概要
Databricks にて一定期間のデータを上書きする処理する際のINGEST_TIMESTAMP列ごとに連携対象の期間のレコードを取得する方法を記述します。
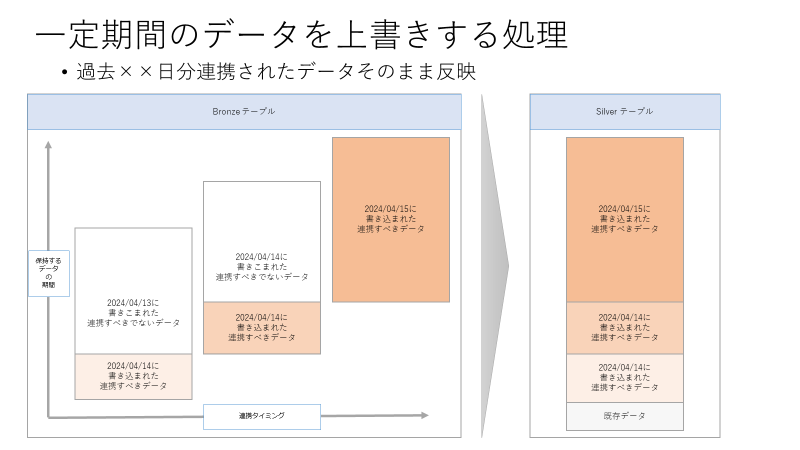
Bronze テーブルから Silver テーブルへのデータローディングパターンとして下記のような一定期間のデータを上書きする処理する方法の記述が抜けていたため、追記することとしました。ただし、その処理の一部としてINGEST_TIMESTAMP列ごとに連携対象の期間のレコードを取得する手順の文章が難解である本記事を補足記事として投稿します。
下記のデータで検証をしております。過去2日分のデータを上書きする場合には、inget_timestampが2024/1/3の場合には 2024/1/1 から 2024/1/3 が連携対象期間となります。inget_timestampが 2024/1/2 の場合には、 2024/1/2 から 2 日分減算した日付である 2023/12/31 から 2024/1/3の最小日である 2024/1/1 の前日である 2024/12/31 が連携対象期間となります。inget_timestampが 2024/1/1 の場合には、 2024/1/1 から 2 日分減算した日付である 2023/12/30 から 2024/1/2 の最小日である 2024/1/1 の前日である 2024/12/30 が連携対象期間となります。
[
{
"inget_timestamp": datetime.datetime(2024, 1, 3),
"min_date": datetime.date(2024, 1, 1),
"max_date": datetime.date(2024, 1, 3),
},
{
"inget_timestamp": datetime.datetime(2024, 1, 2),
"min_date": datetime.date(2023, 12, 31),
"max_date": datetime.date(2024, 1, 2),
},
{
"inget_timestamp": datetime.datetime(2024, 1, 1),
"min_date": datetime.date(2023, 12, 30),
"max_date": datetime.date(2024, 1, 1),
},
]
下記が想定結果です。上記のインプットからアウトプットを生成する関数を後述します。
[
{
"inget_timestamp": datetime.datetime(2024, 1, 3, 0, 0),
"min_date": datetime.date(2024, 1, 1),
"max_date": datetime.date(2024, 1, 3),
},
{
"inget_timestamp": datetime.datetime(2024, 1, 2, 0, 0),
"min_date": datetime.date(2023, 12, 31),
"max_date": datetime.date(2023, 12, 31),
},
{
"inget_timestamp": datetime.datetime(2024, 1, 1, 0, 0),
"min_date": datetime.date(2023, 12, 30),
"max_date": datetime.date(2023, 12, 30),
},
]
検証コードと実行結果
関数の概要
選択されたPython関数get_period_records_by_ingest_timestampは、特定の期間にわたるデータレコードを処理し、ソートして抽出するためのものです。この関数は、以下のステップで動作します:
1.パラメータ定義
-
date_ranges: 処理するデータレコードのリスト。 -
ingest_timestamp_col_name: タイムスタンプが格納されているカラムの名前。 -
watermark_col_type: タイムスタンプの型(日付またはタイムスタンプ)。 -
min_col_nameとmax_col_name: 処理する期間の最小値と最大値を格納するカラムの名前。 -
tgt_period_days: 対象とする期間の日数。 -
adjustment_unitとadjustment_value: 最大値の調整に使用する単位と値。 -
sort_reverse: リストを逆順にソートするかどうかのブール値。
2.ソート処理:
- 入力された [
date_ranges] リストを [ingest_timestamp_col_name] カラムの値に基づいてソートします。このソートは、[sort_reverse] パラメータに基づいて昇順または降順に行われます。
3.データ処理:
- ソートされたリストをループ処理し、各レコードに対して以下の処理を行います:
- 最初のレコードでは、最小値と最大値を計算し、出力リストに追加します。
- 2番目以降のレコードでは、現在のレコードの最小日が出力リストの最小日よりも小さい場合に限り、新たな最小値と最大値を計算し、出力リストに追加します。
4.出力:
- 処理されたデータレコードのリストを返します。各レコードは、
ingest_timestamp_col_name、min_col_name、max_col_nameの値を持つ辞書です。
この関数は、特定の期間にわたるデータの最小値と最大値を抽出し、それらを基にした新しいデータレコードのリストを作成するために使用されます。
関数を定義
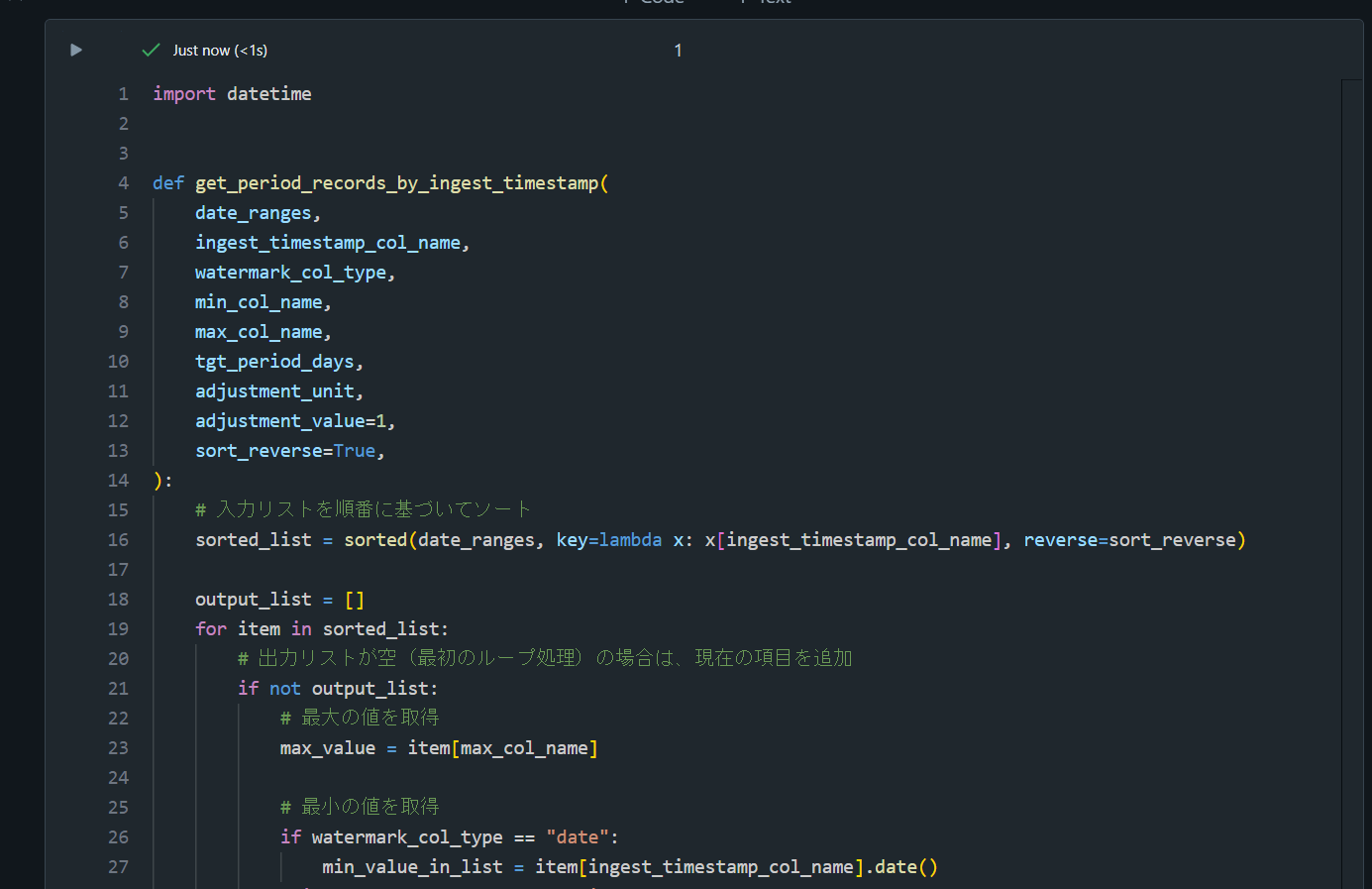
import datetime
def get_period_records_by_ingest_timestamp(
date_ranges,
ingest_timestamp_col_name,
watermark_col_type,
min_col_name,
max_col_name,
tgt_period_days,
adjustment_unit,
adjustment_value=1,
sort_reverse=True,
):
# 入力リストを順番に基づいてソート
sorted_list = sorted(date_ranges, key=lambda x: x[ingest_timestamp_col_name], reverse=sort_reverse)
output_list = []
for item in sorted_list:
# 出力リストが空(最初のループ処理)の場合は、現在の項目を追加
if not output_list:
# 最大の値を取得
max_value = item[max_col_name]
# 最小の値を取得
if watermark_col_type == "date":
min_value_in_list = item[ingest_timestamp_col_name].date()
elif watermark_col_type == "timestamp":
min_value_in_list = item[ingest_timestamp_col_name]
min_value_in_list = min_value_in_list - datetime.timedelta(days=tgt_period_days)
output_list.append(
{
ingest_timestamp_col_name: item[ingest_timestamp_col_name],
min_col_name: min_value_in_list,
max_col_name: max_value,
}
)
else:
# 現在の項目の最小日が、出力リストの最小日よりも小さい場合は、現在の項目を追加
if item[min_col_name] < min_value_in_list:
# 最大の値を取得
time_units_for_max_date = {
adjustment_unit: adjustment_value,
}
max_value = min_value_in_list - datetime.timedelta(**time_units_for_max_date)
# 最小の値を取得
if watermark_col_type == "date":
min_value_in_list = item[ingest_timestamp_col_name].date()
elif watermark_col_type == "timestamp":
min_value_in_list = item[ingest_timestamp_col_name]
min_value_in_list = min_value_in_list - datetime.timedelta(days=tgt_period_days)
output_list.append(
{
ingest_timestamp_col_name: item[ingest_timestamp_col_name],
min_col_name: min_value_in_list,
max_col_name: max_value,
}
)
return output_list
実行確認
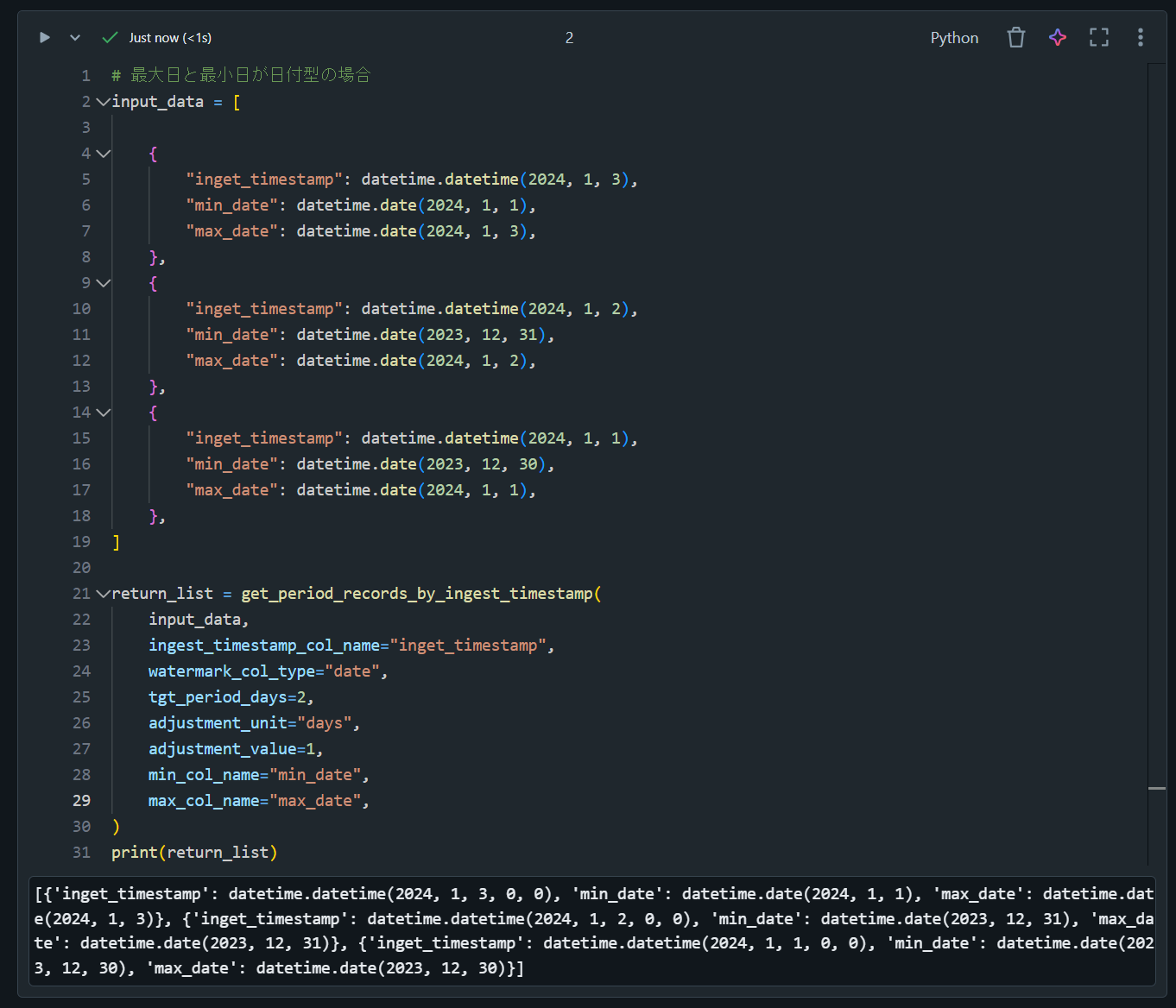
# 最大日と最小日が日付型の場合
input_data = [
{
"inget_timestamp": datetime.datetime(2024, 1, 3),
"min_date": datetime.date(2024, 1, 1),
"max_date": datetime.date(2024, 1, 3),
},
{
"inget_timestamp": datetime.datetime(2024, 1, 2),
"min_date": datetime.date(2023, 12, 31),
"max_date": datetime.date(2024, 1, 2),
},
{
"inget_timestamp": datetime.datetime(2024, 1, 1),
"min_date": datetime.date(2023, 12, 30),
"max_date": datetime.date(2024, 1, 1),
},
]
return_list = get_period_records_by_ingest_timestamp(
input_data,
ingest_timestamp_col_name="inget_timestamp",
watermark_col_type="date",
tgt_period_days=2,
adjustment_unit="days",
adjustment_value=1,
min_col_name="min_date",
max_col_name="max_date",
)
print(return_list)
[
{
"inget_timestamp": datetime.datetime(2024, 1, 3, 0, 0),
"min_date": datetime.date(2024, 1, 1),
"max_date": datetime.date(2024, 1, 3),
},
{
"inget_timestamp": datetime.datetime(2024, 1, 2, 0, 0),
"min_date": datetime.date(2023, 12, 31),
"max_date": datetime.date(2023, 12, 31),
},
{
"inget_timestamp": datetime.datetime(2024, 1, 1, 0, 0),
"min_date": datetime.date(2023, 12, 30),
"max_date": datetime.date(2023, 12, 30),
},
]