概要
Databricks にて特定のユーザーのみで一時的なファイル等をプログラムで利用する方法を共有します。この方法は、思いつきで検証しただけなので、リスクを許容できる場合にのみ利用してください。
部署別にデータを配置する方法がないかという相談をよくうけるのですが、DBFS 上にファイルを配置する方法か クラウドストレージ上に配置する方法のいずれかを紹介しております。前者は Databricks ワークスペース上のすべてのユーザーが操作できてしまうというデメリットがあり、後者にはストレージへの認証を実施する必要があるというデメリットがありました。

引用元:Databricks ファイル システム (DBFS) とは - Azure Databricks | Microsoft Learn
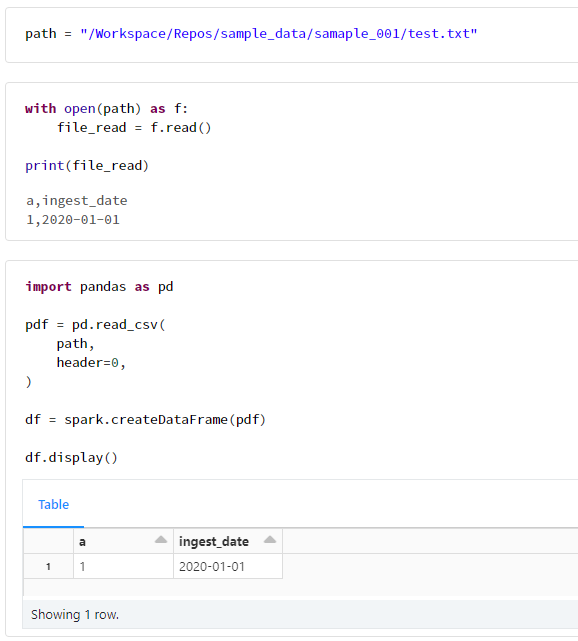
Databricks Repos 上に CSV ファイル等を配置する方法を検証したところ、想定の動作をしました。
Spark データフレームとして読み込もうとするとエラーとなるため、Pandas データフレームとして読み取り後に Spark データフレームとして読み込みました。

java.lang.SecurityException: Cannot use com.databricks.backend.daemon.driver.WorkspaceLocalFileSystem - local filesystem access is forbidden
Databricks Repos の仕様で、200MB がファイルサイズの上限があることや 30 日で削除されることなどの制約を受けることに注意してください。

引用元:Git と Databricks Repos の統合に関する制限事項と FAQ - Azure Databricks | Microsoft Learn

引用元:Git と Databricks Repos の統合に関する制限事項と FAQ - Azure Databricks | Microsoft Learn
今回の検証時に気づいたのですが、ディレクトリやファイルを作成することができるようになったようです。
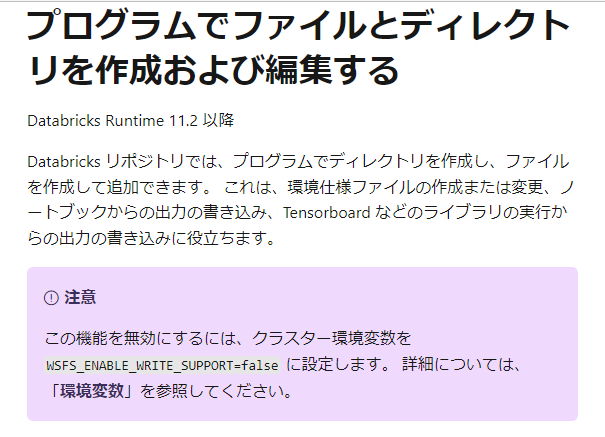
引用元:Azure Databricks Repos でノートブックとプロジェクト ファイルを操作する - Azure Databricks | Microsoft Learn
検証手順
0. 事前準備
0-1. Git レポジトリーと連携しない Repo を作成
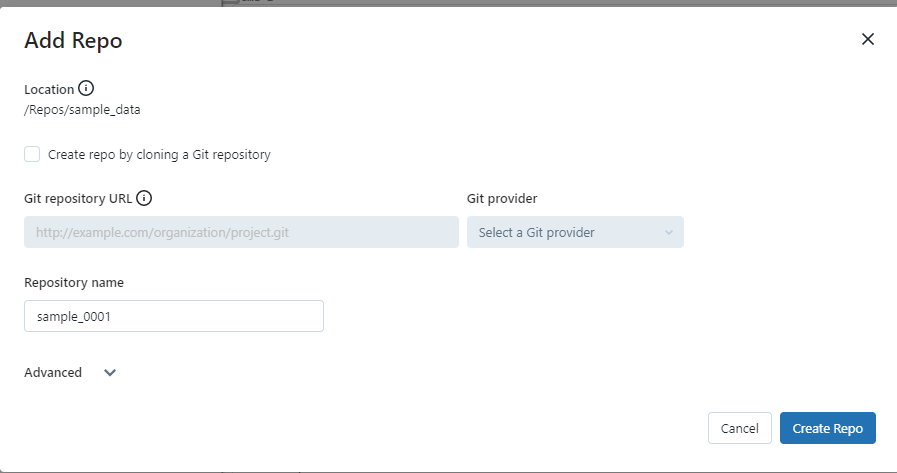
0-2. サンプルのデータをアップロード
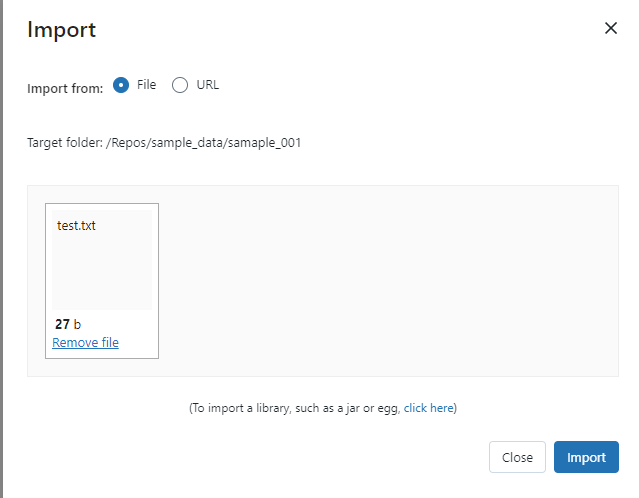
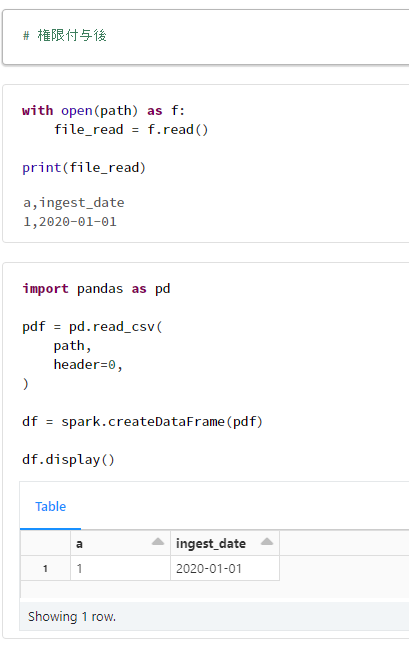
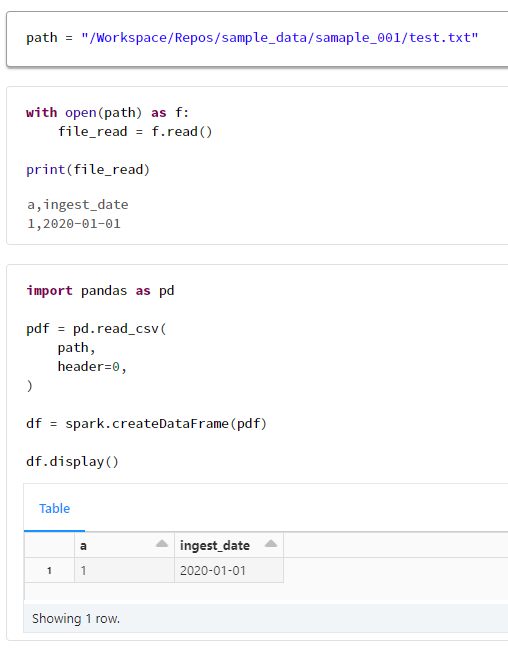
1. ユーザーA(Repos への参照権限があるユーザー)の動作確認
1-1. サンプルデータからデータフレームを作成できることを確認
path = "/Workspace/Repos/sample_data/samaple_001/test.txt"
with open(path) as f:
file_read = f.read()
print(file_read)
import pandas as pd
pdf = pd.read_csv(
path,
header=0,
)
df = spark.createDataFrame(pdf)
df.display()
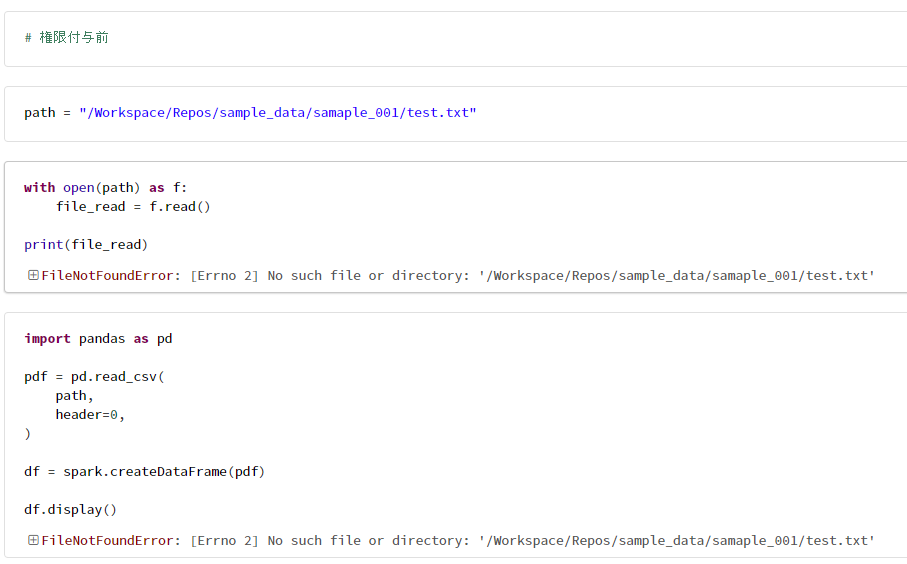
2. ユーザーB(Repos への参照権限がないユーザー)の動作確認
1-1. サンプルデータからデータフレームを作成できないことを確認
path = "/Workspace/Repos/sample_data/samaple_001/test.txt"
with open(path) as f:
file_read = f.read()
print(file_read)
import pandas as pd
pdf = pd.read_csv(
path,
header=0,
)
df = spark.createDataFrame(pdf)
df.display()
FileNotFoundError: [Errno 2] No such file or directory: '/Workspace/Repos/sample_data/samaple_001/test.txt'
3. ユーザーB(Repos への参照権限を付与したユーザー)の動作確認
3-1. ユーザーBに対してレポジトリの参照権限を付与
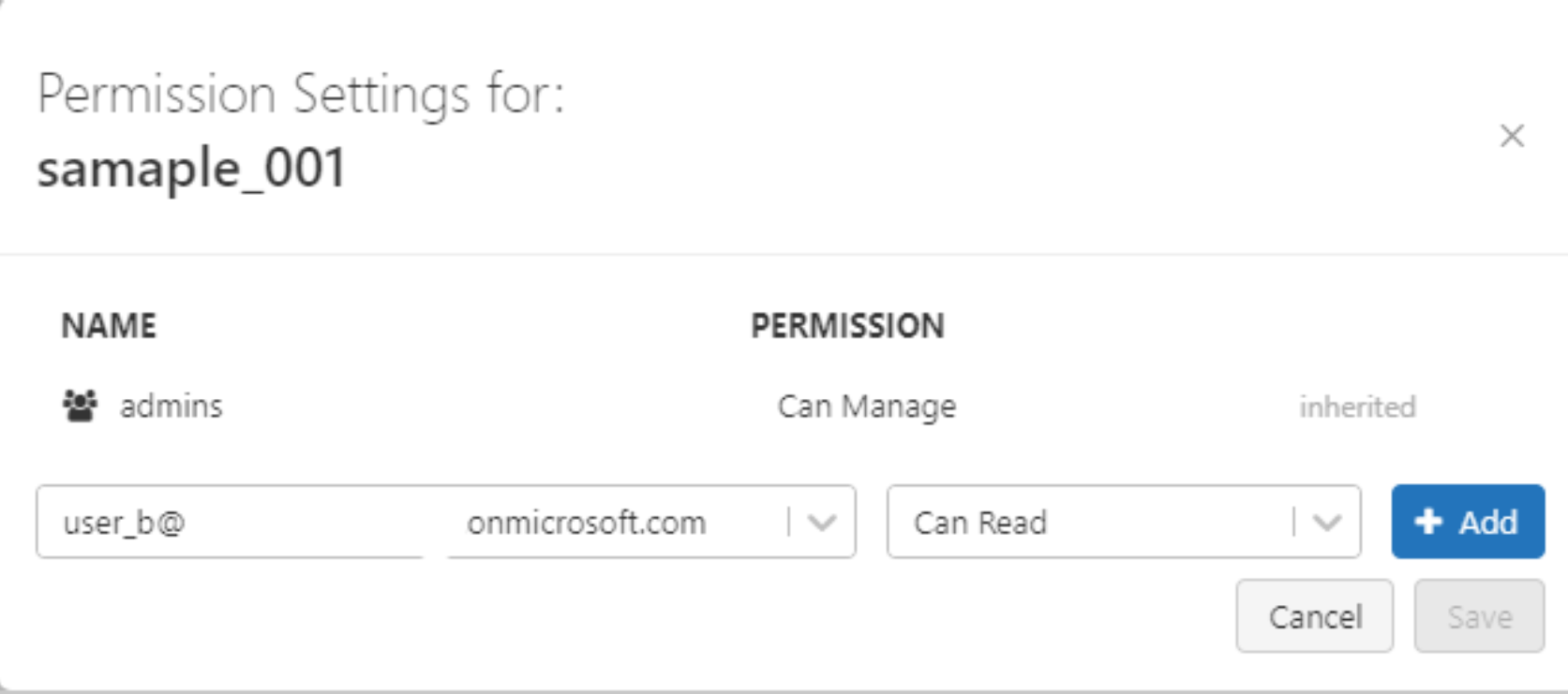
3-2. サンプルデータからデータフレームを作成できることを確認
path = "/Workspace/Repos/sample_data/samaple_001/test.txt"
with open(path) as f:
file_read = f.read()
print(file_read)
import pandas as pd
pdf = pd.read_csv(
path,
header=0,
)
df = spark.createDataFrame(pdf)
df.display()