概要
Databricks DLT の STREMIGN TABLE の処理にて CTAS が実施されたテーブルをソースとした際に発生する DIFFERENT_DELTA_TABLE_READ_BY_STREAMING_SOURCE エラーへの対応方法を共有します。
table_01 = "table_01"
@dlt.table(
name = table_01,
)
def customers_bronze_ingest_flow():
return (
spark.readStream.table(f"{catalog}.dlt_source_01.table_01")
)
org.apache.spark.sql.streaming.StreamingQueryException: [STREAM_FAILED] Query [id = 766d828a-ed98-430e-b880-895337ff75ff, runId = 34a0cd29-2085-4f6b-8c9d-2d279e7a7827] terminated with exception: [DIFFERENT_DELTA_TABLE_READ_BY_STREAMING_SOURCE] The streaming query was reading from an unexpected Delta table (id = 'd14151f7-b18c-40fa-bbfa-57e9d7ff147a').

対応方法としては下記です。CTAS の実行頻度に応じて対応方法を選択してください。
- Full refresh により処理を再実行する方法
- Materialized View に変更する方法
事前準備
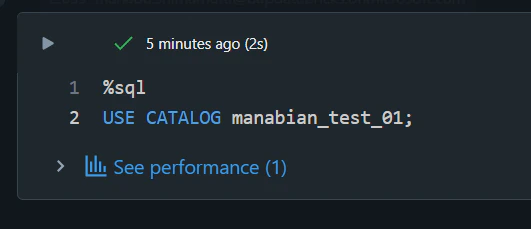
カレントカタログを変更
%sql
USE CATALOG manabian_test_01;
ソースのスキーマとテーブルを作成
%sql
CREATE SCHEMA IF NOT EXISTS dlt_source_01
%sql
CREATE OR REPLACE TABLE dlt_source_01.table_01
AS
SELECT
1 AS id,
'John' AS string_col;
SELECT * FROM dlt_source_01.table_01;

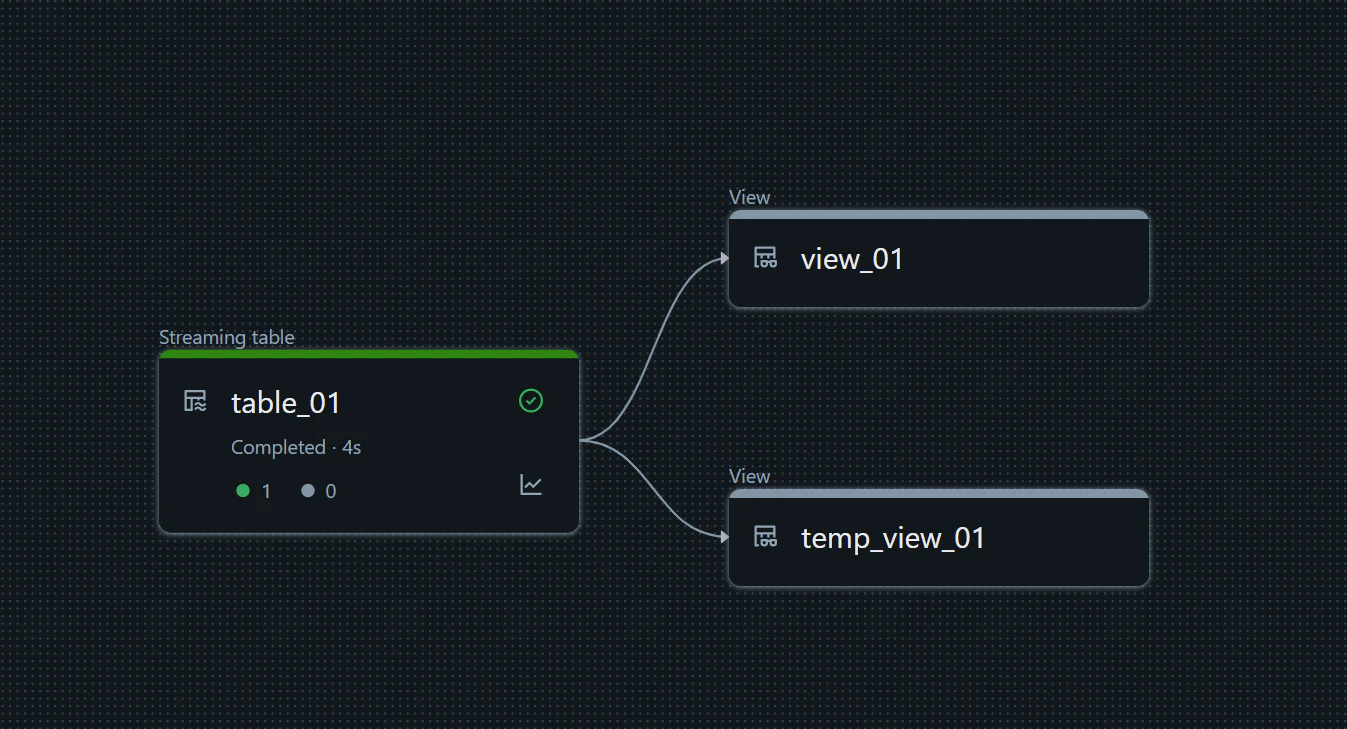
DLT にて初回の処理を実行
from dlt import *
from pyspark.sql.functions import *
catalog = "manabian_test_01"
# table_01 の処理
table_01 = "table_01"
@dlt.table(
name = table_01,
)
def customers_bronze_ingest_flow():
return (
spark.readStream.table(f"{catalog}.dlt_source_01.table_01")
)

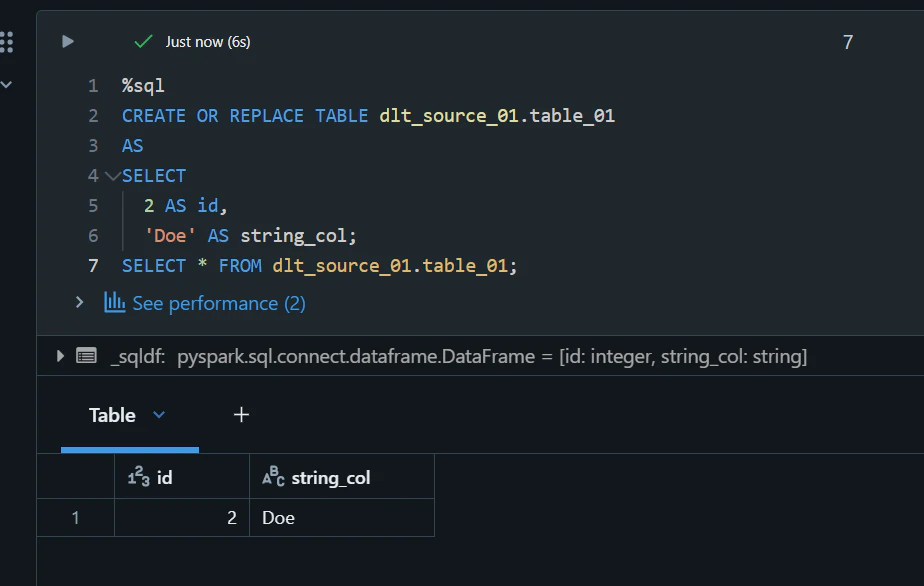
ソーステーブルに対する CTAS 処理の実行
%sql
CREATE OR REPLACE TABLE dlt_source_01.table_01
AS
SELECT
2 AS id,
'Doe' AS string_col;
SELECT * FROM dlt_source_01.table_01;
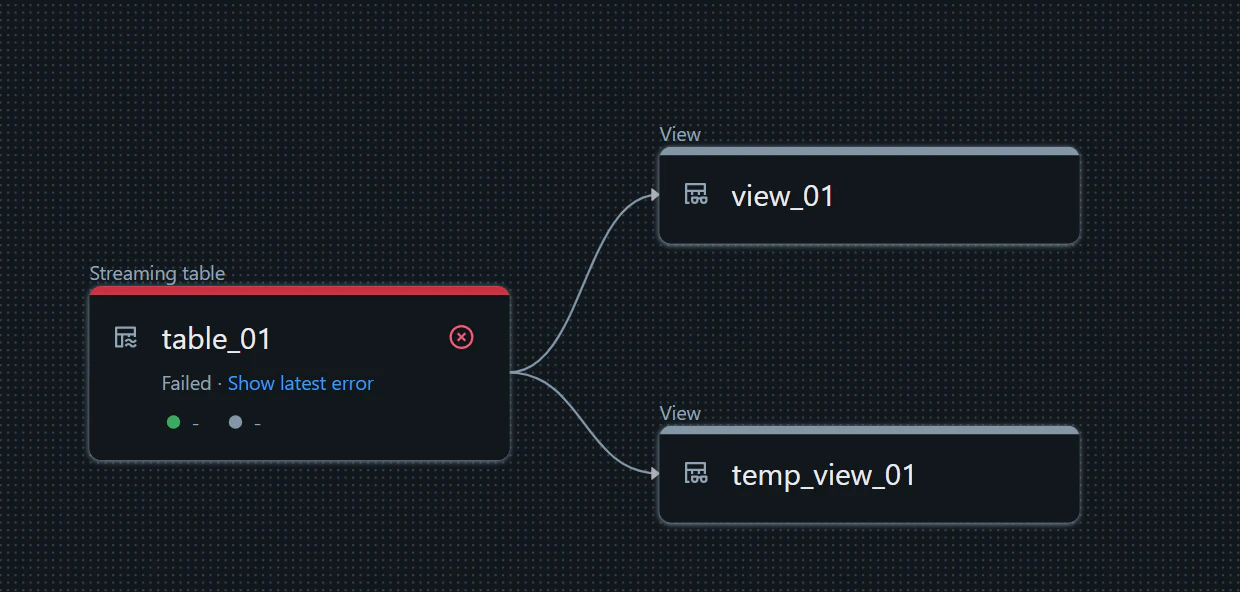
DLT のパイプラインを再実行してエラーとなることを確認
org.apache.spark.sql.streaming.StreamingQueryException: [STREAM_FAILED] Query [id = 766d828a-ed98-430e-b880-895337ff75ff, runId = 34a0cd29-2085-4f6b-8c9d-2d279e7a7827] terminated with exception: [DIFFERENT_DELTA_TABLE_READ_BY_STREAMING_SOURCE] The streaming query was reading from an unexpected Delta table (id = 'd14151f7-b18c-40fa-bbfa-57e9d7ff147a').
It used to read from another Delta table (id = 'b62c7c6a-c58f-44f4-b31f-d3679462ab7b') according to checkpoint.
This may happen when you changed the code to read from a new table or you deleted and
re-created a table. Please revert your change or delete your streaming query checkpoint
to restart from scratch. SQLSTATE: XXKST
=== Streaming Query ===
Identifier: manabian_test_01.dlt_test_01.__materialization_mat_ede7c5ed_6bd8_4172_abdc_0adabac2252c_table_01_1 [id = 766d828a-ed98-430e-b880-895337ff75ff, runId = 34a0cd29-2085-4f6b-8c9d-2d279e7a7827]
対応方法
1. Full refresh により処理を再実行する方法
エラーとなったオブジェクトを、 Full refresh により処理を実行します。
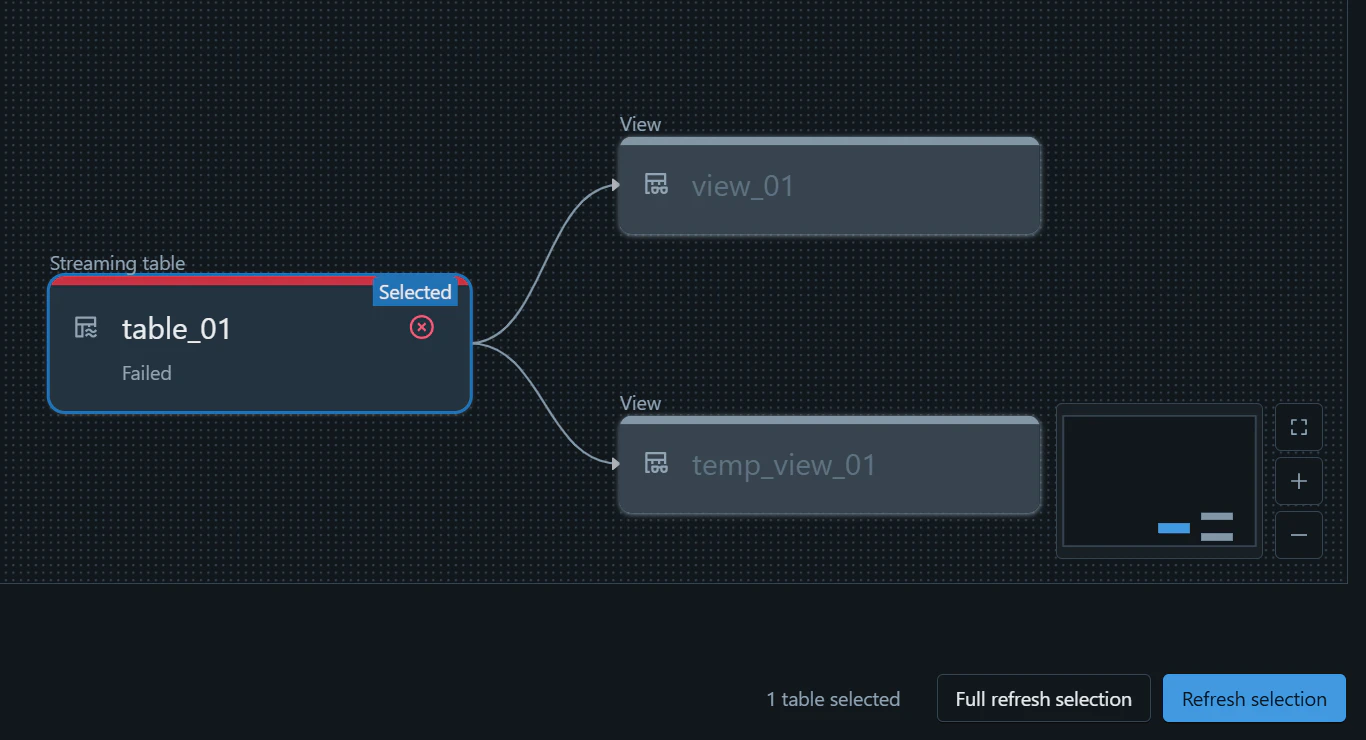

ソースのデータが書き込まれたことを確認します。

2. 1. Materialized View に変更する方法
既存の STREAMING TABLE を削除します。
%sql
DROP TABLE IF EXISTS manabian_test_01.dlt_test_01.table_01;

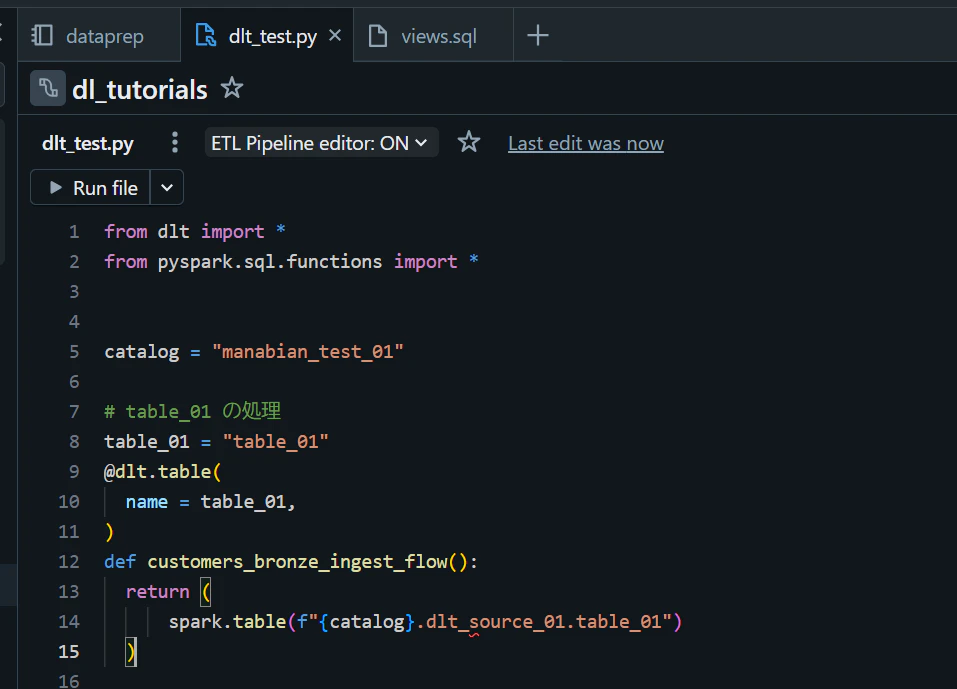
DLT のコードを Materialized View に変更して、処理を実行します。
from dlt import *
from pyspark.sql.functions import *
catalog = "manabian_test_01"
# table_01 の処理
table_01 = "table_01"
@dlt.table(
name = table_01,
)
def customers_bronze_ingest_flow():
return (
spark.table(f"{catalog}.dlt_source_01.table_01")
)

再度 CTAS を実行後に、 DLT の処理が正常に実行できることを確認します。
%sql
CREATE OR REPLACE TABLE dlt_source_01.table_01
AS
SELECT
3 AS id,
'Cat' AS string_col;
SELECT * FROM dlt_source_01.table_01;


