概要
Databricks の Delta Live Table (DLT)にて変更データ キャプチャ (CDC) を SCD TYPE 2 として実行した際に Timestamp 型のカラムで履歴管理が可能です。DLT では APPLY CHANGES API で SCD TYPE 2 でのデータ連携が可能なのですが、int 型でしか履歴管理できないのではないかと勘違いしていました。実際には、 APPLY CHANGES API 実行時のsequence_byパラメータで指定したデータ型となるようです。
勘違いしていた背景としては、下記のドキュメントにて__START_AT列と__END_AT列が INT 型となっていたことです。
下記データの Timestamp 型の列(update_timestamp列)をsequence_byパラメータで指定したところ、 Timestamp 型での履歴管理も実施できることを確認できました。本記事では、INT 型と Timestamp 型の2つのカラムで、 SCD TYPE 2 の処理を実施する手順を紹介します。
検証コードと実行結果
事前準備
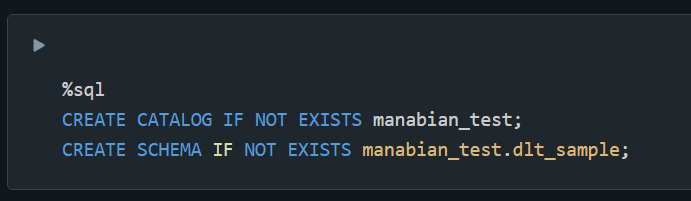
1. カタログとスキーマを作成
%sql
CREATE CATALOG IF NOT EXISTS manabian_test;
CREATE SCHEMA IF NOT EXISTS manabian_test.dlt_sample;
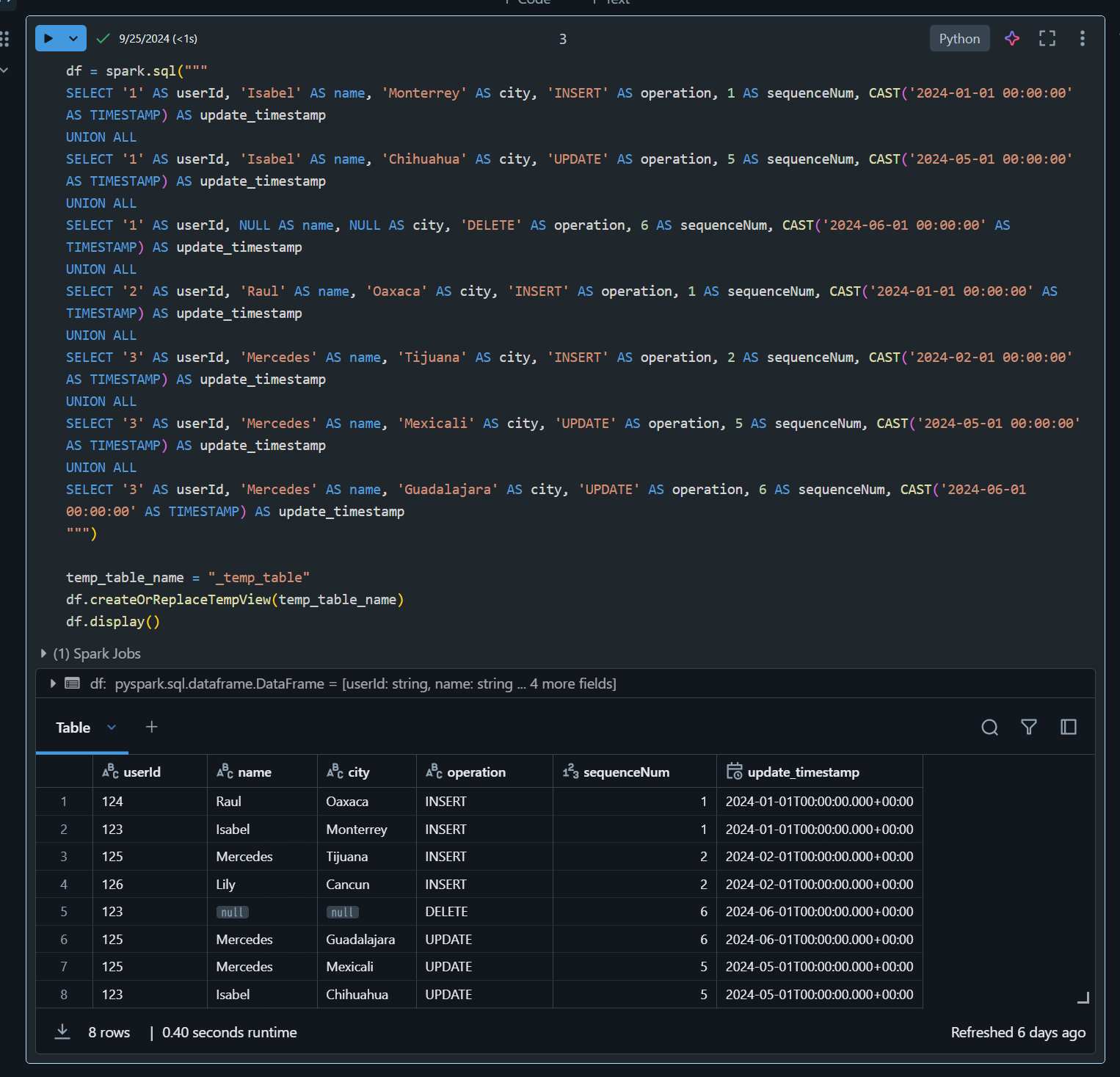
2. ソーステーブルの作成
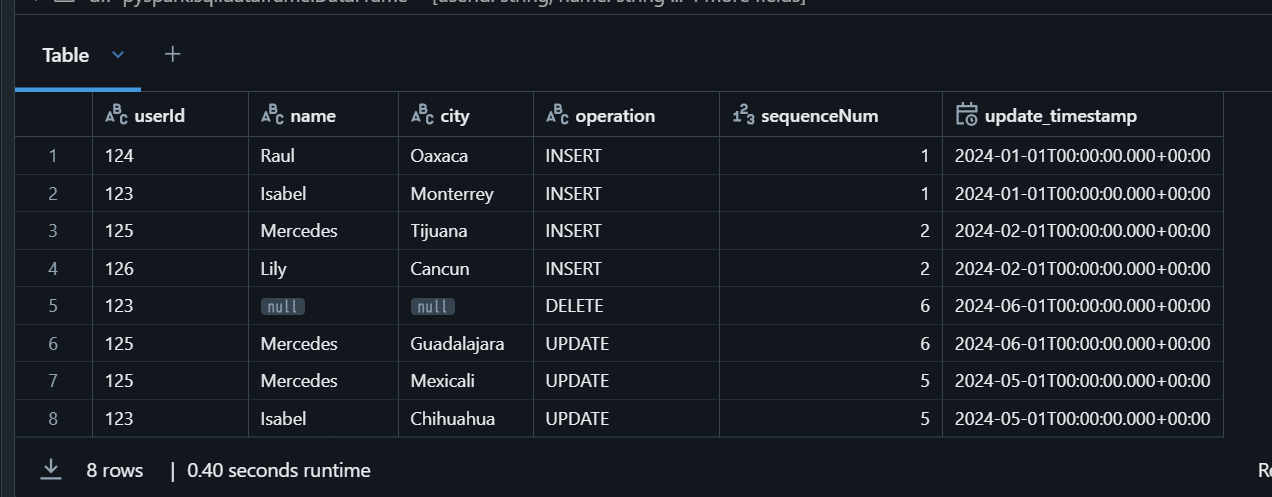
df = spark.sql("""
SELECT '1' AS userId, 'Isabel' AS name, 'Monterrey' AS city, 'INSERT' AS operation, 1 AS sequenceNum, CAST('2024-01-01 00:00:00' AS TIMESTAMP) AS update_timestamp
UNION ALL
SELECT '1' AS userId, 'Isabel' AS name, 'Chihuahua' AS city, 'UPDATE' AS operation, 5 AS sequenceNum, CAST('2024-05-01 00:00:00' AS TIMESTAMP) AS update_timestamp
UNION ALL
SELECT '1' AS userId, NULL AS name, NULL AS city, 'DELETE' AS operation, 6 AS sequenceNum, CAST('2024-06-01 00:00:00' AS TIMESTAMP) AS update_timestamp
UNION ALL
SELECT '2' AS userId, 'Raul' AS name, 'Oaxaca' AS city, 'INSERT' AS operation, 1 AS sequenceNum, CAST('2024-01-01 00:00:00' AS TIMESTAMP) AS update_timestamp
UNION ALL
SELECT '3' AS userId, 'Mercedes' AS name, 'Tijuana' AS city, 'INSERT' AS operation, 2 AS sequenceNum, CAST('2024-02-01 00:00:00' AS TIMESTAMP) AS update_timestamp
UNION ALL
SELECT '3' AS userId, 'Mercedes' AS name, 'Mexicali' AS city, 'UPDATE' AS operation, 5 AS sequenceNum, CAST('2024-05-01 00:00:00' AS TIMESTAMP) AS update_timestamp
UNION ALL
SELECT '3' AS userId, 'Mercedes' AS name, 'Guadalajara' AS city, 'UPDATE' AS operation, 6 AS sequenceNum, CAST('2024-06-01 00:00:00' AS TIMESTAMP) AS update_timestamp
""")
temp_table_name = "_temp_table"
df.createOrReplaceTempView(temp_table_name)
df.display()
%sql
CREATE OR REPLACE TABLE manabian_test.dlt_sample.source_table_01
AS
SELECT
*
FROM
_temp_table
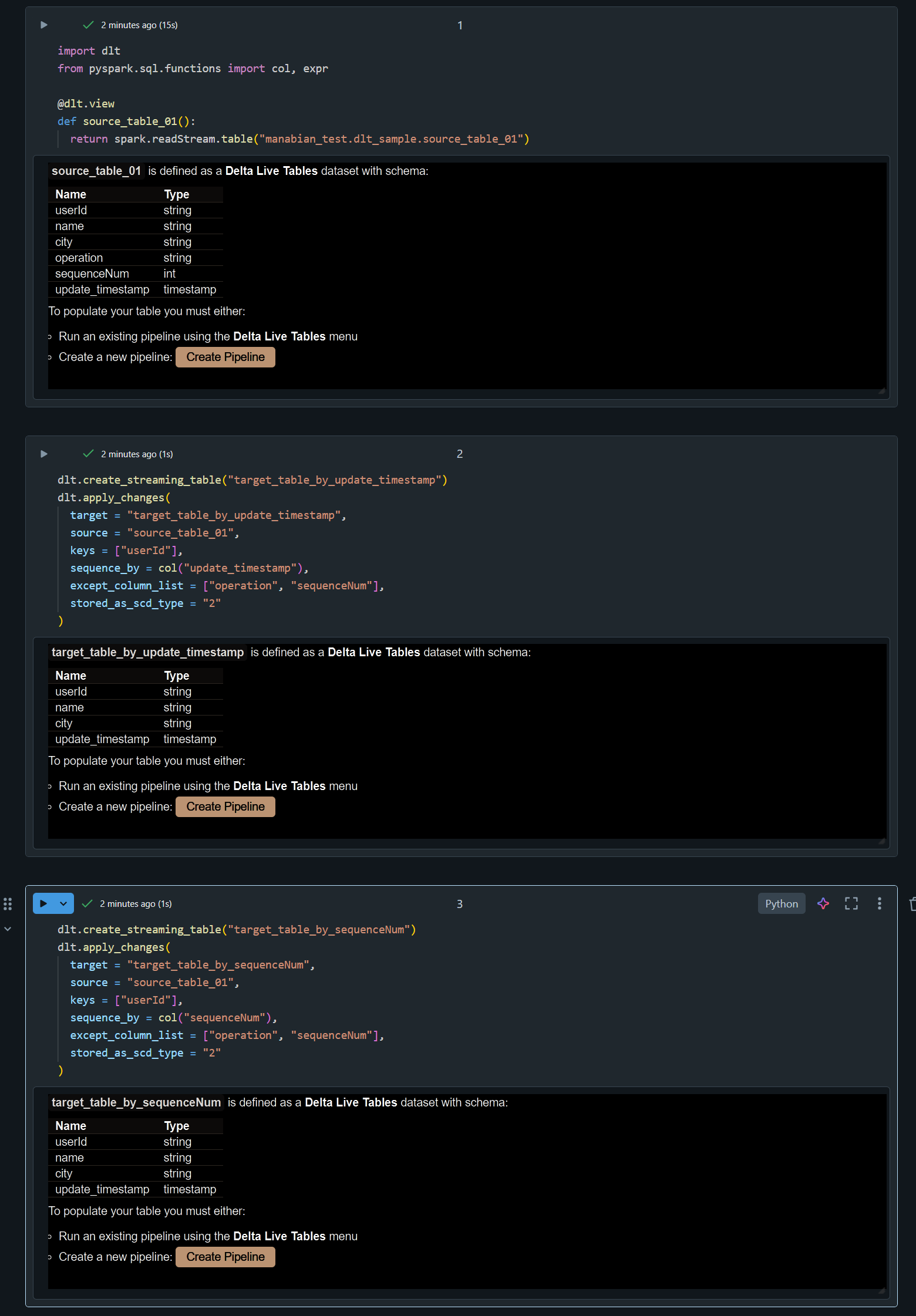
DLT によるデータ実行
1. DLT のコードを記述
import dlt
from pyspark.sql.functions import col, expr
@dlt.view
def source_table_01():
return spark.readStream.table("manabian_test.dlt_sample.source_table_01")
dlt.create_streaming_table("target_table_by_update_timestamp")
dlt.apply_changes(
target = "target_table_by_update_timestamp",
source = "source_table_01",
keys = ["userId"],
sequence_by = col("update_timestamp"),
except_column_list = ["operation", "sequenceNum"],
stored_as_scd_type = "2"
)
dlt.create_streaming_table("target_table_by_sequenceNum")
dlt.apply_changes(
target = "target_table_by_sequenceNum",
source = "source_table_01",
keys = ["userId"],
sequence_by = col("sequenceNum"),
except_column_list = ["operation", "sequenceNum"],
stored_as_scd_type = "2"
)
2. DLT を実行
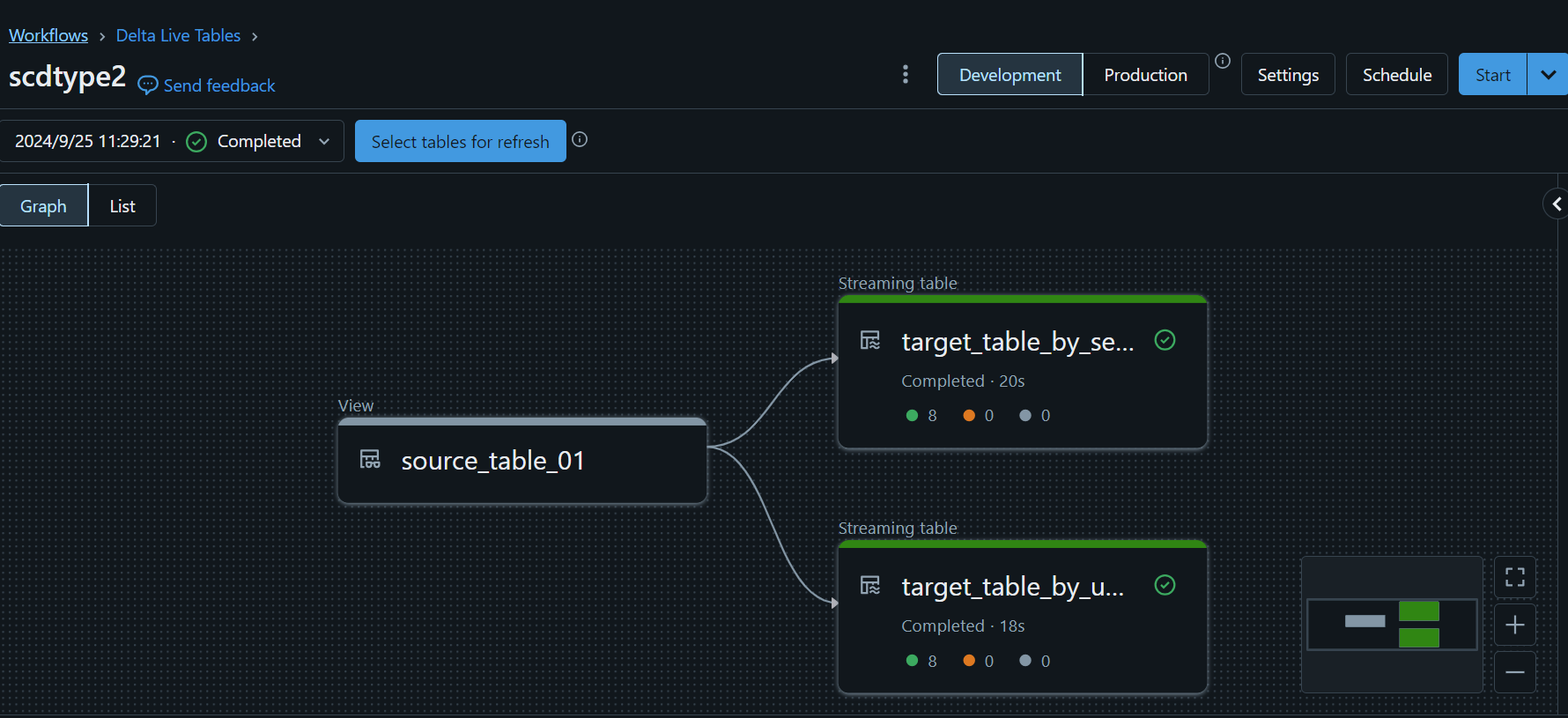
処理結果の確認
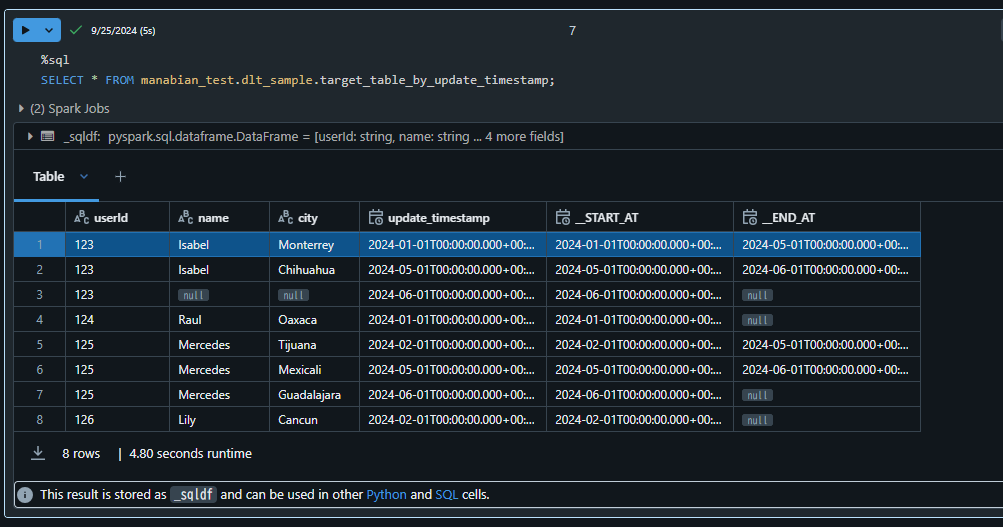
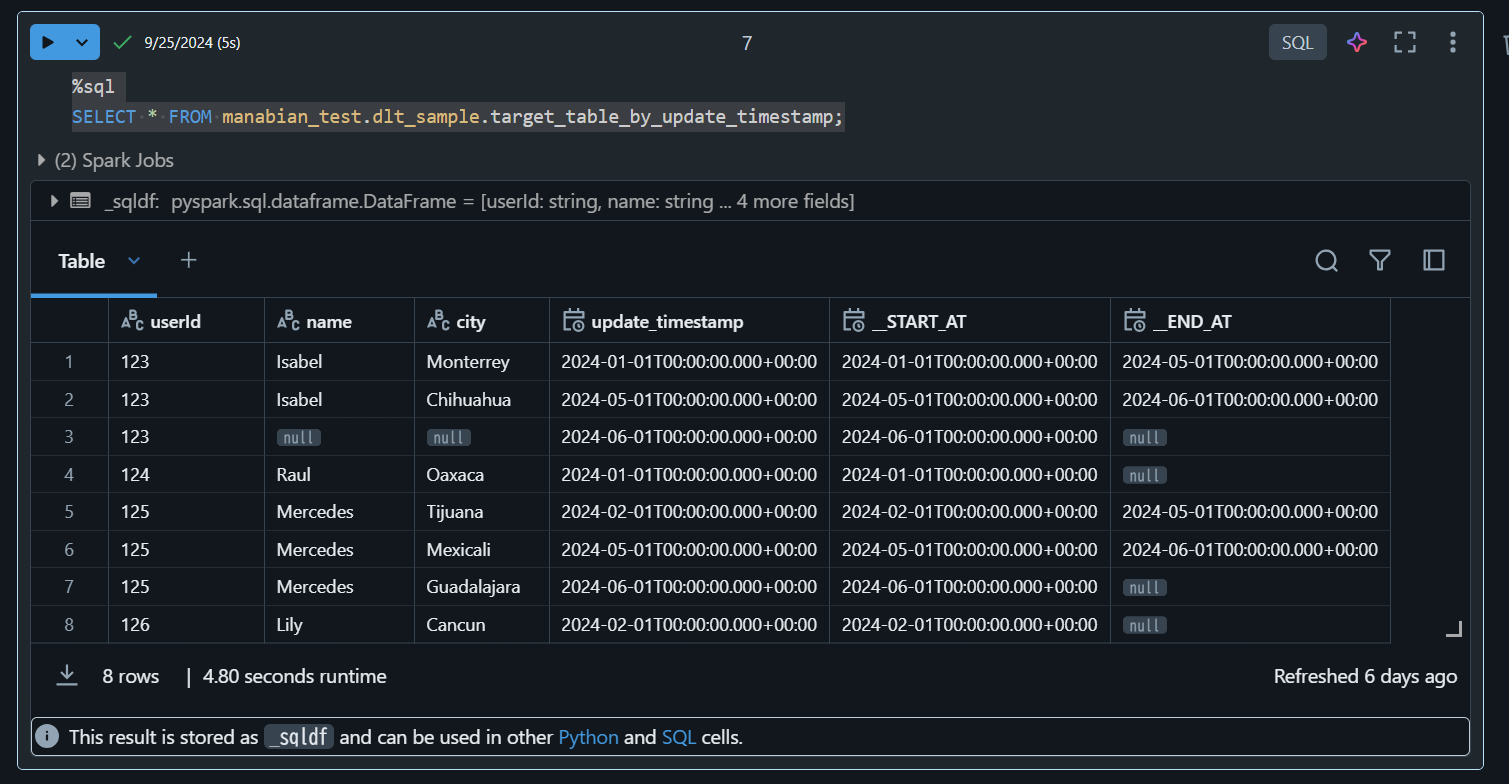
1. Timestamp 型のカラム(update_timestamp列)を sequence_byパラメータで指定した場合の処理結果
%sql
SELECT * FROM manabian_test.dlt_sample.target_table_by_update_timestamp;
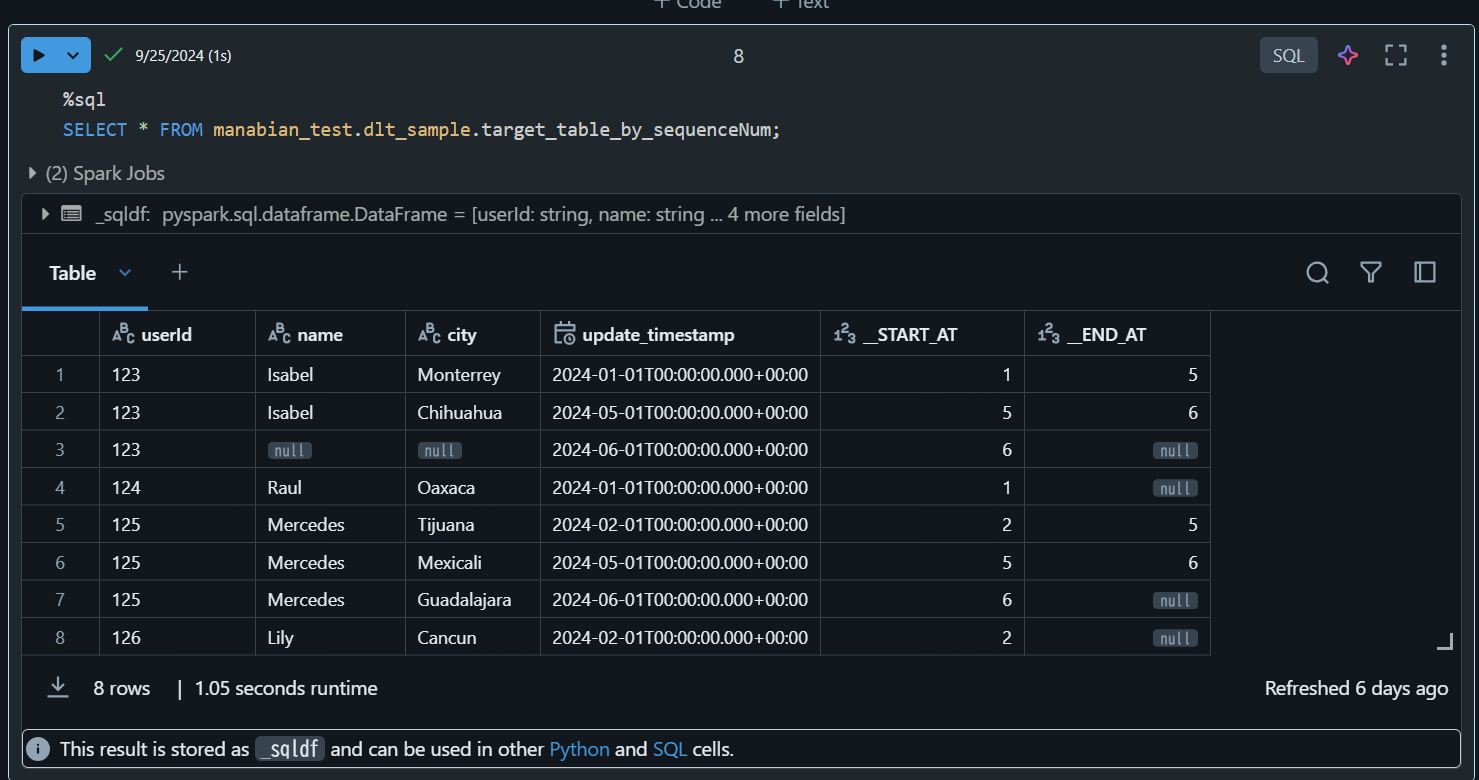
2. INT 型のカラム(sequenceNum列)を sequence_byパラメータで指定した場合の処理結果
%sql
SELECT * FROM manabian_test.dlt_sample.target_table_by_sequenceNum;