概要
Confluent プラットフォーム(Apache Kafka ベース)では、メッセージの消費(Consumer)時に「コンシューマーグループ(Consumer Group)」という重要な概念が利用されます。コンシューマーグループ単位で「オフセット(Offset)」と呼ばれる処理位置が管理・保持されることで、効率的かつ耐障害性に優れたメッセージ処理が可能となっています。
本記事では、Confluent 上でコンシューマーグループを活用する際のオフセット管理方法について、基本概念から実際の確認方法までを解説します。
本記事は、以下のシリーズの一部です。

引用元:Data in Motion 実現へ:Data Streaming Platform である Confluent の全貌 #Kafka - Qiita
コンシューマーグループとオフセットの基本概念
コンシューマーグループとは
コンシューマーグループ (Consumer Group) とは、Kafka クラスター上の特定のトピックからメッセージを消費する一つ以上のコンシューマーの集合体です。
たとえば、consumer_group_A というグループ名で複数のコンシューマープロセスを稼働させれば、同一トピックから効率的にメッセージを並行処理できます。Kafka はグループ内のコンシューマー間でパーティションを自動的に割り当て、重複なくメッセージを分散して取得・処理する仕組みを提供します。
オフセットとは
オフセット (Offset) は、トピックの各パーティションにおいてメッセージが格納される際の連番インデックスです。コンシューマーがあるオフセットまで処理したことを記録することで、システム障害時やコンシューマー再起動時にも、正確な位置から処理を再開できます。
オフセット管理の実態
コンシューマーがメッセージ処理を完了した際、「オフセットコミット(Offset Commit)」を行います。このコミット情報は、内部の特殊なトピック(__consumer_offsets)に格納され、コンシューマーグループごとに管理・保持されます。こうした仕組みにより、Kafka はスケールアウトや障害復旧において柔軟かつ堅牢なメッセージ処理が実現できるのです。
Confluent 上での動作確認
事前準備
1. テスト用トピックの作成
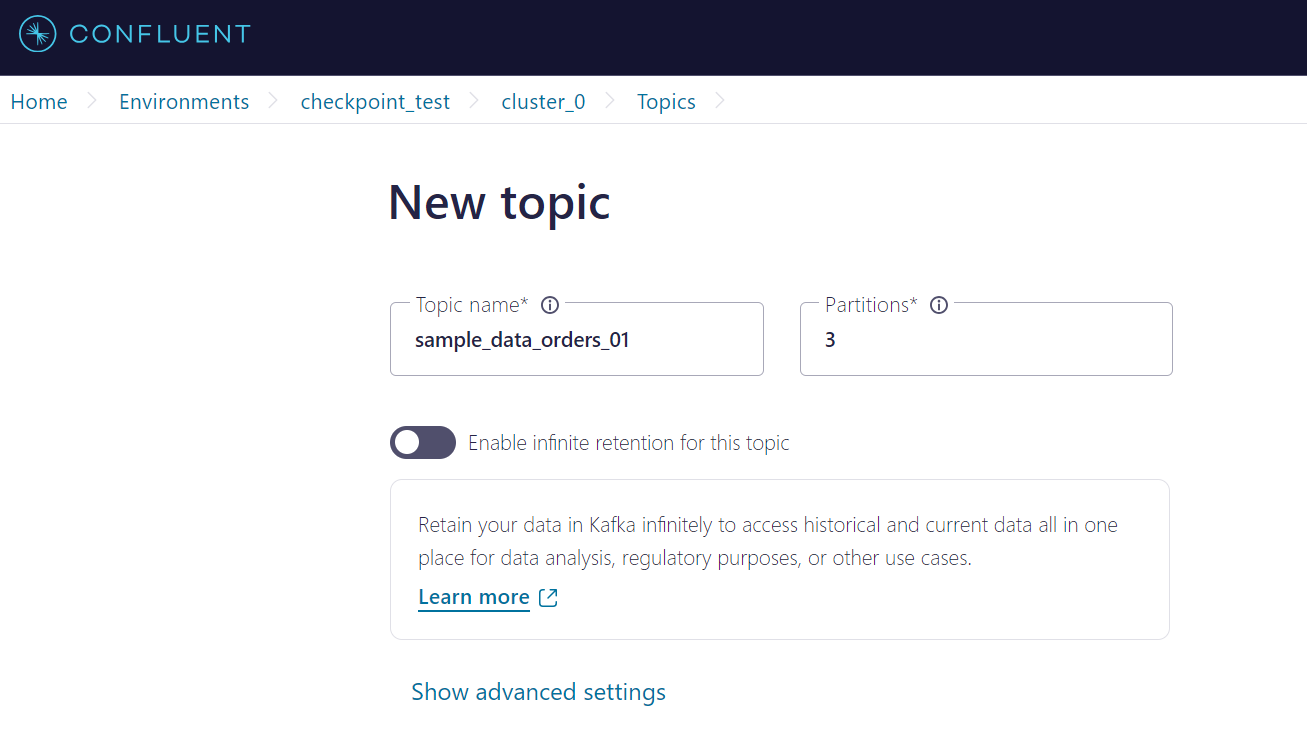
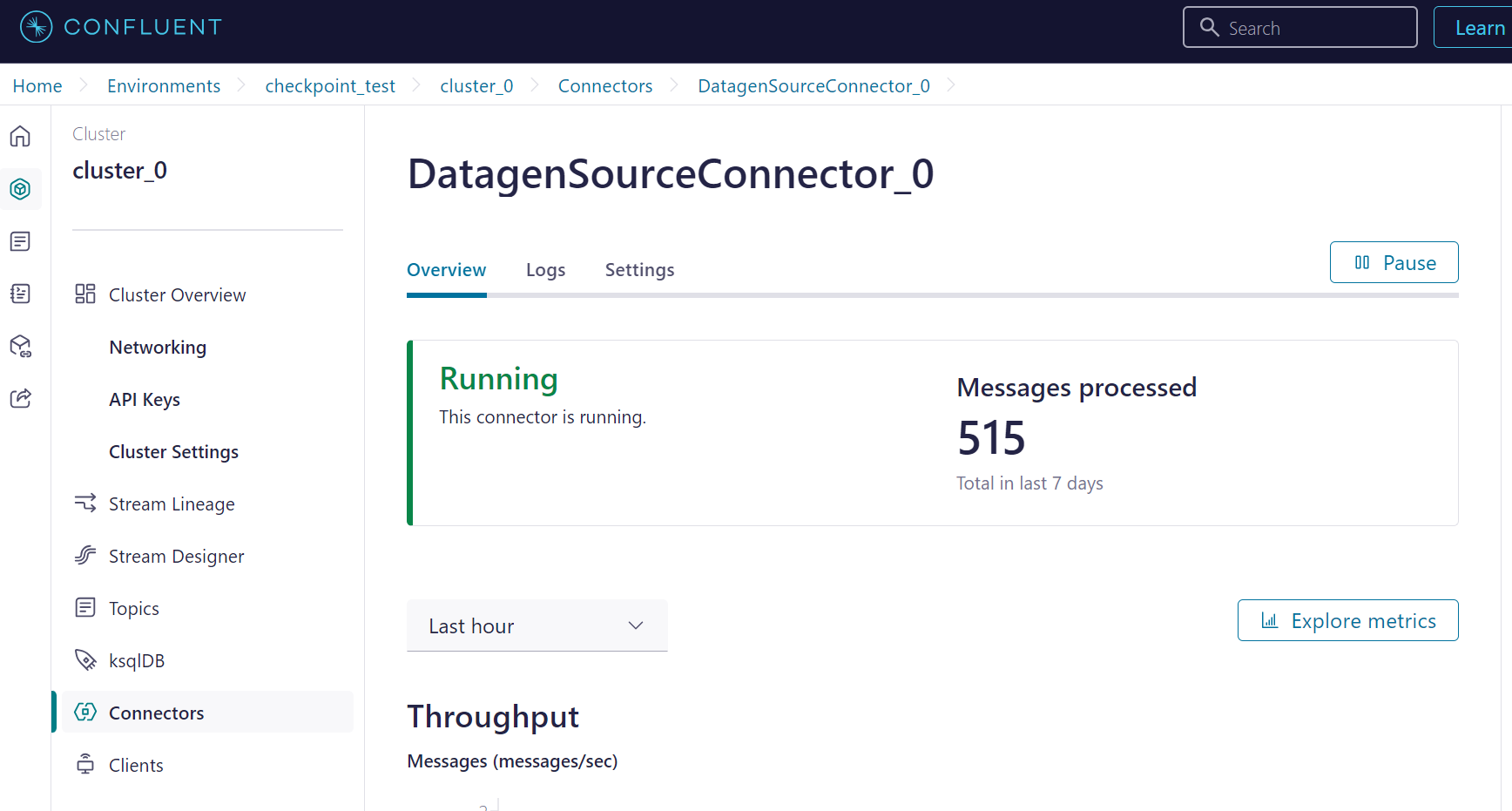
2. トピックへのデータ書き込み
Datagen Source Connector を用いて、テスト用トピックにデータを書き込みます。
3. Google Colab 上での環境準備
!pip install confluent-kafka confluent-kafka[avro,json,protobuf] -q

4. Confluent クラスターと Schema Registry の認証情報設定
# Kafka の接続情報をセット
bootstrap_servers = "pkc-921jm.us-east-2.aws.confluent.cloud:9092"
sasl_username = "Z3KRCXUFVCCFVPEF"
sasl_password = "kHz4/I/A65/FcfmnVw0L5of8YAahK5z02t31GZSnoMcGZvdE+R9NhvLOX74QUhR6"
kafka_conf = {
'bootstrap.servers': bootstrap_servers,
'sasl.username': sasl_username,
'sasl.password': sasl_password,
"security.protocol": "SASL_SSL",
"sasl.mechanisms": "PLAIN",
}
# Schema Registry 接続情報を設定
sr_url = "https://psrc-l6oz3.us-east-2.aws.confluent.cloud"
sr_api_key = "QF5SEOHC5ORP32SZ"
sr_api_secret = "xjtLFGVkKdT+Vvj0iwpvuU+maR1ptFZwAi6kyEtavdb3P7rdvLlyCTJxlUPVNfGi"
sr_conf = {
'url': sr_url,
'basic.auth.user.info': f"{sr_api_key}:{sr_api_secret}"
}

5. Consume の実行
topic_name = "sample_data_orders_01"
consumer_group_name = "consumer_group_01"
from confluent_kafka import Consumer
from confluent_kafka.serialization import SerializationContext, MessageField
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.avro import AvroDeserializer
schema_registry_client = SchemaRegistryClient(sr_conf)
consumer_conf = {
'group.id': consumer_group_name,
'auto.offset.reset': 'earliest',
'enable.auto.commit': True,
}
consumer_conf.update(kafka_conf)
consumer = Consumer(consumer_conf)
consumer.subscribe([topic_name])
avro_deserializer = AvroDeserializer(schema_registry_client)
cnt = 0
loop_num = 50
try:
for _ in range(loop_num):
msg = consumer.poll(3.0)
if msg is None:
break
if msg.error():
print("Consumer error: {}".format(msg.error()))
continue
data = avro_deserializer(msg.value(), SerializationContext(msg.topic(), MessageField.VALUE))
cnt += 1
finally:
print(f"{cnt} 回の Avro メッセージ受信終了")

パーティションごとのオフセット確認
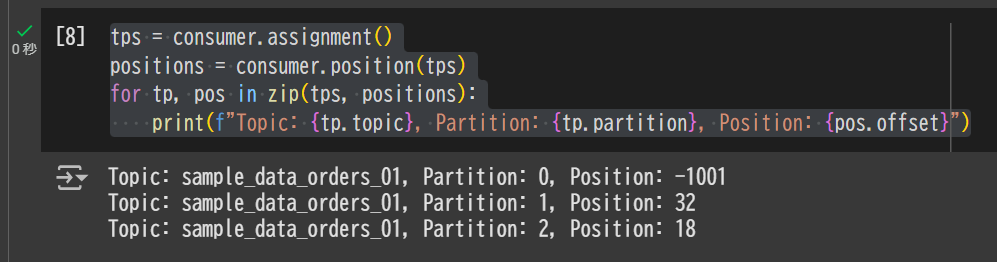
1. Consumer.position() を利用する方法
tps = consumer.assignment()
positions = consumer.position(tps)
for tp, pos in zip(tps, positions):
print(f"Topic: {tp.topic}, Partition: {tp.partition}, Position: {pos.offset}")
Topic: sample_data_orders_01, Partition: 0, Position: -1001
Topic: sample_data_orders_01, Partition: 1, Position: 32
Topic: sample_data_orders_01, Partition: 2, Position: 18
2. Consumer.committed() を利用する方法
tps = consumer.assignment()
committed_offsets = consumer.committed(tps)
for tp in committed_offsets:
print(f"Topic: {tp.topic}, Partition: {tp.partition}, Committed offset: {tp.offset}")
Topic: sample_data_orders_01, Partition: 0, Committed offset: -1001
Topic: sample_data_orders_01, Partition: 1, Committed offset: 32
Topic: sample_data_orders_01, Partition: 2, Committed offset: 18

3. AdminClient によるコンシューマーグループ単位でのオフセット取得
from confluent_kafka.admin import AdminClient
from confluent_kafka import TopicPartition, ConsumerGroupTopicPartitions, KafkaException
admin_client = AdminClient(kafka_conf)
# コンシューマーグループ一覧取得
list_groups_f = admin_client.list_consumer_groups()
groups_result = list_groups_f.result(timeout=10)
valid_groups = groups_result.valid
for group_listing in valid_groups:
group_id = group_listing.group_id
cg_offsets_futures = admin_client.list_consumer_group_offsets([ConsumerGroupTopicPartitions(group_id=group_id)])
future = cg_offsets_futures[group_id]
try:
cg_topic_partitions = future.result(timeout=10)
print(f"Consumer Group: {group_id}")
for tp in cg_topic_partitions.topic_partitions:
print(f" Topic: {tp.topic}, Partition: {tp.partition}, Offset: {tp.offset}")
except KafkaException as e:
print(f"Failed to retrieve offsets for group {group_id}: {e}")
Consumer Group: consumer_group_05
Topic: sample_data_orders_2, Partition: 1, Offset: 36
Topic: sample_data_orders_2, Partition: 0, Offset: 14
Consumer Group: consumer_group_03
Topic: sample_data_orders_1, Partition: 2, Offset: 10
Consumer Group: consumer_group_01
Topic: sample_data_orders_1, Partition: 0, Offset: 86
Topic: sample_data_orders_1, Partition: 4, Offset: 62
...

まとめ
本記事では、Confluent プラットフォーム上でコンシューマーグループ単位のオフセット管理について、基本的な概念から実際のオフセット確認方法までを示しました。
Kafka のメッセージ処理においてオフセット管理は欠かせない存在であり、これを理解することで、障害復旧やスケーリング時にもスムーズな処理再開を行うことが可能になります。ぜひ本記事を参考に、運用・開発環境でのデータ処理をより堅牢かつ効率的に行ってみてください。