概要
GPUサーバのリソースを詳細にモニタリングするための、Prometheusのexporterを作成しました。このexporterによって、サーバ内の各GPUを使用しているdockerのコンテナ名やイメージ名、プロセスIDやコマンドを取得できます。また、docker-composeによりサーバへ手軽にデプロイできるようになっています。
GitHubにてリポジトリを公開していますので、ぜひお試しください!
背景
私が所属する研究開発チームでは、複数台のGPUサーバを運用し、深層学習に基づく自然言語処理や動画像処理の開発や性能評価をしています。各GPUサーバではnvidia-dockerが導入されており、ユーザが自由にコンテナを立ち上げることができるようになっています。このような環境では、他のユーザとリソース(特にGPU)がコンフリクトしていないことを確認する必要があります。もし、GPUリソースがコンフリクトすると、プログラムが実行されなかったり、CPUでの処理に切り替わることで処理時間が大幅に長くなったりして、研究開発の効率が落ちてしまいます。
解決策
いちいち各サーバへログインして確認するのは手間がかかるので、監視ツールであるPrometheusを利用してリソースを一覧できるようにします。Prometheusでは、独自にexporter(サーバやシステムの情報を収集するためのエンドポイント)を作成することができます。必要なメトリクスを複数のコマンド (ps, docker, nvidia_smi) を利用して収集します:
| メトリクス | 収集コマンド |
|---|---|
| コンテナ名 | docker |
| イメージ名 | docker |
| コマンド | ps |
| ユーザ名 | ps |
| CPU使用率 | ps |
| メモリ使用量 | ps |
| GPU番号・UUID | nvidia_smi |
| プロセス名・ID | nvidia_smi |
モニタリング例
docker-composeによって、モニタリングに必要なexporterをまとめて立ち上げられるようにしています。実際はこれに加えてansible(構成管理ツール)を導入しており、複数サーバへのデプロイを自動化しています。
監視用のPrometheusサーバでは、Grafanaを用いてリソースを可視化しています。
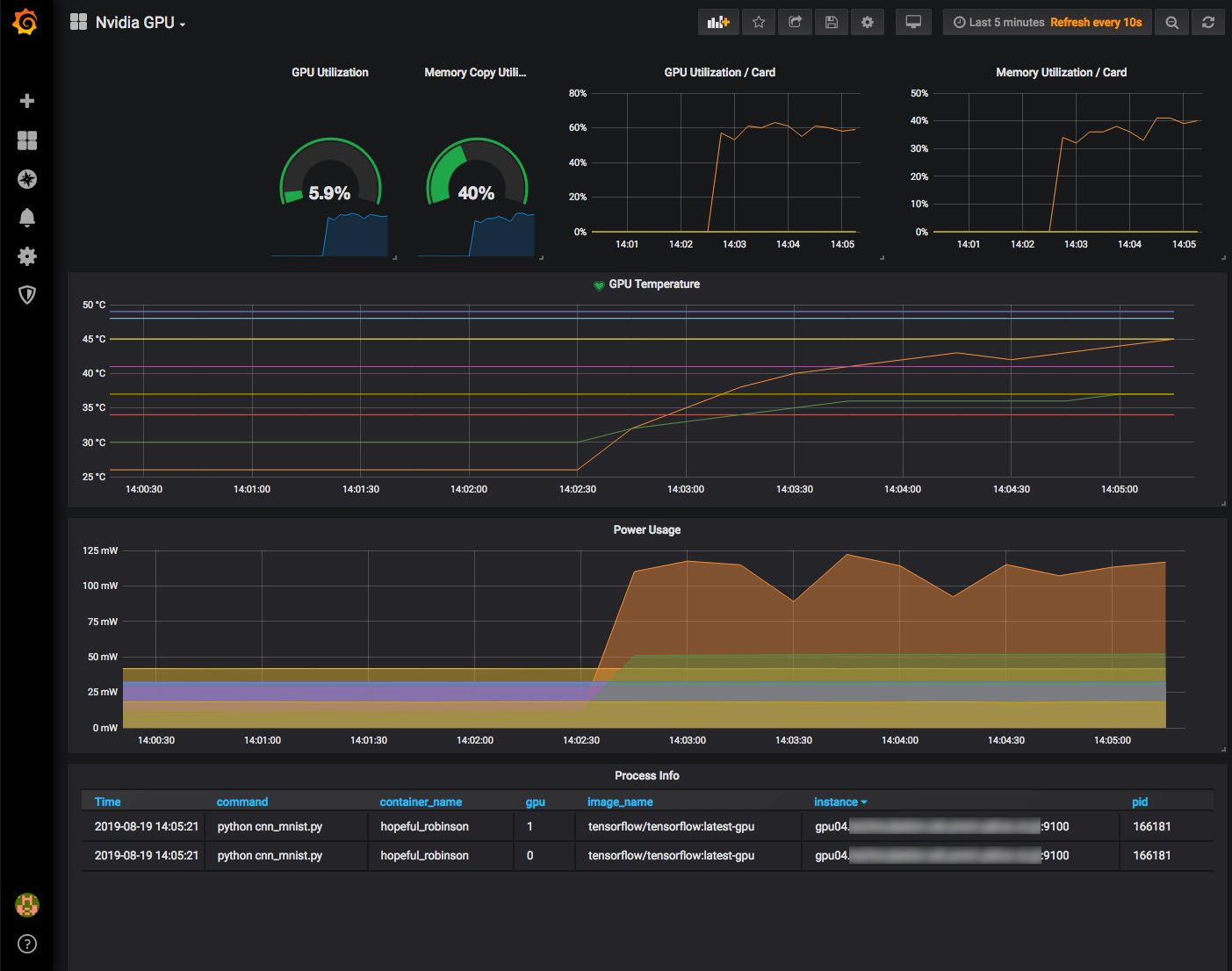
試しにtensorflowのコンテナでmnistをやってみたの図。GPUの使用率やメモリ使用率(GPUごと、全体それぞれ)、温度や電力消費量、GPUを使用しているコンテナやイメージの名前、コマンドなどが表示され、リソースの空きが簡単に確認できます。
プロセス一覧(スクリーンショット内、Process Infoの欄)を表示するには、例えば次のようなクエリ (PromQL) を指定します:
sum(nvidia_smi_process) by (instance, gpu, pid, command, image_name, container_name)
おわりに
研究開発に用いるGPUサーバにおいて、リソースの空きを簡単に確認できるモニタリングツールを紹介しました。コマンド1つでデプロイできるようになっているので、ぜひお試しください。