この記事は Snowflake Advent Calendar 2020 の9日目の記事です。
概要
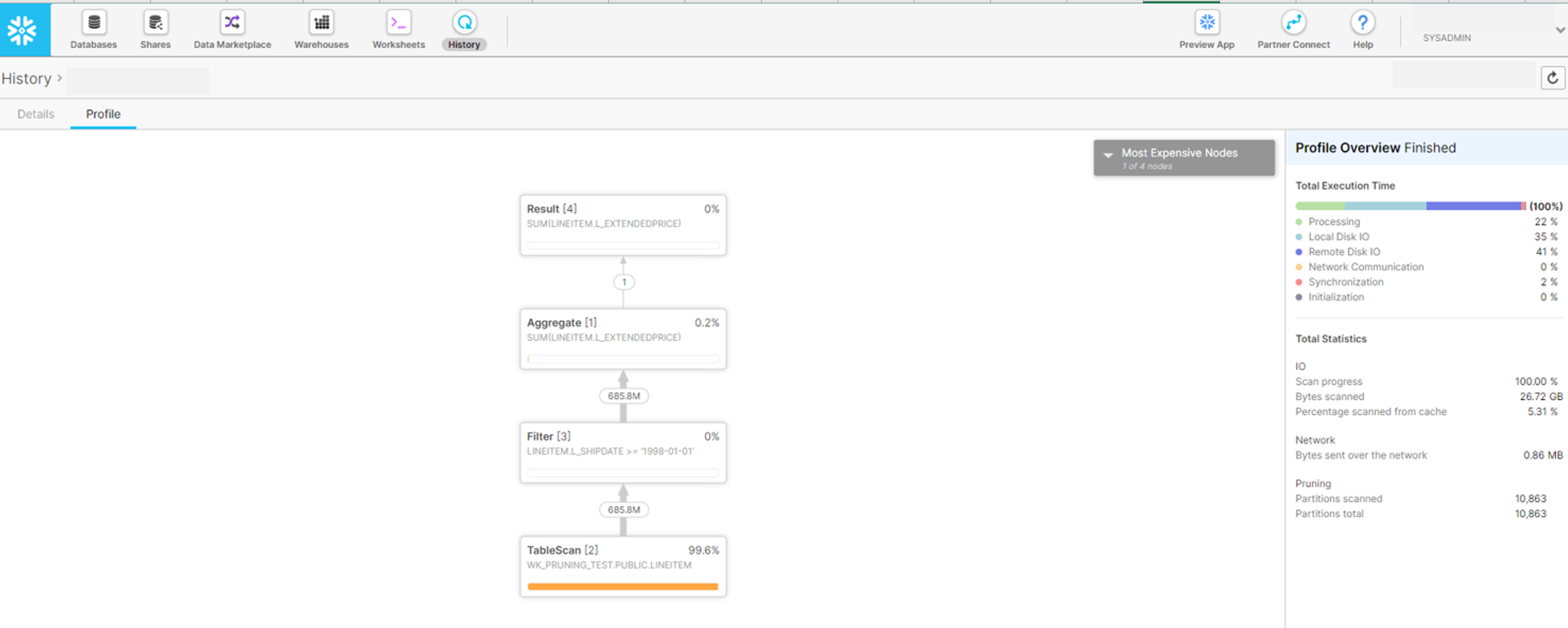
Snowflakeにてクエリプルーニング(クエリ実行時のパーテイション参照のスキップ)を行う要因となるクラスタリングキーの利用方法を紹介します。6億レコードのテーブルにて指定期間の集計を行うクエリで検証したところ、約10倍の性能向上を確認できました。
クラスタリングキーを設定しない場合の実行時間を基準とした実行時間の比率を含めた性能検証結果を下記表に示します。単一列にクラスタリングキーとして指定したほうがいいが、複数列でクラスタリングキーに設定しても向上されるようです。
| 番号 | 施策 | 実行時間の比率 | Partitions scanned | Bytes scanned |
|---|---|---|---|---|
| 1 | クラスタリングキーの設定なし | 1 | 10863 | 26.80GB |
| 2 | L_SHIPDATE列にクラスタリングキーを設定 | 10 | 1241 | 2.30GB |
| 3 | L_SHIPDATE列を含む複数列にクラスタリングキーを設定 | 7 | 1613 | 3.66GB |
結論
よく利用する大規模なファクトテーブルに対しては、利用する複数の日付列をクラスタリング列に設定したほうがよさそうです。ただし、自動クラスタリングにコストがかかるため、他頻度で更新するテーブルやあまり利用しないテーブルへ設定する場合に、コストメリットの考慮が必要です。
ドキュメントにおいても、日付列に設定が勧められております。
- 選択フィルターで最もアクティブに使用されるクラスタ列。日付ベースのクエリに関係する多くのファクトテーブル(例:WHERE invoice_date > x AND 請求日 <= y」)の場合、日付列を選択することをお勧めします。
クラスタリングキー
クラスタリングキーとは
ドキュメントにて下記のように説明されております。
クラスタリングキーは、同じ マイクロパーティション 内のテーブル内のデータを共存させるために明示的に指定されたテーブル(またはテーブル上の式)の列のサブセットです。
引用元:https://docs.snowflake.com/ja/user-guide/tables-clustering-keys.html#what-is-a-clustering-key
クラスタリングキーのメンテナンス
下記のドキュメントに記載がある通り、クラスタリングキーのメンテナンスは自動で実施されます。
自動クラスタリング — Snowflake Documentation
"AUTOMATIC_CLUSTERING"として課金されるようです。
なお、手動クラスタリングは実施できなくなったようです。
2020年5月現在、手動再クラスタリングはすべてのアカウントで廃止されました。
引用元:手動再クラスタリング--- 非推奨 — Snowflake Documentation
検証方法
1. 検証用データベースとテーブルを作成
CREATE OR REPLACE DATABASE WK_PRUNING_TEST;
USE WK_PRUNING_TEST;
Create or replace table LINEITEM (
L_ORDERKEY NUMBER(38,0)
,L_PARTKEY NUMBER(38,0)
,L_SUPPKEY NUMBER(38,0)
,L_LINENUMBER NUMBER(38,0)
,L_QUANTITY NUMBER(12,2)
,L_EXTENDEDPRICE NUMBER(12,2)
,L_DISCOUNT NUMBER(12,2)
,L_TAX NUMBER(12,2)
,L_RETURNFLAG VARCHAR(255)
,L_LINESTATUS VARCHAR(255)
,L_SHIPDATE DATE
,L_COMMITDATE DATE
,L_RECEIPTDATE DATE
,L_SHIPINSTRUCT VARCHAR(255)
,L_SHIPMODE VARCHAR(255)
,L_COMMENT VARCHAR(255)
);
/*
--下記コードは本番環境で実施しないようにしてください。
--検証のために、リザルトキャッシュ機能をオフにします。
use role accountadmin;
ALTER ACCOUNT SET USE_CACHED_RESULT = FALSE;
SHOW PARAMETERS LIKE '%USE_CACHED_RESULT%'
--検証完了後、リザルトキャッシュ機能をオンにします。
use role accountadmin;
ALTER ACCOUNT SET USE_CACHED_RESULT = TRUE;
SHOW PARAMETERS LIKE '%USE_CACHED_RESULT%'
*/
2. サンプルデータの取り込み
USE WK_PRUNING_TEST;
TRUNCATE TABLE LINEITEM;
INSERT INTO LINEITEM
SELECT
*
FROM
"SNOWFLAKE_SAMPLE_DATA"."TPCH_SF1000"."LINEITEM";
-- 5,999,989,709であることを確認
SELECT COUNT(*) FROM LINEITEM
3. 検証用テーブルの作成
CREATE OR REPLACE TABLE LINEITEM_CLONE_1 CLONE LINEITEM;
CREATE OR REPLACE TABLE LINEITEM_CLONE_2 CLONE LINEITEM;
4. 検証用テーブル1のL_SHIPDATE列にクラスタリングキーを設定
ALTER TABLE "PUBLIC"."LINEITEM_CLONE_1" CLUSTER BY (L_SHIPDATE);
--cluster_by列が、LINEAR(L_SHIPDATE)となっていることを確認
show tables like 'LINEITEM_CLONE_1';
5. 検証用テーブル2のL_COMMITDATE列、L_COMMITDATE列、L_SHIPDATE列にクラスタリングキーを設定
/*
--カーディナリティチェック
--Docsより、"低いカーディナリティ列の前に高いカーディナリティ列を配置すると、後者の列でのクラスタリングの有効性が低下します。"との記載あり
SELECT
approx_count_distinct(L_SHIPDATE)
,approx_count_distinct(L_COMMITDATE)
,approx_count_distinct(L_COMMITDATE)
FROM LINEITEM
;
*/
ALTER TABLE "PUBLIC"."LINEITEM_CLONE_2" CLUSTER BY (L_COMMITDATE,L_COMMITDATE,L_SHIPDATE) ;
--cluster_by列が、LINEAR(L_COMMITDATE,L_COMMITDATE,L_SHIPDATE)となっていることを確認
show tables like 'LINEITEM_CLONE_2';
6. 自動で再クラスタリグされるため、少し待機後、検証用クエリを実行
SELECT
SUM(L_EXTENDEDPRICE)
FROM
"PUBLIC"."LINEITEM"
WHERE L_SHIPDATE >= '1998-01-01'
;
SELECT
SUM(L_EXTENDEDPRICE)
FROM
"PUBLIC"."LINEITEM_CLONE_1"
WHERE L_SHIPDATE >= '1998-01-01'
;
SELECT
SUM(L_EXTENDEDPRICE)
FROM
"PUBLIC"."LINEITEM_CLONE_2"
WHERE L_SHIPDATE >= '1998-01-01'
;
7. Historyタブにてクエリの実行結果を確認