概要
Databricks Auto Loader にて CSV ファイルの 1 行目をスキップする方法を共有します。!dataのような謎の文字が 1 行目にあり、2 行目から実際の CSV 形式のデータがはじまるファイルをインタフェースしたことがありました。本記事では、そういったファイルを Databricks Auto Loader にて取り込む方法を紹介します。
Databricks Auto Loader の CSV オプションにおけるskipRowsを指定することで、!dataの行をスキップできます。

引用元:Auto Loaderのオプション | Databricks on AWS
事前準備
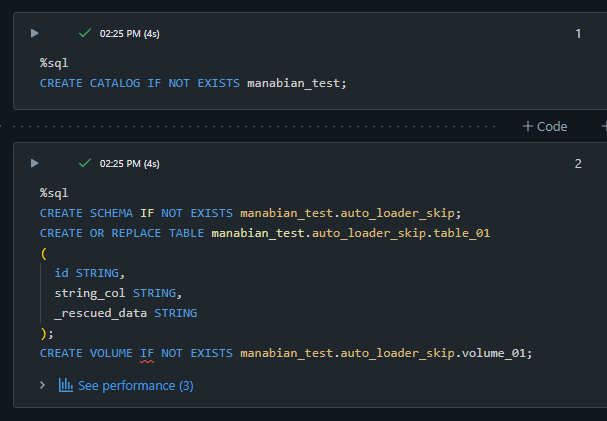
カタログ、スキーマ、テーブル、及び、 Volume の作成
%sql
CREATE CATALOG IF NOT EXISTS manabian_test;
%sql
CREATE SCHEMA IF NOT EXISTS manabian_test.auto_loader_skip;
CREATE OR REPLACE TABLE manabian_test.auto_loader_skip.table_01
(
id STRING,
string_col STRING,
_rescued_data STRING
);
CREATE VOLUME IF NOT EXISTS manabian_test.auto_loader_skip.volume_01;
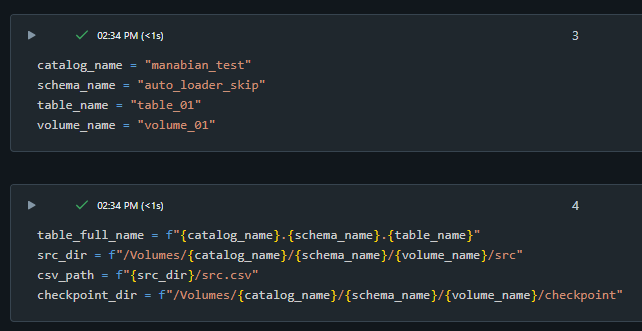
変数を定義
catalog_name = "manabian_test"
schema_name = "auto_loader_skip"
table_name = "table_01"
volume_name = "volume_01"
table_full_name = f"{catalog_name}.{schema_name}.{table_name}"
src_dir = f"/Volumes/{catalog_name}/{schema_name}/{volume_name}/src"
csv_path = f"{src_dir}/src.csv"
checkpoint_dir = f"/Volumes/{catalog_name}/{schema_name}/{volume_name}/checkpoint"
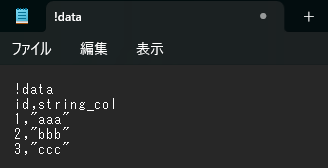
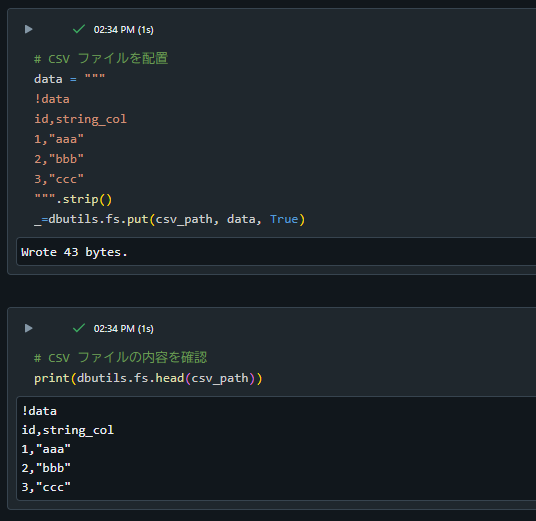
CSV ファイルを配置
# CSV ファイルを配置
data = """
!data
id,string_col
1,"aaa"
2,"bbb"
3,"ccc"
""".strip()
_=dbutils.fs.put(csv_path, data, True)
# CSV ファイルの内容を確認
print(dbutils.fs.head(csv_path))
検証用コードとその結果
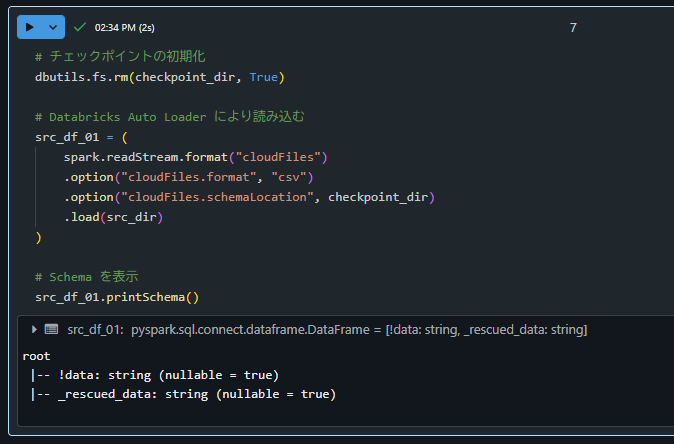
1. skipRowを指定しない場合の動作確認
!dataをカラム名として参照しており想定外の動作となっていることを確認。
# チェックポイントの初期化
dbutils.fs.rm(checkpoint_dir, True)
# Databricks Auto Loader により読み込む
src_df_01 = (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "csv")
.option("cloudFiles.schemaLocation", checkpoint_dir)
.load(src_dir)
)
# Schema を表示
src_df_01.printSchema()
root
|-- !data: string (nullable = true)
|-- _rescued_data: string (nullable = true)
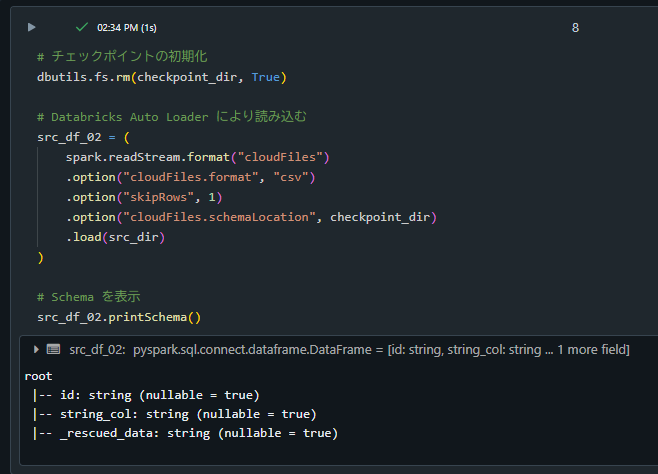
2. skipRowを指定した場合の動作確認
データフレームのカラムが想定通りとなっていることを確認。
# チェックポイントの初期化
dbutils.fs.rm(checkpoint_dir, True)
# Databricks Auto Loader により読み込む
src_df_02 = (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "csv")
.option("skipRows", 1)
.option("cloudFiles.schemaLocation", checkpoint_dir)
.load(src_dir)
)
# Schema を表示
src_df_02.printSchema()
root
|-- id: string (nullable = true)
|-- string_col: string (nullable = true)
|-- _rescued_data: string (nullable = true)
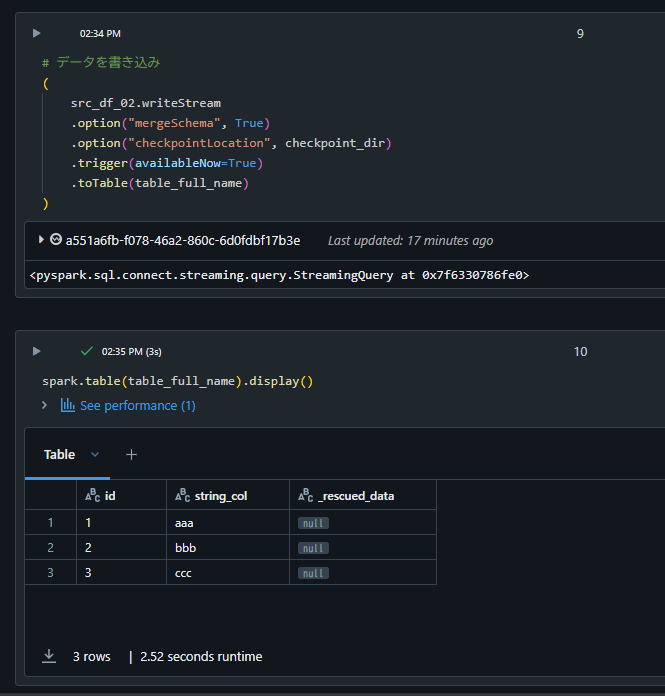
テーブルに対して書き込み、想定通りにテーブルに書き込まれていることを確認。
# データの書き込み
(
src_df_02.writeStream
.option("mergeSchema", True)
.option("checkpointLocation", checkpoint_dir)
.trigger(availableNow=True)
.toTable(table_full_name)
)
spark.table(table_full_name).display()
事後処理
カタログの削除
%sql
DROP CATALOG IF EXISTS manabian_test CASCADE;