本記事は、OpenShift Advent Calendar 2022 の2日目です。
はじめに
本記事では、OpenShift 上にデプロイされたアプリケーションのログを Apache Kafka に集約し、Apache Kafka をデータハブとして活用して、AWS のマネージドサービスや Splunk などの様々なシステムにアプリケーションログを配信するログ収集プラットフォームの構築方法を紹介します。
そもそも OpenShift Logging では、ClusterLogForwarder API を用いて Elasticsearch・Fluentd・Amazon CloudWatch・Apache Kafka などのサードパーティーシステムにログを転送する機能を持っていますが、サポートされているログ転送先のサードパーティーシステムがある程度限られてしまいます。[1]
これに対して Apache Kafka では、エコシステムが発展しておりサードパーティーシステムと Apache Kafka を接続する部品が数多くコミュニティから提供されていること、ログ転送先のサードパーティーシステムが増えた場合にログ転送先を追加し易いこと、アプリケーションログのデータ量が増えた場合にスケールし易いことなどのメリットがあります。
システム規模やログ転送先の種類によっては OpenShift Logging の ClusterLogForwarder API の利用で十分に足りるケースも多いと思いますが、高いログ転送のスループットやログ転送先の追加の拡張性が要求されるシステムでは本記事のシステム構成が一つの構成案になると考えています。
本記事におけるシステム構成図
本記事では、以下のシステム構成図の流れでログ転送するログ集約プラットフォームを構築したいと思います。
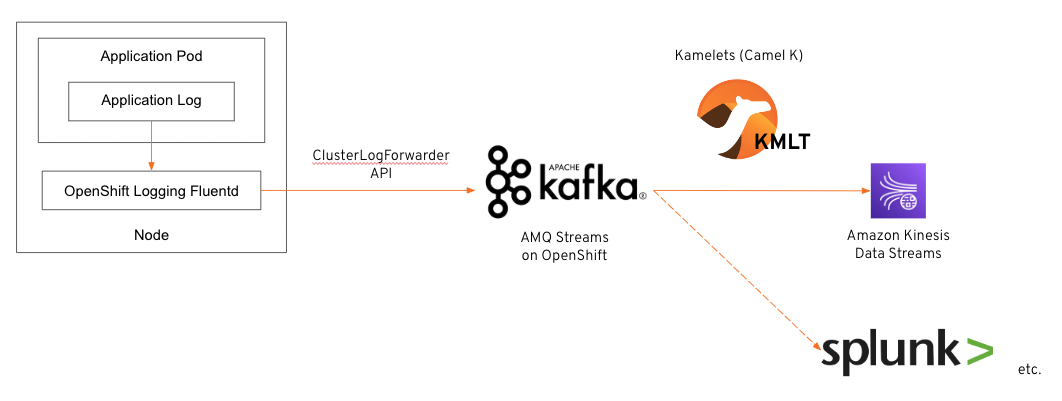
ログ転送先のサードパーティーシステムとして Amazon Kinesis Data Streams を利用し、Apache Kafka には Red Hat がエンタープライズ向けにサポートを提供する AMQ Streams [2] を利用し、Apache Kafka と Amazon Kinesis Data Streams との接続には Kubernetes ネイティブな Camel インテグレーションを実現する Kamelets (Camel K) [3] を利用しています。
環境構築
Operator インストール
OpenShift Web コンソールの Operator -> OperatorHub から、以下の Operator をインストールします。
- OpenShift Elasticsearch Operator (stable)
- Red Hat OpenShift Logging (stable)
- Red Hat Integration - AMQ Streams (stable)
- Red Hat Integration - Camel K (latest)
- Red Hat OpenShift Serverless (stable)
また、OpenShift Serverless では Knative Serving もインストールします。[4]
OpenShift Logging のデプロイ
以下の ClusterLogging カスタムリソースのマニフェストファイルを作成し、OpenShift Logging のロギングスタックをデプロイします。ここでは、Apache Kafka (AMQ Streams) へのログ転送できれば良いので、Elasticsearch・Kibana のデプロイは行いません。
apiVersion: logging.openshift.io/v1
kind: ClusterLogging
metadata:
namespace: openshift-logging
name: instance
spec:
managementState: Managed
collection:
logs:
fluentd: {}
type: fluentd
AMQ Streams on OpenShift のデプロイ
以下の Kafka カスタムリソースのマニフェストファイルを作成し、Kafka クラスタを構築します。
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
listeners:
- name: plain
port: 9092
tls: false
type: internal
replicas: 3
storage:
type: ephemeral
version: 3.1.0
zookeeper:
replicas: 3
storage:
type: ephemeral
entityOperator:
topicOperator: {}
userOperator: {}
Kafka クラスタの構築が完了したら、以下の KafkaTopic カスタムリソースのマニフェストファイルを作成し、ログ転送用の Kafka トピックを作成します。
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: application-log
labels:
strimzi.io/cluster: my-cluster
spec:
partitions: 10
replicas: 2
ClusterLogForwarder の設定
OpenShift Logging の fluentd から Apache Kafka へログ転送を実現するため、以下の ClusterLogForwarder カスタムリソースのマニフェストファイルを作成します。
<Project Name> には AMQ Streams (Apache Kafka) をインストールした OpenShift プロジェクト名に変更してください。
apiVersion: "logging.openshift.io/v1"
kind: ClusterLogForwarder
metadata:
name: instance
namespace: openshift-logging
spec:
outputs:
- name: kafka-app
type: kafka
kafka:
brokers:
- tcp://my-cluster-kafka-bootstrap.<Project Name>.svc.cluster.local:9092/
topic: application-log
pipelines:
- name: application-log
inputRefs:
- application
outputRefs:
- kafka-app
KameletBinding のデプロイ
KameletBinding カスタムリソースを用いて Apache Kafka と Amazon Kinesis Data Streams を接続する前に、以下のようなコマンドを実行することによりAWSアクセスキー・AWSシークレットキーを格納する Kubernetes Secret を作成します。
$ oc create secret generic aws-kinesis-secret --from-literal=accessKey=<AWSアクセスキー> --from-literal=secretKey=<AWSシークレットキー>
作成した Kubernetes Secret を使って以下の KameletBinding カスタムリソースのマニフェストファイルを作成することにより、Apache Kafka と Amazon Kinesis Data Streams を接続します。
apiVersion: camel.apache.org/v1alpha1
kind: KameletBinding
metadata:
name: kafka-to-kinesis
spec:
integration:
configuration:
- type: "secret"
value: "aws-kinesis-secret"
source:
ref:
kind: Kamelet
apiVersion: camel.apache.org/v1alpha1
name: kafka-source
properties:
bootstrapServers: "my-cluster-kafka-bootstrap:9092"
topic: "application-log"
securityProtocol: PLAINTEXT
user: "dummy"
password: "dummy"
sink:
ref:
kind: Kamelet
apiVersion: camel.apache.org/v1alpha1
name: aws-kinesis-sink
properties:
region: "ap-northeast-1"
stream: "logging-to-kinesis"
ここまで紹介したマニフェストファイルを作成・適用することにより、OpenShift 上にデプロイされたアプリケーションのログが Apache Kafka に集約され、Kamelets (Camel K) を使って Kineis Data Streams に連携されました。
さいごに
本記事では、アプリケーションのログを Apache Kafka に集約し、様々なシステムにアプリケーションログを配信するログ収集プラットフォームの構築方法やサンプルのマニフェストファイルを記載しました。
「はじめに」に記載している通り、要件によっては本記事のシステム構成が一つの構成案になると考えていますので、もし要件が合うようでしたら本記事の内容を参考としてご活用ください。
参考
[1] https://docs.openshift.com/container-platform/4.11/logging/cluster-logging-external.html#cluster-logging-collector-log-forwarding-about_cluster-logging-external
[2] https://access.redhat.com/documentation/en-us/red_hat_amq_streams/2.2/html-single/amq_streams_on_openshift_overview/index
[3] https://access.redhat.com/documentation/en-us/red_hat_integration/2022.q4/html-single/integrating_applications_with_kamelets/index
[4] https://docs.openshift.com/container-platform/4.11/serverless/install/installing-knative-serving.html