概要
Databricksでは、タイムスタンプの文字列(例:2024-02-19 13:35:24)を扱う際、クラスターのタイムゾーン設定が重要となります。例えば、タイムスタンプのタイムゾーンがUTCであるにも関わらず、Sparkの設定(spark.sql.session.timeZone)がJSTになっていると、予期しない結果が生じる可能性があります。これを避けるための一つの戦略として、データエンジニアリングのフェーズでは全てのタイムゾーン処理をUTCで行い、BIツールなどでデータを参照する際に適切なタイムゾーンを設定するという方法があります。
Databricks(Spark)では、タイムスタンプ型のデータはタイムゾーン設定(例:JSTやAsia/Tokyo)を考慮します。つまり、設定されたタイムゾーンに基づいて、タイムスタンプに対してタイムゾーンのオフセットが適用されます。例えば、2020-01-01 00:00:00というタイムスタンプを取得しようとした場合、タイムゾーンがJSTに設定されていると、内部的には9時間加算され、2020-01-01 09:00:00として扱われます。これにより、元のタイムスタンプを正確に取得することができない状況が生じます。
この問題に対する解決策として、以下の2つの方法が考えられます。私は最初の方法を選択しました。これは、パラメータの数を増やすことなく、Sparkの設定(spark.sql.session.timeZone)とタイムスタンプの文字列の想定タイムゾーンを一致させることが、運用上最も簡単であったからです。
- Spark Conf のタイムゾーンに基づき変換する方法
- タイムスタンプの文字列とタイムゾーンを渡す方法
1. Spark Conf のタイムゾーンに基づき変換する方法には、次のコードにより渡されたタイムスタンプの文字列を設定したタイムゾーンのタイムスタンプの文字列に変換することで実施できます。
local_trigger_ts = spark.sql(
f"""
SELECT
date_format(
CAST(from_utc_timestamp('{trigger_ts}', current_timezone()) AS timestamp),
'yyyy-MM-dd HH:mm:ss'
)
"""
).first()[0]
print(local_trigger_ts)

本記事ではコード実行により仕様を確認した上で、対応方法のサンプルコードを提示します。
Databricks の仕様の確認
前提事項
タイムスタンプの文字列(2024-02-19 13:35:24)を渡すケースとして、次のようなケースがあります。1 のケースとしては監査列やフィルター条件などでタイムスタンプを指定する場合に利用することがあります。
- 外部からパラメータとしてタイムスタンプの文字列を渡すケース
- プログラム内でタイムスタンプの文字列を取得して渡されるケース
1. 外部からパラメータとしてタイムスタンプの文字列を渡す方法
trigger_ts = "2020-01-01 00:00:00"
import datetime
from pyspark.sql import Row
data = [
Row(id=1, timestamp_col=datetime.datetime(2020, 1, 1, 0, 0)),
Row(id=2, timestamp_col=datetime.datetime(2020, 2, 2, 0, 0)),
Row(id=3, timestamp_col=datetime.datetime(2020, 3, 2, 0, 0)),
]
df = spark.createDataFrame(data)
df = df.filter(f"timestamp_col = CAST('{trigger_ts}' AS timestamp)")
df.display()

プログラム内でタイムスタンプの文字列を取得する方法
プログラム内でタイムスタンプの文字列を取得する方法としては、次のような方法があります。
local_ts = spark.sql(
f"""
SELECT
date_format(
CAST(from_utc_timestamp('{trigger_ts}', current_timezone()) AS timestamp),
'yyyy-MM-dd HH:mm:ss'
)
"""
).first()[0]
print()
2024-02-20 04:32:29

タイムゾーン設定による想定外の動作
1. 外部からパラメータとしてタイムスタンプの文字列を渡すケースの想定外の動作
下記のコードに実行により、Sparkの設定(spark.sql.session.timeZone)をJSTに設定した場合、タイムゾーンがUTCであるデータに対するフィルタリングが正常に動作しなくなることが確認できます。具体的には、フィルタリングによって1レコードが抽出できるていましたが、データが一切抽出できなくなりました。これは、タイムゾーン設定がデータ抽出の結果に影響を与えるという、予期しない挙動を示しています。
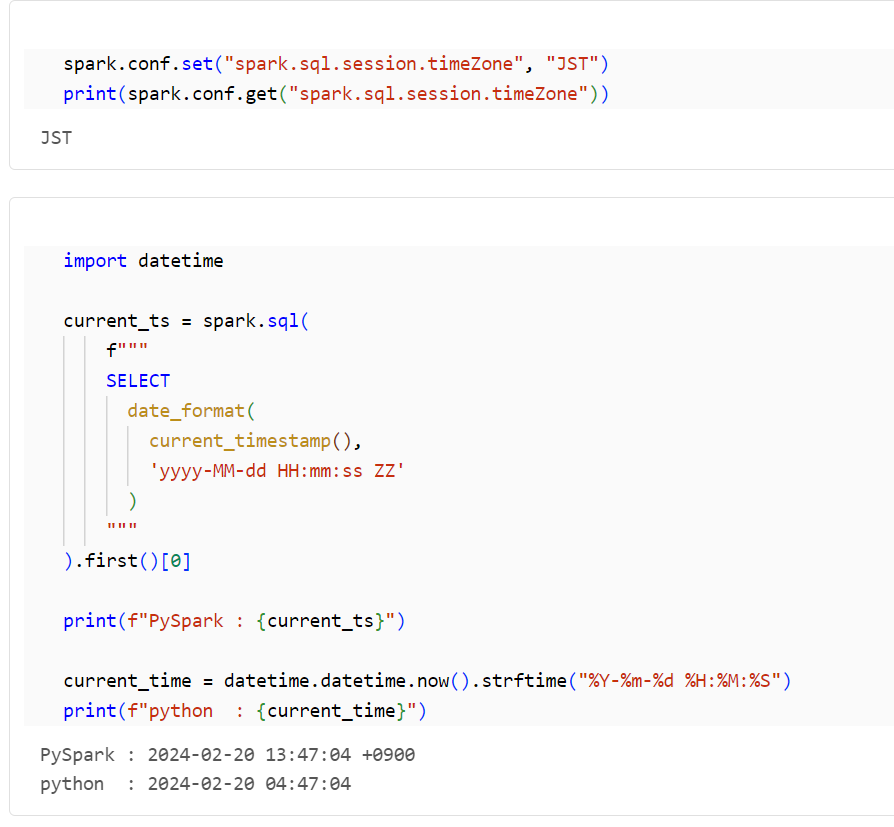
spark.conf.set("spark.sql.session.timeZone", "JST")
print(spark.conf.get("spark.sql.session.timeZone"))
trigger_ts = "2020-01-01 00:00:00"
import datetime
from pyspark.sql import Row
data = [
Row(id=1, timestamp_col=datetime.datetime(2020, 1, 1, 0, 0)),
Row(id=2, timestamp_col=datetime.datetime(2020, 2, 2, 0, 0)),
Row(id=3, timestamp_col=datetime.datetime(2020, 3, 2, 0, 0)),
]
df = spark.createDataFrame(data)
df = df.filter(f"timestamp_col = CAST('{trigger_ts}' AS timestamp)")
df.display()

2. プログラム内でタイムスタンプの文字列を取得して渡されるケースの想定外の動作
Pythonのdatetimeライブラリを使用してタイムスタンプの文字列を取得すると、予期しない結果が得られることがあります。以下のコードでは、タイムゾーンを変更した後のPySparkとdatetimeライブラリの結果を比較しています。Pythonでは、Sparkの設定(spark.sql.session.timeZone)の影響を受けず、UTCの時刻が表示されます。そのため、PySpark の処理で使用するタイムスタンプの文字列は、PySpark で取得する方が適切です。
import datetime
current_ts = spark.sql(
f"""
SELECT
date_format(
current_timestamp(),
'yyyy-MM-dd HH:mm:ss ZZ'
)
"""
).first()[0]
print(f"PySpark : {current_ts}")
current_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"python : {current_time}")
PySpark : 2024-02-20 13:45:52 +0900
python : 2024-02-20 04:45:52
タイムゾーン設定に対する
1-1. Spark Conf のタイムゾーンに基づき変換する方法
次の処理を追加することで、渡されたタイムスタンプの文字列を設定したタイムゾーンのタイムスタンプの文字列に変換します。
spark.conf.set("spark.sql.session.timeZone", "JST")
print(spark.conf.get("spark.sql.session.timeZone"))
trigger_ts = "2020-01-01 00:00:00"
local_trigger_ts = spark.sql(
f"""
SELECT
date_format(
CAST(from_utc_timestamp('{trigger_ts}', current_timezone()) AS timestamp),
'yyyy-MM-dd HH:mm:ss'
)
"""
).first()[0]
print(local_trigger_ts)
実施したデータ抽出処理が正常に動作し、期待通りの結果が得られました。これは、適切なタイムゾーン設定とデータ処理が行われたことを示しています。
import datetime
from pyspark.sql import Row
data = [
Row(id=1, timestamp_col=datetime.datetime(2020, 1, 1, 0, 0)),
Row(id=2, timestamp_col=datetime.datetime(2020, 2, 2, 0, 0)),
Row(id=3, timestamp_col=datetime.datetime(2020, 3, 2, 0, 0)),
]
df = spark.createDataFrame(data)
df = df.filter(f"timestamp_col = CAST('{local_trigger_ts}' AS timestamp)")
df.display()
1-2. タイムスタンプの文字列とタイムゾーンを渡す方法
このコードでは、タイムスタンプの文字列だけでなく、タイムゾーンもパラメータとして渡すようにしています。
trigger_ts = "2020-01-01 00:00:00"
trigger_tz = "JST"
このコードは、指定されたタイムスタンプとタイムゾーンを受け取り、それを現在のタイムゾーンに基づいたタイムスタンプの文字列に変換します。これにより、異なるタイムゾーンでの日時を一貫した形式で扱うことが可能になります。
spark.conf.set("spark.sql.session.timeZone", "JST")
print(spark.conf.get("spark.sql.session.timeZone"))
local_trigger_ts = spark.sql(
f"""
SELECT
date_format(
CAST(from_utc_timestamp('{trigger_ts}', '{trigger_tz}') AS timestamp),
'yyyy-MM-dd HH:mm:ss'
)
"""
).first()[0]
print(local_trigger_ts)
実施したデータ抽出処理が正常に動作し、期待通りの結果が得られました。これは、適切なタイムゾーン設定とデータ処理が行われたことを示しています。
import datetime
from pyspark.sql import Row
data = [
Row(id=1, timestamp_col=datetime.datetime(2020, 1, 1, 0, 0)),
Row(id=2, timestamp_col=datetime.datetime(2020, 2, 2, 0, 0)),
Row(id=3, timestamp_col=datetime.datetime(2020, 3, 2, 0, 0)),
]
df = spark.createDataFrame(data)
df = df.filter(f"timestamp_col = CAST('{local_trigger_ts}' AS timestamp)")
df.display()