概要
本記事では、Databricks 上で Hadoop Catalog を利用して Apache Iceberg(以下、Iceberg)を扱う基本的な手順を紹介します。ただし、ここで紹介する内容は Databricks 上で Iceberg を推奨することを目的としたものではありません。
なお、Iceberg ではテーブルを管理するためのカタログが必須となりますが、今回の検証ではストレージだけで完結する Hadoop Catalog を用いています。

いくつかの操作は Databricks の仕様上エラーとなりましたが、そのまま掲載しています。Apache Iceberg は複数のサービスで動作することを想定していますが、実際にはサービスベンダーが機能をサポート・保証しているかを確認する必要があります。Spark ベースのプラットフォームであっても必ずしも動作が保証されるわけではないので、利用する際には必ず検証を行うことをおすすめします。
クラスターの作成
クラスターの設定について
Databricks 上で Apache Iceberg を動かすには、以下のような設定を行ったクラスターを用意する必要があります。
- Databricks Runtime のバージョンを 12.2LTS 以前にすること
- アクセスモードを分離なし共有(Uniyt Catalog 利用不可のモード」)にすること
- Java 8 に対応したライブラリ(Iceberg 1.6.1 以前のライブラリ)を利用すること
- Spark 構成に Iceberg 関連の設定を実施
これらの設定にたどり着くまでに、以下のようなエラーに遭遇しました(参考リンク参照):
- Databricks 上で Hadoop Catalog により Apache Iceberg を実行する際の Failed to find data source: ICEBERG への対応方法 #Spark - Qiita
- Databricks 上で Hadoop Catalog により Apache Iceberg を実行する際の Multiple sources found for ICEBERG #Spark - Qiita
- Databricks 上で Hadoop Catalog により Apache Iceberg を実行する際の Java のバージョンによるエラーへの対応方法 #Spark - Qiita
クラスター構築時の設定
1. Databricks Runtime にて 12.2 を選択
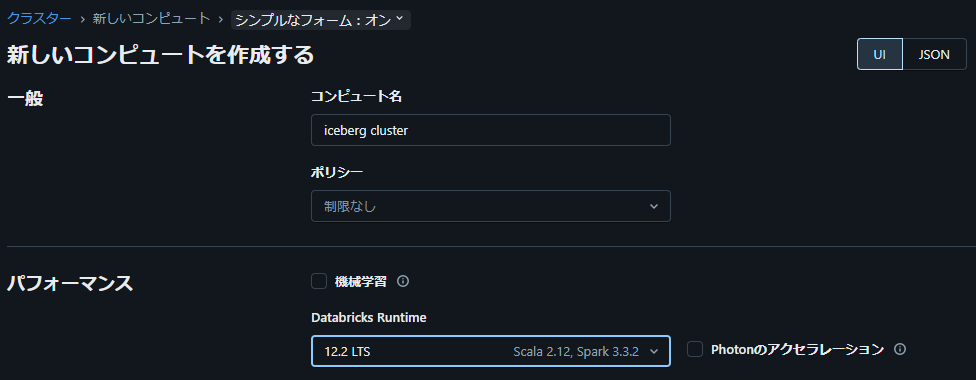
2. アクセスモードを「分離なし共有」に設定
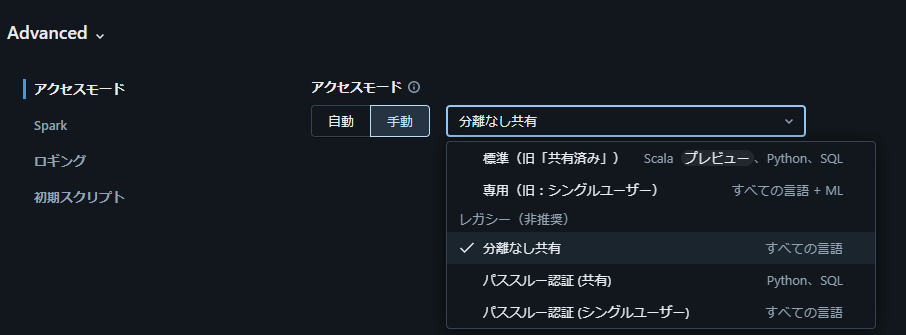
3. Spark 構成に Iceberg 関連の設定を追加
spark.sql.catalog.spark_catalog.warehouse に指定したディレクトリに、テーブルのデータが書き込まれます。
spark.sql.catalog.spark_catalog = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.spark_catalog.type = hadoop
spark.sql.catalog.spark_catalog.warehouse = dbfs:/Iceberg
spark.sql.extensions = org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions

4. Iceberg 関連ライブラリ (org.apache.iceberg:iceberg-spark-runtime-3.3_2.13:1.6.1) をインストール
クラスターの「ライブラリ」タブで「新規インストール」を選択し、「ライブラリをインストール」ウィンドウから「Maven」を選びます。
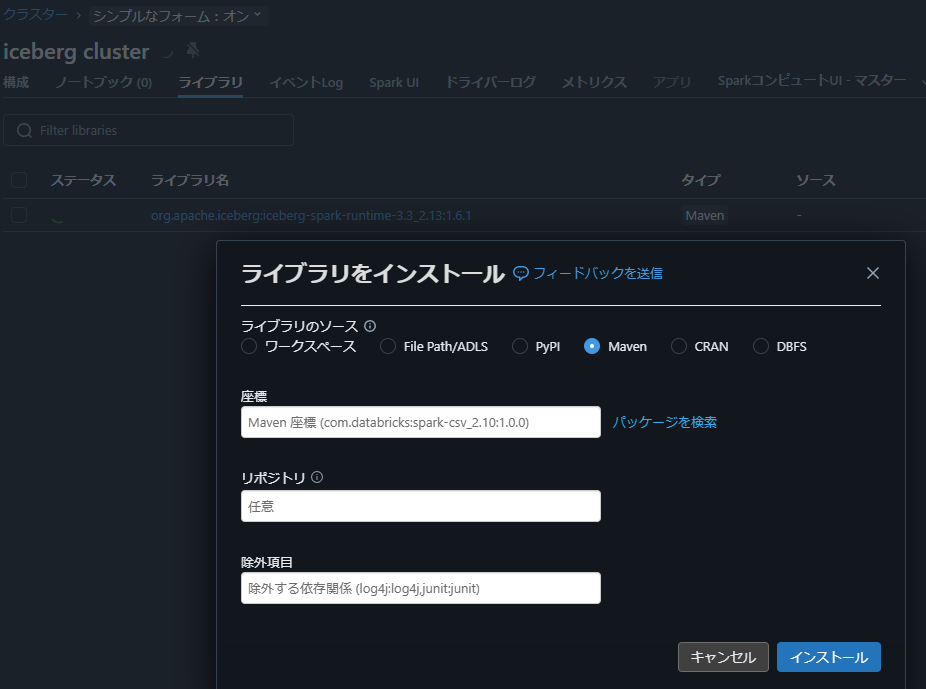
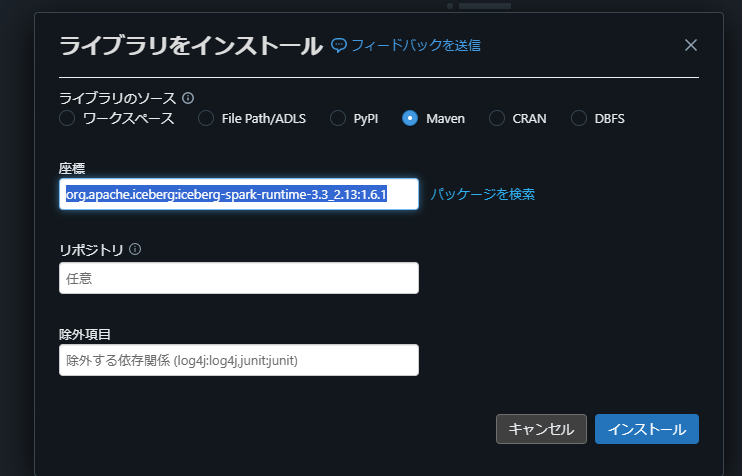
org.apache.iceberg iceberg-spark-runtime と入力すると、バージョン一覧が表示されます。ここでは org.apache.iceberg:iceberg-spark-runtime-3.3_2.13 の 1.6.1 を選択します。

org.apache.iceberg:iceberg-spark-runtime-3.3_2.13:1.6.1 であることを確認して「インストール」を選択します。
Apache Iceberg の基本的な操作
1. Namespace の作成
CREATE NAMESPACE 文の実行
Iceberg 用のデータベース(Namespace)を作成します。
-- データベース(Namespace)を作成する
CREATE NAMESPACE IF NOT EXISTS iceberg_demo;

iceberg_demo ディレクトリが作成されたことを確認
以下の Python コードを実行すると、Spark の設定から warehouse ディレクトリのパスを取得し、その中に作成された Namespace 用ディレクトリをリストで確認できます。dbfs:/Iceberg 配下に iceberg_demo ディレクトリができていれば OK です。
%python
wh_dir = spark.conf.get("spark.sql.catalog.spark_catalog.warehouse")
display(dbutils.fs.ls(wh_dir))

2. テーブルの作成
CREATE TABLE 文の実行
先ほど作成した Namespace 内に first_table を作成します。
CREATE OR REPLACE TABLE iceberg_demo.first_table(
id INT,
name STRING,
value INT
)
USING iceberg;
first_table ディレクトリが作成されたことを確認
Namespace 内にテーブル用ディレクトリが追加されているか、以下のコードで確認します。
%python
wh_dir = spark.conf.get("spark.sql.catalog.spark_catalog.warehouse")
namspace_name = "iceberg_demo"
table_data_dir = f"{wh_dir}/{namspace_name}"
display(dbutils.fs.ls(table_data_dir))

3. データの書き込み
INSERT 文の実行
first_table にデータを挿入します。
INSERT INTO
iceberg_demo.first_table (id, name, value)
VALUES (1, 'sample', 100), (2, 'example', 200);
SELECT
*
FROM
iceberg_demo.first_table

UPDATE 文の実行
下記のように UPDATE を実行するとエラーになります。
UPDATE
iceberg_demo.first_table
SET
value = 150
WHERE
id = 1;
DeltaAnalysisException: UPDATE destination only supports Delta sources.
Some(RelationV2[id#108, name#109, value#110] spark_catalog.iceberg_demo.first_table spark_catalog.iceberg_demo.first_table )

DELETE 文の実行
id が 2 のレコードを削除します。
DELETE FROM
iceberg_demo.first_table
WHERE
id = 2;
SELECT
*
FROM
iceberg_demo.first_table

MERGE 文
下記のような MERGE 文を実行するとエラーになります。
-- 書き込み用データを準備
CREATE OR REPLACE TEMPORARY VIEW updates_table AS
SELECT
1 AS id,
'updated_sample' AS name,
200 AS value
UNION ALL
SELECT
3 AS id,
'new_entry' AS name,
300 AS value;
MERGE INTO
iceberg_demo.first_table AS target
USING
updates_table AS source
ON
target.id = source.id
WHEN MATCHED THEN UPDATE SET target.name = source.name, target.value = source.value
WHEN NOT MATCHED THEN INSERT (id, name, value) VALUES (source.id, source.name, source.value);
DeltaAnalysisException: MERGE destination only supports Delta sources.
TRUNCATE TABLE 文
テーブル内の全データを削除します。
TRUNCATE TABLE iceberg_demo.first_table;
SELECT
*
FROM
iceberg_demo.first_table

4. タイムトラベル
事前準備
タイムトラベルを確認するため、新しいテーブルを作成し、2 回に分けてデータを挿入します。
CREATE OR REPLACE TABLE iceberg_demo.timestravel(
id INT,
data STRING
)
USING iceberg;
INSERT INTO
iceberg_demo.timestravel
VALUES (1, 'first'), (2, 'first');
INSERT INTO
iceberg_demo.timestravel
VALUES (3, 'second'), (4, 'second');

snapshot-id の取得
Iceberg でテーブルの履歴を確認するための SQL は Databricks 上でエラーになります。
SELECT
*
FROM
iceberg_demo.timestravel.history;
そのためテーブルのディレクトリにある metadata ファイルを直接表示し、1 回目の INSERT で生成された snapshot-id (例: 5355881699654019663) を取得します。
%python
wh_dir = spark.conf.get("spark.sql.catalog.spark_catalog.warehouse")
namspace_name = "iceberg_demo"
table_name = "timestravel"
table_data_dir = f"{wh_dir}/{namspace_name}/{table_name}/metadata/v2.metadata.json"
print(dbutils.fs.head(table_data_dir))

snapshot-id を指定したクエリの実行
取得した snapshot-id を VERSION AS OF の後に指定して実行します。
SELECT
*
FROM
iceberg_demo.timestravel VERSION AS OF 5355881699654019663
SELECT
*
FROM
iceberg_demo.timestravel;

5. スキーマ進化(Schema Evolution)
事前準備
スキーマ進化を試すためのテーブルを作成します。
CREATE OR REPLACE TABLE iceberg_demo.schema_evo(
id BIGINT,
product STRING,
quantity INT,
price DECIMAL(10, 2)
)
USING iceberg;
カラムの追加
既存テーブルに新しいカラム new_col を追加します。
ALTER TABLE
iceberg_demo.schema_evo
ADD
COLUMNS (
new_col STRING
COMMENT '新しく追加するカラム'
);
DESC iceberg_demo.schema_evo;

カラムの削除
先ほど追加した new_col を削除します。
ALTER TABLE
iceberg_demo.schema_evo
DROP COLUMNS (
new_col
);
DESC iceberg_demo.schema_evo;

カラム名の変更
カラム名を変更します。
ALTER TABLE
iceberg_demo.schema_evo
RENAME COLUMN
id
TO
`アイディ`;
DESC iceberg_demo.schema_evo;

カラムのデータ型変更
既存カラムのデータ型を変更します。
ALTER TABLE
iceberg_demo.schema_evo
ALTER COLUMN
quantity
TYPE BIGINT;
DESC iceberg_demo.schema_evo;

6. パーティションの設定
パーティションを設定したテーブルの作成
order_date 列の日付を基準にパーティションを作成し、データを挿入します。
CREATE OR REPLACE TABLE iceberg_demo.partition_table(
id BIGINT,
customer_id BIGINT,
order_date TIMESTAMP,
total_amount DOUBLE
) USING ICEBERG
PARTITIONED BY (day(order_date));
INSERT INTO
iceberg_demo.partition_table
VALUES
(1, 101, CAST('2024-02-01 12:00:00' AS timestamp), 100.50),
(2, 102, CAST('2024-02-02 14:30:00' AS timestamp), 200.75),
(3, 103, CAST('2024-02-02 16:45:00' AS timestamp), 150.25);

パーティションの設定を確認
Databricks 上では、Iceberg で利用可能なパーティション情報の表示 SQL はエラーになります。
SHOW PARTITIONS iceberg_demo.partition_table;
AnalysisException: Table spark_catalog.iceberg_demo.partition_table does not support partition management.; line 1 pos 16;
ShowPartitions [partition#560]

そのため、テーブルの data ディレクトリを直接確認します。order_date_day=2024-02-01 と order_date_day=2024-02-02 にディレクトリが分かれていることがわかります。TIMESTAMP 型カラムを day(order_date) と指定したので、日付単位でパーティションが作られています。
%python
wh_dir = spark.conf.get("spark.sql.catalog.spark_catalog.warehouse")
namspace_name = "iceberg_demo"
table_name = "partition_table"
table_data_dir = f"{wh_dir}/{namspace_name}/{table_name}/data"
display(dbutils.fs.ls(table_data_dir))

パーティション進化(Partition evolution)の実施
Iceberg が提供するパーティション進化(Partition evolution)を Databricks 上で試そうとすると、以下の通りエラーが発生します。
ALTER TABLE iceberg_demo.partition_table
REPLACE PARTITION
FIELD day(order_date)
WITH bucket(16, customer_id)
;
ParseException:
[PARSE_SYNTAX_ERROR] Syntax error at or near 'PARTITION'.(line 1, pos 49)

7. CoW(Copy on Write)と MoR(Merge on Read)の動作検証
CoW と MoR について
Iceberg ではテーブルの行レベル更新や削除の処理方式として Copy-On-Write (CoW) と Merge-On-Read (MoR) の 2 つをサポートしています。それぞれ次のような特徴があります。MoR 方式を選択した場合は定期的なコンパクション(Compaction)が必要になり、運用コストが上がる点に注意が必要です。
-
Copy-On-Write (CoW)
更新・削除が発生すると、該当のデータファイル全体をコピーして書き換え、新しいファイルを作成する方式。- メリット: 読み取り時は常に最新のファイルのみを参照すればよく、シンプルで高速
- デメリット: 書き込み時にファイルの再書き出しが必要になるため、更新負荷が高い
-
Merge-On-Read (MoR)
既存のデータファイルはそのまま残し、更新・削除データを新規ファイル(および削除ファイル)として書き込む方式。- メリット: 書き込み時は既存ファイルを直接書き換えないため高速
- デメリット: 読み取り時にマージ処理が必要となり、ファイル数が増えるほどパフォーマンスに影響する可能性がある
CoW テーブルと MoR テーブルの準備
下記のように、CoW / MoR それぞれのテーブルを作成してデータ挿入・削除を実行します。
-- CoW モードのテーブル作成
CREATE TABLE iceberg_demo.sample_cow (
id INT,
name STRING
)
USING iceberg
TBLPROPERTIES (
'format-version' = '2',
'write.delete.mode' = 'copy-on-write',
'write.update.mode' = 'copy-on-write',
'write.merge.mode' = 'copy-on-write'
);
-- MoR モードのテーブル作成
CREATE TABLE iceberg_demo.sample_mor (
id INT,
name STRING
)
USING iceberg
TBLPROPERTIES (
'format-version' = '2',
'write.delete.mode' = 'merge-on-read',
'write.update.mode' = 'merge-on-read',
'write.merge.mode' = 'merge-on-read'
);
-- CoW テーブルにデータ挿入
INSERT INTO iceberg_demo.sample_cow VALUES (1, 'Alice'), (2, 'Bob'), (3, 'Charlie');
-- MoR テーブルにデータ挿入
INSERT INTO iceberg_demo.sample_mor VALUES (1, 'Alice'), (2, 'Bob'), (3, 'Charlie');
-- CoW テーブルでの DELETE
DELETE FROM iceberg_demo.sample_cow WHERE id = 2;
-- MoR テーブルでの DELETE
DELETE FROM iceberg_demo.sample_mor WHERE id = 2;

ファイル内容を確認
Iceberg では下記のようにファイル状況を確認する SQL をサポートしていますが、Databricks ではエラーが発生します。
-- CoW テーブルのファイル状況を確認
SELECT content, file_path
FROM iceberg_demo.sample_cow.files;

そこで data のディレクトリを確認します。MoR のテーブルにて-deletes.parquetという名称で終わる Parquet 形式のファイルを確認できませんでした。Databricks 上では MoR が意図したとおりには動作していないようです。
%python
wh_dir = spark.conf.get("spark.sql.catalog.spark_catalog.warehouse")
namspace_name = "iceberg_demo"
table_name = "sample_cow"
table_data_dir = f"{wh_dir}/{namspace_name}/{table_name}/data"
display(dbutils.fs.ls(table_data_dir))
%python
wh_dir = spark.conf.get("spark.sql.catalog.spark_catalog.warehouse")
namspace_name = "iceberg_demo"
table_name = "sample_mor"
table_data_dir = f"{wh_dir}/{namspace_name}/{table_name}/data"
display(dbutils.fs.ls(table_data_dir))

Compaction の実施
Iceberg では Compaction(データファイルの再マージ処理)を行う SQL が用意されていますが、Databricks 上で実行するとエラーとなります。
CALL iceberg.system.rewrite_data_files ('iceberg_demo.sample_mor')
ParseException:
[PARSE_SYNTAX_ERROR] Syntax error at or near 'CALL'.(line 1, pos 0)

まとめ
本記事では、Databricks 環境上で Hadoop Catalog を利用して Apache Iceberg を動作させる手順や、その際に発生するエラー・制限事項などを紹介しました。Iceberg ではテーブルのバージョン管理やスナップショット機能、スキーマ進化、パーティション進化、そして Copy-On-Write (CoW) / Merge-On-Read (MoR) といった高度なテーブル管理機能が利用できます。しかし、Databricks との組み合わせにおいては、Iceberg が本来備えている機能の一部がサポートされていなかったり、エラーが発生したりする状況があるようです。
実際に利用する際には、以下の点に留意するとよいでしょう。
-
クラスター構成
Databricks Runtime のバージョンやアクセスモード、ライブラリのバージョン設定が重要で、正しく設定しないと Iceberg を認識できません。 -
Databricks との互換性
UPDATE や MERGE などの SQL 操作、パーティション管理や Compaction 等の Iceberg 固有の機能が Databricks 上では実行できないケースがあります。 -
サービスベンダーのサポート状況
Spark ベースだからといってすべての機能が動作保証されるわけではないため、実運用前に機能単位で検証・確認することが必要です。
Iceberg はローカル環境や他のプラットフォームでも動作するオープンソースのテーブルフォーマットであり、マルチエンジン・マルチクラウドな分析基盤を構築するうえで有力な選択肢のひとつです。ただし、今回のように Databricks 上で利用する際には、サービス側のサポート状況をしっかりと確認しながら機能検証を進めることが欠かせません。