概要
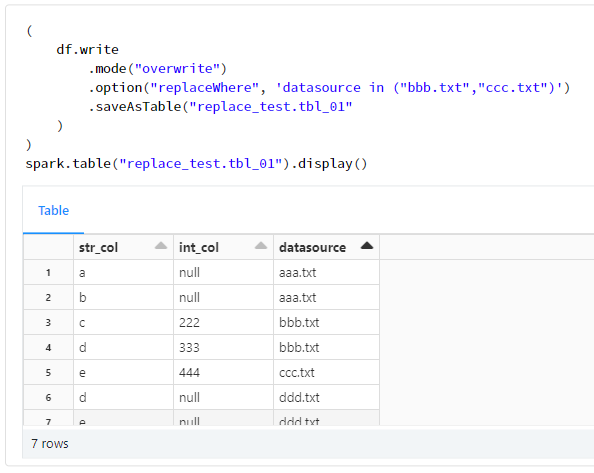
Databricks の replaceWhere による選択的上書きにて IN 句(例:datasource in ("bbb.txt","ccc.txt"))の利用可否の検証結果を共有します。結論としては、IN 句で指定したデータが上書きされました。replaceWhere による選択的上書きとは、次のドキュメントにて記載されている機能です。
検証方法と検証結果
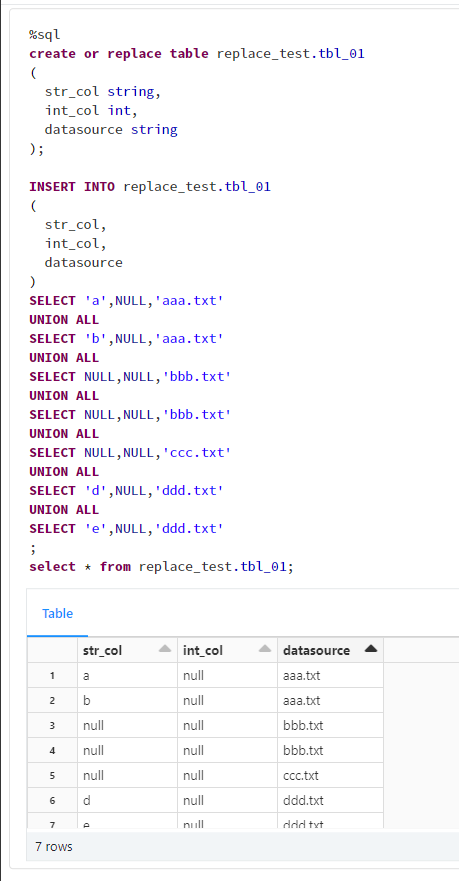
次のようなデータをもつテーブルを用意します。
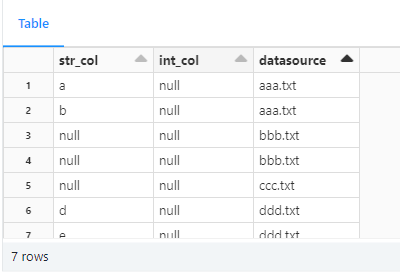
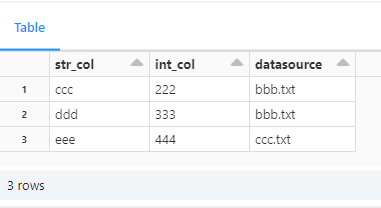
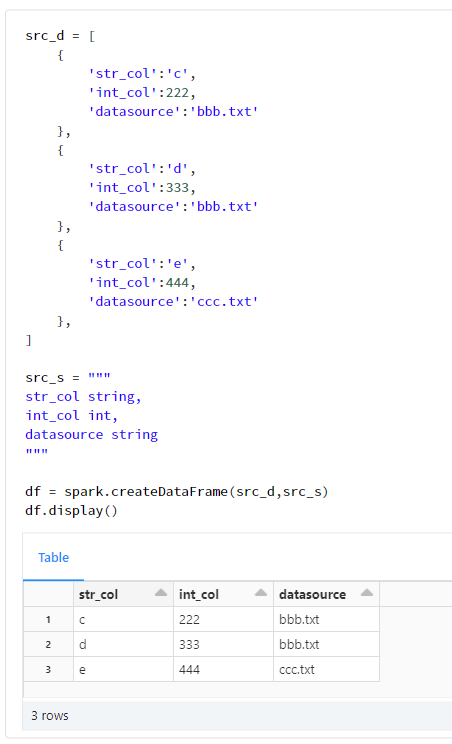
datasource列にてbbb.txtとccc.txtの値のレコードを次のようなデータに上書きします。
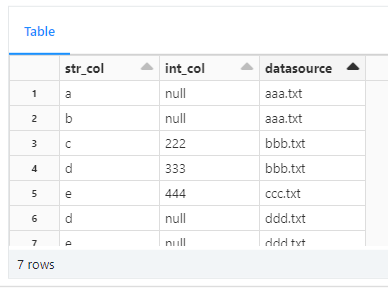
replaceWhere による選択的上書きを実施したところ、次のようにデータが上書きされました。
検証コード
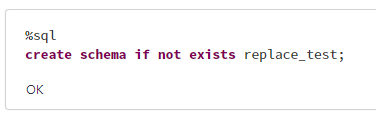
1. スキーマを作成
%sql
create schema if not exists replace_test;
2. テーブル作成と初期データの挿入
%sql
create or replace table replace_test.tbl_01
(
str_col string,
int_col int,
datasource string
);
INSERT INTO replace_test.tbl_01
(
str_col,
int_col,
datasource
)
SELECT 'a',NULL,'aaa.txt'
UNION ALL
SELECT 'b',NULL,'aaa.txt'
UNION ALL
SELECT NULL,NULL,'bbb.txt'
UNION ALL
SELECT NULL,NULL,'bbb.txt'
UNION ALL
SELECT NULL,NULL,'ccc.txt'
UNION ALL
SELECT 'd',NULL,'ddd.txt'
UNION ALL
SELECT 'e',NULL,'ddd.txt'
;
select * from replace_test.tbl_01;
3. 上書きデータを保持したデータフレームを作成
src_d = [
{
'str_col':'c',
'int_col':222,
'datasource':'bbb.txt'
},
{
'str_col':'d',
'int_col':333,
'datasource':'bbb.txt'
},
{
'str_col':'e',
'int_col':444,
'datasource':'ccc.txt'
},
]
src_s = """
str_col string,
int_col int,
datasource string
"""
df = spark.createDataFrame(src_d,src_s)
df.display()
4. replaceWhere による選択的上書きの実施と結果確認
(
df.write
.mode("overwrite")
.option("replaceWhere", 'datasource in ("bbb.txt","ccc.txt")')
.saveAsTable("replace_test.tbl_01"
)
)
spark.table("replace_test.tbl_01").display()
5. リソースの作成
%sql
drop schema replace_test cascade
