概要
Databricks にて Azure Synapse Analytics Dedicated SQL (専用 SQL プール) から Spark コネクター経由でデータを取得する方法の検証結果を共有します。
専用 SQL プールに対して Spark コネクター経由でデータ交換を行う場合には、下記図のようになります。Databricks(Spark) <-> Storage <-> 専用 SQL プール というようにデータのやり取りを実施するため、それぞれの認証設定が必要となります。
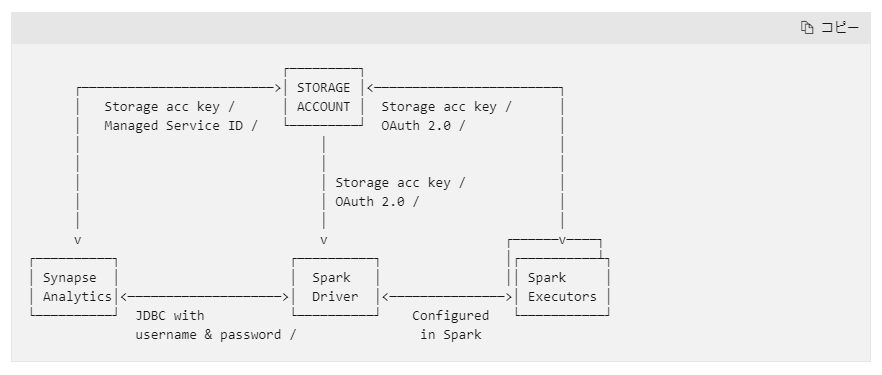
引用元:Azure Synapse Analytics - Azure Databricks | Microsoft Learn
3 つのサービス間での認証方法としては、下記表の方法があります。
| # | 認証経路 | 認証方法 |
|---|---|---|
| 1 | databricks --> 専用 SQL プール | 1. Service Principal 2. SQL 認証 |
| 2 | 専用 SQL プール --> Azure Storage | 1. Managed Service ID 2. Storage Access Key 3. Databricks で保持している Storage Access Key *1 |
| 3 | databricks --> Azure Storage | 1. Service Principal 2. Storage Access Key *2 |
*1 Databirkcs にてデータフレーム操作時に forwardSparkAzureStorageCredentials を true を設定することで実行できる方法

引用元:Azure Synapse Analytics - Azure Databricks | Microsoft Learn
*2 SAS での認証はサポートされていないようです。
Azure Synapse では、SAS を使用した BLOB ストレージへのアクセスはサポートされていません。
引用元:Azure Synapse Analytics - Azure Databricks | Microsoft Learn
synapse --> Azure Storage のサービスでは 基本的には Managed Service ID による認証を選択することになるため、Databricksにおける認証にてサービスプリンシパルを利用できるかが認証方法の検討の要因となり、次のいずれかを選択することが多くなりそうです。
1. Databricks にてサービスプリンシパルをベースに認証する方法
| # | 認証経路 | 認証方法 |
|---|---|---|
| 1 | databricks --> 専用 SQL プール | 2. Service Principal |
| 2 | 専用 SQL プール --> Azure Storage | 1. Managed Service ID |
| 3 | databricks --> Azure Storage | 1. Service Principal |
2. Databricks にてそれぞれのサービスにおける認証機能をベースに認証する方法
| # | 認証経路 | 認証方法 |
|---|---|---|
| 1 | databricks --> 専用 SQL プール | 1. SQL 認証 |
| 2 | 専用 SQL プール --> Azure Storage | 1. Managed Service ID |
| 3 | databricks --> Azure Storage | 2. Storage Access Key |
Azure Storage 上に一時的なデータが残ってしまうため、定期的に削除することが必要となります。ライフサイクル管理ポリシーを利用するなどの削除方法を検討してください。

引用元:Azure Synapse Analytics - Azure Databricks | Microsoft Learn
参考リンク
- チュートリアル:Azure portal および SSMS を使用してデータを読み込む - Azure Synapse Analytics | Microsoft Learn
- Azure Databricks で Azure Data Lake Storage Gen2 と Blob Storage にアクセスする - Azure Databricks | Microsoft Learn
- Azure SQL Database にサービス プリンシパル ユーザーを作成する - Azure SQL Database | Microsoft Learn
動作検証
0. 事前準備
0-1. Azure リソースを作成
- Azure Synapse Analytics
- 専用 SQL プール(Azure Synapse Analytics 内に作成)
- データAzure Storage (階層型名前空間が有効)
- Azure Databricks
0-2. Azure Synapse Analytics のマネージド ID に Azure Storageへの ストレージ BLOB データ共同作成者 ロールを付与
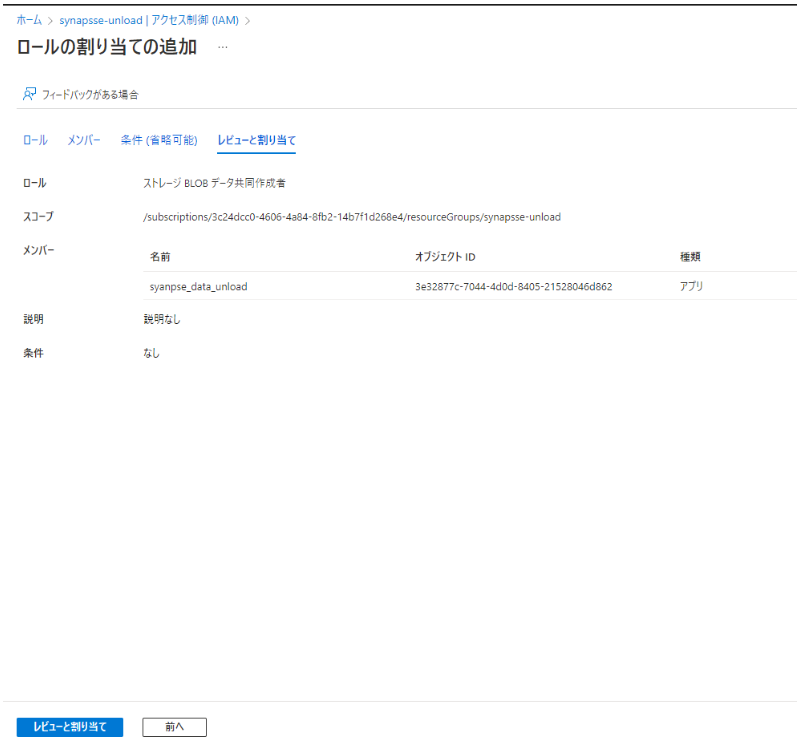
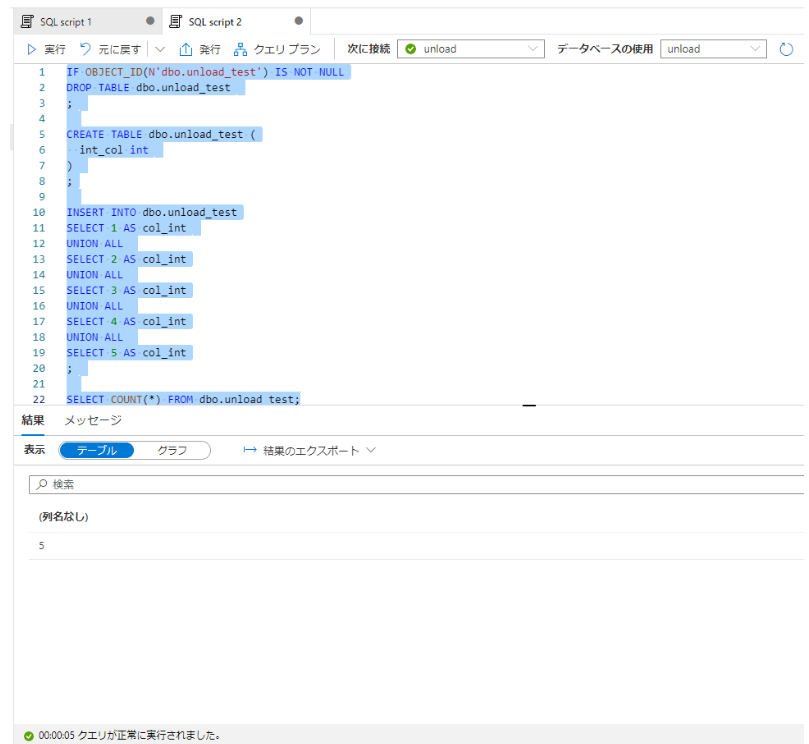
0-3. 専用 SQL プールにてサンプル用テーブルを作成
IF OBJECT_ID(N'dbo.unload_test') IS NOT NULL
DROP TABLE dbo.unload_test
;
CREATE TABLE dbo.unload_test (
int_col int
)
;
INSERT INTO dbo.unload_test
SELECT 1 AS col_int
UNION ALL
SELECT 2 AS col_int
UNION ALL
SELECT 3 AS col_int
UNION ALL
SELECT 4 AS col_int
UNION ALL
SELECT 5 AS col_int
;
SELECT COUNT(*) FROM dbo.unload_test;
1. Databricks にてサービスプリンシパルをベースに認証する方法**
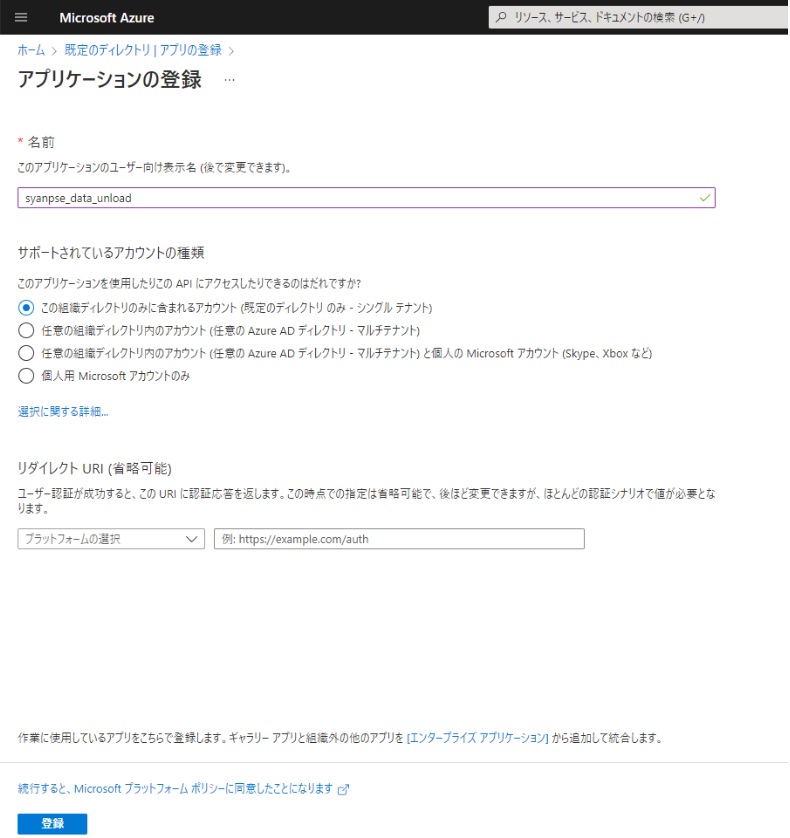
1-1. サービスプリンシパルの作成
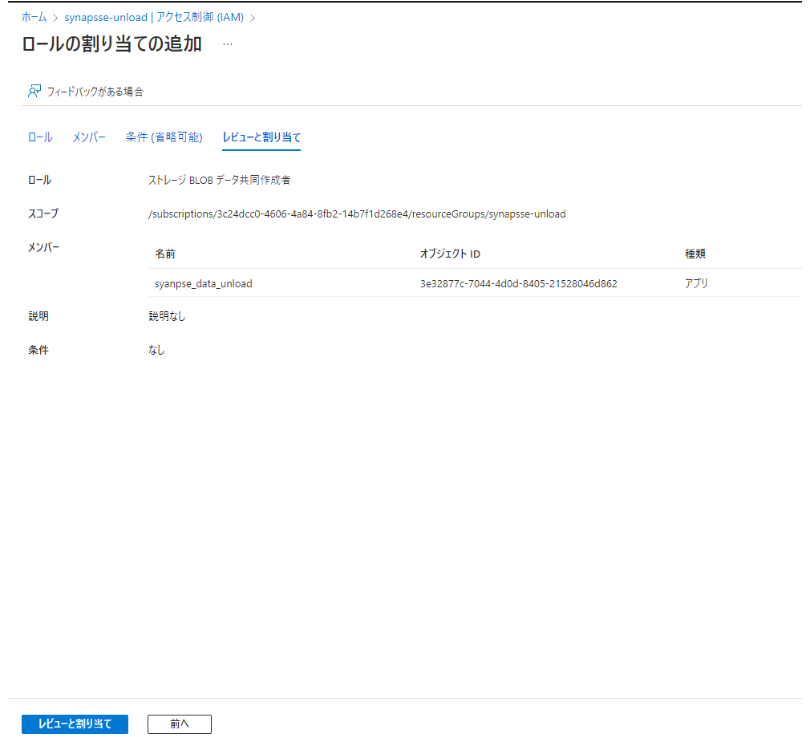
1-2. サービスプリンシパルに対して Azure Storageへの ストレージ BLOB データ共同作成者 ロールを付与
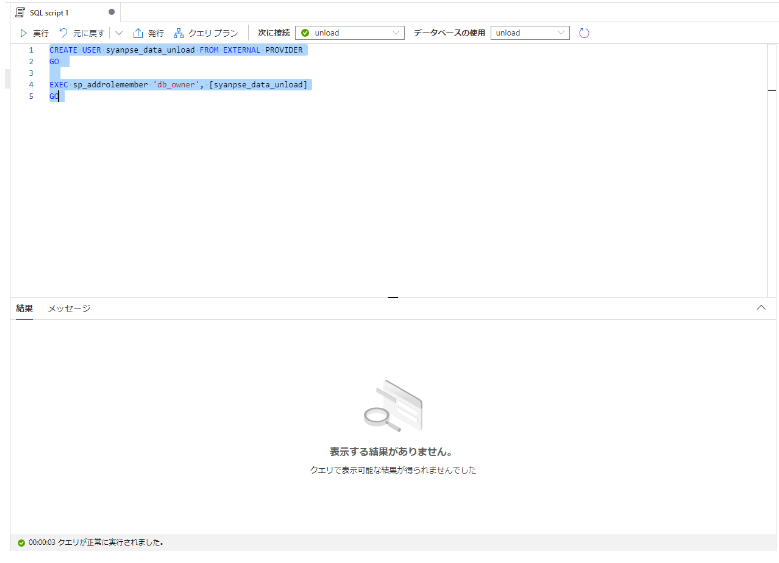
1-3. サービスプリンシパルに対して 専用 SQL プールにおけるユーザーとして登録後、 db_owner ロールを付与
CREATE USER syanpse_data_unload FROM EXTERNAL PROVIDER
GO
EXEC sp_addrolemember 'db_owner', [syanpse_data_unload]
GO
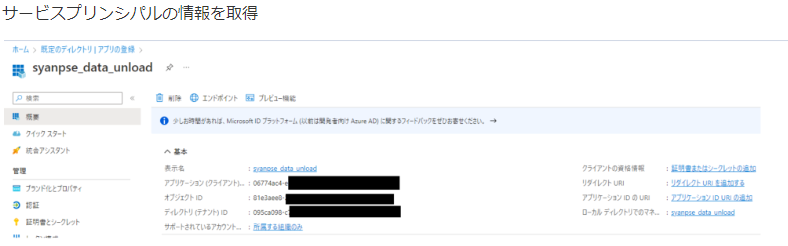
1-4. サービスプリンシパルのディレクトリ (テナント) ID、 アプリケーション (クライアント) 、および、シークレットの値 を取得
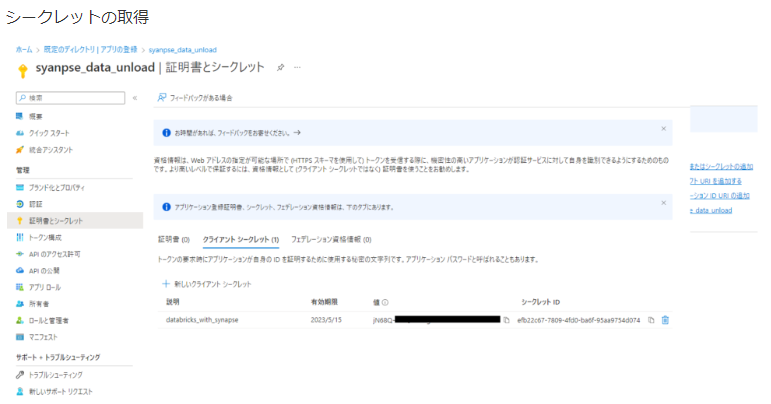
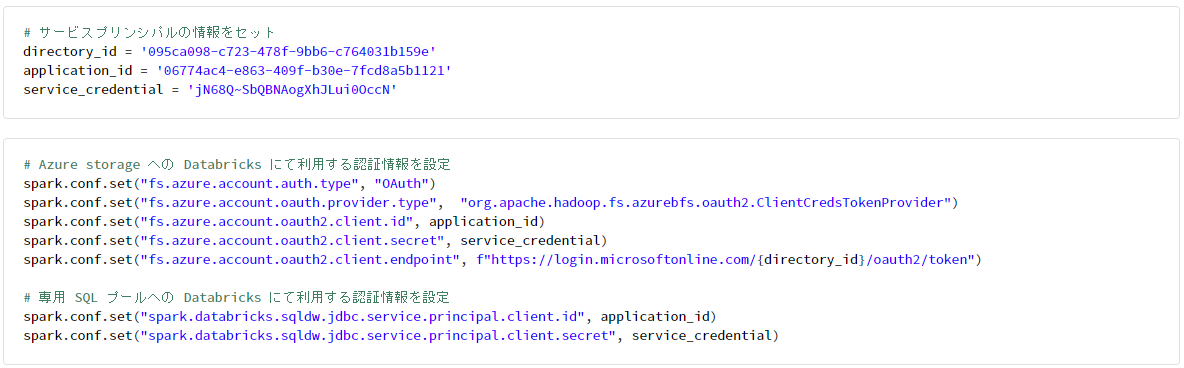
1-5. Databricks にて認証情報を設定後、専用 SQL プールからデータを取得
# サービスプリンシパルの情報をセット
directory_id = '095ca098-c723-478f-9bb6-c764031b159e'
application_id = '06774ac4-e863-409f-b30e-7fcd8a5b1121'
service_credential = 'jN68Q~SbQBNAogXhJLui0OccN'
# Azure storage への Databricks にて利用する認証情報を設定
spark.conf.set("fs.azure.account.auth.type", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id", application_id)
spark.conf.set("fs.azure.account.oauth2.client.secret", service_credential)
spark.conf.set("fs.azure.account.oauth2.client.endpoint", f"https://login.microsoftonline.com/{directory_id}/oauth2/token")
# 専用 SQL プールへの Databricks にて利用する認証情報を設定
spark.conf.set("spark.databricks.sqldw.jdbc.service.principal.client.id", application_id)
spark.conf.set("spark.databricks.sqldw.jdbc.service.principal.client.secret", service_credential)
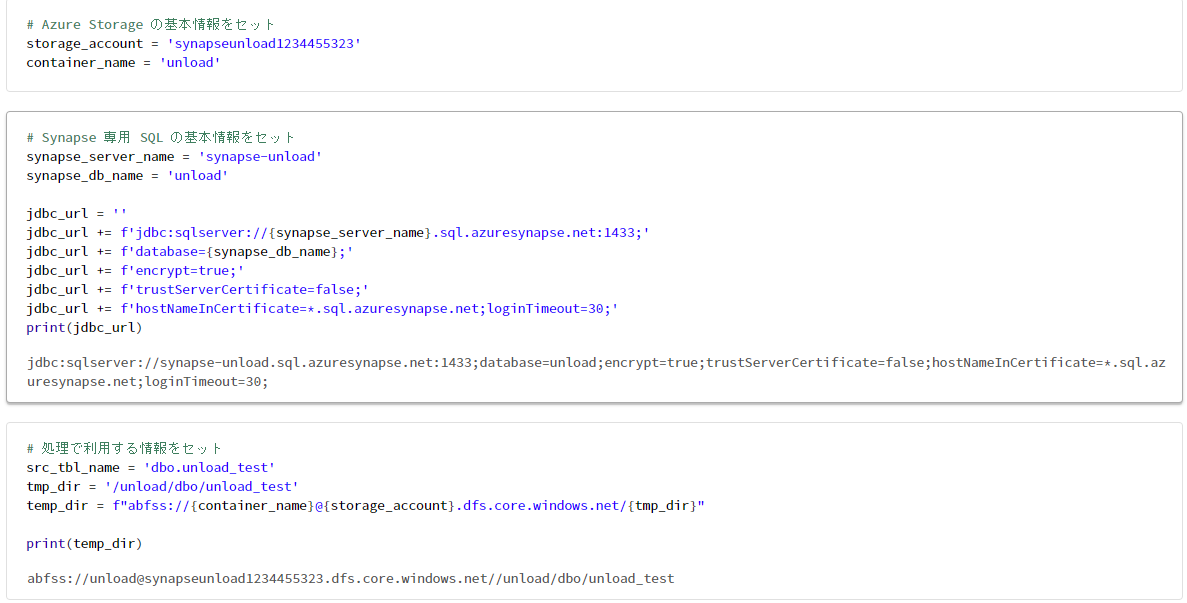
# Azure Storage の基本情報をセット
storage_account = 'synapseunload1234455323'
container_name = 'unload'
# Synapse 専用 SQL の基本情報をセット
synapse_server_name = 'synapse-unload'
synapse_db_name = 'unload'
jdbc_url = ''
jdbc_url += f'jdbc:sqlserver://{synapse_server_name}.sql.azuresynapse.net:1433;'
jdbc_url += f'database={synapse_db_name};'
jdbc_url += f'encrypt=true;'
jdbc_url += f'trustServerCertificate=false;'
jdbc_url += f'hostNameInCertificate=*.sql.azuresynapse.net;loginTimeout=30;'
print(jdbc_url)
# 処理で利用する情報をセット
src_tbl_name = 'dbo.unload_test'
tmp_dir = '/unload/dbo/unload_test'
temp_dir = f"abfss://{container_name}@{storage_account}.dfs.core.windows.net/{tmp_dir}"
print(temp_dir)
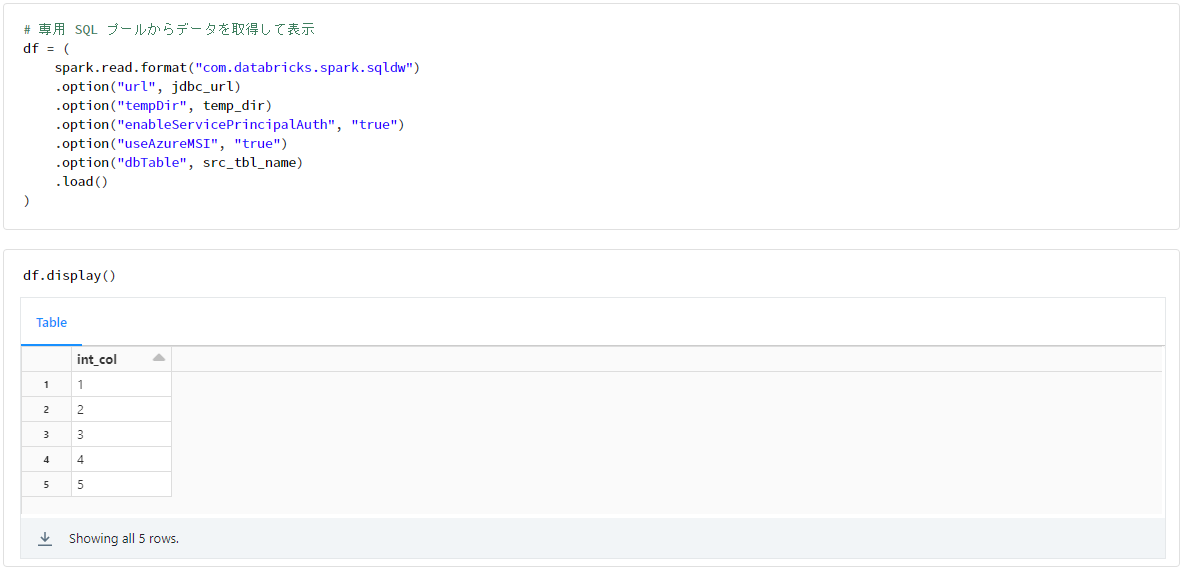
# 専用 SQL プールからデータを取得して表示
df = (
spark.read.format("com.databricks.spark.sqldw")
.option("url", jdbc_url)
.option("tempDir", temp_dir)
.option("enableServicePrincipalAuth", "true")
.option("useAzureMSI", "true")
.option("dbTable", src_tbl_name)
.load()
)
df.display()
2. Databricks にてそれぞれのサービスにおける認証機能をベースに認証する方法
2-1. Azure Storageのアクセスキーを取得
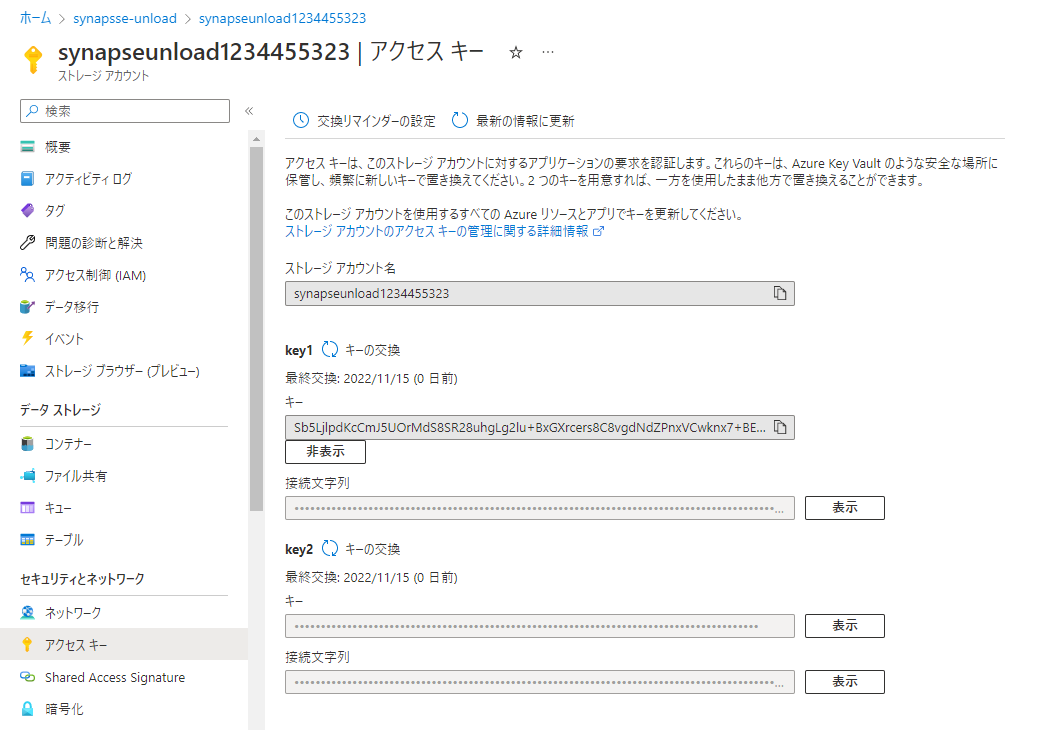
2-2. Databricks にて認証情報を設定後、専用 SQL プールからデータを取得
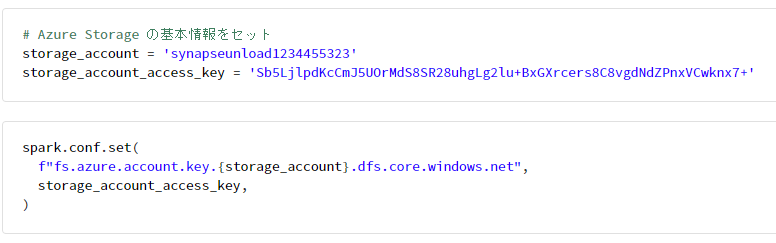
# Azure Storage の基本情報をセット
storage_account = 'synapseunload1234455323'
storage_account_access_key = 'Sb5LjlpdKcCmJ5UOrMdS8SR28uhgLg2lu+BxGXrcers8C8vgdNdZPnxVCwknx7+'
spark.conf.set(
f"fs.azure.account.key.{storage_account}.dfs.core.windows.net",
storage_account_access_key,
)
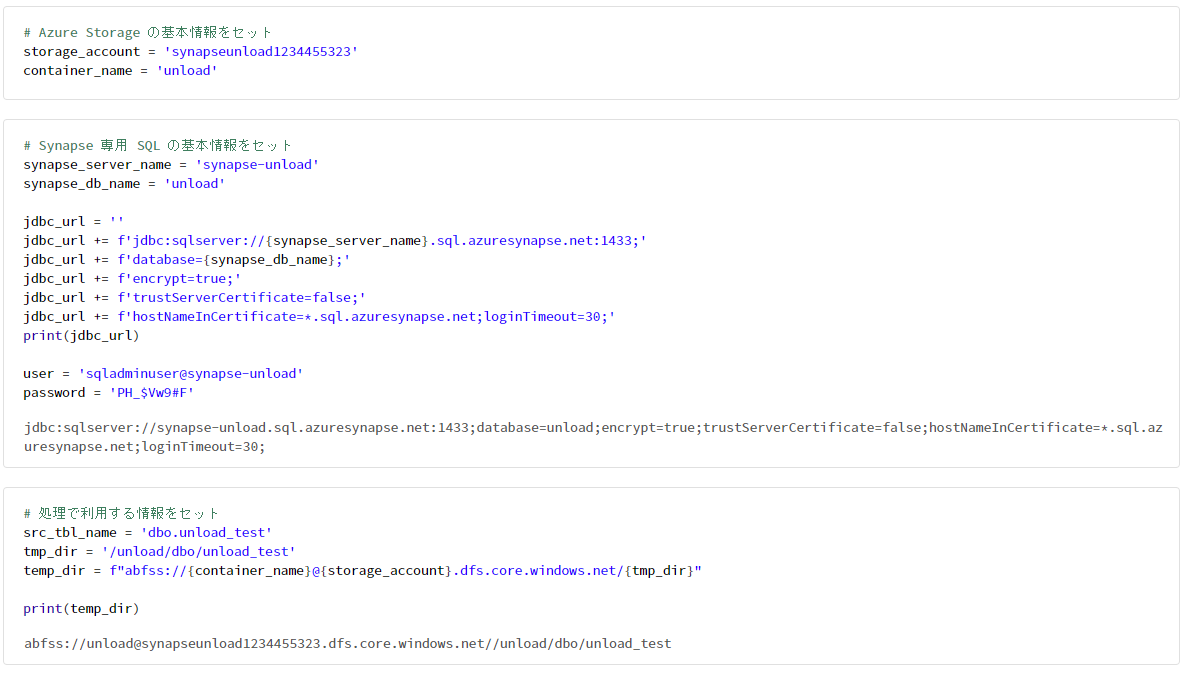
# Azure Storage の基本情報をセット
storage_account = 'synapseunload1234455323'
container_name = 'unload'
# Synapse 専用 SQL の基本情報をセット
synapse_server_name = 'synapse-unload'
synapse_db_name = 'unload'
jdbc_url = ''
jdbc_url += f'jdbc:sqlserver://{synapse_server_name}.sql.azuresynapse.net:1433;'
jdbc_url += f'database={synapse_db_name};'
jdbc_url += f'encrypt=true;'
jdbc_url += f'trustServerCertificate=false;'
jdbc_url += f'hostNameInCertificate=*.sql.azuresynapse.net;loginTimeout=30;'
print(jdbc_url)
user = 'sqladminuser@synapse-unload'
password = 'PH_$Vw9#F`'
# 処理で利用する情報をセット
src_tbl_name = 'dbo.unload_test'
tmp_dir = '/unload/dbo/unload_test'
temp_dir = f"abfss://{container_name}@{storage_account}.dfs.core.windows.net/{tmp_dir}"
print(temp_dir)
# 専用 SQL プールからデータを取得して表示
df = (
spark.read.format("com.databricks.spark.sqldw")
.option("url", jdbc_url)
.option("tempDir", temp_dir)
.option("useAzureMSI", "true")
.option("user", user)
.option("password", password)
.option("dbTable", src_tbl_name)
.load()
)
df.display()