概要
PySparkにて階層されているStructTypeを単一のカラムにフラットする方法を共有します。
階層されているStructTypeとは、下記のデータフレームのstruct列のことです。
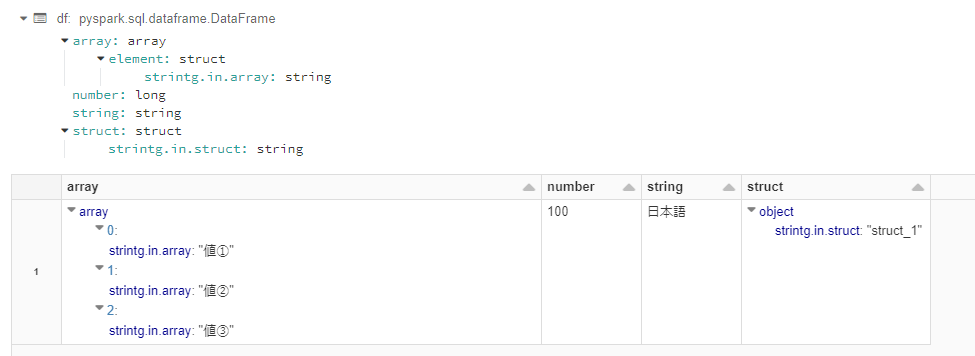
今回紹介するのは、structのカラムをstruct.strintg.in.structという単一のカラムにする方法です。
検証環境
databricks runtime: 8.3.x-cpu-ml-scala2.12
Python version: 3.8.8
pyspark version: 3.1.2.dev0
手順
1. データを準備
json_data ="""
{
"array":[
{ "strintg.in.array": "値①"},
{ "strintg.in.array": "値②"},
{ "strintg.in.array": "値③"}
],
"number":100,
"string":"日本語",
"struct":{
"strintg.in.struct": "struct_1"
},
}
"""
df = spark.read.json(sc.parallelize([json_data]))
df.display()
df.createOrReplaceTempView('tmp_nested_columns')
df.printSchema()
2. 関数を定義
def get_flatten_transformation(df:DataFrame, combine_str = '_'):
"""StructTypeの階層をフラット化
"""
cols=[col(e['name']).alias(e['renamed_column_name']) for e in _get_defination(df.schema.jsonValue(), combine_str=combine_str)]
return df.select(cols)
def _get_defination(schema:dict, prefix='', combine_str='_'):
"""Sparkデータフレームのスキーマを辞書の変数としてリターン値
"""
fields = schema['fields']
list_definations=[]
prefix = prefix+'.' if prefix !='' else ''
for field in fields:
if type(field['type']) is dict:
if field['type']['type'] == 'struct':
column_name_prefix = f'{prefix}`{field["name"]}`'
list_definations.extend(DataEngineering.get_defination(field['type'], column_name_prefix))
else:
field["name"] = f'{prefix}`{field["name"]}`'
field["renamed_column_name"] = f'{field["name"]}'.replace('.', combine_str).replace('`', '')
list_definations.append(field)
else:
field["name"] = f'{prefix}`{field["name"]}`'
field["renamed_column_name"] = f'{field["name"]}'.replace('.', combine_str).replace('`', '')
list_definations.append(field)
return list_definations
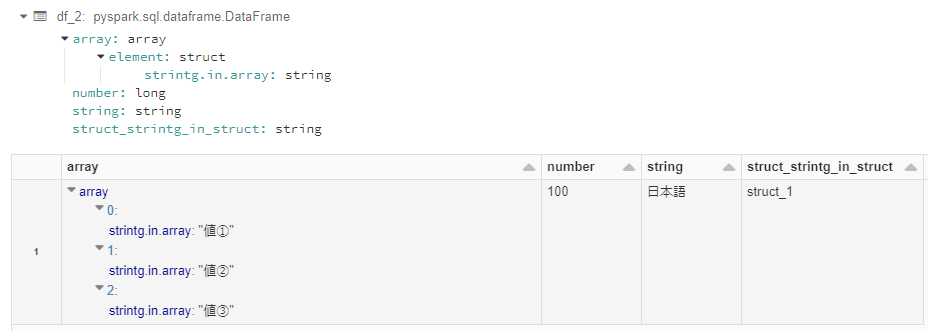
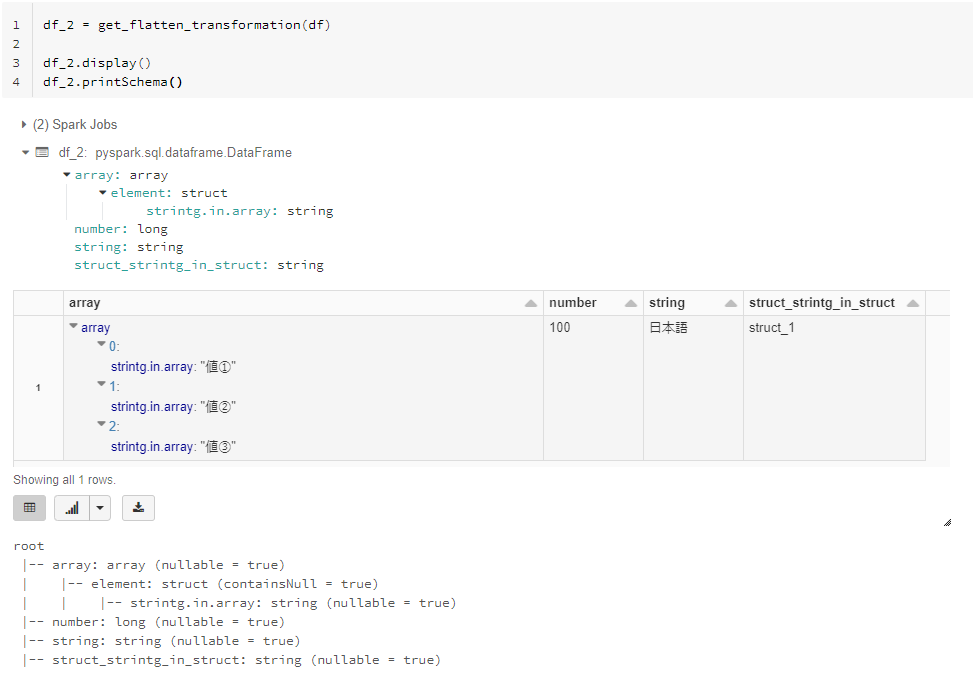
3. 階層されているStructTypeをフラット化
df_2 = get_flatten_transformation(df)
df_2.printSchema()
df_2.display()
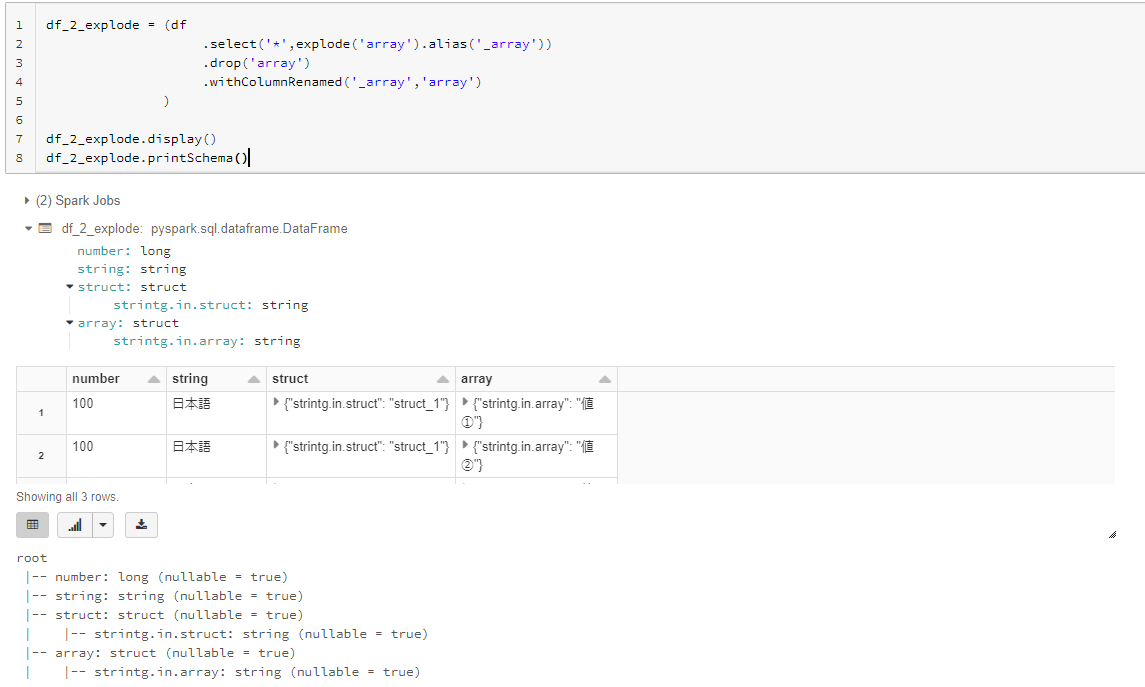
4. ArrayTypeのデータフレームをフラット化
# ArrayTypeをexplode関数によりStructTypeに変換
df_2_explode = (df
.select('*',explode('array').alias('_array'))
.drop('array')
.withColumnRenamed('_array','array')
)
df_2_explode.display()
df_2_explode.printSchema()