要旨
Linuxから専用回路を呼び出して行列積演算行うことで超高速計算するようなシステムを作成しようとしましたが,知識不足と技術不足とIOがボトルネックとなり,C言語プログラムと比べて8%程度の高速化にとどまりました.
はじめに
Linuxから専用回路を呼び出して行列積演算を行うシステムを作ります.実装を容易にするために,入力行列を32bit正数を要素にもつサイズを8×8の正方行列に限定しました.
Verilogコード
https://github.com/ryutakashino/MtxMul8_DigilentLinux_on_ZYBO/tree/master/hard
以下に説明するモジュールとVerilogファイルの対応は次の通りです.
READモジュール:INPUT_MODULE.v
WRITEモジュール:OUTPUT_MODULE.v
内積計算モジュール:DOTPRODUCT_MODULE.v
演算コントロールモジュール:CTRL_MODULE.v
開発環境
開発ボード:ZYBO

開発ソフト:Vivado17.4 & Xilinx SDK 17.4(BOOTファイルを作るために使用)

実装手順 概略
実装にあたり,FPGAとCPUの両方をもつZYNQチップを搭載したZYBOボードを使用しました.FPGA側に専用回路を実装し,ZYBOのCPU側にLinuxをいれた上で専用回路を呼び出すようなプログラムを作成し,行列積計算を行いました.
大まかな手順を示します.
- Verilogで行列演算回路を作る.
- Vivadoを用いてZYNQ IP(CPU)と行列演算回路を組み合わせ,Bitstreamファイルを生成する.
- LinuxカーネルをZYBO用にビルドしてブートファイルBoot.binを生成する.
- Bootファイル,Bitstreamファイルと各種設定ファイルをSDカードに落とし,ZYBOを起動する.
- Linux上から回路を呼び出すプログラムを作成する.
3-5の手順は日本でも有数のFPGAサイトである「FPGAの部屋」を運営するmarsee先生の勉強会資料に従って実装しました.この資料では,LinuxからFPGAのLチカ回路を操作するというプロジェクトを実装しています.
http://marsee101.blog19.fc2.com/blog-entry-3079.html#comment2723
今回の行列演算回路ではCPUとFPGA間における行列要素の送受信を全く同じ方式を用いて行っています.
回路の概要
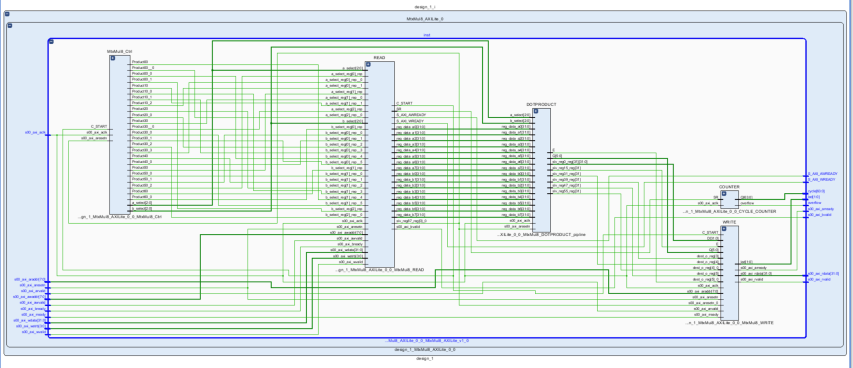
作成した行列積計算回路は次のようなモジュール図になります.

CPUから送られてきた2つの入力行列の128要素がRead(FPGA側からは読み込み)モジュールにより図内の灰色のレジスタファイルに書き込まれます.そして緑色のレジスタファイルに行列積の計算結果が格納され,CPUからWrite(FPGA側からは書き込み)モジュールを通して読み出されることになります.
この2つのレジスタファイルの間にあるのが,青色の内積計算モジュールです.この内積計算モジュールは,4クロックで2つの8要素ベクトルの内積を計算できます.また,計算がパイプライン化されているため,最初の4クロック以降は1クロックごとに内積の値が出力されます.
内積計算モジュールに行ベクトルと列ベクトルの組を64回だけ与えることで,8×8行列積計算をすることができます.行列積計算の開始/終了や内積計算モジュールに対する入力ベクトルの選択を行っているのが赤色の演算コントロールモジュールです.
Vivadoで出力した行列積演算回路のSchematic図を示します.
CPUからFPGAへのデータの送受信
CPUとFPGA間のデータの送受信にはいくつかの方法が存在します.今回は最も実装が容易であるGPポートを介してCPUとFPGAが直接通信を行う通信方式を採用しました.この方法は,実装が用意であるぶん通信速度が遅いという特徴があります.
Vivadoを用いてGPポートに先頭アドレス0x43c00000からオフセット0x10000の範囲のアドレスを割り振りました1.このアドレスに書き込みや読み込みを行うことで行列積演算回路にデータを送受信することができます.データのやり取りは常にCPU側から行列積演算回路へ問い合わせるという形であり,行列積演算回路からCPUへと通信を始めることはできません.特定のアドレスにデータを読み書きするためにUIOというLinuxデバイスドライバを使用しました.このドライバを用いることで,特定のアドレスへの読み書きを配列の形で扱うことができます.
この行列演算回路ではWriteのアドレスとReadのアドレスは異なるレジスタが対応します.アドレス0に1をWriteすることで,行列積演算が開始します.そしてアドレス0のReadで計算の終了判定を行います.返り値が1のときは計算中であり,返り値が3のときは計算が終了しています.入力アドレスと出力のアドレスに対応するレジスタの役割を以下の表にまとめます.
Writeアドレスと対応する役割
| 先頭アドレスからのオフセット | 役割 |
|---|---|
| 0 | 計算開始 |
| 1 | 入力行列Aの1行1列目要素 |
| 2 | 入力行列Aの1行2列目要素 |
| 3 | 入力行列Aの1行3列目要素 |
| ... | ... |
| 64 | 入力行列Aの8行8列目要素 |
| 65 | 入力行列Bの1行1列目要素 |
| 66 | 入力行列Bの1行2列目要素 |
| 67 | 入力行列Bの1行3列目要素 |
| ... | ... |
| 128 | 入力行列Bの1行1列目要素 |
Readアドレスと対応する役割
| 先頭アドレスからのオフセット | 役割 |
|---|---|
| 0 | 計算ステータス (1:計算中,3:計算終了) |
| 1 | 計算結果の1行1列目要素 |
| 2 | 計算結果の1行2列目要素 |
| 3 | 計算結果の1行3列目要素 |
| ... | ... |
| 64 | 計算結果の8行8列目要素 |
すなわち,行列演算回路を呼び出すLinux側のプログラムは次の手順を実行します.
- アドレス1-128に入力行列の要素を書き込む.
- アドレス0に1を書き込んで行列積計算を開始する.
- アドレス0の返り値が3になるまで空ループで読み込む.
- アドレス1-64を計算結果として読み出す.
性能
作成した行列積回路の性能を調べるためにC言語による行列積計算プログラムと実行速度の比較をZYBO上で行いました.既に行列要素が書き込まれた配列a,bに対して.それらの積の結果を配列cに格納するまでの処理を比較する測定部分としました.測定部分を図示すると下図のようになります.ただし,オーバーヘッド対策のため測定部分を1000回を繰り返し、行列積計算時間は測定時間の1/1000としました.
テストに用いた行列の要素は,現在の時間をシードとしたrandom関数を用いて生成しました.行列積計算回路に飽和演算を実装していないため,値の範囲は12bit以下で表せる整数に限定しました.
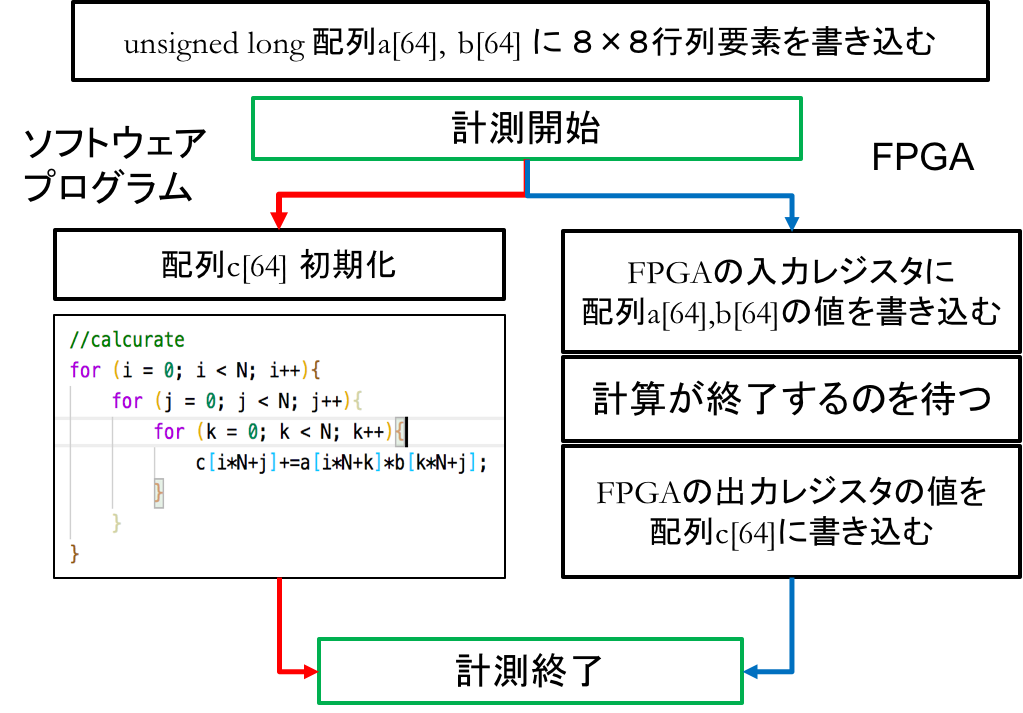
測定手段
システムコール clock gettime 関数
POSIX環境にて使用できるシステムコールです.引数のclk_idにCLOCK_MONOTONICを与えて測定を行いました.システムコールであるため,呼び出しの際のオーバヘッドが計測時間に影響を与える可能性を考慮する必要があります.
PMU
PMUはARM CPU内部に存在するパフォーマンス測定のためのレジスタ群です.この中にあるサイクルカウンタを用いて時間の測定を行います.このレジスタの大きさは32bitであり,計測時間が6.6sを超えるとオーバーフローが発生する可能性があります.しかし,今回は測定時間が十分に短いため,オーバーフローを考慮する必要はありません.測定ではインラインアセンブラを用いて,サイクルカウンタの値を直接読み込みます.このため,前節の関数に比べてオーバーヘッドが少ないという利点があります.ただし,PMUを使用するためにはカーネルモードでPMU内にあるPMUSERENRレジスタのLSBを1にする必要があります.なお実際に得られる値はサイクル数ですが,nsへ結果を変換して測定結果とします.
測定結果
2通りの計算方法を2通りの測定手段でそれぞれ1500回ずつ測定して作成した階級幅1μsのヒストグラムが次のようになります.青色が行列積計算回路の結果で,赤色がC言語プログラムによる結果です.横軸が1μs幅の階級であり,縦軸が階級に属する試行の回数です.
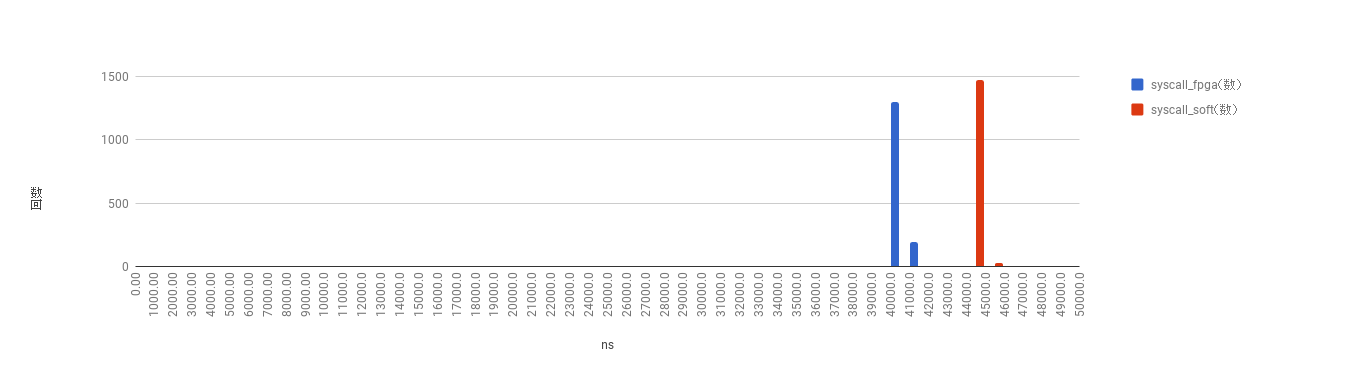
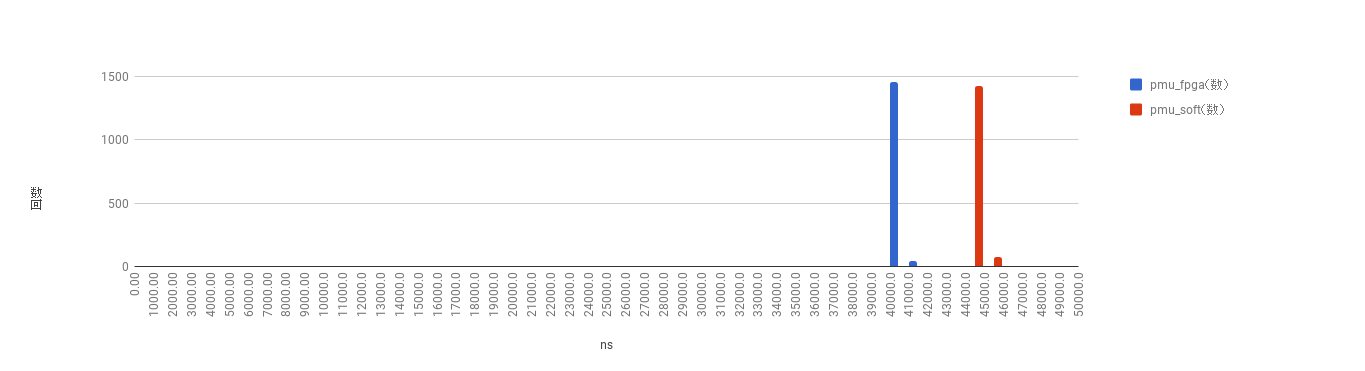
上の図がclock_gettiemシステムコールによる測定結果で,下の図がPMUによる測定結果です.
得られたデータの平均値を次の表にまとめます.
| 平均値 | FPGA(青棒) | C 3重ループ(赤棒) |
|---|---|---|
| clock_gettime | 40985.40494ns | 44506.76081ns |
| PMU | 40949.36348ns | 44507.62684ns |
FPGAでの実行時間は約40.9μs, C言語での実行時間は約44.5μsとなりました.
どちらの測定方法においてもFPGAによる実装の方が約8%ほど高速でした.
考察
この回路は理論上,8×8の行列積演算を1μs以下で計算することができます.FPGAにより数十倍の高速化というものを期待していたため,今回の結果は期待をはるかに下回るものでした.
原因を調べるため,VivadoのFPGA信号観測機能を使用しました.これはILAとよばれる埋め込みロジックアナライザー回路を作成した回路に埋め込むことで,回路内部の信号を観察することができます.ILAに併せて64ビットサイクルカウンタを追加し,信号の変化に対応するサイクル数を測定できるようにします.
測定した結果を次に示します.なお,わかり易さのためにPowerpointを用いて処理ごとの時間を強調しました.
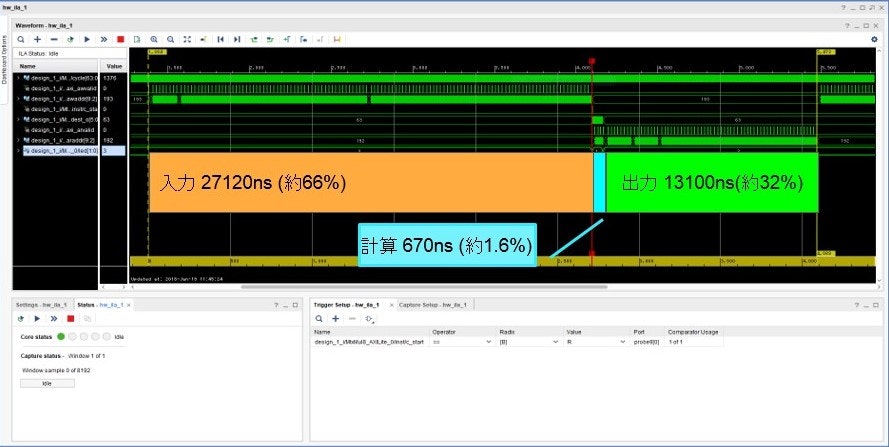
上図は1000回測定中のある1回における行列積計算回路の信号観測結果です.得られた信号観測結果から計測した実行サイクル数は4089cycleでした.この回路は100MHzで動作しているため,実行時間は40890nsになります.このときのCPU側から測定(PMU)した平均実行時間は40945.084615nsでした。
ここから実に98%の時間がIOに費やされていることがわかります.つまり,今回の行列演算においてCPUからFPGAへデータを送受信するIOがボトルネックになっていました.32bit整数64*3要素を送受信するのに27120ns+13100nsだけかかっているため,この回路の平均データ転送速度は約19MB/sとなります.
Zynq-7000テクニカルリファレンスマニュアル中の今回採用したCPUとFPGA間の通信方式に関する説明を引用します.
ソフトウェアの観点で最も簡単な方法は、Cortex-A9を使用してPS-PL間のデータ転送を行うことです(図22-1参照)。
データフローは、CPUから直接実行されるため、DMAからのイベントを個別に処理する必要はありません。PLへのアクセスは、2つの M_AXI_GPマスターポートを介して行われ、各ポートには、 PL AXIトランザクションを開始するためのメモ リアドレス範囲があります。また、わずか 1 つのAXIスレーブをインプリメントしてCPUの要求に応えることができるため、PLデザインもシンプルです。
データ転送に CPU を使用する場合の欠点は、高性能 CPU は複雑な制御や演算タスクを行うのではなく、シンプルなデータ転送を行うのに数サイクル使用することと、達成可能なスループットが限られていることです。この方法では、25MB/s未満の転送レートが適切となります。
(Zynq-7000 AP SoC テクニカル リファレンス マニュアルUG585 (v1.10) p617より引用)
今回の結果は記述されている通りの転送レートになりました.ここから,この転送速度は根本的なものであり別の通信方式を採用しなければ高速化は望めないことがわかります.
さらに,テクニカルマニュアルに書かれている他のCPU-FPGA間の通信方式2を挙げると,
PL_AXI_HP_DMA :予想スループット1200MB/s
PL_AXI_ACP_DMA :予想スループット1200MB/s
など,はるかに高速なテータの転送方式が存在していることがわかります.そして,いずれもCPUと直接データをやり取りするのではなくメモリを介してデータを転送することで高速化を図っています.
以上より,速度不足の原因はIOであり,FPGA-CPU間のデータ転送にメモリを介することでさらなる高速化が期待できることがわかりました.
感想
専用の回路を作れば数クロックで高速計算ができると単純に考えていましたが,そう単純な話ではないことが分かりました.何かしらの演算を行う前提としてデータをそろえる必要があり,そこには必ずIOが発生します.そのロジスティクス的な要素を考えることなしに,高速化は望めないのだと知りました.
次の目標であるメモリを介した高速な通信方式を用いるためには,FPGAにDMA回路を入れたり,ソフトウェア側がデータ共有のためのメモリ空間の確保などひと手間をかける必要があり,圧倒的に知識が足りません.次の課題としたいと思います.
参考
Zynq-7000 AP SoC テクニカル リファレンス マニュアルUG585
https://japan.xilinx.com/support/documentation/user_guides/j_ug585-Zynq-7000-TRM.pdf
Vivado and ZYBO Linux勉強会を開催
http://marsee101.blog19.fc2.com/blog-entry-3079.html#comment2723