概要
Databricks から Confluent に Protobuf 形式の Topic データを書き込む際にスキーマレジストリを利用して実施する方法を紹介します。
本記事は、以下のシリーズの一部です。

引用元:Databricks と Confluent をつなぐ:データ連携の全体像を徹底解説 #Spark - Qiita
事前準備
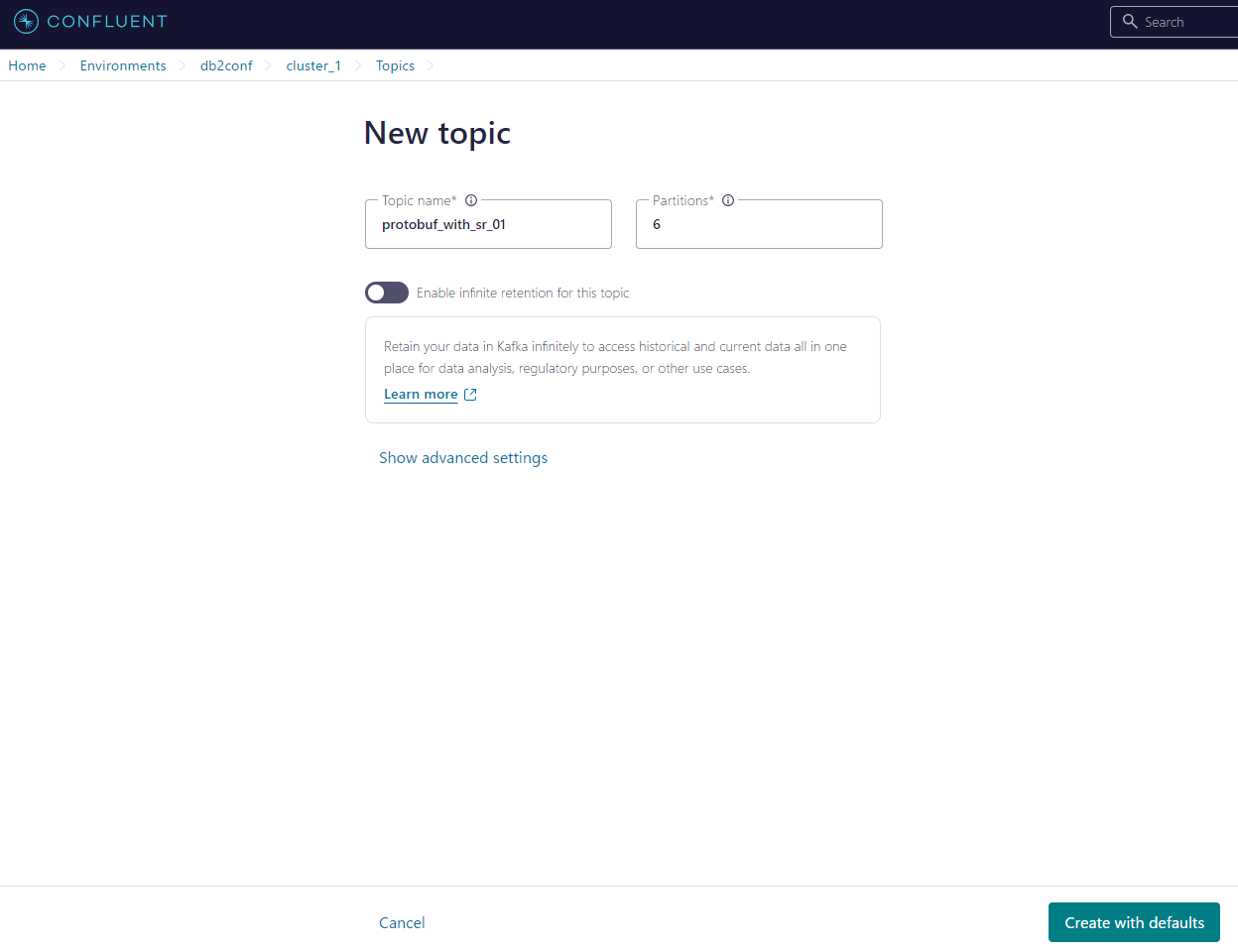
1. Confluent にて Topic を作成
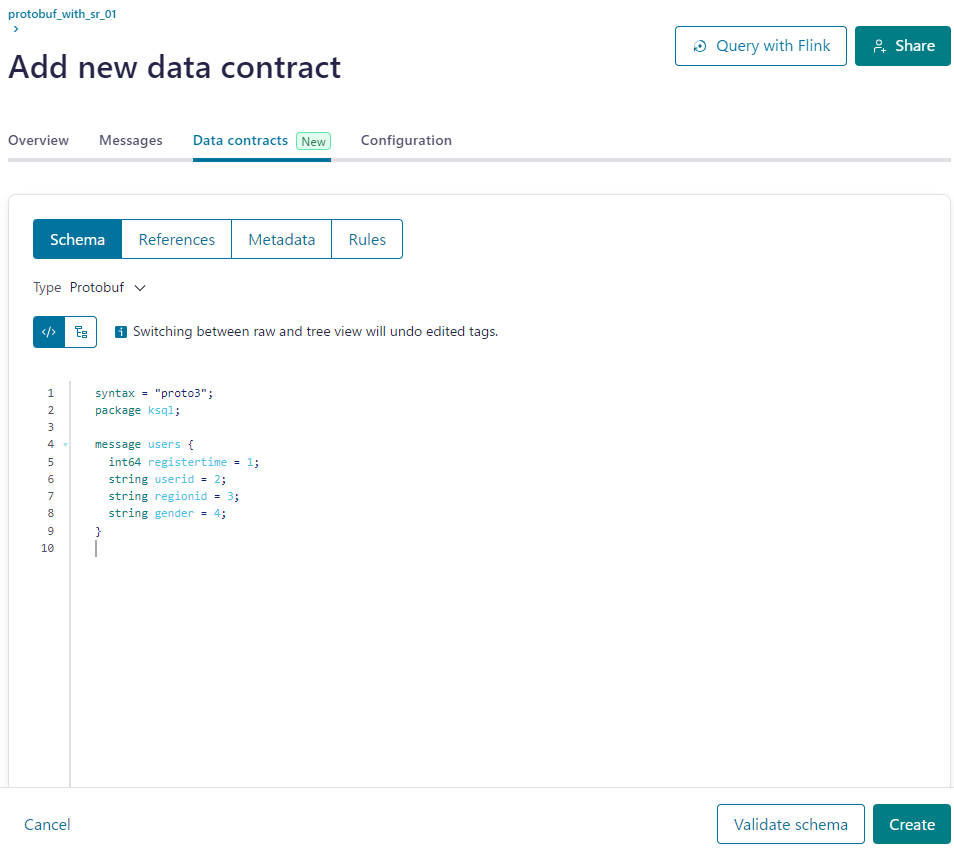
2. Confluent にて Topic にスキーマを設定
syntax = "proto3";
package ksql;
message users {
int64 registertime = 1;
string userid = 2;
string regionid = 3;
string gender = 4;
}
3. Confluent にて API キーを主塔

4. Confluent にて Schema Registry API キーを取得

5. Databricks にてデータベースのオブジェクトを作成
%sql
CREATE CATALOG IF NOT EXISTS confluent_test;
CREATE SCHEMA IF NOT EXISTS confluent_test.test;
src_table_name = "confluent_test.test.src_table"
checkpoint_volume_name = "confluent_test.test.checkpoint_01"
checkpoint_volume_dir = f"/Volumes/confluent_test/test/checkpoint_01"
spark.sql(f"CREATE TABLE IF NOT EXISTS {src_table_name}")
spark.sql(f"CREATE VOLUME IF NOT EXISTS {checkpoint_volume_name}")
dbutils.fs.rm(checkpoint_volume_dir, True)

6. テーブルにデータを書きこみ
data = [
("User_1", 1507214855421, "Region_1", "OTHER"),
("User_2", 1516353515688, "Region_2", "OTHER"),
("User_3", 1511384261793, "Region_3", "FEMALE")
]
columns = ["userid", "registertime", "regionid", "gender"]
df = spark.createDataFrame(data, columns)
df.write.format("delta").mode("overwrite").saveAsTable(src_table_name)
spark.table(src_table_name).display()

データを書き込む手順
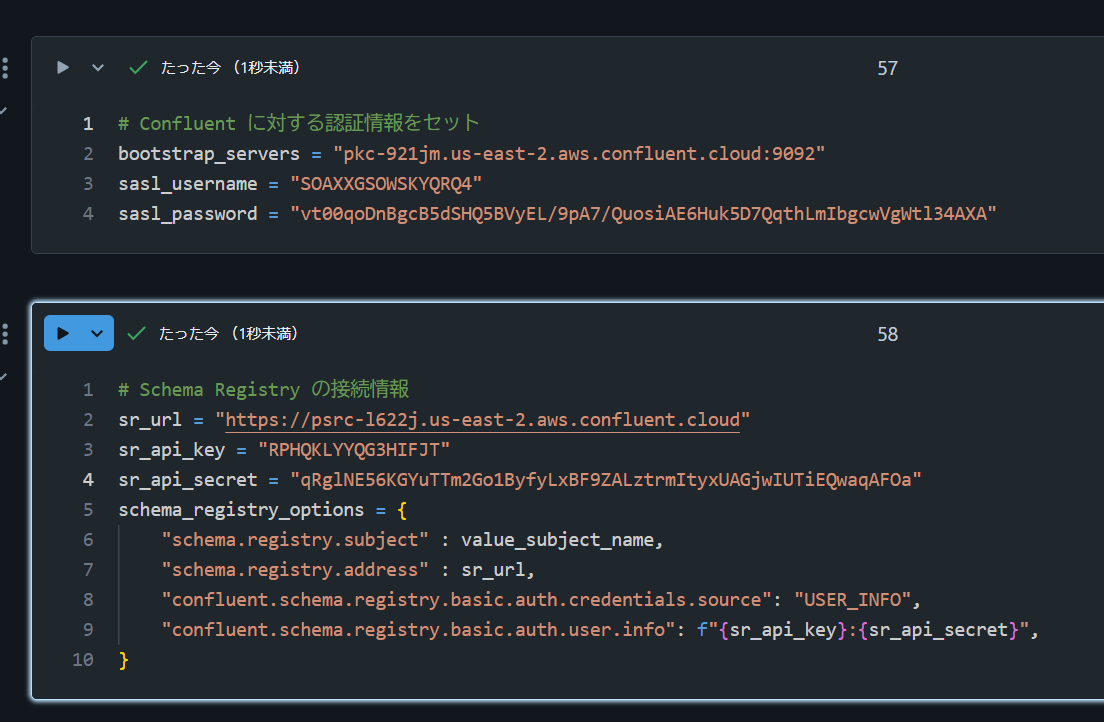
1. Databricks 上で API キーと Schema Registry API キーを変数にセット
# Confluent に対する認証情報をセット
bootstrap_servers = "pkc-921aa.us-east-2.aws.confluent.cloud:9092"
sasl_username = "U4BML4OPRCaaaa"
sasl_password = "zzEjUzyUwYYJneNE240L7jgPVrHAtRBANo6wnnzCgKlGIJ9OxJqaJZWRvaaaaa"
# Schema Registry の接続情報
sr_url = "https://psrc-l622j.us-east-2.aws.confluent.cloud"
sr_api_key = "RPHQKLYYQG3HIFJT"
sr_api_secret = "qRglNE56KGYuTTm2Go1ByfyLxBF9ZALztrmItyxUAGjwIUTiEQwaqAFOaaFAAAA"
schema_registry_options = {
"schema.registry.subject" : value_subject_name,
"schema.registry.address" : sr_url,
"confluent.schema.registry.basic.auth.credentials.source": "USER_INFO",
"confluent.schema.registry.basic.auth.user.info": f"{sr_api_key}:{sr_api_secret}",
}
2. Databricks に Topic と Subject を変数にセット
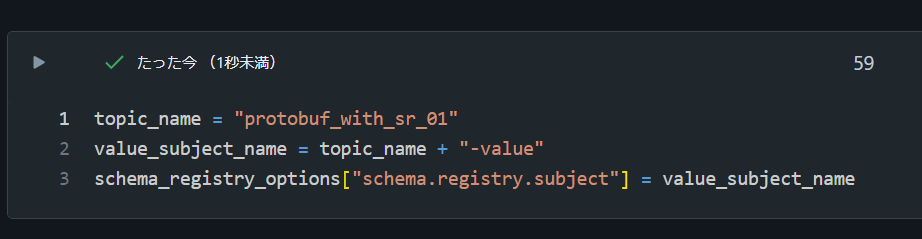
topic_name = "protobuf_with_sr_01"
value_subject_name = topic_name + "-value"
schema_registry_options["schema.registry.subject"] = value_subject_name
3. Databricks にて Conflunet へ書き込みを実施
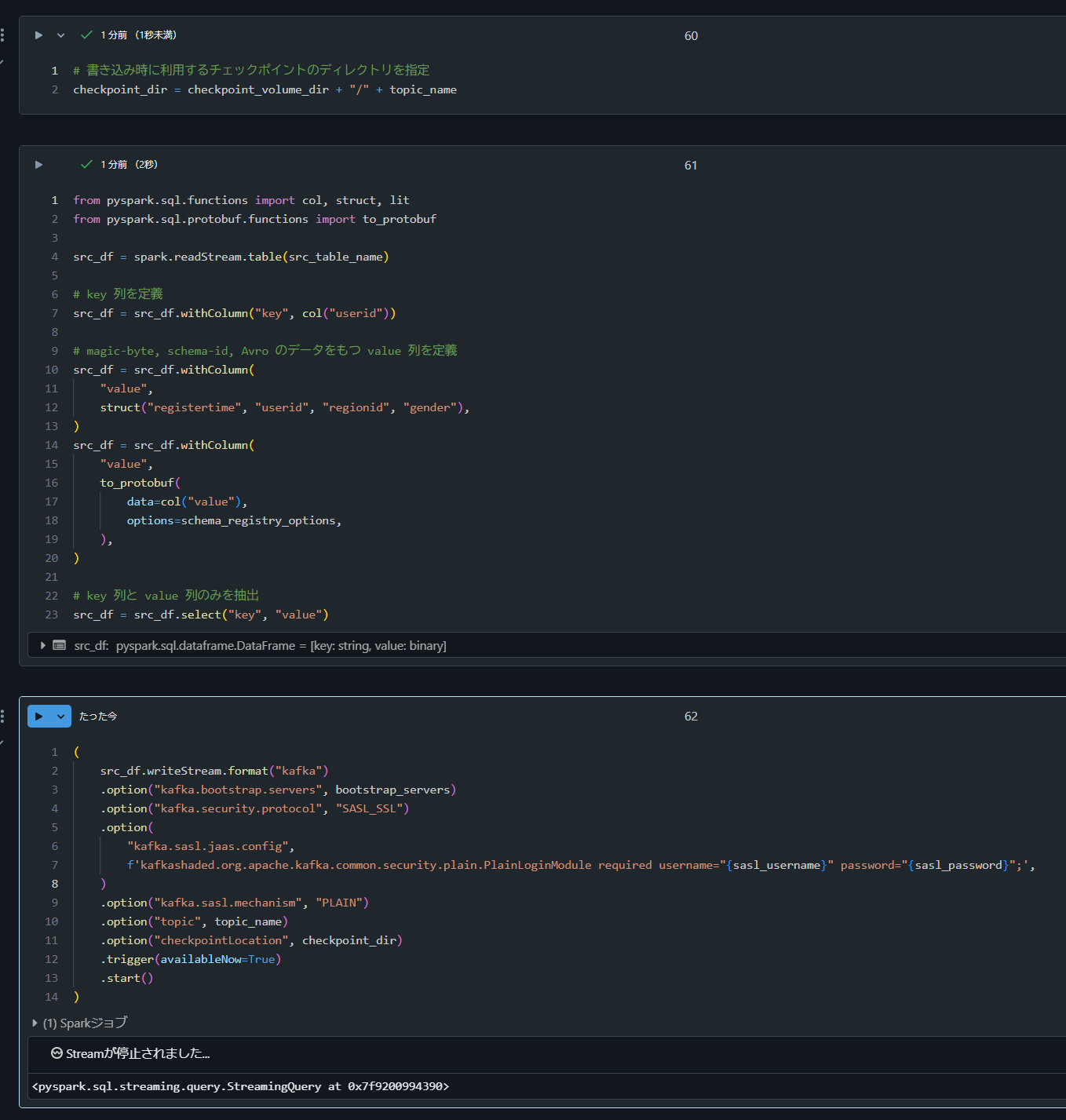
# 書き込み時に利用するチェックポイントのディレクトリを指定
checkpoint_dir = checkpoint_volume_dir + "/" + topic_name
from pyspark.sql.functions import col, struct, lit
from pyspark.sql.avro.functions import to_avro
src_df = spark.readStream.table(src_table_name)
# key 列を定義
src_df = src_df.withColumn("key", col("userid"))
src_df = src_df.withColumn(
"value",
struct("registertime", "userid", "regionid", "gender"),
)
src_df = src_df.withColumn(
"value",
to_avro(
data=col("value"),
options=schema_registry_options,
schemaRegistryAddress=sr_url,
# subject を指定するとエラーとなるためデフォルト戦略に任せる
# subject=lit(value_subject_name),
),
)
# key 列と value 列のみを抽出
src_df = src_df.select("key", "value")
(
src_df.writeStream.format("kafka")
.option("kafka.bootstrap.servers", bootstrap_servers)
.option("kafka.security.protocol", "SASL_SSL")
.option(
"kafka.sasl.jaas.config",
f'kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username="{sasl_username}" password="{sasl_password}";',
)
.option("kafka.sasl.mechanism", "PLAIN")
.option("topic", topic_name)
.option("checkpointLocation", checkpoint_dir)
.trigger(availableNow=True)
.start()
)