概要
Databricks にて Confluent から Protobuf 形式の Topic のデータ取得を手動でスキーマを指定して実施する方法を紹介します。
本記事は、以下のシリーズの一部です。

引用元:Databricks と Confluent をつなぐ:データ連携の全体像を徹底解説 #Spark - Qiita
事前準備
1. Confluent にて Topic を作成
syntax = "proto3";
package ksql;
message users {
int64 registertime = 1;
string userid = 2;
string regionid = 3;
string gender = 4;
}

2. Confluent にて API キーを主塔

3. Databricks 上でノートブックと同じ階層のディレクトリにuser.protoファイルを作成
syntax = "proto3";
package ksql;
message users {
int64 registertime = 1;
string userid = 2;
string regionid = 3;
string gender = 4;
}
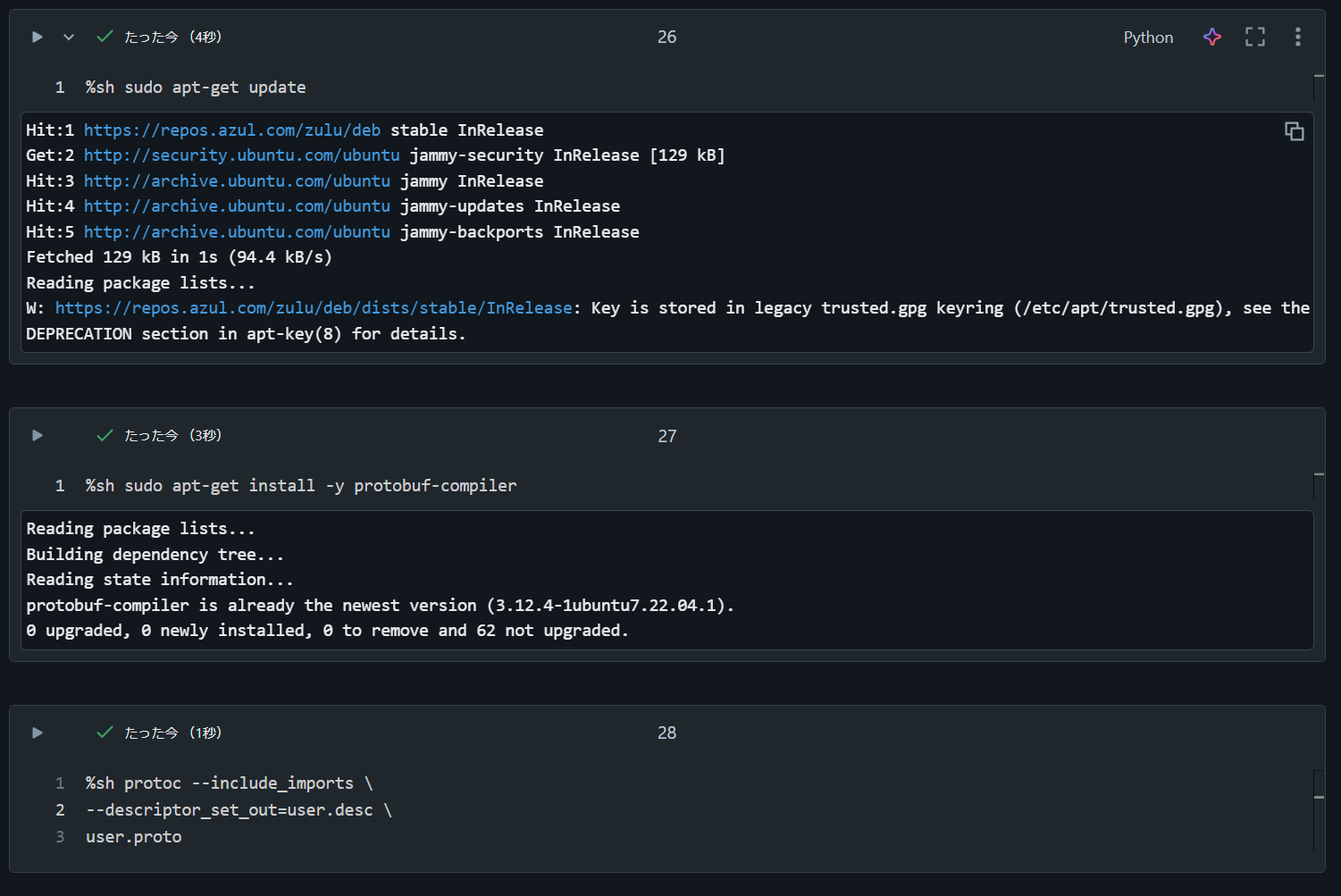
4. Databricks 上でuser.descファイルを生成
%sh sudo apt-get update
%sh sudo apt-get install -y protobuf-compiler
%sh protoc --include_imports \
--descriptor_set_out=user.desc \
user.proto
データを取得する手順
1. Databricks 上で API キーを変数にセット
# Confluent に対する認証情報をセット
bootstrap_servers = "pkc-921aa.us-east-2.aws.confluent.cloud:9092"
sasl_username = "U4BML4OPRCaaaa"
sasl_password = "zzEjUzyUwYYJneNE240L7jgPVrHAtRBANo6wnnzCgKlGIJ9OxJqaJZWRvaaaaa"

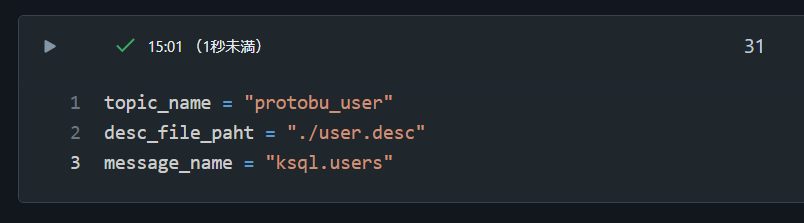
2. Topic 名と Desc ファイルに関する情報を変数にセット
topic_name = "protobu_user"
desc_file_paht = "./user.desc"
message_name = "ksql.users"
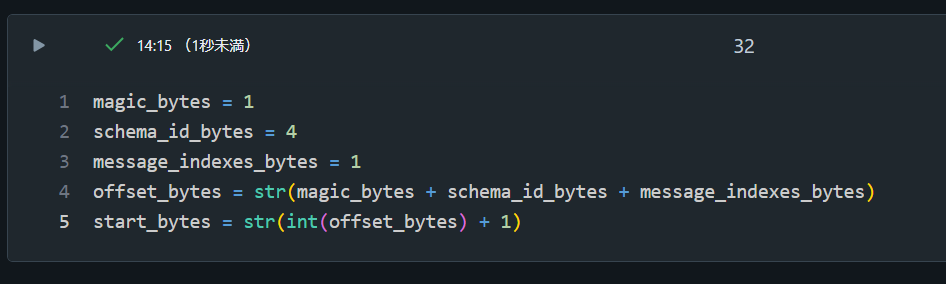
3. 除外するバイト数を変数にセット
magic_bytes = 1
schema_id_bytes = 4
message_indexes_bytes = 1
offset_bytes = str(magic_bytes + schema_id_bytes + message_indexes_bytes)
start_bytes = str(int(offset_bytes) + 1)
4. Condluent からデータを取得
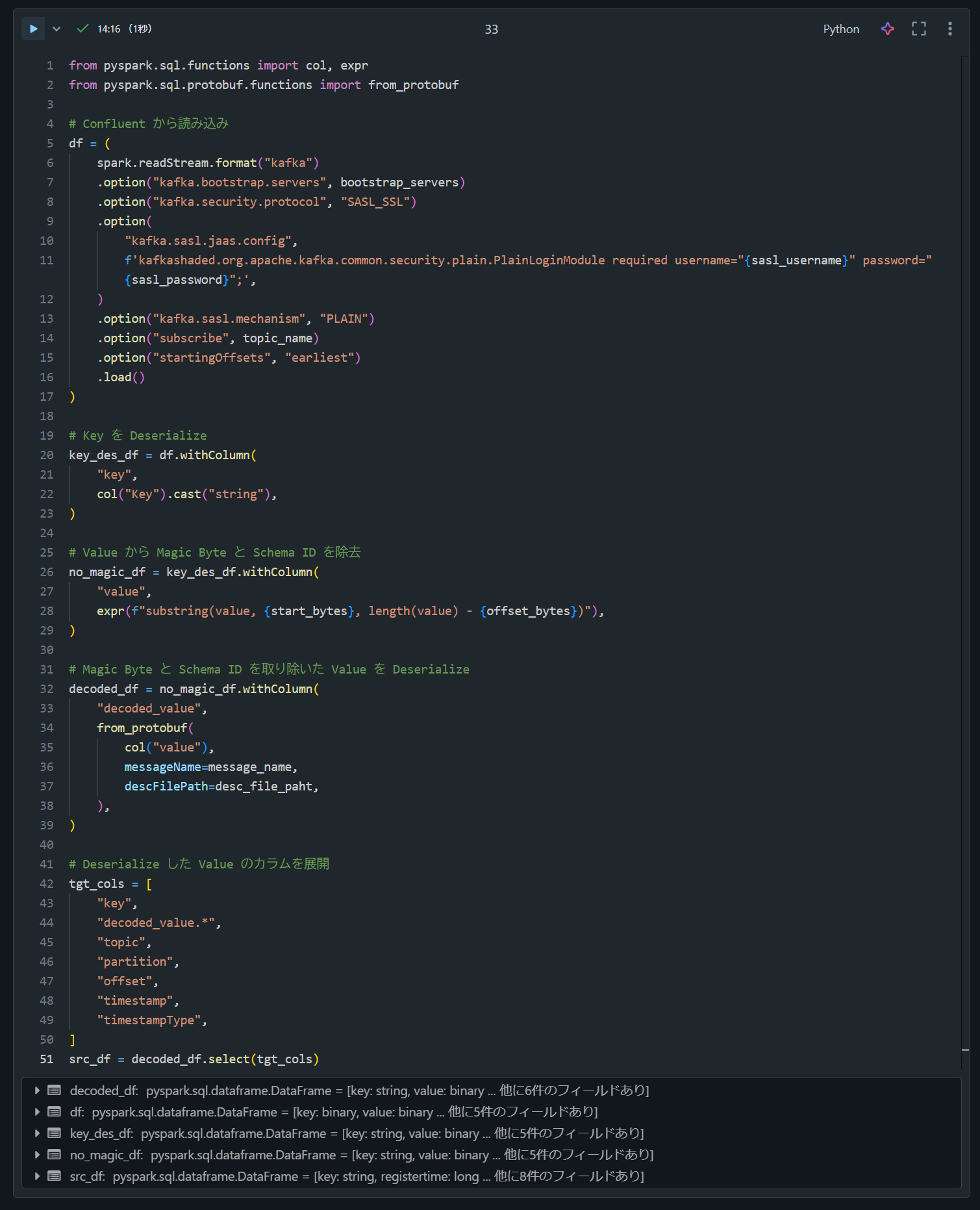
from pyspark.sql.functions import col, expr
from pyspark.sql.protobuf.functions import from_protobuf
# Confluent から読み込み
df = (
spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", bootstrap_servers)
.option("kafka.security.protocol", "SASL_SSL")
.option(
"kafka.sasl.jaas.config",
f'kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username="{sasl_username}" password="{sasl_password}";',
)
.option("kafka.sasl.mechanism", "PLAIN")
.option("subscribe", topic_name)
.option("startingOffsets", "earliest")
.load()
)
# Key を Deserialize
key_des_df = df.withColumn(
"key",
col("Key").cast("string"),
)
# Value から Magic Byte と Schema ID を除去
no_magic_df = key_des_df.withColumn(
"value",
expr(f"substring(value, {start_bytes}, length(value) - {offset_bytes})"),
)
# Magic Byte と Schema ID を取り除いた Value を Deserialize
decoded_df = no_magic_df.withColumn(
"decoded_value",
from_protobuf(
col("value"),
messageName=message_name,
descFilePath=desc_file_paht,
),
)
# Deserialize した Value のカラムを展開
tgt_cols = [
"key",
"decoded_value.*",
"topic",
"partition",
"offset",
"timestamp",
"timestampType",
]
src_df = decoded_df.select(tgt_cols)
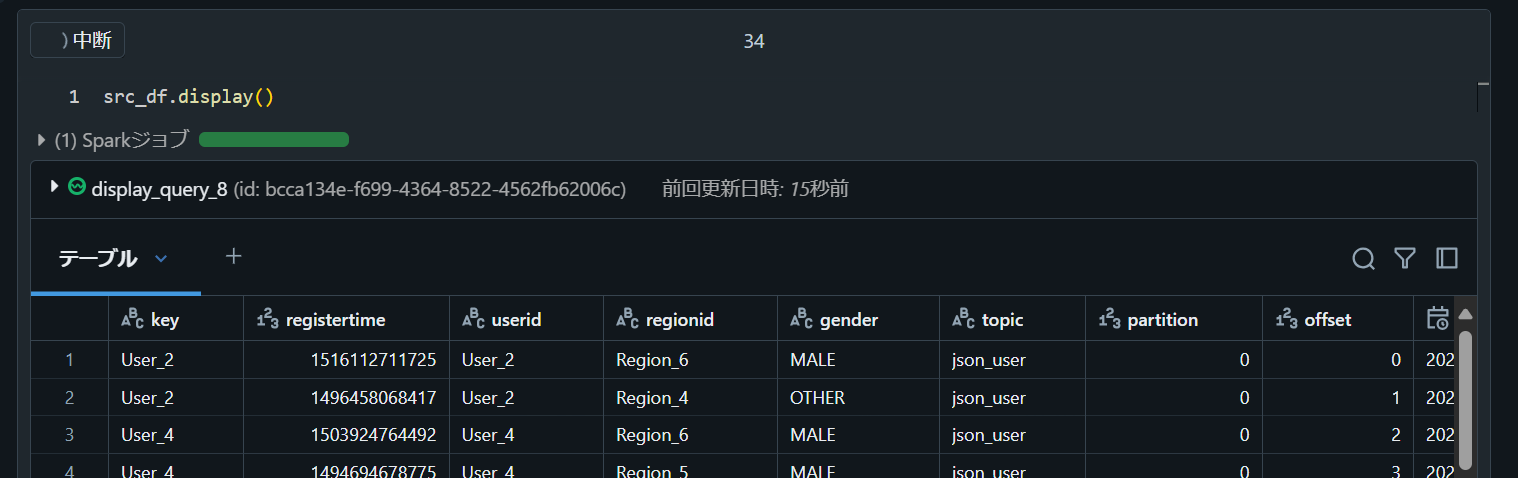
5. データを表示
src_df.display()
事後処理
Databricks ノートブックの実行を停止
