はじめに
いままでpythonや機械学習によるデータ分析の勉強に取り組んできて、これから就職を見据える段階に入ってきました。
就職活動を始めるにあたり、「どこまで出来るようになったのか」を考え始めたところです。
せっかく機械学習によるデータ分析等をメインに学習したので、悩んでいたところ「コンペに出てみてはどうか?」と、教えていただいたので、やってみました。
Kaggleの「Spaceship Titanic - Predict which passengers are transported to an alternate dimension」に参加し、このデータ分析をした結果どういう傾向が見えたのかをこの資料としてまとめます。
実行環境
パソコン:Windows11
開発環境:Kaggle Notebook
言語:Python
ライブラリ:Pandas、Numpy、Matplotlib
分析するデータ
以下のデータを利用して、分析結果をまとめます。
分析の流れを確認する
- データの確認をする
- データの加工をする
- 各種パラメータの取得
- モデルの作成
- 評価
データの確認をする
必要なライブラリのインポートと、上記のデータのCSVファイルを読み込みます。
実行したコード
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
%matplotlib inline
train = pd.read_csv('/kaggle/input/spaceship-titanic/train.csv')
test = pd.read_csv('/kaggle/input/spaceship-titanic/test.csv')
sample = pd.read_csv('/kaggle/input/spaceship-titanic/sample_submission.csv')
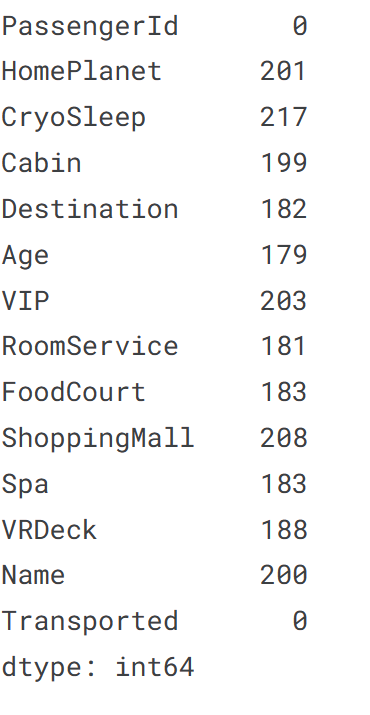
#欠損値の確認
train.isnull().sum()
集計結果
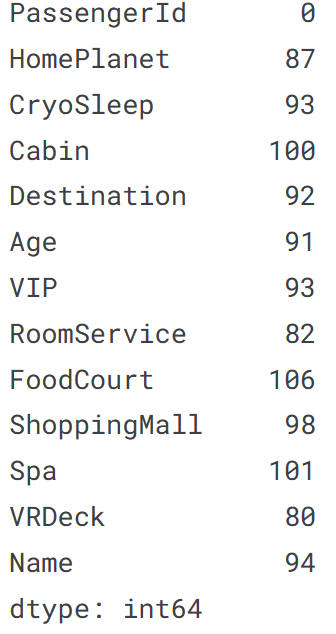
test.isnull().sum()
集計結果
データの前処理(欠損値の補充&要素の削除)
train['HomePlanet'] = train['HomePlanet'].fillna('Earth')
test['HomePlanet'] = test['HomePlanet'].fillna('Earth')
train['CryoSleep'] = train['CryoSleep'].fillna('False')
test['CryoSleep'] = test['CryoSleep'].fillna('False')
train['CryoSleep'] = train['CryoSleep'].astype(bool)
test['CryoSleep'] = test['CryoSleep'].astype(bool)
train = train.drop('Cabin', axis=1)
test = test.drop('Cabin', axis=1)
train['Destination'] = train['Destination'].fillna('TRAPPIST-1e')
test['Destination'] = test['Destination'].fillna('TRAPPIST-1e')
train['Age'] = train['Age'].fillna(train['Age'].mean())
test['Age'] = test['Age'].fillna(test['Age'].mean())
train['VIP'] = train['VIP'].fillna('False')
test['VIP'] = test['VIP'].fillna('False')
train['VIP'] = train['VIP'].astype(bool)
test['VIP'] = test['VIP'].astype(bool)
train['RoomService'] = train['RoomService'].fillna(train['RoomService'].mean())
test['RoomService'] = test['RoomService'].fillna(test['RoomService'].mean())
train['FoodCourt'] = train['FoodCourt'].fillna(train['FoodCourt'].mean())
test['FoodCourt'] = test['FoodCourt'].fillna(test['FoodCourt'].mean())
train['ShoppingMall'] = train['ShoppingMall'].fillna(train['ShoppingMall'].mean())
test['ShoppingMall'] = test['ShoppingMall'].fillna(test['ShoppingMall'].mean())
train['Spa'] = train['Spa'].fillna(train['Spa'].mean())
test['Spa'] = test['Spa'].fillna(test['Spa'].mean())
train['VRDeck'] = train['VRDeck'].fillna(train['VRDeck'].mean())
test['VRDeck'] = test['VRDeck'].fillna(test['VRDeck'].mean())
train = train.drop('Name', axis=1)
test = test.drop('Name', axis=1)
train.isnull().sum()
集計結果

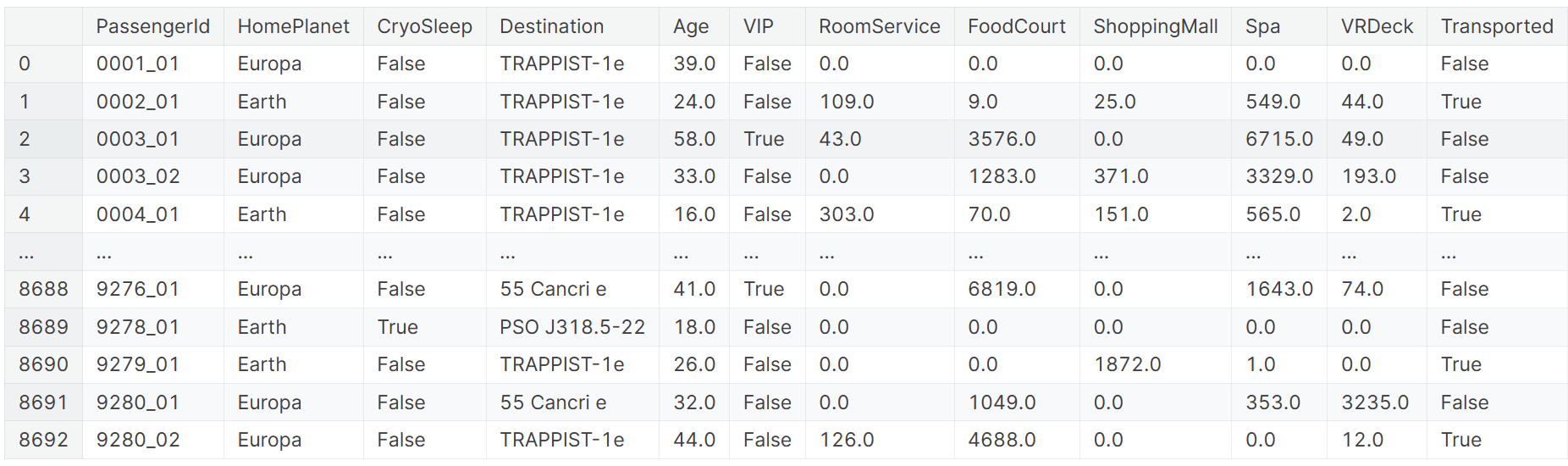
train
集計結果
object型をint,bool,float型に変換する
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
train['HomePlanet'] = label_encoder.fit_transform(train['HomePlanet'])
test['HomePlanet'] = label_encoder.fit_transform(test['HomePlanet'])
train['Destination'] = label_encoder.fit_transform(train['Destination'])
test['Destination'] = label_encoder.fit_transform(test['Destination'])
train['Transported'] = label_encoder.fit_transform(train['Transported'])
train.dtypes
集計結果

#データを分析用に分ける
x_train = train.drop(['Transported', 'PassengerId'], axis=1)
y_train = train['Transported']
#kaggleフォーム提出用にIdを保存
passenger_id_test = test['PassengerId']
passenger_id_test
LightGBMのパラメーターチューニングを行う
!pip install optuna
!pip install optuna-integration
import optuna.integration.lightgbm as lgb
from sklearn.model_selection import KFold
trainval = lgb.Dataset(x_train, label=y_train)
params = {
'objective': 'binary',
'metric': {'binary_error'},
'early_stopping_round': 100,
'verbose': -1
}
tuner = lgb.LightGBMTunerCV(
params,
trainval,
folds=KFold(n_splits=3)
)
tuner.run()
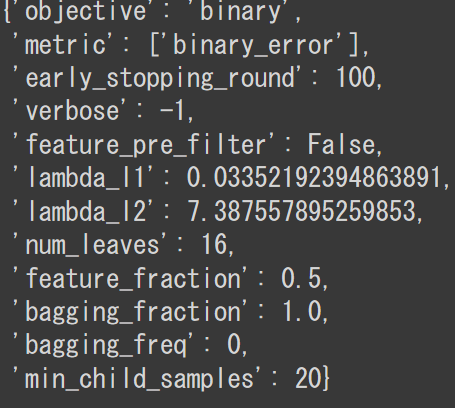
tuner.best_params
集計結果
モデルの作成
import lightgbm as lgb
params={'objective': 'binary',
'metric': ['binary_error'],
'feature_pre_filter': False,
'lambda_l1': 0.03352192394863891,
'lambda_l2': 7.387557895259853,
'num_leaves': 16,
'feature_fraction': 0.5,
'bagging_fraction': 1.0,
'bagging_freq': 0,
'min_child_samples': 20}
model = lgb.LGBMClassifier()
model.set_params(**params)
model.fit(x_train, y_train)
算出したパラメーターをparamsに落とし込んでモデルの作成を行った
Kaggle提出用にCSVファイルの作成
sample['Transported'] = model.predict(x_test)
sample['Transported'] = sample['Transported'].map(lambda x: 'True' if x == 1 else 'False')
sample
sample.to_csv('SPAsubmission.csv', header=True, index=False)
まとめ&評価
結果は1371位/3336人でした。
前処理をもっと複雑丁寧に行ったり、モデル選択の工夫などで、更により順位を上げることが出来るかもしれないと思いました。
今回はKagglleの分類についてやってみましたが、他にも時系列分析や画像判定、自然言語処理などまだまだ勉強したいことが多くあるので、これからも学習を続けていこうと思います。

