この記事の概要
2018/11/26~2019/2/26で開催されたkaggleの「kaggle Elo Merchant Category Recommendation」コンペに「Makotu_with_0.05_friends」というチーム名で参加していました。
結果は35th/4,128teamsでsilver medalを頂くことができました。これでsilver medal3つ目で、シルバーコレクターになりつつあります。(Gold欲しかった…)
この記事では、どんなコンペだったか?の概要と自分たちの取ったアプローチ・上位者のアプローチとそこからの学びを、コンペに参加しなかった方もなんとなくわかる程度にまとめます。
【注意】
**「コンペに参加してない人も概要・難しいポイント・アプローチを知ることができる・学びにできる」**ことがこの記事の目的です。よって、
- データを深く触った人しか理解ができないようなTopicはこの記事では触れません。
- merchant_idを「お店」と表現したり、一部わかりやすさを重視した表現にしています。

コンペの主催者
Eloというブラジルの決済サービス企業がコンペのホストです。
クレジットカードやオンラインサービスの決済周りのプラットフォームビジネスをしているようです。ブラジル版Paypalみたいなものなのかなと思っています。
コンペ概要
Eloが「ロイヤリティスコア」として定義しているスコアの予測をします。
-
ロイヤリティスコアは「card_id」というカード単位で付与されています。
- 学習用のcard_idは約20万レコード、予測用のcard_idは約12万レコード存在しています。
-
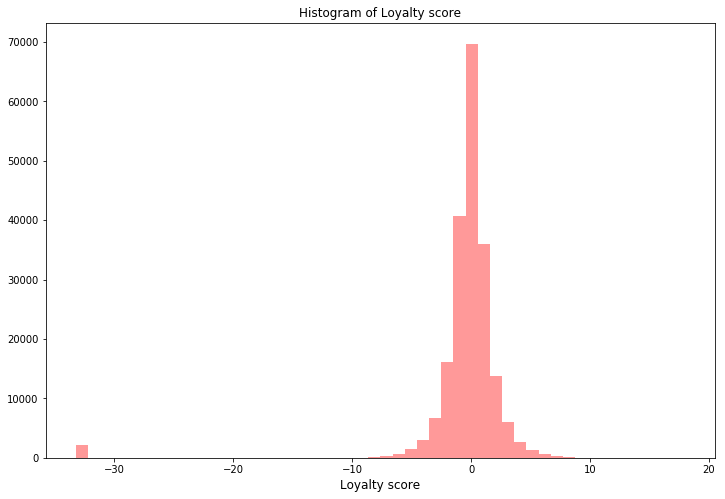
ロイヤリティスコアはほば大多数が-10~10の値の間に分布していますが、一部「-33」という「異常値」が振られています。後述しますが、とにかくこの異常値がこのコンペの参加者を最初から最後まで混乱させる要因でした。
-
評価指標はRMSEです。連続値の予測をするときに定番とされる指標ですね。
提供されたデータ
ホスト側からは主に3つのテーブルデータが提供されました。
(hist/newの区分けは参加していない人にとってはややこしいだけなので省略してます)
-
各card_idのマスタ
- 各card_idとそのロイヤリティスコア(target)
-
各card_idの取引履歴データ
- 各card_idに、いつ、どのお店で、どれだけの取引があったのかを表すtransactionデータ
- 取引の中には異常な取引があり、そのフラグ(authorized_flag)などもある
-
お店(merchant_id)のマスタ
- 今回のコンペでは精度にほぼ寄与せず、多くの人が使っていなかったと思います
このコンペで難しいと感じたこと
私の中では、結局このコンペの難しいポイントは targetの中に「異常値」が存在することに集約されるのではないかと感じています。混乱を巻き起こし、参加者を霧の中に誘いました。(私たちは「何もわからない、霧の中に迷い込んだようだ」と感じたことから、このコンペを**「霧コンペ」**と名づけました)

冗談はさておき、targetの中に異常値があることで「ロイヤリティスコアそのものを予測すること」と「異常値を分類すること」の両方を考慮する必要が出てきます。
(実務で機械学習を使うとき、こういう異常なサンプルは抜いて予測するのが普通なのに、ホスト側は何がしたいんだ…?)と内心で思ったことは秘密です。
discussionでは異常値の確率が高いサンプルに-33のラベルを手でつけるとLBのスコアが上がることが共有され、おそらくLB上では多くの参加者がこれをしていたのではないかと思います。(結果的にこれはPB上では機能せず、劇薬みたいなアプローチでした…)
自分たちのアプローチ
会社のメンバー2人とチームを組んで参加しました。
1人は先輩(分析部署の副部長)・1人は後輩(新卒1年目)です。
役割はこんな感じで、うまくワークしてたかなと感じます。
先輩(副部長):
方針に関するアドバイザリ担当
後輩(新卒1年目):
①ハイパラチューニング担当
②twitterで「eloコンペ」を調べてみんなの辛そうなツイートを拾ってくる担当
私(中堅):
メインで手を動かす担当
使用した特徴量
以下のような特徴量を作成しました。
こういう人間の行動に関するデータの特徴量を作る時は「カードを使っている人がどんな使い方するかな、どんな行動するかな」を思い浮かべながら作れるので、特徴量がマスクされているコンペより作っていて楽しいですね。
色々作りましたが、重要度が高かった変数としては例えばこんな感じです。
- 異常な取引がいつごろ発生していたか(authorize_flag=0だけでmonth_diffの平均を取る)
- 取引日の間隔(取引日の差分を取り、差分の最大値や平均値を取る)
- 最後に取引した日の購入額
- 一番取引額が多かった日
- あと、なぜ効いたかはいまだにわかりませんがkiller featureとして month_diffの平均 / 取引が発生してた期間(最終取引日 - 初回取引日)が良く効いてました。
モデリング
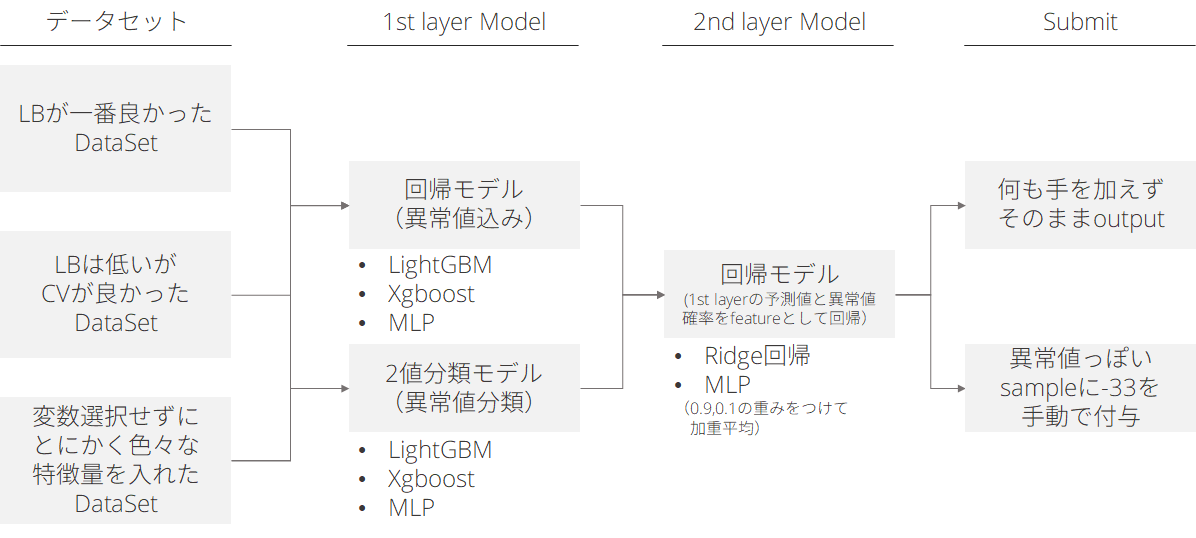
以下の図のようにモデリングしました。
- データセットを3種類作成
- LBが良かったデータセット/CVが良かったデータセット/変数選択をしてないデータセット
- 変数選択はborutaとかはあまり効かなかった印象で、手動で試行錯誤
- LightGBM/xgboost/NN(シンプルな3層mlp)で学習器を作成
- 異常値ありの連続値回帰と、異常値かどうかの分類器の2種類作成
- seedは3seedで、Averagingせずにそのまま結果を出力
- 上記の結果を横に結合して、ridge回帰とmlpで予測し、重み付け平均
- データセット × 回帰モデル/2値分類 × 学習器 × seed = 54columns
- second levelはLightGBMとかではなくシンプルなridge回帰が良かったのは知見
- 何も手を加えないsubmitと、異常値確率の高いサンプルに-33を手動で加えるsubmitを用意
- 異常値の分布や特徴がLBのtestデータとPBのtestデータで違う場合、-33をつけたsubmitは最終resultで順位が下がるだろう、という話をチームでしており、両方のsubmitを用意した
- 結果的にそれが功を奏した。何も手を加えないsubmitの結果が良かった
うまくいかなかったこと
- Adversarial Validation
- Seed Averaging
- LightGBMの特徴量にそのまま異常値の確率を入れてモデリング
- 月間取引量の時系列データを作りLSTMで学習させた結果をNNに入れる
- 若干複雑なネットワークにもチャレンジしてみたのですが精度は上がらず、シンプルな設計が良かったです。上位解法もシンプルなネットワークが多かったように見受けられます。
TOP層のアプローチ
こちらは、他の方のブログでとても丁寧に紹介されており、私が書いても重複になってしまうだけなので、ブログへのリンクを貼って代用できればと思います。めちゃくちゃ参考になりました…!
Kaggle Eloコンペの振り返り・上位解法まとめ (天色グラフィティ)
個人的には、上位の方が使っていた
- 「transactionデータにtargetを紐づけて予測値を出し、それを特徴量とする」方法
- 利用した店のidや購買量を文字列で並べてベクトル化して特徴量とする方法
は目からウロコで、今後のコンペでも活用していこうと思いました。
(私の)学び
- transaction dataを使った特徴量作成
- 取引状況を文字列としてベクトル化した特徴量作成
- Stackingはシンプルなモデル(今回はridge回帰)が強力なこともある
- テーブルデータでのNNは、シンプルな設計が強力なこともある
というわけでEloコンペについてまとめてみましたが、補足や訂正などあれば適宜ご指摘いただければ幸いです!