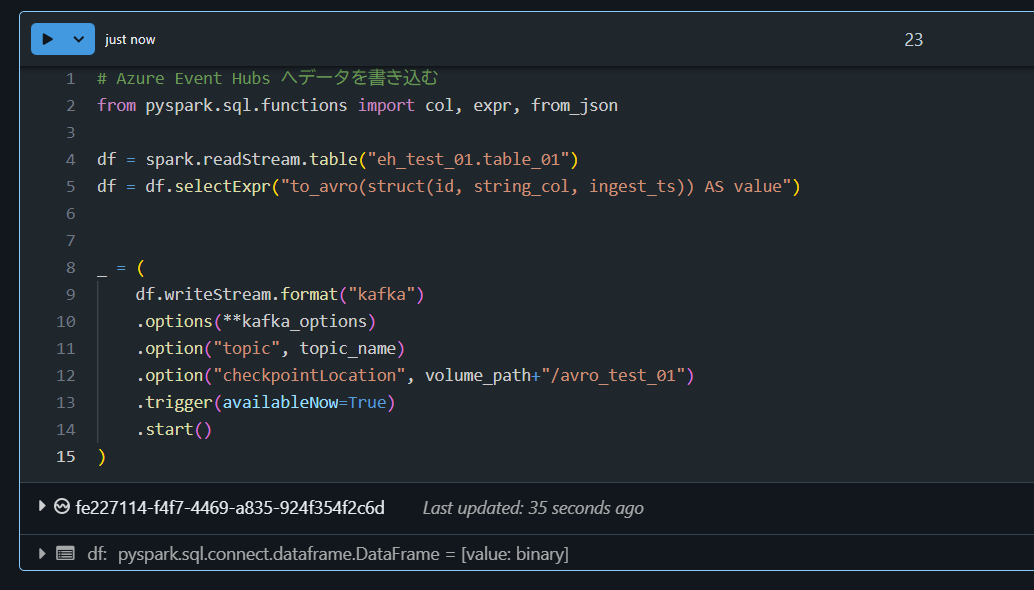
# Azure Event Hubs へデータを書き込む
from pyspark.sql.functions import col, expr, from_json
df = spark.readStream.table("eh_test_01.table_01")
df = df.selectExpr("to_avro(struct(id, string_col, ingest_ts)) AS value")
_ = (
df.writeStream.format("kafka")
.options(**kafka_options)
.option("topic", topic_name)
.option("checkpointLocation", volume_path+"/avro_test_01")
.trigger(availableNow=True)
.start()
)
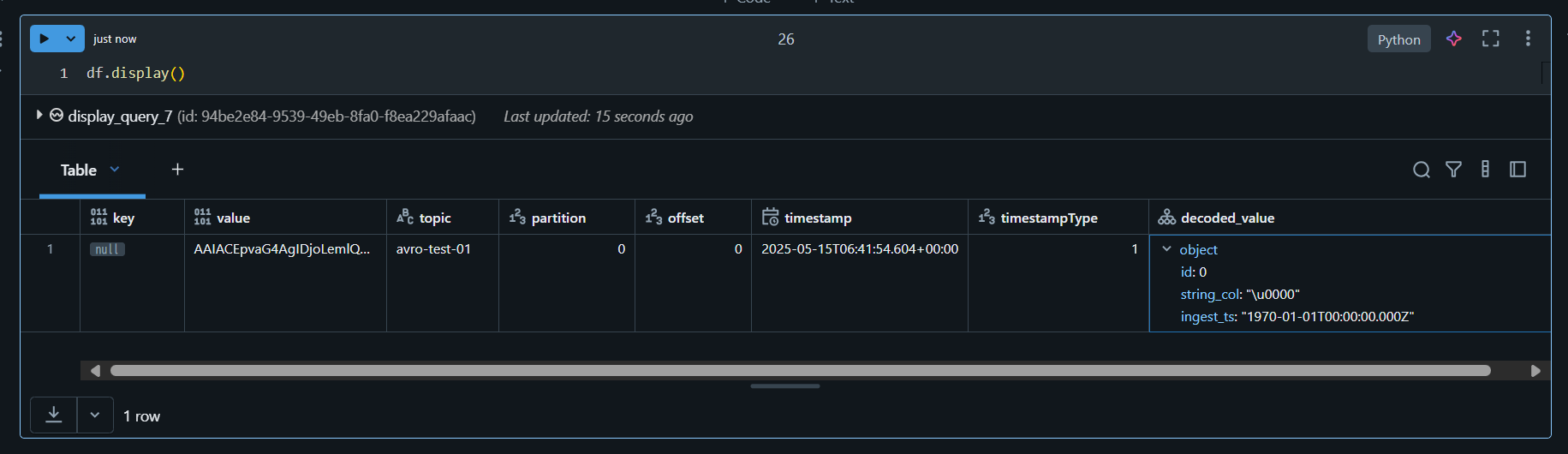
Azure Event Hubs の画面にてデータが書きこまれたことを確認します。
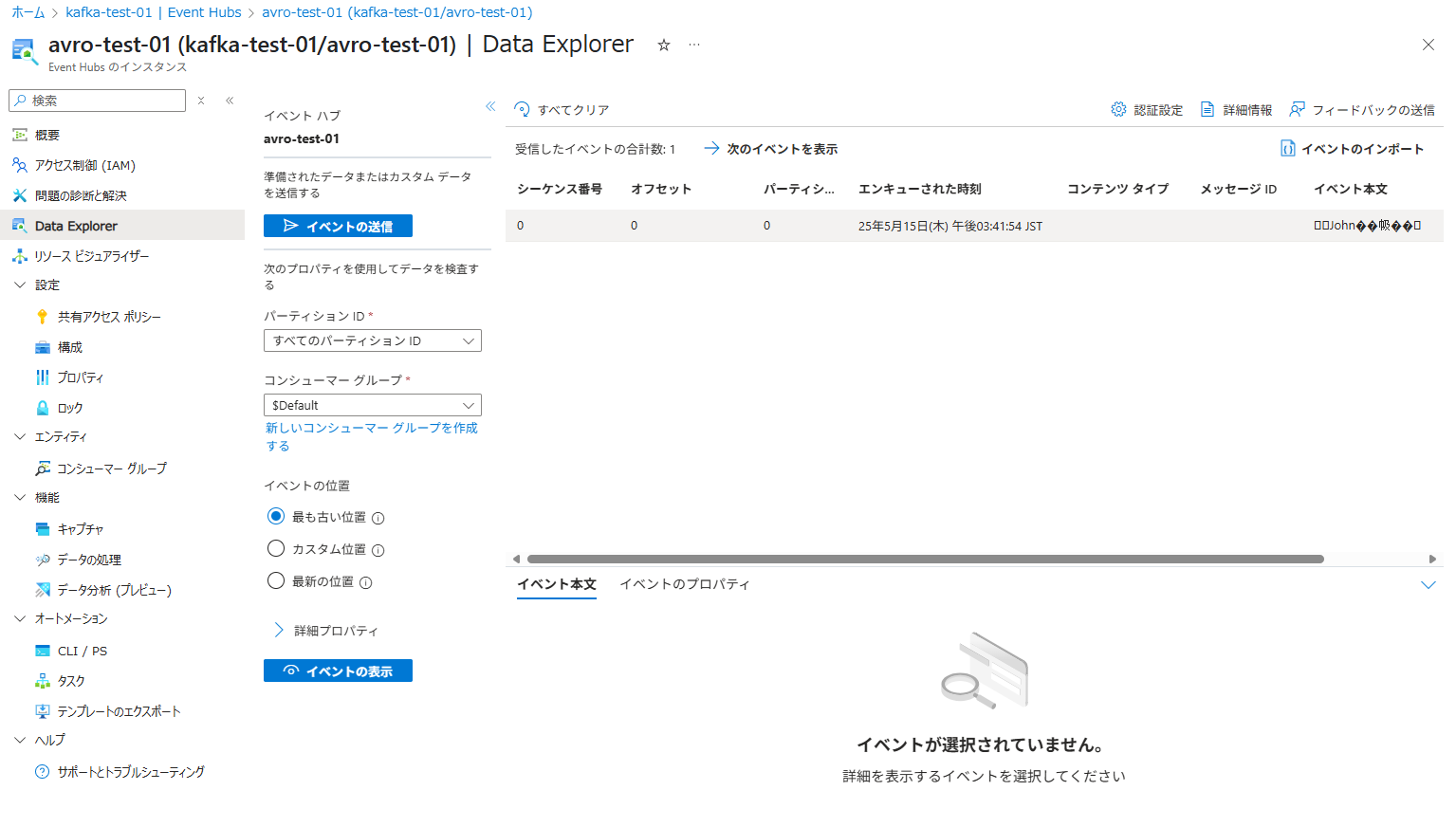
3. Databricks から Azure Event Hubs から読み込みの実施
schema = """
{
"name": "kafka_test_01.avro_0",
"type": "record",
"fields": [
{
"name": "id",
"type": "long"
},
{
"name": "string_col",
"type": "string"
},
{
"name": "ingest_ts",
"type": {
"type": "long",
"logicalType": "timestamp-micros"
}
}
]
}
"""
# Azure Event Hubs からデータを取得
from pyspark.sql.functions import col
from pyspark.sql.avro.functions import from_avro
df = (
spark.readStream.format("kafka")
.options(**kafka_options)
.option("subscribe", topic_name)
.option("startingOffsets", "earliest") # 検証目的であるため earliest に設定
.load()
)
df = df.withColumn(
"decoded_value",
from_avro(
col("value"),
schema,
),
)
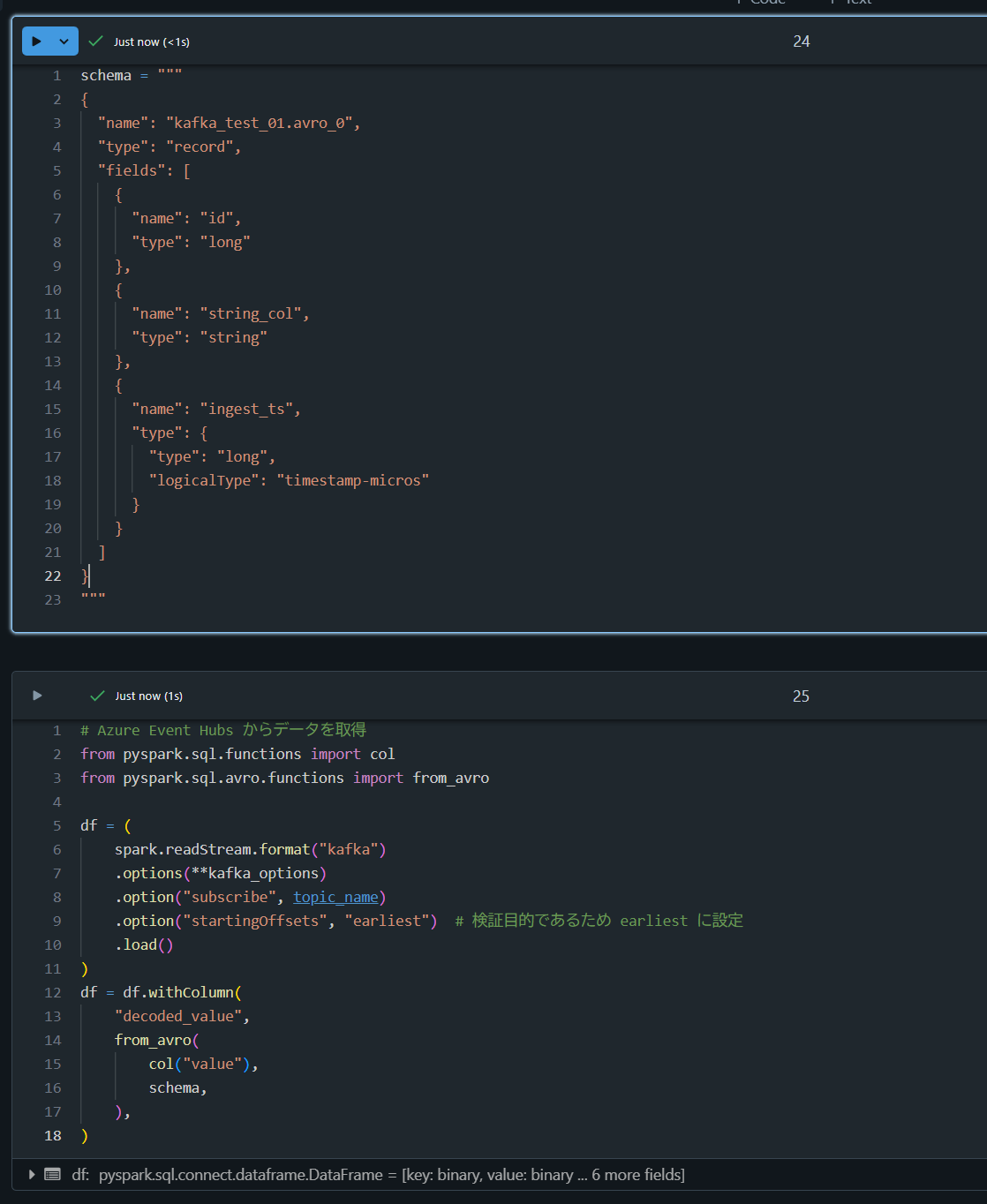
df.display()