Unity Catalog のテーブルへ移行方法論概要
本文書では、HiveメタストアのテーブルからUnityカタログのテーブルに移行する方法を紹介します。Unity Catalogでは、Deltaテーブルのみがサポートされているため、移行元テーブルの種類に基づく移行方法が必要となります。本記事では、次表で示すソーステーブルに応じた移行方法を行うための検証結果と実際の移行方法を記述します。
| # | ソーステーブル | 移行方法 |
|---|---|---|
| 1 | Delta テーブル |
DEEP CLONE を実行後、テーブルコメントを設定。 |
| 2 | Delta 以外のテーブル |
CREATE TABLE LIKE により Delta テーブルの定義を生成して、TBLPROPERTIESを設定後にデータをロード。 |
テーブルのメタデータには次表で示す項目があり、DEEP CLONE での反映可否を記述しています。DEEP CLONE による反映ではtable_commentのみ想定通りに反映されず、Delta テーブルのdescription列の値を反映するなどの対応が必要です。データへの権限付与については、Hive メタストア利用時と Hive メタストア利用時で設定方法が異なるため、対象外としてます。
| # | テーブルのメタデータ | DEEP CLONE による反映可否 |
|---|---|---|
| 1 | table_name | 〇 |
| 2 | table_comment | × |
| 3 | data_source | 〇 |
| 4 | column_identifier | 〇 |
| 5 | column_type | 〇 |
| 6 | column_comment | 〇 |
| 7 | NOT NULL constraint | 〇 |
| 8 | GENERATED ALWAYS | 〇 |
| 9 | DEFAULT | 〇 |
| 10 | TBLPROPERTIES | 〇 |
| 11 | PARTITIONED BY | 〇 |
| 12 | CHECK constraint | 〇 |
| 13 | BLOOM FILTER INDEX | 〇 |
テーブルの説明(table_comment)については、複製されない旨がドキュメントに記載さています。
複製されないメタデータは、テーブルの説明とユーザー定義のコミット メタデータです。
引用元:複製の種類 - Azure Databricks | Microsoft Learn
1. 事前準備
1-1. カタログとスキーマの作成
Hive メタストアと Unity Catalog 上に検証に利用するオブジェクトを作成します。
%sql
-- Create schema in hive metastore
CREATE SCHEMA IF NOT EXISTS hive_metastore.uc_migration_01;
-- Create catalog and schema in Unity catalog
CREATE CATALOG IF NOT EXISTS uc_migration_01;
CREATE SCHEMA IF NOT EXISTS uc_migration_01.schema_01;
1-2. Hive メタストアに Delta テーブルを作成
Databricks 上にあるサンプルデータである TPC-CH の NATION のファイルをベースにした Delta テーブルを作成し、データのロードなどを行います。
%sql
CREATE OR REPLACE TABLE hive_metastore.uc_migration_01.nation_delta
(
N_NATIONKEY integer COMMENT 'This is a N_NATIONKEY'
,N_NAME string COMMENT 'This is a N_NAME'
,N_REGIONKEY integer COMMENT 'This is a N_REGIONKEY'
,N_COMMENT string COMMENT 'This is a N_COMMENT'
,update_date TIMESTAMP COMMENT 'This is a update_date'
,getnerated_col string GENERATED ALWAYS AS ('default_value') COMMENT 'This is a getnerated_col'
,identity_col BIGINT GENERATED ALWAYS AS IDENTITY COMMENT 'This is a identity_col'
)
PARTITIONED BY (
N_REGIONKEY,
update_date
)
COMMENT 'This is a nation_delta'
TBLPROPERTIES (
delta.dataSkippingNumIndexedCols = 1
,delta.logRetentionDuration = 'interval 30 days'
,delta.deletedFileRetentionDuration= 'interval 7 days'
,delta.enableChangeDataFeed = true
,delta.autoOptimize.optimizeWrite = true
,delta.autoOptimize.autoCompact = true
,delta.tuneFileSizesForRewrites = true
)
;
-- Insert into table
INSERT INTO hive_metastore.uc_migration_01.nation_delta
(
N_NATIONKEY
,N_NAME
,N_REGIONKEY
,N_COMMENT
,update_date
)
SELECT
N_NATIONKEY
,N_NAME
,N_REGIONKEY
,N_COMMENT
,CAST(current_timestamp AS date) AS update_date
FROM
read_files(
'dbfs:/databricks-datasets/tpch/data-001/nation/nation.tbl',
format => 'csv',
sep => '|',
schema => '
N_NATIONKEY integer
,N_NAME string
,N_REGIONKEY integer
,N_COMMENT string
')
;
-- Set BLOOM FILTER INDEX
CREATE BLOOMFILTER INDEX ON TABLE hive_metastore.uc_migration_01.nation_delta
FOR COLUMNS(
N_NATIONKEY OPTIONS (
fpp = 0.4,
numItems = 40000000
),
N_NAME OPTIONS (
fpp = 0.1,
worthlessnumItems = 50000000
)
)
;
-- Set NOT NULL constraint
ALTER TABLE
hive_metastore.uc_migration_01.nation_delta
ALTER COLUMN
N_NATIONKEY
SET
NOT NULL;
-- Set CHECK constraint
ALTER TABLE
hive_metastore.uc_migration_01.nation_delta
DROP
CONSTRAINT IF EXISTS dateWithinRange
;
ALTER TABLE
hive_metastore.uc_migration_01.nation_delta
ADD
CONSTRAINT dateWithinRange CHECK (update_date > '1900-01-01')
;

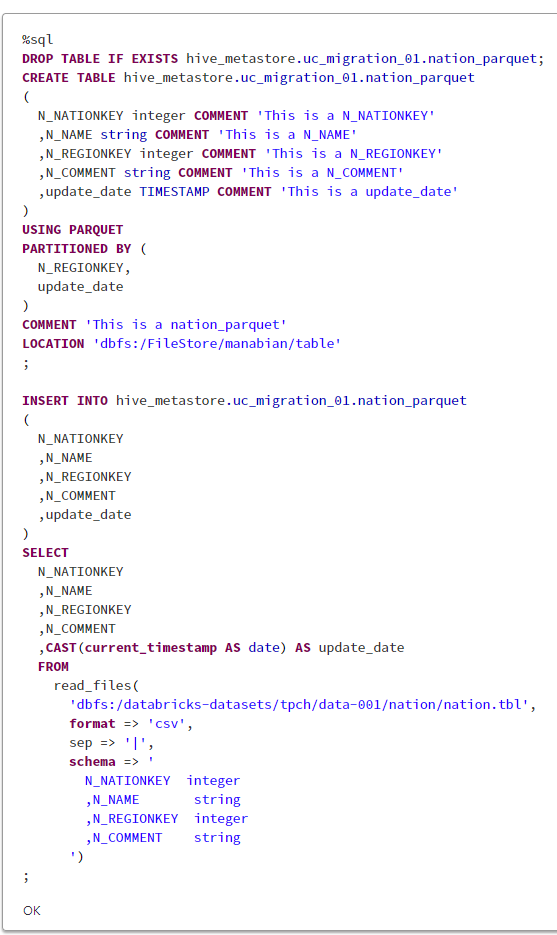
1-3. Hive メタストアに Delta 以外のテーブル(Parquet のテーブル)を作成
Databricks 上にあるサンプルデータである TPC-CH の NATION のファイルをベースにした Parquet テーブルを作成し、データのロードなどを行います。
%sql
DROP TABLE IF EXISTS hive_metastore.uc_migration_01.nation_parquet;
CREATE TABLE hive_metastore.uc_migration_01.nation_parquet
(
N_NATIONKEY integer COMMENT 'This is a N_NATIONKEY'
,N_NAME string COMMENT 'This is a N_NAME'
,N_REGIONKEY integer COMMENT 'This is a N_REGIONKEY'
,N_COMMENT string COMMENT 'This is a N_COMMENT'
,update_date TIMESTAMP COMMENT 'This is a update_date'
)
USING PARQUET
PARTITIONED BY (
N_REGIONKEY,
update_date
)
COMMENT 'This is a nation_parquet'
LOCATION 'dbfs:/FileStore/manabian/table'
;
INSERT INTO hive_metastore.uc_migration_01.nation_parquet
(
N_NATIONKEY
,N_NAME
,N_REGIONKEY
,N_COMMENT
,update_date
)
SELECT
N_NATIONKEY
,N_NAME
,N_REGIONKEY
,N_COMMENT
,CAST(current_timestamp AS date) AS update_date
FROM
read_files(
'dbfs:/databricks-datasets/tpch/data-001/nation/nation.tbl',
format => 'csv',
sep => '|',
schema => '
N_NATIONKEY integer
,N_NAME string
,N_REGIONKEY integer
,N_COMMENT string
')
;
2. 移行方法を検討するための技術検証
2-1. Delta テーブルがソーステーブルの場合に DEEP CLONE で反映される項目を確認
Hive メタストアの Delta テーブルを Unity Catalog の Delta テーブルとして DEEP CLONE を実施して、反映される項目を確認します。
%sql
DROP TABLE IF EXISTS uc_migration_01.schema_01.nation_delta;
CREATE TABLE uc_migration_01.schema_01.nation_delta
DEEP CLONE hive_metastore.uc_migration_01.nation_delta
;
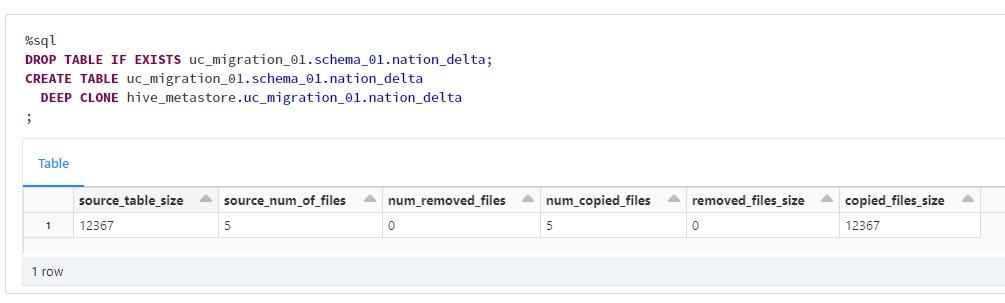
DEEP CLON により作成されたテーブルの DDL を次のコードで確認すると、COMMENTの記述を確認できませんでした。
ddl = spark.sql('SHOW CREATE TABLE uc_migration_01.schema_01.nation_delta').first()[0]
print(ddl)
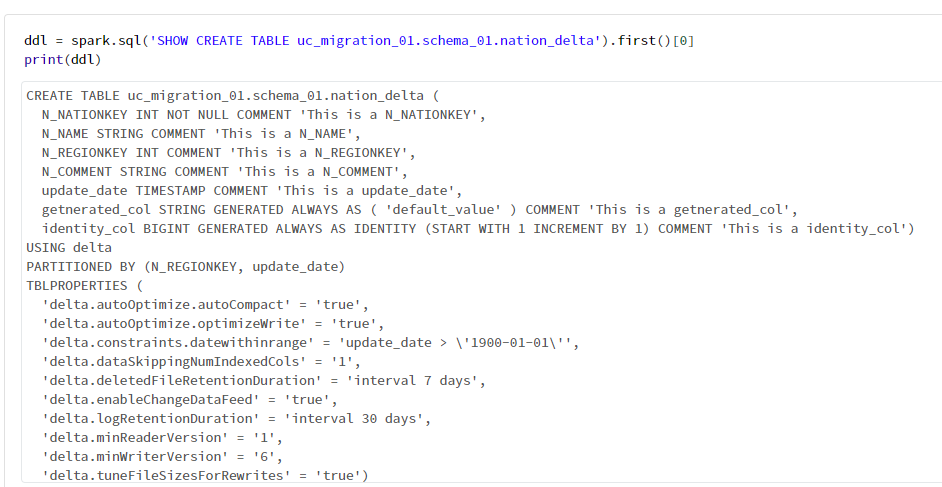
移行前後のdescriptionを確認すると、移行前のテーブルでは設定されているにも関わらず、移行後のテーブルでは null となっていることが確認できました。DEEP CLONE では反映されず、table_commentを追加するロジックが必要となる判断しました。
%sql
DESC DETAIL hive_metastore.uc_migration_01.nation_delta;

%sql
DESC DETAIL uc_migration_01.schema_01.nation_delta;

BLOOM FILTER INDEXについては、カラムのメタデータを確認したところ反映されていることを確認できました。
for field in spark.table("hive_metastore.uc_migration_01.nation_delta").schema:
if field.metadata:
print(f"{{'col_name':'{field.name}', 'metadata':{field.metadata}}}")

2-2. Delta 以外のテーブルがソーステーブルの場合に Delta テーブルの DDL の生成方法の検討
Databricks Runtime 13.0 以降で利用できるCREATE TABLE LIKEにより Parquet テーブルをもとに Delta テーブルの DDL を生成することを検証しました。
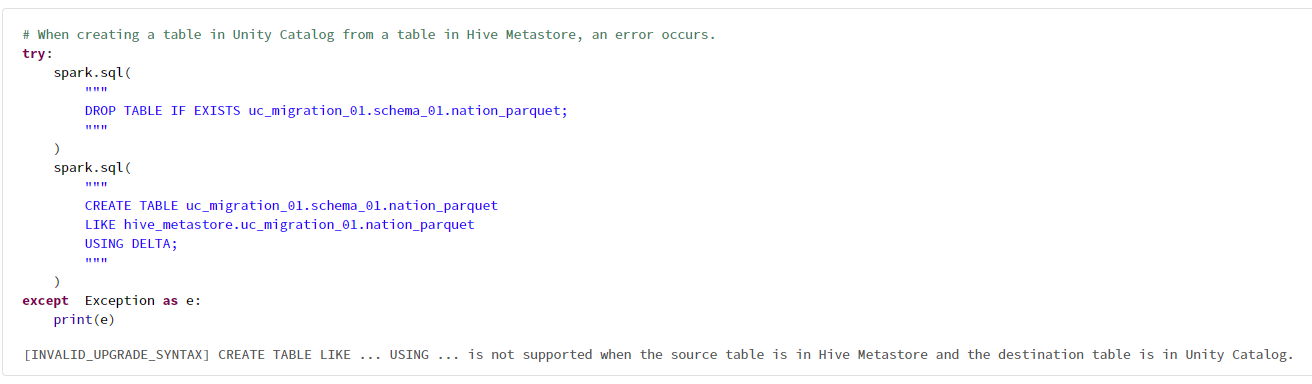
Hive メタストアのテーブルから Unity Catalog のテーブルを作成しようとすると次のようなエラーが発生しました。
# When creating a table in Unity Catalog from a table in Hive Metastore, an error occurs.
try:
spark.sql(
"""
DROP TABLE IF EXISTS uc_migration_01.schema_01.nation_parquet;
"""
)
spark.sql(
"""
CREATE TABLE uc_migration_01.schema_01.nation_parquet
LIKE hive_metastore.uc_migration_01.nation_parquet
USING DELTA;
"""
)
except Exception as e:
print(e)
[INVALID_UPGRADE_SYNTAX] CREATE TABLE LIKE ... USING ... is not supported when the source table is in Hive Metastore and the destination table is in Unity Catalog.
Hive メタストア間であれば想定通りに実行できたため、Hive メタストアのテーブルとして DDL を作成する方針に変更しました。一時的作成したにテーブルの DDL を取得して、テーブル名の Unity Catalog のテーブルに置換した SQL 文を利用します。
# Get the DDL of the Hive Metastore table by temporarily creating a Unity Catalog table
spark.sql(
"""
DROP TABLE IF EXISTS hive_metastore.uc_migration_01.nation_parquet__temp;
"""
)
spark.sql(
"""
CREATE TABLE hive_metastore.uc_migration_01.nation_parquet__temp
LIKE hive_metastore.uc_migration_01.nation_parquet
USING DELTA
TBLPROPERTIES (
'delta.autoOptimize.autoCompact' = 'true'
);
"""
)
ddl = spark.sql('SHOW CREATE TABLE hive_metastore.uc_migration_01.nation_parquet__temp').first()[0]
print(ddl)

一時的に作成したテーブルを削除します。
%sql
-- Drop the temporary table
DROP TABLE hive_metastore.uc_migration_01.nation_parquet__temp;

3. Unity Catalog のテーブルへの移行用 SQL の生成と実行
3-1. 移行用 SQL の生成
Unity Catalog のテーブルへの移行用 SQL の生成するための次のような関数を定義しました。delta や parquet などのテーブルで設定している data_source に応じて分岐するようになっております。生成した SQL を表示するのみであり、実行は行わず、出力結をコピー&ペースして実行する想定です。
import inspect
import os
from distutils.version import LooseVersion, StrictVersion
def generate_uc_ddl_from_hive_metastore_tbl(
tables_config,
should_print=True,
):
"""Generates DDL statements for creating new tables in Unity Catalog from existing tables in Hive Metastore.
Args:
tables_config (list): A list of dictionaries containing configuration information for each table to be migrated.
should_print (bool, optional): Whether to print the generated SQL statements. Defaults to True.
Raises:
Exception: If Databricks Runtime version is not 13.0 or later.
Returns:
dict: A dictionary containing the generated SQL statements for each table.
"""
old_tbl_name_key = "old_table_name"
new_table_name_key = "new_table_name"
new_location_key = "new_location"
tblproperties_key = "tblproperties"
temp_table_name_key = "temp_table_name"
current_db_runtiem_version = os.environ.get('DATABRICKS_RUNTIME_VERSION',None)
exp_runtiem_version = "13.0"
# Check if the Databricks Runtime version is 13.0 or later
if not(StrictVersion(current_db_runtiem_version) > StrictVersion(exp_runtiem_version)):
raise Exception('Because `CREATE TABLE LIKE` is being used, Databricks Runtime must be 13.0 or later.')
migration_sqls = {}
for tbl_cof in tables_config:
old_table_name = tbl_cof[old_tbl_name_key]
new_table_name = tbl_cof[new_table_name_key]
new_location = tbl_cof[new_location_key]
tblproperties = tbl_cof.get(tblproperties_key, {})
temp_table_name = tbl_cof.get(temp_table_name_key, f"{old_table_name}__tmp")
# Get the data source of the table
data_src = (
spark.sql(f"DESC EXTENDED {old_table_name}")
.filter("col_name = 'Provider'")
.select("data_type")
.first()[0]
.lower()
)
sqls = []
if data_src == "delta":
# Generate SQL statement for creating a new table using DEEP CLONE
deep_clone_sql = f"""
CREATE OR REPLACE TABLE {new_table_name}
DEEP CLONE {old_table_name}
"""
if new_location != "":
deep_clone_sql += f" LOCATION '{new_location}'"
deep_clone_sql = inspect.cleandoc(deep_clone_sql)
deep_clone_sql += ";"
sqls.append(deep_clone_sql)
# Generate SQL statement for adding a table comment
table_comment = (
spark.sql(f"DESC DETAIL {old_table_name}")
.select("description")
.first()[0]
)
if table_comment is not None:
table_comment_sql = f"""
COMMENT ON TABLE {new_table_name}
IS '{table_comment}'
"""
table_comment_sql = inspect.cleandoc(table_comment_sql)
table_comment_sql += ";"
sqls.append(table_comment_sql)
else:
# Generate SQL statement for creating a temporary table
spark.sql(
f"""
DROP TABLE IF EXISTS {temp_table_name};
"""
)
spark.sql(
f"""
CREATE TABLE {temp_table_name}
LIKE {old_table_name}
USING DELTA;
"""
)
# Generate SQL statement for getting the DDL of the temporary table
ddl = spark.sql(
f"""
SHOW CREATE TABLE {temp_table_name};
"""
).first()[0]
ddl += ";"
# Replace the temporary table name with the new table name in the DDL
ddl = ddl.replace(
f"CREATE TABLE {temp_table_name}",
f"CREATE OR REPLACE TABLE {new_table_name}",
)
# Generate SQL statement for dropping the temporary table
spark.sql(
f"""
DROP TABLE {temp_table_name};
"""
)
sqls.append(ddl)
# Generate SQL statement for adding table properties
if tblproperties != {}:
tblproperties_values = ",\n ".join(
[
f"'{tblproperties_key}' = '{tblproperties_name}'"
for tblproperties_key, tblproperties_name in tblproperties.items()
]
)
tblproperties_ddl = f"""
ALTER TABLE {new_table_name}
SET TBLPROPERTIES (
{tblproperties_values}
);
"""
tblproperties_ddl = inspect.cleandoc(tblproperties_ddl)
sqls.append(tblproperties_ddl)
# Generate SQL statement for inserting data
insert_sql = f"""
INSERT INTO TABLE {new_table_name}
SELECT
*
FROM {old_table_name}
;
"""
insert_sql = inspect.cleandoc(insert_sql)
sqls.append(insert_sql)
migration_sqls[new_table_name] = sqls
# Print the generated SQL statements
if should_print:
for tbl_name, sqls in migration_sqls.items():
print(f"-- `{tbl_name}` ddls")
for sql in sqls:
print(sql)
print("")
return migration_sqls
上記関数では、次のようなパラメータを渡すことを想定しております。
| # | 項目 | 概要 |
|---|---|---|
| 1 | old_table_name | 移行元テーブル名。 |
| 2 | new_table_name | 移行先テーブル名。 |
| 3 | new_location | 移行先テーブルのロケーション。空白の場合には、マネージドテーブルとなる。 |
| 4 | temp_table_name | 移行元テーブルが Delta 以外のテーブルの場合に利用する 一時テーブル名。 |
| 5 | tblproperties | 移行元テーブルが Delta 以外のテーブルの場合に設定する TBLPROPERTIES。 |
# sample parameter
[
{
"old_table_name": "hive_metastore.uc_migration_01.nation_delta",
"new_table_name": "uc_migration_01.schema_01.nation_delta",
"new_location": "",
},
{
"old_table_name": "hive_metastore.uc_migration_01.nation_parquet",
"temp_table_name": "hive_metastore.uc_migration_01.nation_parquet__temp",
"new_table_name": "uc_migration_01.schema_01.nation_delta_parquet",
"new_location": "",
"tblproperties": {
'delta.autoOptimize.autoCompact': 'true',
'delta.autoOptimize.optimizeWrite': 'true',
},
},
]
実際に関数を実行すると、テーブルごとに実行する SQL が表示されます。
tables_config = [
{
"old_table_name": "hive_metastore.uc_migration_01.nation_delta",
"new_table_name": "uc_migration_01.schema_01.nation_delta",
"new_location": "",
"table_comment": "This is a nation_delta",
},
{
"old_table_name": "hive_metastore.uc_migration_01.nation_parquet",
"temp_table_name": "hive_metastore.uc_migration_01.nation_parquet__temp",
"new_table_name": "uc_migration_01.schema_01.nation_delta_parquet",
"new_location": "",
"table_comment": "",
"tblproperties": {
'delta.autoOptimize.autoCompact': 'true',
'delta.autoOptimize.optimizeWrite': 'true',
},
},
]
migration_sqls = generate_uc_ddl_from_hive_metastore_tbl(tables_config)

3-2. 移行用 SQL の実行
関数により表示された SQL 文を実行します。
%sql
-- `uc_migration_01.schema_01.nation_delta` ddls
CREATE OR REPLACE TABLE uc_migration_01.schema_01.nation_delta
DEEP CLONE hive_metastore.uc_migration_01.nation_delta;
COMMENT ON TABLE uc_migration_01.schema_01.nation_delta
IS 'This is a nation_delta';
-- `uc_migration_01.schema_01.nation_delta_parquet` ddls
CREATE OR REPLACE TABLE uc_migration_01.schema_01.nation_delta_parquet (
N_NATIONKEY INT COMMENT 'This is a N_NATIONKEY',
N_NAME STRING COMMENT 'This is a N_NAME',
N_COMMENT STRING COMMENT 'This is a N_COMMENT',
N_REGIONKEY INT COMMENT 'This is a N_REGIONKEY',
update_date TIMESTAMP COMMENT 'This is a update_date')
USING delta
PARTITIONED BY (N_REGIONKEY, update_date)
COMMENT 'This is a nation_parquet'
TBLPROPERTIES (
'delta.minReaderVersion' = '1',
'delta.minWriterVersion' = '2')
;
ALTER TABLE uc_migration_01.schema_01.nation_delta_parquet
SET TBLPROPERTIES (
'delta.autoOptimize.autoCompact' = 'true',
'delta.autoOptimize.optimizeWrite' = 'true'
);
INSERT INTO TABLE uc_migration_01.schema_01.nation_delta_parquet
SELECT
*
FROM hive_metastore.uc_migration_01.nation_parquet
;
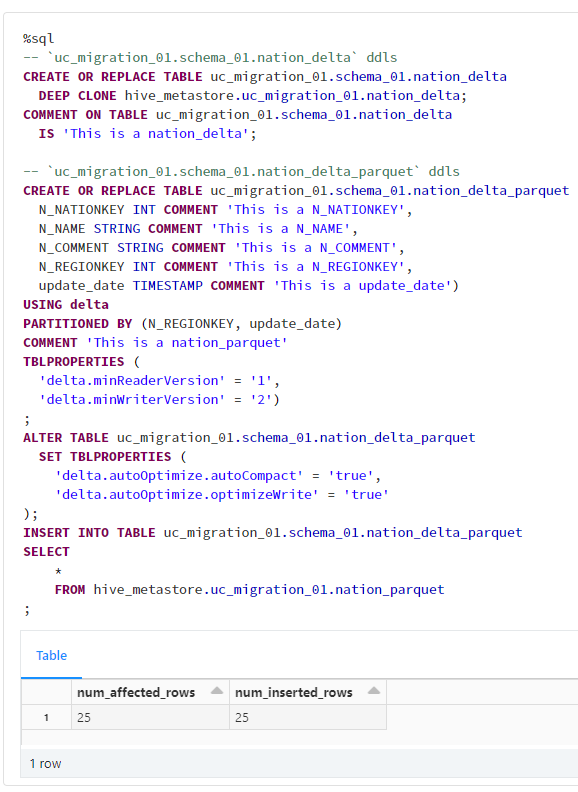
3-3. 移行後のテーブルの確認
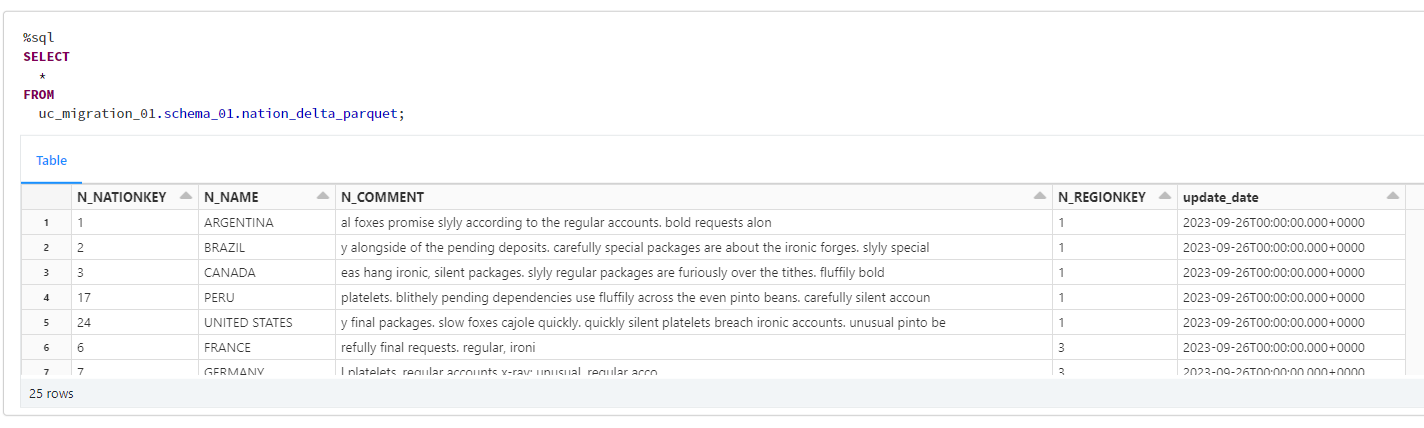
移行後の2つのテーブルのデータを確認したところ、想定通りにデータが移行されていることを確認できました。
%sql
SELECT
*
FROM
uc_migration_01.schema_01.nation_delta;

%sql
SELECT
*
FROM
uc_migration_01.schema_01.nation_delta_parquet;
4. リソースの削除
4-1. カタログとスキーマの削除
本手順で作成したオブジェクトの削除を実施します。
%sql
-- Drop the schema in Hive Metastore
DROP SCHEMA IF EXISTS hive_metastore.uc_migration_01 CASCADE;
-- Drop the catalog and schema in Unity Catalog
DROP CATALOG IF EXISTS uc_migration_01 CASCADE;

Conclusion
この記事では、Hive メタストアのテーブルから Unity Catalog のテーブルに移行する方法を紹介しました。Unity Catalog は Databricks の機能をフルに活用できるメタストアサービスです。Hive メタストアのテーブルは Delta テーブルとして Unity Catalog に移行できますが、その際にはテーブルの種類やメタデータに応じた適切な方法を選択する必要があります。本記事では、その方法を具体的な SQL スクリプトとともに説明しました。Unity Catalog によりデータ管理をより効率的かつ安全に行い、Databricks をより楽しみましょう。