概要
Databricks 開発時にノートブックの一部を修正して複製する作業を次のステップにて大量に実施することがあります。退屈なことはPythonにやらせようと考えました。実装方針とコードを共有します。
- ベースノートブックの内容をエクスポート
- ノートブック内容の一部を修正
- 別名のノートブックとしてインポート
実装方針
ノートブックのエクスポートとインポート
ノートブックのエクスポートとインポートを自動化する方法としては、Databricks SDK for Python と Databricks REST API があります。簡易的に利用できる Databricks SDK for Pythonを紹介します。
- Databricks SDK for Python (Beta) — Databricks SDK for Python beta documentation (databricks-sdk-py.readthedocs.io)
- Databricks REST API reference
ベースのノートブックと内容の置換方法
複製元のノートブックをベースのノートブックとして事前に用意します。置換対象の箇所を、##ではじまり##で終わる文字(例:##table##)で記述し、その文字列を置換します。置換する方法としては、静的な値(例:samples.tpch.nation)をに置換する方法と動的な値(変数値)に置換する方法があります。動的な値を置換する方法として、SELECT 文でカラムを生成するケースがあります。修正前の##cols##と##table##を置換する方法を紹介します。
# 修正前
df = spark.sql("""
SELECT
##cols##
FROM
##table##
LIMIT 10;
""")
df.display()
# 修正後
df = spark.sql("""
SELECT
n_nationkey,
n_name,
n_regionkey,
n_comment
FROM
samples.tpch.nation
LIMIT 10;
""")
df.display()
コードと実行結果
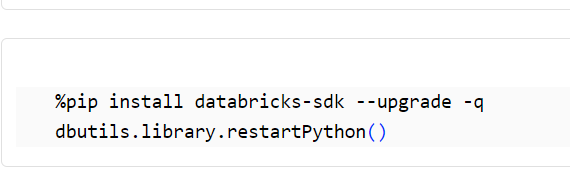
ライブラリのインストール
Databricks SDK for python をインストールします。
%pip install databricks-sdk --upgrade -q
dbutils.library.restartPython()
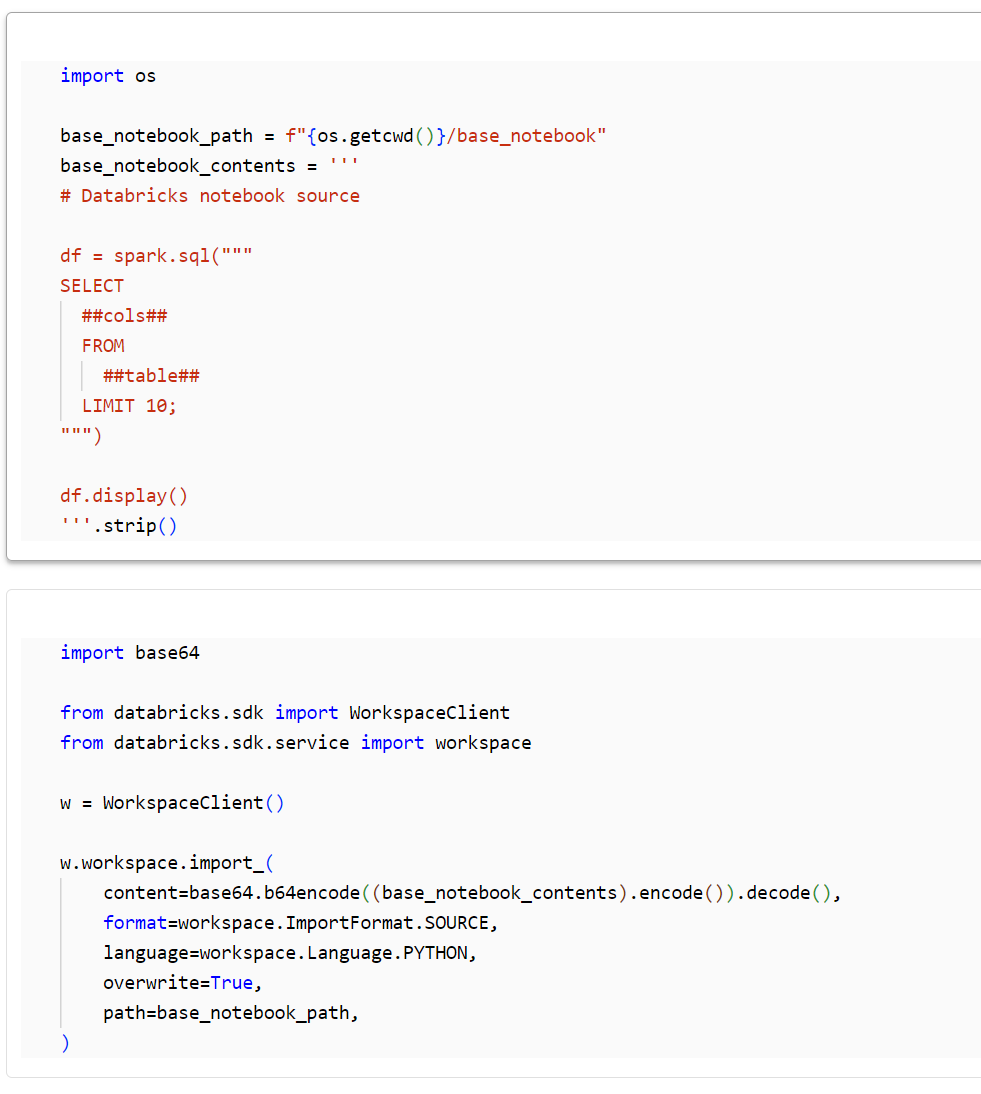
ベースのノートブックを作成
取得元となるベースのノートブックを作成します。##cols##と##table##が置換対象の文字列です。
import os
base_notebook_path = f"{os.getcwd()}/base_notebook"
base_notebook_contents = '''
# Databricks notebook source
df = spark.sql("""
SELECT
##cols##
FROM
##table##
LIMIT 10;
""")
df.display()
'''.strip()
import base64
from databricks.sdk import WorkspaceClient
from databricks.sdk.service import workspace
w = WorkspaceClient()
w.workspace.import_(
content=base64.b64encode((base_notebook_contents).encode()).decode(),
format=workspace.ImportFormat.SOURCE,
language=workspace.Language.PYTHON,
overwrite=True,
path=base_notebook_path,
)
base_notebookというベースのノートブックが作成されます。

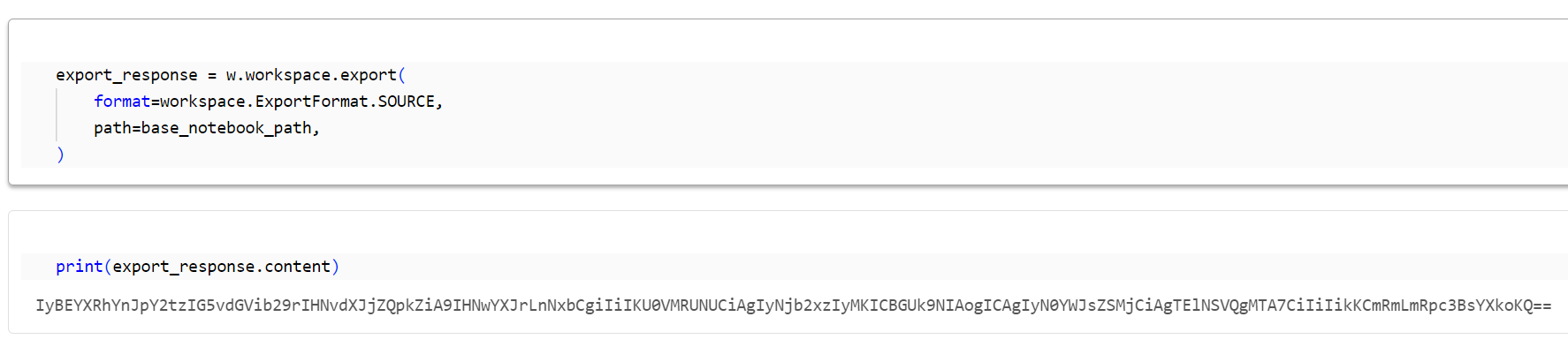
ベースノートブックの内容をエクスポート
Databricks SDK にて作成済みのベースのノートブックの内容を取得します。取得した内容は base64 形式となっております。
export_response = w.workspace.export(
format=workspace.ExportFormat.SOURCE,
path=base_notebook_path,
)
print(export_response.content)
ベースノートブックの内容を decode して、識別可能な文字に変換します。
decoded_content = base64.b64decode(export_response.content)
decoded_content = decoded_content.decode()
print(decoded_content)

ノートブック内容の一部を修正
##table##をテーブル名に変換します。
replaced_strs = {
"##table##": "samples.tpch.nation",
}
for old, new in replaced_strs.items():
decoded_content = decoded_content.replace(old, new)
# `##table##`が`samples.tpch.nation`に変更されていることを確認
print(decoded_content)

##cols##を、テーブル情報から生成した SELECT 文の named_expression の変数値に置換します。
columns = spark.table("samples.tpch.nation").columns
columns_str = ",\n ".join(columns)
print(columns_str)
replaced_strs_by_var = {
"##cols##": "columns_str",
}
for old, new in replaced_strs_by_var.items():
decoded_content = decoded_content.replace(old, eval(new))
print(decoded_content)

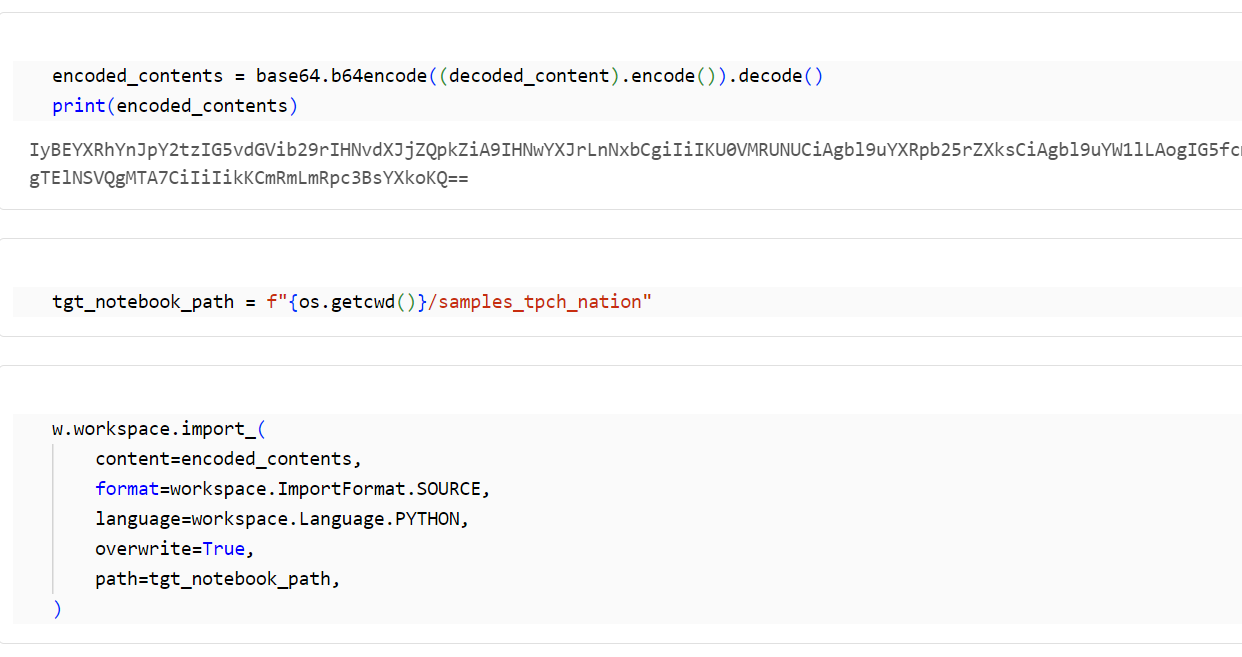
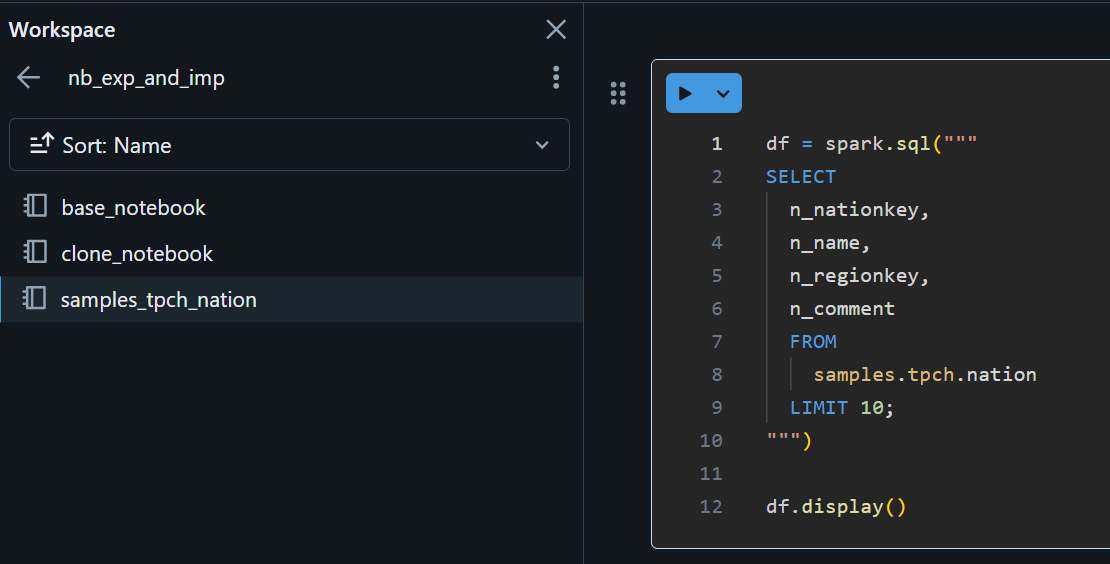
別名のノートブックとしてインポート
ベースのテーブルから取得後に一部の値を置換した文字列を、 base64 形式に変換し、ノートブックとしてインポートします。
encoded_contents = base64.b64encode((decoded_content).encode()).decode()
print(encoded_contents)
tgt_notebook_path = f"{os.getcwd()}/samples_tpch_nation"
w.workspace.import_(
content=encoded_contents,
format=workspace.ImportFormat.SOURCE,
language=workspace.Language.PYTHON,
overwrite=True,
path=tgt_notebook_path,
)
samples_tpch_nationというノートブックが作成されます。
まとめ
この記事では、Databricksのノートブックの一部を修正して複製する作業を自動化する方法を提案しました。
具体的には、ベースノートブックの内容をエクスポートし、その内容の一部を修正した後、別名のノートブックとしてインポートするという手順を説明しました。このプロセスは、Databricks SDK for Pythonを使用して実装されています。また、ノートブックの内容を修正する際には、静的な値や動的な値(変数値)に置換する方法を提供しました。これにより、SELECT文のカラムを生成するなど、より複雑なケースに対応することが可能になります。
この自動化手法を利用することで、Databricks開発時の生産性を向上させることが期待できます。