概要
データエンジニアリングのプログラム開発を行う際にテスト用ファイルをソースとすることがよくありますが、COPY INTO により開発する際には同一ファイル名が取り込まれないことに注意が必要です。Delta Lake 形式のテーブルのディレクトリにて取り込み済みファイル一覧の情報が管理されているようで、ディレクトリの初期化が必要となるようです。この仕様を知らずに開発を行うと、処理が完了しているにも関わらず、データが想定通りに取り込まれないと勘違いしてしまいます。
COPY INTO では、ドキュメントに記載のある通り、ソースとなるファイルを取り込むことを一度だけ実行されることが保証されています。

引用元:COPY INTO を使用してデータを読み込む - Azure Databricks | Microsoft Learn
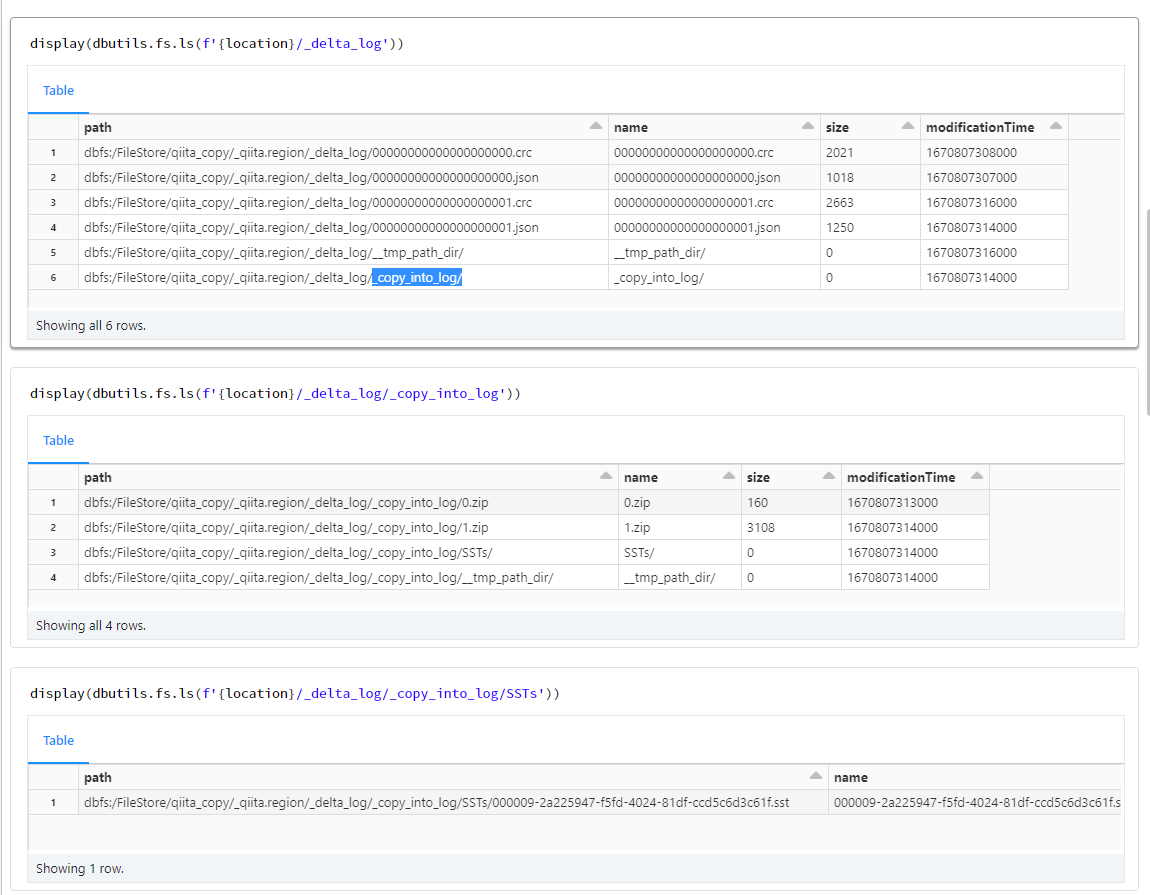
COPY INTO を実行すると、_delta_log 配下に _copy_into_logというディレクトリが作成され、そこで取り込み済みファイルの一覧を管理しているようです。sstという拡張子のファイルがあるため、推測ですが、処理時には RocksDB で管理されていそうです。
COPY INTO にて、取り込み済みファイルでも取り込むためのオプションとしてCOPY_OPTIONSにforceというオプションがありますが、開発時にのみ true にすることは現実的ではないです。

引用元:COPY INTO (Databricks SQL) - Azure Databricks - Databricks SQL | Microsoft Learn
下記の方法ではCOPY INTOによりデータが再取り込みされなかったため、ディレクトリの初期化(マネージドテーブルの場合には DROP TABLE)が必要になるようです。
- DELETE
- TRUNCATE
- CREATE OR REPLACE
- DROP TABLE(外部テーブルであることが前提)
検証
事前準備
db_name = '_qiita'
tbl_name = f'{db_name}.region'
tbl_path = f'dbfs:/FileStore/qiita_copy/{tbl_name}'
file_path = "dbfs:/databricks-datasets/tpch/data-001/region/region.tbl"
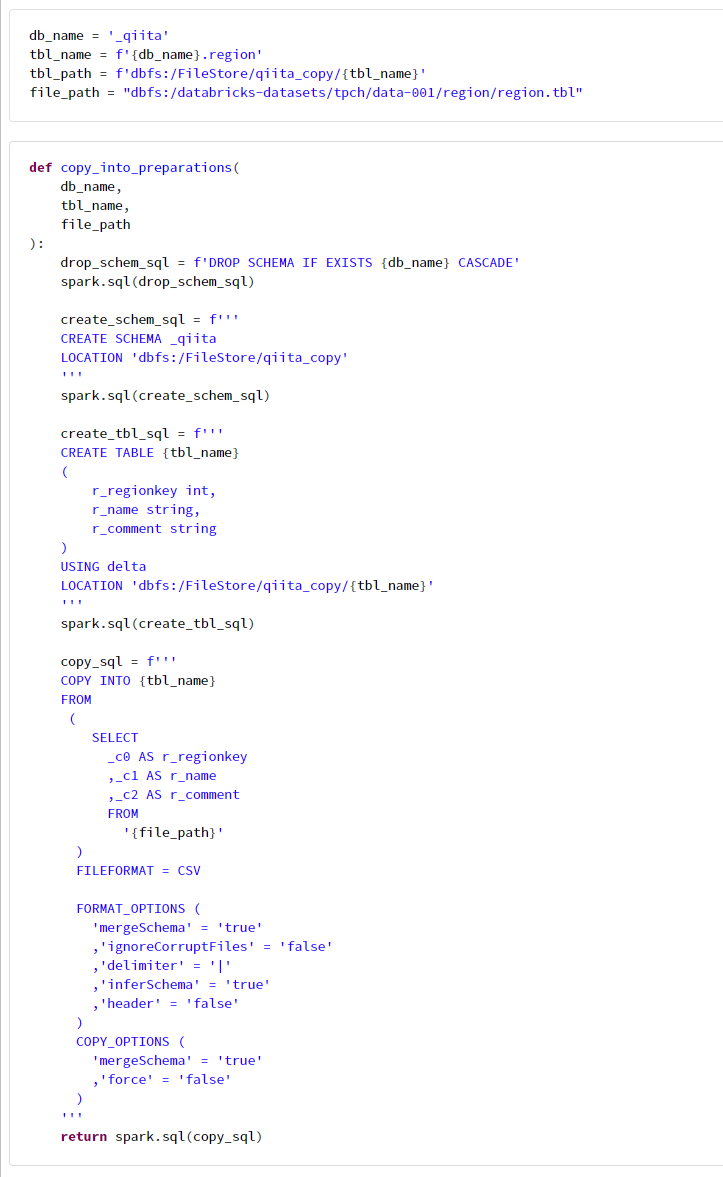
def copy_into_preparations(
db_name,
tbl_name,
file_path
):
drop_schem_sql = f'DROP SCHEMA IF EXISTS {db_name} CASCADE'
spark.sql(drop_schem_sql)
create_schem_sql = f'''
CREATE SCHEMA _qiita
LOCATION 'dbfs:/FileStore/qiita_copy'
'''
spark.sql(create_schem_sql)
create_tbl_sql = f'''
CREATE TABLE {tbl_name}
(
r_regionkey int,
r_name string,
r_comment string
)
USING delta
LOCATION 'dbfs:/FileStore/qiita_copy/{tbl_name}'
'''
spark.sql(create_tbl_sql)
copy_sql = f'''
COPY INTO {tbl_name}
FROM
(
SELECT
_c0 AS r_regionkey
,_c1 AS r_name
,_c2 AS r_comment
FROM
'{file_path}'
)
FILEFORMAT = CSV
FORMAT_OPTIONS (
'mergeSchema' = 'true'
,'ignoreCorruptFiles' = 'false'
,'delimiter' = '|'
,'inferSchema' = 'true'
,'header' = 'false'
)
COPY_OPTIONS (
'mergeSchema' = 'true'
,'force' = 'false'
)
'''
return spark.sql(copy_sql)
copy_into_preparations(
db_name,
tbl_name,
file_path
)
df = spark.table(tbl_name)
df.display()

# 2回目の実行
copy_sql = f'''
COPY INTO {tbl_name}
FROM
(
SELECT
_c0 AS r_regionkey
,_c1 AS r_name
,_c2 AS r_comment
FROM
'{file_path}'
)
FILEFORMAT = CSV
FORMAT_OPTIONS (
'mergeSchema' = 'true'
,'ignoreCorruptFiles' = 'false'
,'delimiter' = '|'
,'inferSchema' = 'true'
,'header' = 'false'
)
COPY_OPTIONS (
'mergeSchema' = 'true'
,'force' = 'false'
)
# 5 件でかわらないことを確認
df= spark.table(tbl_name)
df.display()
'''
spark.sql(copy_sql)

ディレクトリを確認
# Delta Lake のディレクトリパスを取得
location = spark.sql(f"desc extended {tbl_name}").filter("col_name='Location'").select('data_type').first()[0]
print(location)
display(dbutils.fs.ls(f'{location}/_delta_log'))
Table

display(dbutils.fs.ls(f'{location}/_delta_log/_copy_into_log'))
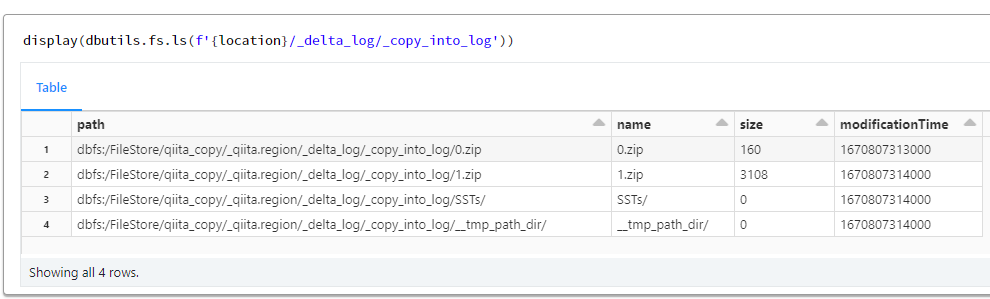
display(dbutils.fs.ls(f'{location}/_delta_log/_copy_into_log/SSTs'))

# sst ファイル名を取得
sst_file_name = dbutils.fs.ls(f'{location}/_delta_log/_copy_into_log/SSTs')[0].name
print(dbutils.fs.head(f'{location}/_delta_log/_copy_into_log/SSTs/{sst_file_name}'))

ディレクトリを初期化した場合の検証
copy_into_preparations(
db_name,
tbl_name,
file_path
)
spark.table(tbl_name).display()
# Delta Lake のディレクトリパスを取得
location = spark.sql(f"desc extended {tbl_name}").filter("col_name='Location'").select('data_type').first()[0]
dbutils.fs.rm(location, True)
drop_tbl_sql = f'''
DROP TABLE {tbl_name}
'''
spark.sql(drop_tbl_sql)
create_or_replace_tbl_sql = f'''
CREATE TABLE {tbl_name}
(
r_regionkey int,
r_name string,
r_comment string
)
USING delta
LOCATION '{tbl_path}'
'''
spark.sql(create_or_replace_tbl_sql)
spark.table(tbl_name).display()

copy_sql = f'''
COPY INTO {tbl_name}
FROM
(
SELECT
_c0 AS r_regionkey
,_c1 AS r_name
,_c2 AS r_comment
FROM
'{file_path}'
)
FILEFORMAT = CSV
FORMAT_OPTIONS (
'mergeSchema' = 'true'
,'ignoreCorruptFiles' = 'false'
,'delimiter' = '|'
,'inferSchema' = 'true'
,'header' = 'false'
)
COPY_OPTIONS (
'mergeSchema' = 'true'
,'force' = 'false'
)
'''
spark.sql(copy_sql)
df = spark.table(tbl_name)
df.display()

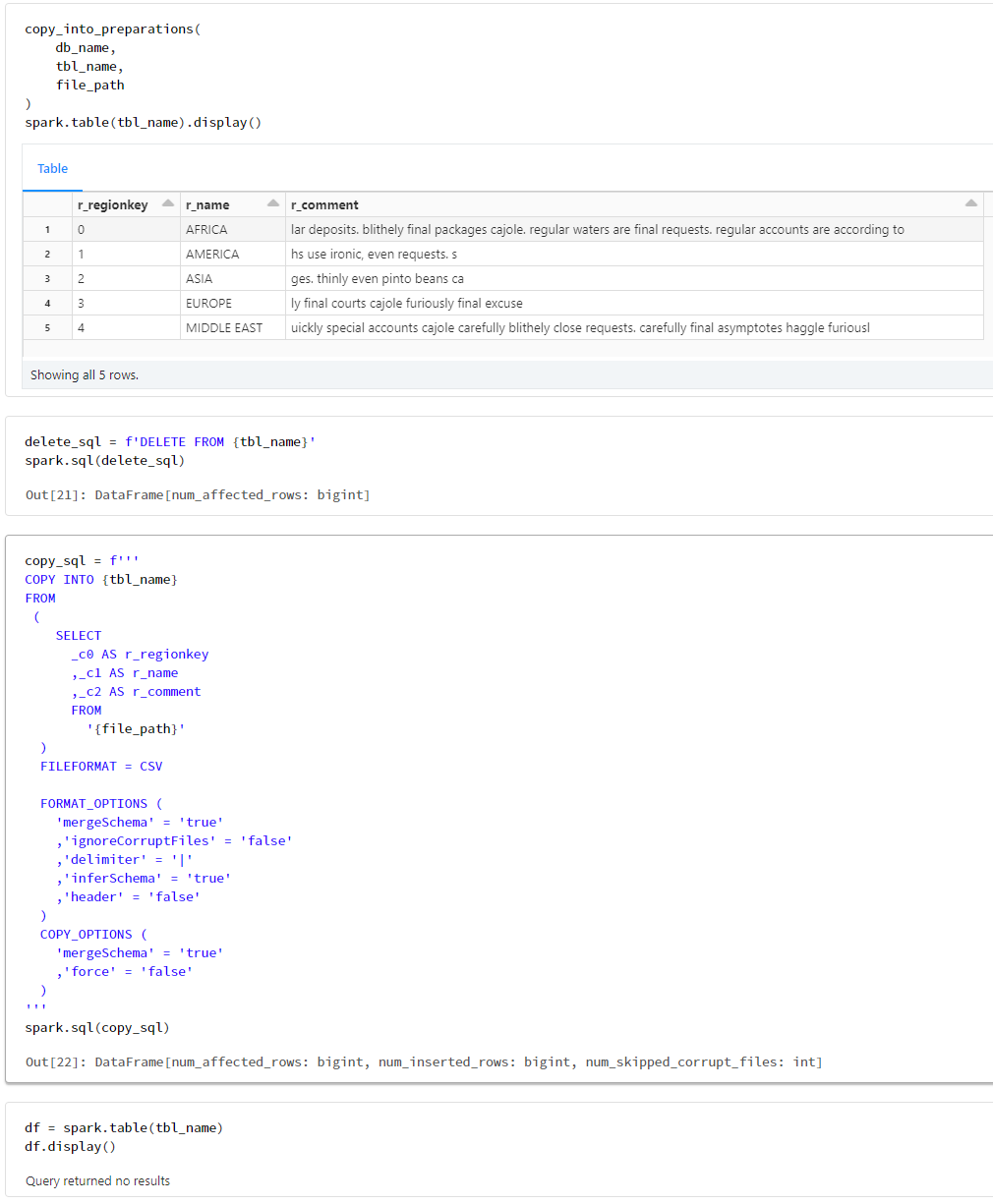
DELETEした場合の検証
copy_into_preparations(
db_name,
tbl_name,
file_path
)
spark.table(tbl_name).display()
delete_sql = f'DELETE FROM {tbl_name}'
spark.sql(delete_sql)
copy_sql = f'''
COPY INTO {tbl_name}
FROM
(
SELECT
_c0 AS r_regionkey
,_c1 AS r_name
,_c2 AS r_comment
FROM
'{file_path}'
)
FILEFORMAT = CSV
FORMAT_OPTIONS (
'mergeSchema' = 'true'
,'ignoreCorruptFiles' = 'false'
,'delimiter' = '|'
,'inferSchema' = 'true'
,'header' = 'false'
)
COPY_OPTIONS (
'mergeSchema' = 'true'
,'force' = 'false'
)
'''
spark.sql(copy_sql)
df = spark.table(tbl_name)
df.display()
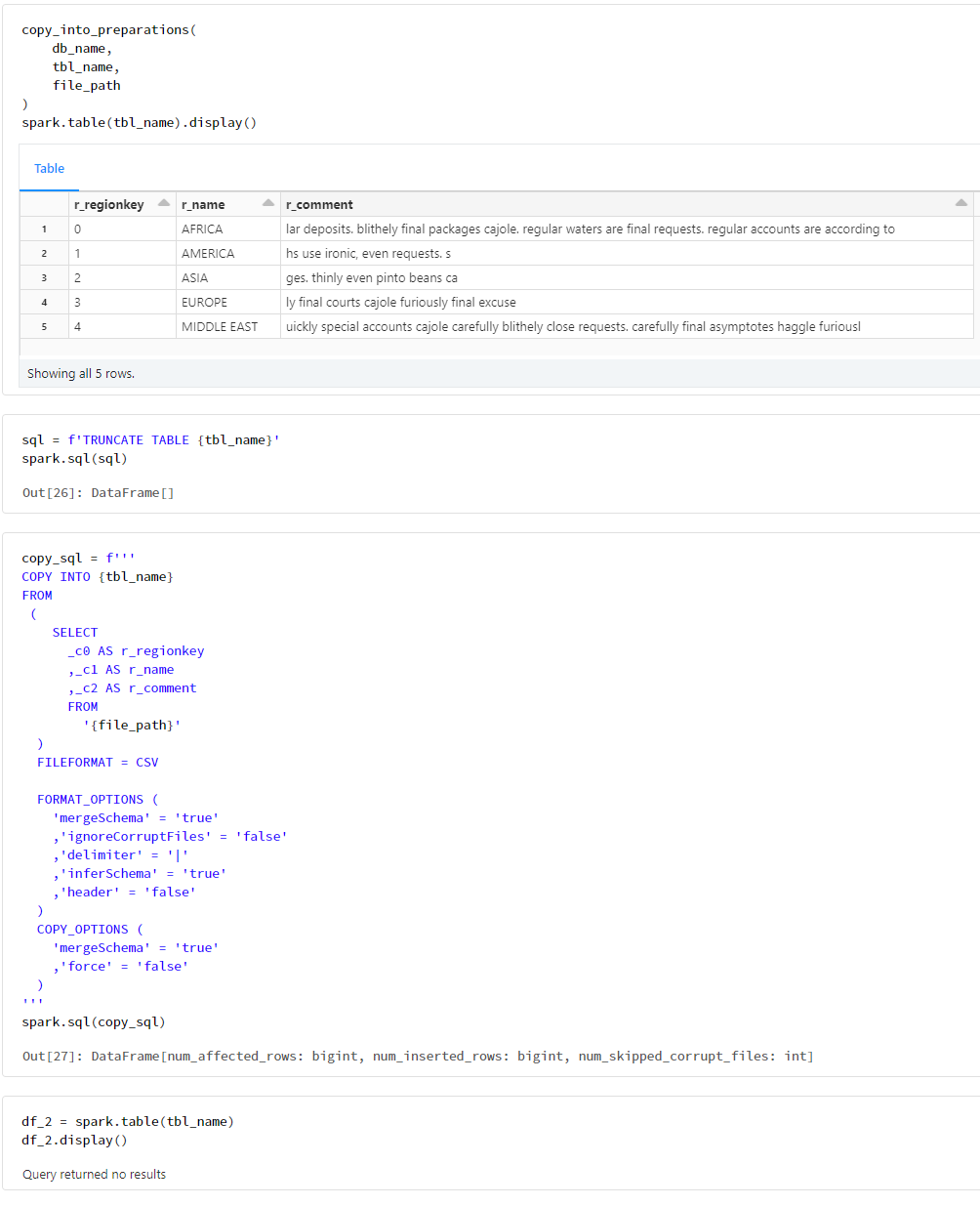
TRUNCATEした場合の検証
copy_into_preparations(
db_name,
tbl_name,
file_path
)
spark.table(tbl_name).display()
sql = f'TRUNCATE TABLE {tbl_name}'
spark.sql(sql)
copy_sql = f'''
COPY INTO {tbl_name}
FROM
(
SELECT
_c0 AS r_regionkey
,_c1 AS r_name
,_c2 AS r_comment
FROM
'{file_path}'
)
FILEFORMAT = CSV
FORMAT_OPTIONS (
'mergeSchema' = 'true'
,'ignoreCorruptFiles' = 'false'
,'delimiter' = '|'
,'inferSchema' = 'true'
,'header' = 'false'
)
COPY_OPTIONS (
'mergeSchema' = 'true'
,'force' = 'false'
)
'''
spark.sql(copy_sql)
df_2 = spark.table(tbl_name)
df_2.display()
CREATE OR REPLACEした場合の検証
copy_into_preparations(
db_name,
tbl_name,
file_path
)
spark.table(tbl_name).display()
create_or_replace_tbl_sql = f'''
CREATE OR REPLACE TABLE {tbl_name}
(
r_regionkey int,
r_name string,
r_comment string
)
USING delta
'''
spark.sql(create_or_replace_tbl_sql)
copy_sql = f'''
COPY INTO {tbl_name}
FROM
(
SELECT
_c0 AS r_regionkey
,_c1 AS r_name
,_c2 AS r_comment
FROM
'{file_path}'
)
FILEFORMAT = CSV
FORMAT_OPTIONS (
'mergeSchema' = 'true'
,'ignoreCorruptFiles' = 'false'
,'delimiter' = '|'
,'inferSchema' = 'true'
,'header' = 'false'
)
COPY_OPTIONS (
'mergeSchema' = 'true'
,'force' = 'false'
)
'''
spark.sql(copy_sql)
df_2 = spark.table(tbl_name)
df_2.display()

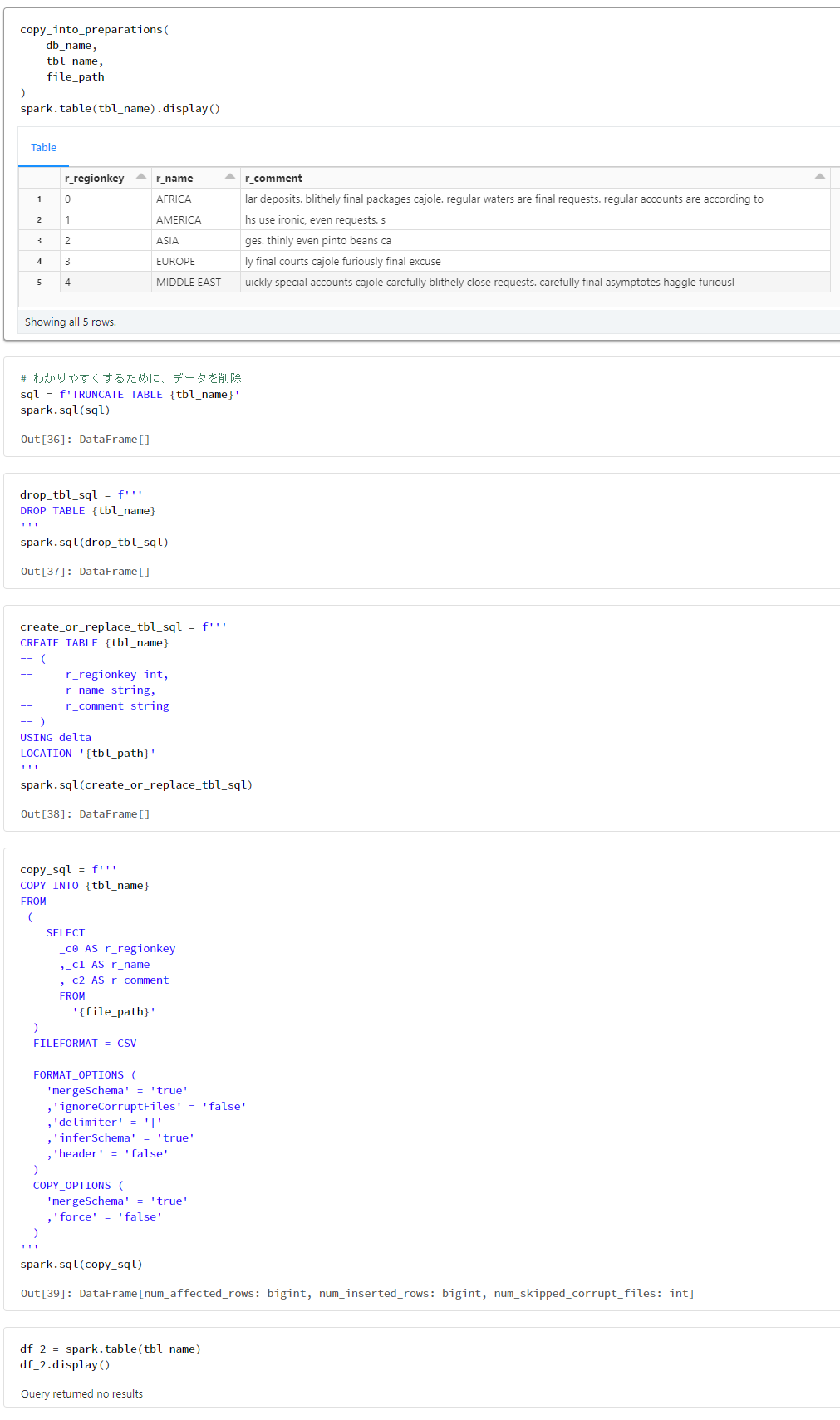
外部テーブルをDROP TABLEした場合の検証
copy_into_preparations(
db_name,
tbl_name,
file_path
)
spark.table(tbl_name).display()
# わかりやすくするために、データを削除
sql = f'TRUNCATE TABLE {tbl_name}'
spark.sql(sql)
drop_tbl_sql = f'''
DROP TABLE {tbl_name}
'''
spark.sql(drop_tbl_sql)
create_or_replace_tbl_sql = f'''
CREATE TABLE {tbl_name}
-- (
-- r_regionkey int,
-- r_name string,
-- r_comment string
-- )
USING delta
LOCATION '{tbl_path}'
'''
spark.sql(create_or_replace_tbl_sql)
copy_sql = f'''
COPY INTO {tbl_name}
FROM
(
SELECT
_c0 AS r_regionkey
,_c1 AS r_name
,_c2 AS r_comment
FROM
'{file_path}'
)
FILEFORMAT = CSV
FORMAT_OPTIONS (
'mergeSchema' = 'true'
,'ignoreCorruptFiles' = 'false'
,'delimiter' = '|'
,'inferSchema' = 'true'
,'header' = 'false'
)
COPY_OPTIONS (
'mergeSchema' = 'true'
,'force' = 'false'
)
'''
spark.sql(copy_sql)
df_2 = spark.table(tbl_name)
df_2.display()
COPY_OPTIONSのforceオプションの検証
copy_into_preparations(
db_name,
tbl_name,
file_path
)
spark.table(tbl_name).display()
copy_sql = f'''
COPY INTO {tbl_name}
FROM
(
SELECT
_c0 AS r_regionkey
,_c1 AS r_name
,_c2 AS r_comment
FROM
'{file_path}'
)
FILEFORMAT = CSV
FORMAT_OPTIONS (
'mergeSchema' = 'true'
,'ignoreCorruptFiles' = 'false'
,'delimiter' = '|'
,'inferSchema' = 'true'
,'header' = 'false'
)
COPY_OPTIONS (
'mergeSchema' = 'true'
,'force' = 'true'
)
'''
spark.sql(copy_sql)
# 10レコードあることを確認
df = spark.table(tbl_name)
df.display()

本手順で作成したリソースを削除
%sql
DROP SCHEMA IF EXISTS _qiita CASCADE
