概要
Google Colab (Python)にて Wikidata に対する SPARQL の基本的な操作を実施します。 Wikidata の基本的な説明を実施後、本ノートブックにて Python で Wikidata から SPARQL によりデータの抽出を実行します。
Spark の記事ではなく、 SPARQL の記事です。SPARQL とは、RDF(Resource Description Framework)データをクエリするための問い合わせ言語です。SPARQLは、W3C(World Wide Web Consortium)によって標準化された言語で、RDFデータモデルに基づくデータベースから情報を抽出するために使用されているようです。
Wikidata について
Wikidata とは、下記のように説明されており、取得したデータを自由に再利用にできます。
ウィキデータは、人間とコンピュータの双方が平等に参照・編集できる無料のオープンな知識データベースサイトです。
引用元:Wikidata
Wikidata 上のデータを取得する方法として、Wikidata Query Service という SPARQL を実行できる WEB インタフェースが提供されています。操作方法については、下記のドキュメントにて詳細が記載されています。
Wikidata Query Service では実行した SPARQL を追記した URL により共有することが可能であり、下記の URL を開くと Wikidata から 人口が多い TOP 10 の国を抽出する SPARQL が記述された状態の Wikidata Query Service に接続ができる。
Wikidata Query Service には、他にも下記のような機能があります。
- サンプルクエリを実行する機能
- prefix を登録する機能
- Python 等のコードに変換する機能
- データをエクスポートする機能
- グラフ化機能
SPAQL についてより学習したい場合には、下記のドキュメントが参考となります。
事前準備
SPARQLWrapper のインストール
!pip install SPARQLWrapper -q

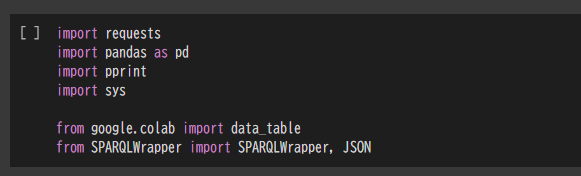
利用するライブラリのインポート
import requests
import pandas as pd
import pprint
import sys
from google.colab import data_table
from SPARQLWrapper import SPARQLWrapper, JSON
SPARQL の基本的な実行
Web APIを利用したSPARQLによるデータ取得
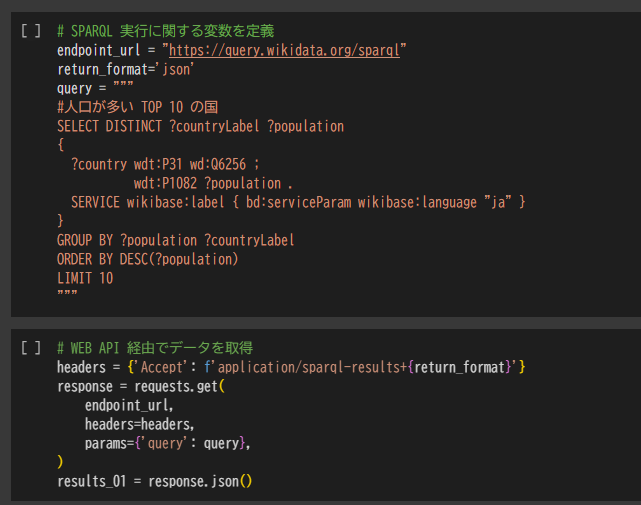
# SPARQL 実行に関する変数を定義
endpoint_url = "https://query.wikidata.org/sparql"
return_format='json'
query = """
#人口が多い TOP 10 の国
SELECT DISTINCT ?countryLabel ?population
{
?country wdt:P31 wd:Q6256 ;
wdt:P1082 ?population .
SERVICE wikibase:label { bd:serviceParam wikibase:language "ja" }
}
GROUP BY ?population ?countryLabel
ORDER BY DESC(?population)
LIMIT 10
"""
# WEB API 経由でデータを取得
headers = {'Accept': f'application/sparql-results+{return_format}'}
response = requests.get(
endpoint_url,
headers=headers,
params={'query': query},
)
results_01 = response.json()
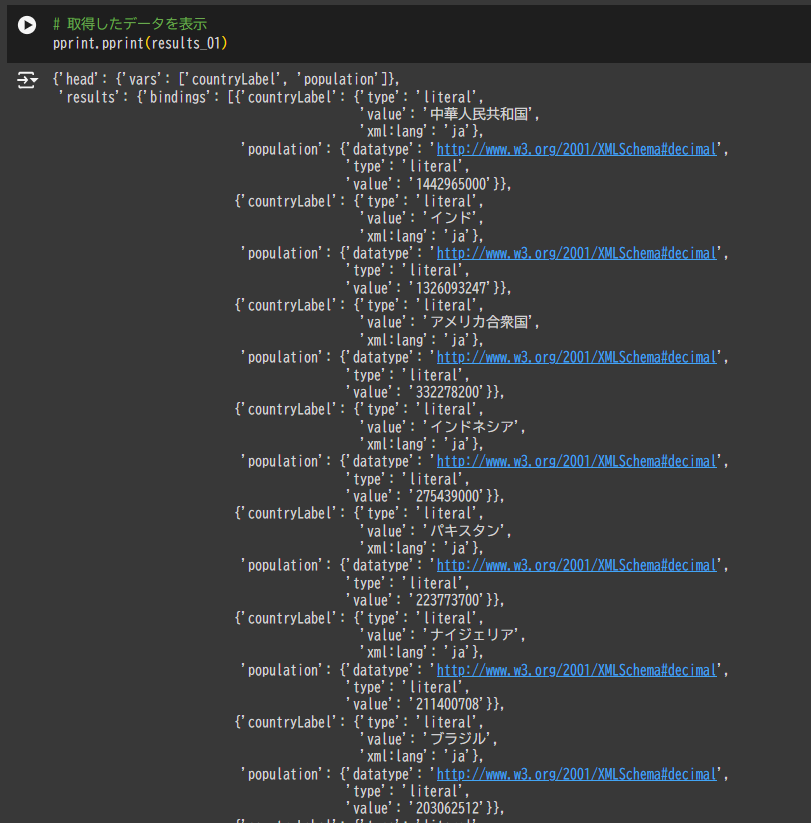
# 取得したデータを表示
pprint.pprint(results_01)
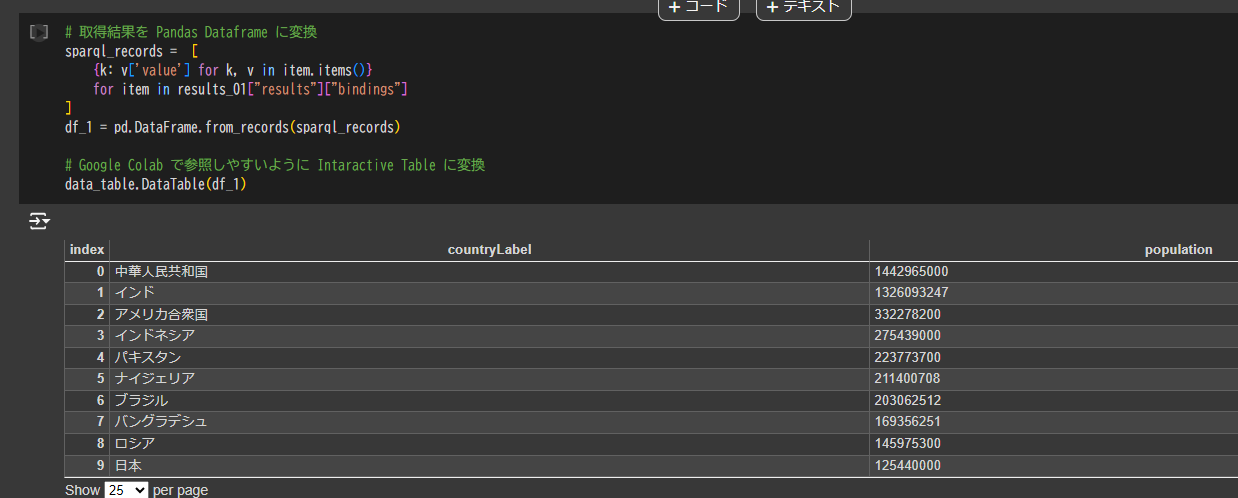
# 取得結果を Pandas Dataframe に変換
sparql_records = [
{k: v['value'] for k, v in item.items()}
for item in results_01["results"]["bindings"]
]
df_1 = pd.DataFrame.from_records(sparql_records)
# Google Colab で参照しやすいように Intaractive Table に変換
data_table.DataTable(df_1)
SPARQLWrapper ライブラリを利用したSPARQLによるデータ取得
# SPARQL 実行に関する変数を定義
endpoint_url = "https://query.wikidata.org/sparql"
return_format='json'
query = """
#人口が多い TOP 3 の国
SELECT DISTINCT ?countryLabel ?population
{
?country wdt:P31 wd:Q6256 ;
wdt:P1082 ?population .
SERVICE wikibase:label { bd:serviceParam wikibase:language "ja" }
}
GROUP BY ?population ?countryLabel
ORDER BY DESC(?population)
LIMIT 3
"""
# SPARQLWrapper ライブラリ経由でデータを取得
user_agent = "WDQS-example Python/%s.%s" % (sys.version_info[0], sys.version_info[1])
sparql = SPARQLWrapper(endpoint_url, agent=user_agent)
sparql.setQuery(query)
sparql.setReturnFormat(JSON)
results_02 = sparql.query().convert()
# 取得したデータを表示
pprint.pprint(results_02)
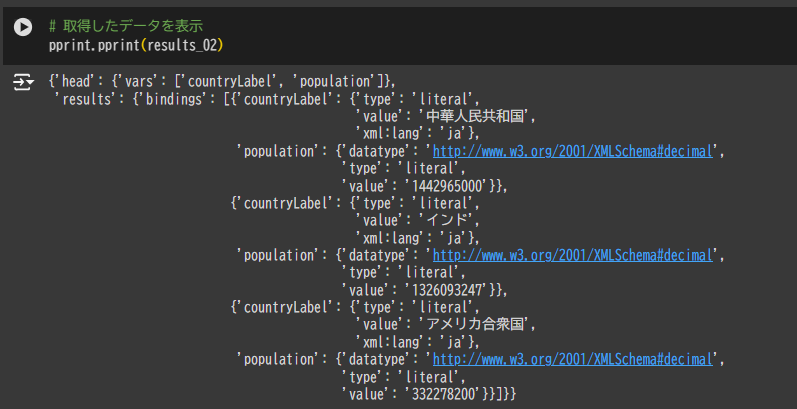
# 取得結果を Pandas Dataframe に変換
sparql_records = [
{k: v['value'] for k, v in item.items()}
for item in results_02["results"]["bindings"]
]
df_02 = pd.DataFrame.from_records(sparql_records)
# Google Colab で参照しやすいように Intaractive Table に変換
data_table.DataTable(df_02)
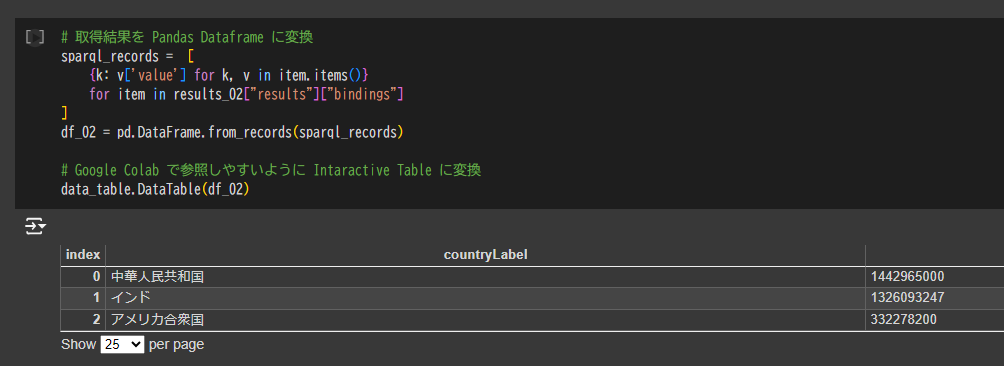
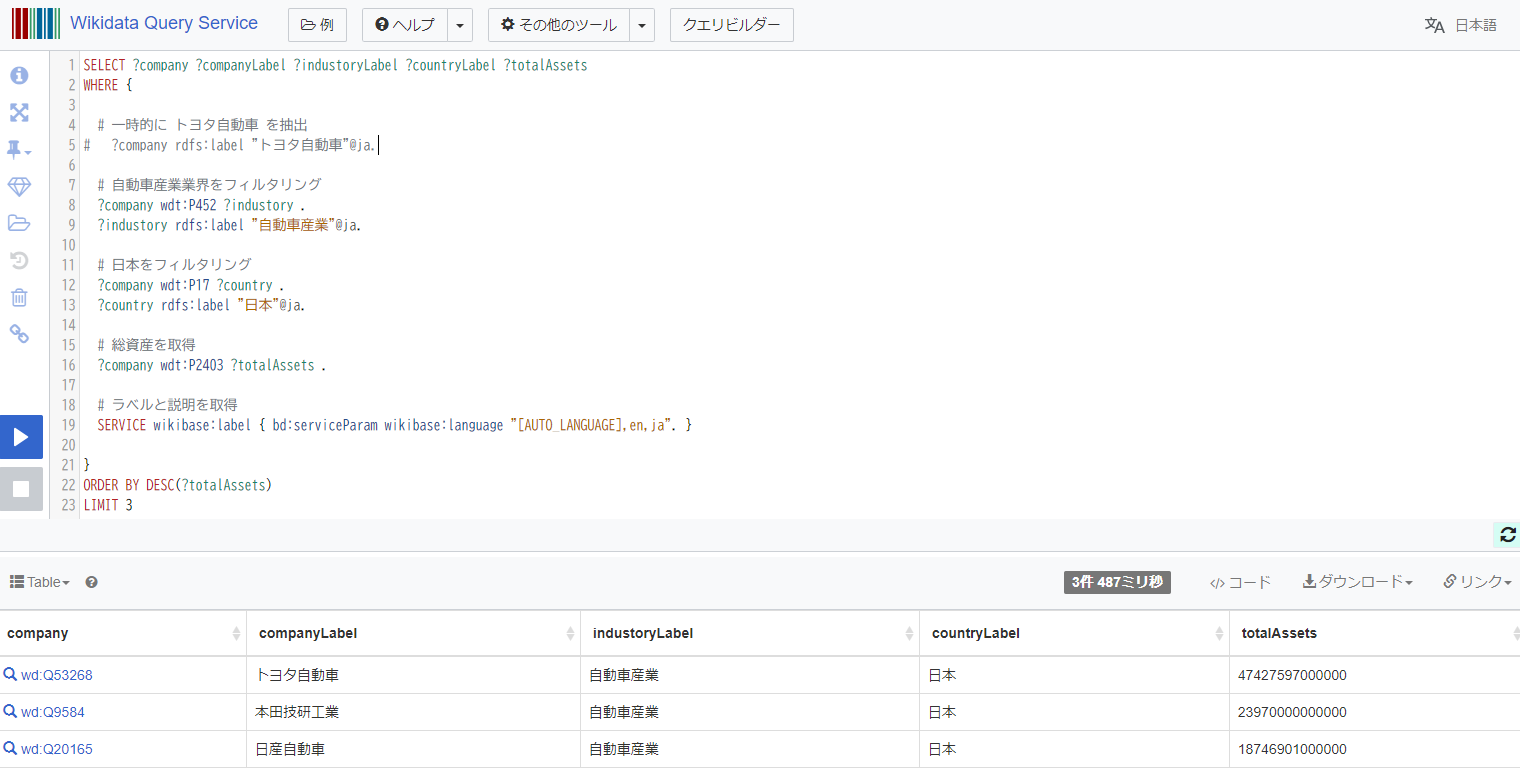
日本の自動車業界における総資産が TOP 3 の企業のデータ抽出
SPARQL の組み立て
今回の要件を満たす SPARQL は下記のようなコードとなります。SPARQL の組み立て方法が不明であったため、とりあえずトヨタ自動車のデータの抽出から初めて、業界や国のフィルタリング条件を追加していきました。
SELECT ?company ?companyLabel ?industoryLabel ?countryLabel ?totalAssets
WHERE {
# 一時的に トヨタ自動車 を抽出
# ?company rdfs:label "トヨタ自動車"@ja.
# 自動車産業業界をフィルタリング
?company wdt:P452 ?industory .
?industory rdfs:label "自動車産業"@ja.
# 日本をフィルタリング
?company wdt:P17 ?country .
?country rdfs:label "日本"@ja.
# 総資産を取得
?company wdt:P2403 ?totalAssets .
# ラベルと説明を取得
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en,ja". }
}
ORDER BY DESC(?totalAssets)
LIMIT 3
下記のクエリによりトヨタ自動車のデータを取得します。wd:Q53268と書かれている箇所をクリックして wikidata のページに飛びます。
SELECT ?company ?companyLabel ?industoryLabel ?countryLabel ?totalAssets
WHERE {
# 一時的に トヨタ自動車 を抽出
?company rdfs:label "トヨタ自動車"@ja.
# ラベルと説明を取得
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en,ja". }
}
ORDER BY DESC(?totalAssets)
LIMIT 3
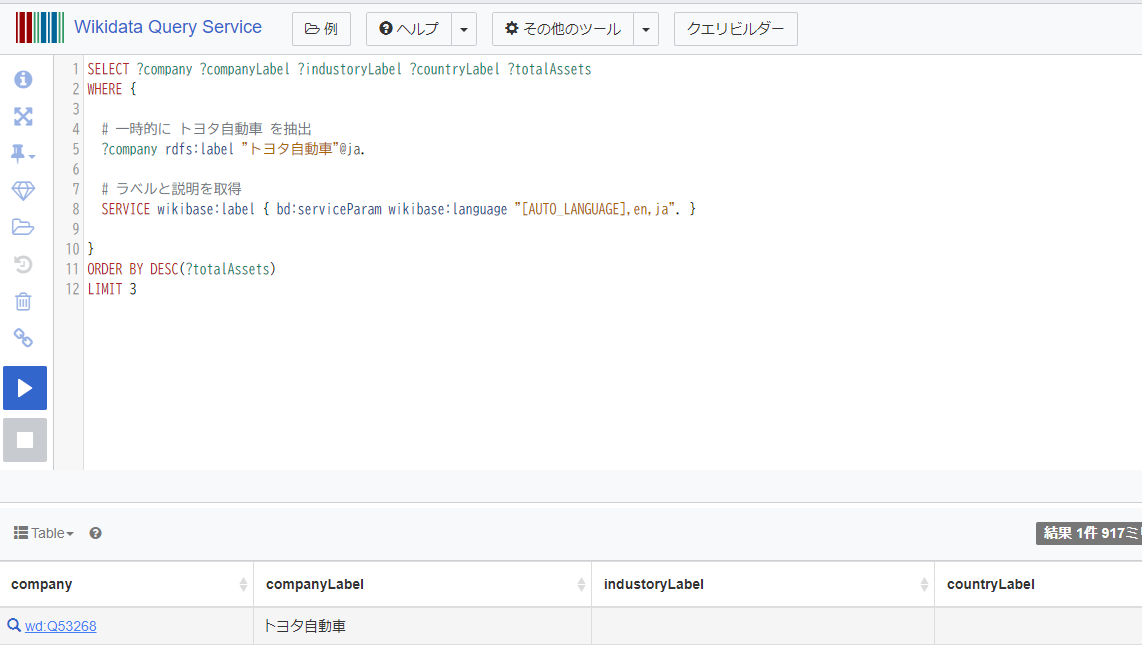
Wikidata のページにて Industy と書かて箇所をクリックします。
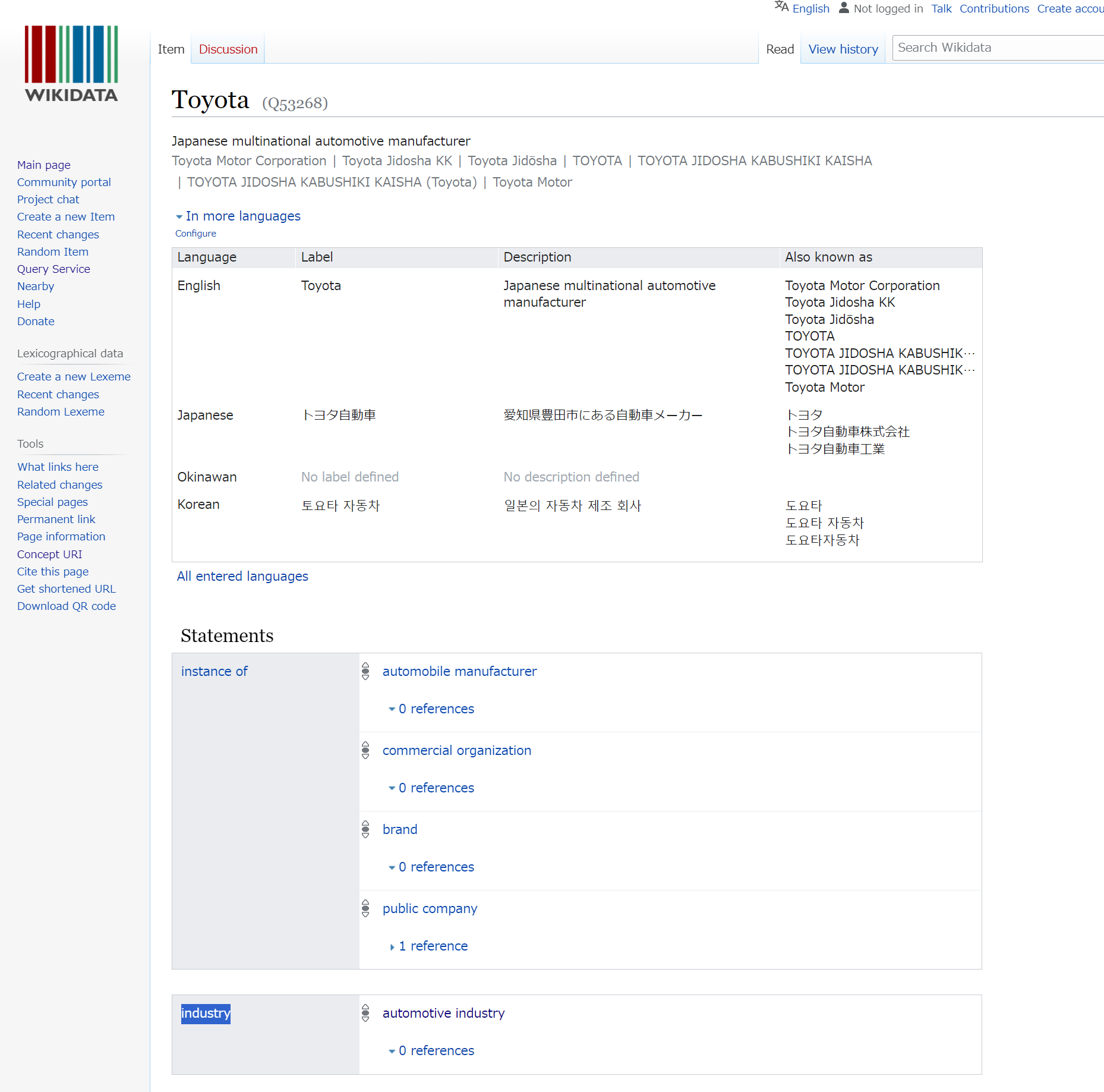
Industry の識別子である P452 を取得します。
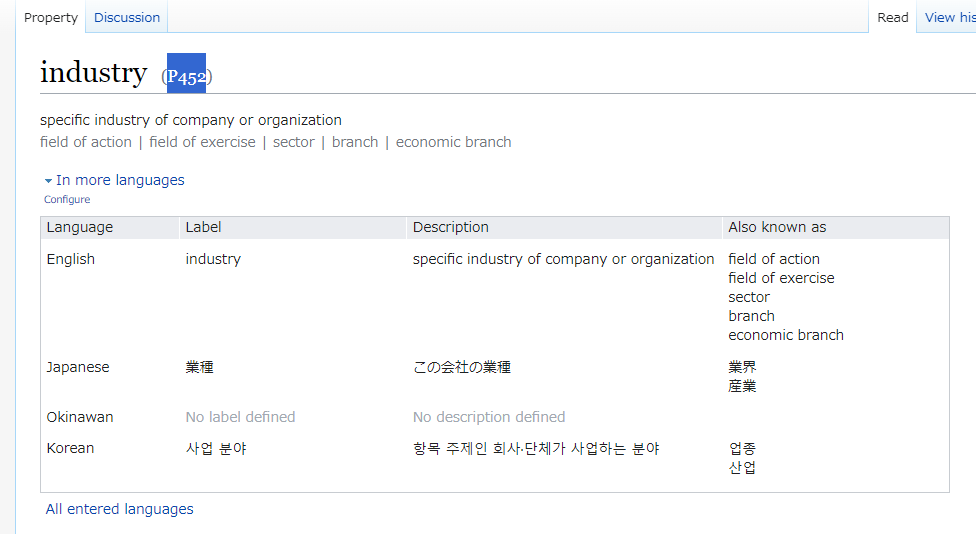
トヨタ自動車のフィルタリングを外し、industry のプロパティを追加して自動車産業のみにフィルタリングします。その結果、自動車
SELECT ?company ?companyLabel ?industoryLabel ?countryLabel ?totalAssets
WHERE {
# 一時的に トヨタ自動車 を抽出
# ?company rdfs:label "トヨタ自動車"@ja.
# 自動車産業業界をフィルタリング
?company wdt:P452 ?industory .
?industory rdfs:label "自動車産業"@ja.
# ラベルと説明を取得
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en,ja". }
}
ORDER BY DESC(?totalAssets)
LIMIT 3
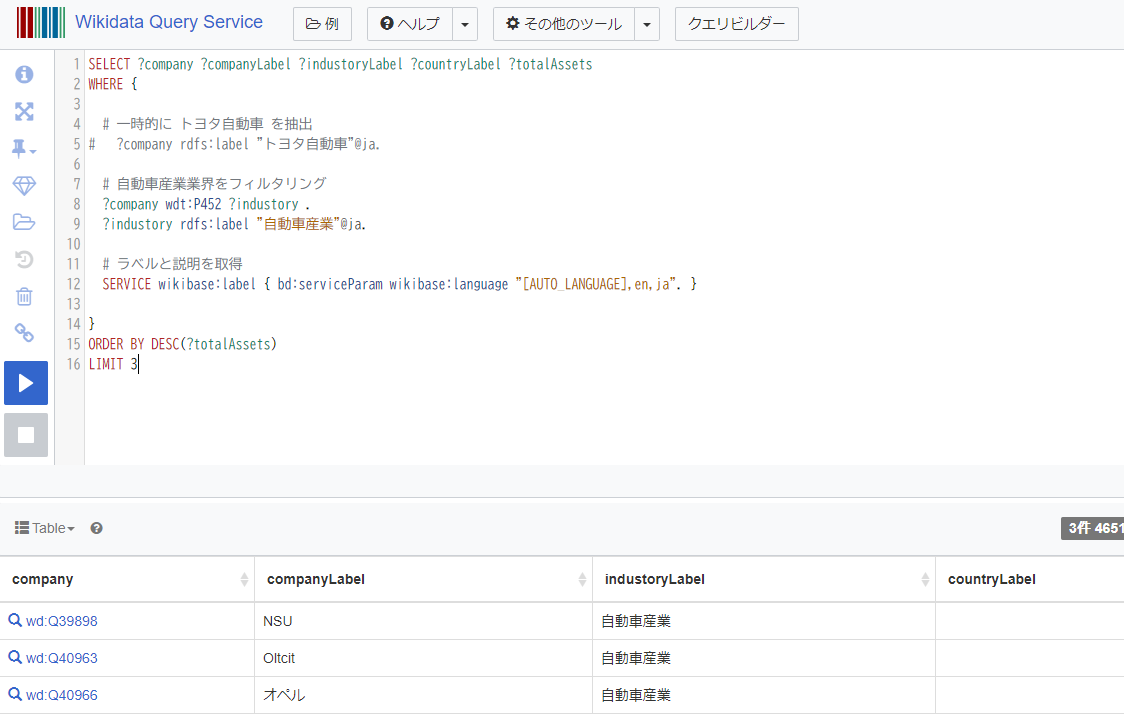
同様に county の項目値を取得して日本にフィルタリングします。
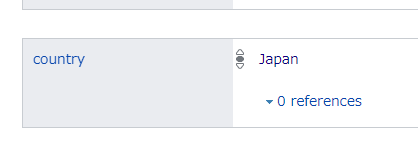
SELECT ?company ?companyLabel ?industoryLabel ?countryLabel ?totalAssets
WHERE {
# 一時的に トヨタ自動車 を抽出
# ?company rdfs:label "トヨタ自動車"@ja.
# 自動車産業業界をフィルタリング
?company wdt:P452 ?industory .
?industory rdfs:label "自動車産業"@ja.
# 日本をフィルタリング
?company wdt:P17 ?country .
?country rdfs:label "日本"@ja.
# ラベルと説明を取得
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en,ja". }
}
ORDER BY DESC(?totalAssets)
LIMIT 3
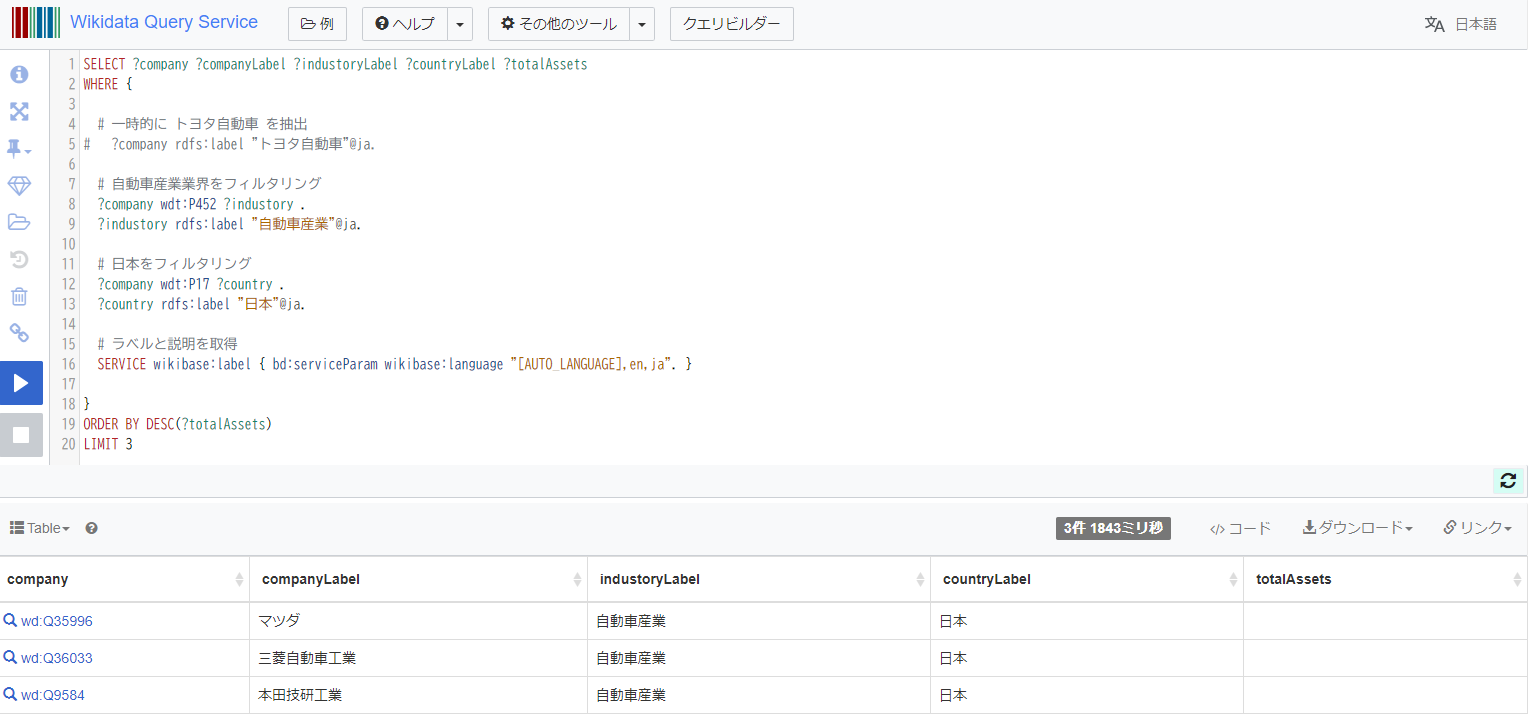
同様に total assets の項目値を取得します。この修正により要件を満たすクエリとなります。
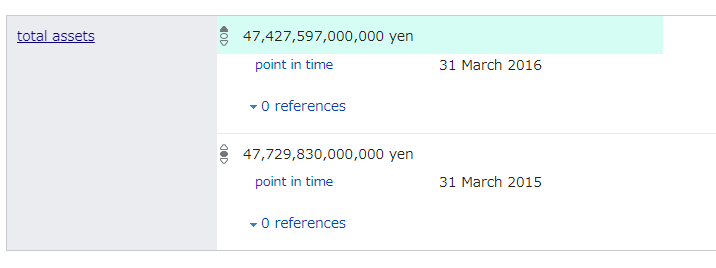
SELECT ?company ?companyLabel ?industoryLabel ?countryLabel ?totalAssets
WHERE {
# 一時的に トヨタ自動車 を抽出
# ?company rdfs:label "トヨタ自動車"@ja.
# 自動車産業業界をフィルタリング
?company wdt:P452 ?industory .
?industory rdfs:label "自動車産業"@ja.
# 日本をフィルタリング
?company wdt:P17 ?country .
?country rdfs:label "日本"@ja.
# 総資産を取得
?company wdt:P2403 ?totalAssets .
# ラベルと説明を取得
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en,ja". }
}
ORDER BY DESC(?totalAssets)
LIMIT 3
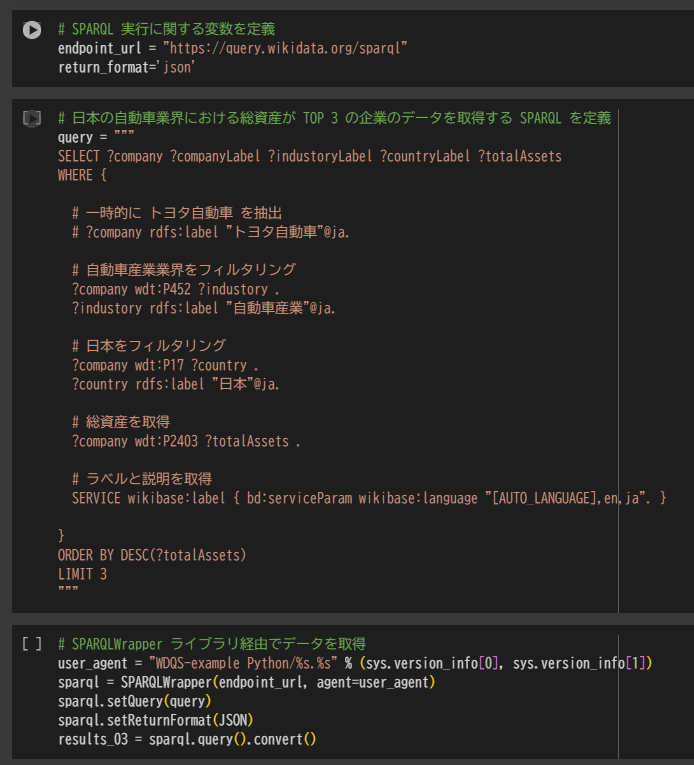
Python でのデータを抽出から可視化までの処理
# SPARQL 実行に関する変数を定義
endpoint_url = "https://query.wikidata.org/sparql"
return_format='json'
# 日本の自動車業界における総資産が TOP 3 の企業のデータを取得する SPARQL を定義
query = """
SELECT ?company ?companyLabel ?industoryLabel ?countryLabel ?totalAssets
WHERE {
# 一時的に トヨタ自動車 を抽出
# ?company rdfs:label "トヨタ自動車"@ja.
# 自動車産業業界をフィルタリング
?company wdt:P452 ?industory .
?industory rdfs:label "自動車産業"@ja.
# 日本をフィルタリング
?company wdt:P17 ?country .
?country rdfs:label "日本"@ja.
# 総資産を取得
?company wdt:P2403 ?totalAssets .
# ラベルと説明を取得
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en,ja". }
}
ORDER BY DESC(?totalAssets)
LIMIT 3
"""
# SPARQLWrapper ライブラリ経由でデータを取得
user_agent = "WDQS-example Python/%s.%s" % (sys.version_info[0], sys.version_info[1])
sparql = SPARQLWrapper(endpoint_url, agent=user_agent)
sparql.setQuery(query)
sparql.setReturnFormat(JSON)
results_03 = sparql.query().convert()
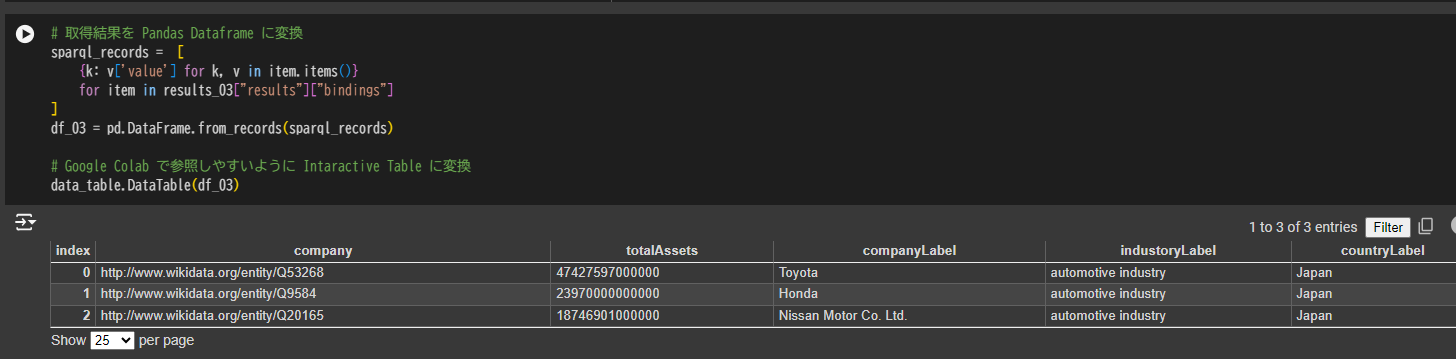
# 取得結果を Pandas Dataframe に変換
sparql_records = [
{k: v['value'] for k, v in item.items()}
for item in results_03["results"]["bindings"]
]
df_03 = pd.DataFrame.from_records(sparql_records)
# Google Colab で参照しやすいように Intaractive Table に変換
data_table.DataTable(df_03)
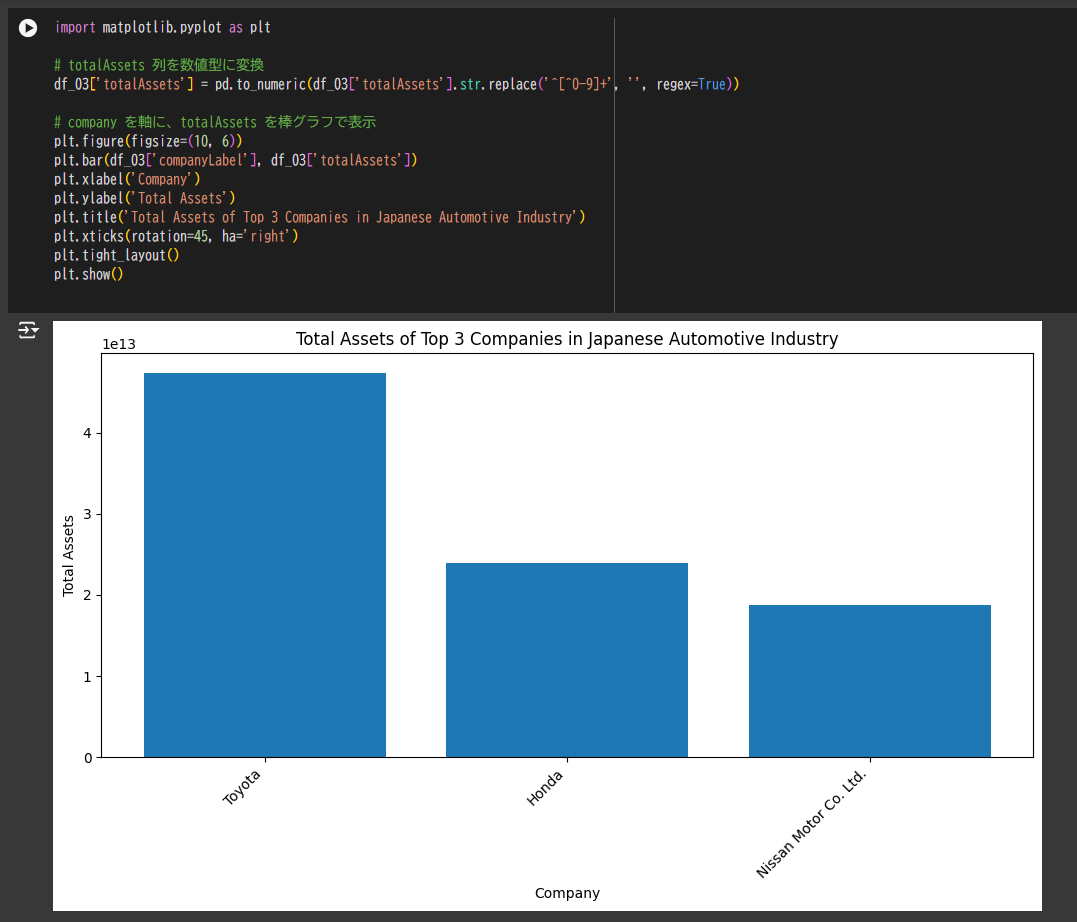
import matplotlib.pyplot as plt
# totalAssets 列を数値型に変換
df_03['totalAssets'] = pd.to_numeric(df_03['totalAssets'].str.replace('^[^0-9]+', '', regex=True))
# company を軸に、totalAssets を棒グラフで表示
plt.figure(figsize=(10, 6))
plt.bar(df_03['companyLabel'], df_03['totalAssets'])
plt.xlabel('Company')
plt.ylabel('Total Assets')
plt.title('Total Assets of Top 3 Companies in Japanese Automotive Industry')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
所感
- SPARQLに関する情報源が限られているため、実装プロセスが不明瞭であったり、特定の機能の実装可能性を判断するのが難しかった。
- SQLエンジニアである私には、WHERE句の中で取得するカラムのロジックを記述することに違和感があった。
- この記事で総資産の取得を試みたが、通貨や会計年度に関する情報の取得方法を確立できなかった。複数の条件でデータを取得できるかどうかも不明だった。