Navigation Timing とか Resource Timing とか、パフォーマンスまわりのAPIについて自分で整理できていなかったので、これを機会にまとめてみました。
API
| API | 内容 | サポート状況 |
|---|---|---|
| Navigation Timing API | ブラウザがウェブページを表示するのに要する時間の詳細に関するAPI | http://caniuse.com/#feat=nav-timing |
| Resource Timing API | ウェブページで読み込まれるリソースの読み込みに要する時間の詳細に関するAPI | http://caniuse.com/#feat=resource-timing |
| High Resolution Time API | マイクロ秒で経過時間を取得するAPI | http://caniuse.com/#feat=high-resolution-time |
| User Timing API | マイクロ秒の性能計測用API | http://caniuse.com/#feat=user-timing |
Navigation Timing API
performance.timingで以下のようなプロパティが取得できます。
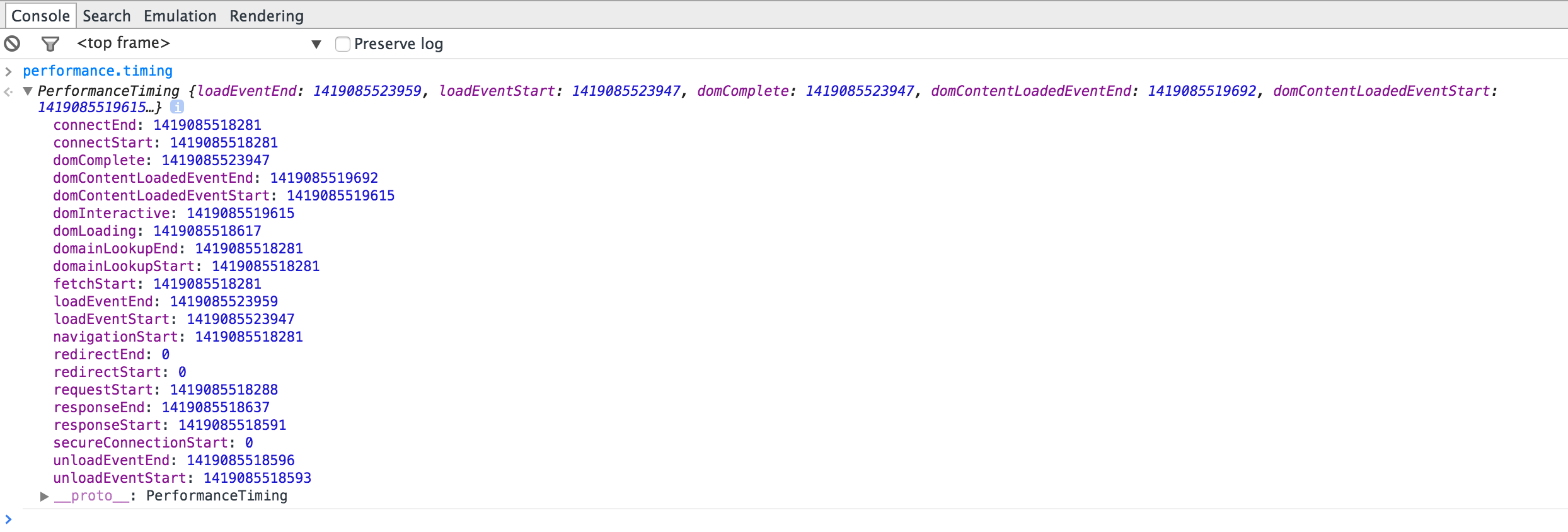
取得される値は、UTC(1970年1月1日0時0分0秒)を起点としたミリ秒になります。
| プロパティ | 内容 |
|---|---|
navigationStart |
前回のドキュメントのunloadが完了した直後の時間。前回のドキュメントが存在しない場合、"fetchStart"と同じ値になる。 |
unloadEventStart |
前回のドキュメントのunloadイベントが発火する直前の時間 |
unloadEventEnd |
前回のドキュメントのunloadイベントが発火した直後の時間 |
redirectStart |
リダイレクトが開始された時間 |
redirectEnd |
リダイレクトが存在する場合、リダイレクトのレスポンスの最後のバイトを受け取った直後の時間。 |
fetchStart |
ブラウザがURLを探し始める直前の時間。アプリケーションキャッシュのチェックやキャッシュされてないファイルをサーバに要求することも含んでいる。 |
domainLookupStart |
DNSルックアップが発生する直前の時間。DNSルックアップが不要な場合、"fetchStart"と同じ値になる。 |
domainLookupEnd |
DNSルックアップの発生直後の時間。DNSルックアップが不要な場合、"fetchStart"と同じ値になる。 |
connectStart |
ブラウザがサーバに接続する直前の時間。URLがキャッシュもしくはローカルのリソースの場合、"domainLookupEnd"と同じ値になる。 |
connectEnd |
サーバへの接続が確立した時間。URLがキャッシュもしくはローカルのリソースの場合、"domainLookupEnd"と同じ値になる。 |
secureConnectionStart |
HTTPSプロトコルが使われているケースで、セキュアに接続するためのハンドシェイク処理の開始する直前の時間 |
requestStart |
ブラウザがURLにリクエストを送信する直前の時間 |
responseStart |
ブラウザがレスポンスの受け取りを開始した直後の時間 |
responseEnd |
ブラウザがレスポンスを全て受け取った直後の時間 |
domLoading |
"document.readyState"の値が"loading"になる直前の時間 |
domInteractive |
"document.readyState"の値が"interactive"になる直前の時間 |
domContentLoadedEventStart |
DOMContentLoadedイベントの発火直前の時間 |
domContentLoadedEventEnd |
DOMContentLoadedイベントの発火直後の時間 |
| domComplete | "document.readyState"の値が"complete"になる直前の時間 |
loadEventStart |
windowのloadイベント発火直前の時間 |
loadEventEnd |
windowのloadイベント発火直後の時間 |
window.onloadイベント中では、loadEventEndの値は常に0が返されるので、
javascript - Why does my attempt at measuring render time with Web Performance API keep resulting in negative values - Stack Overflowのように
setTimeout()で遅延させることで、正常に値を取得できます。
Resource Timing API
performance.getEntriesByType('resource')で、全リソースのPerformanceResourceTimingオブジェクトの配列が取得できます。
各PerformanceResourceTimingオブジェクトには以下のようなプロパティがあり、Navigation Timing APIとは違い、ナビゲーション開始時を起点とするミリ秒での値となります。
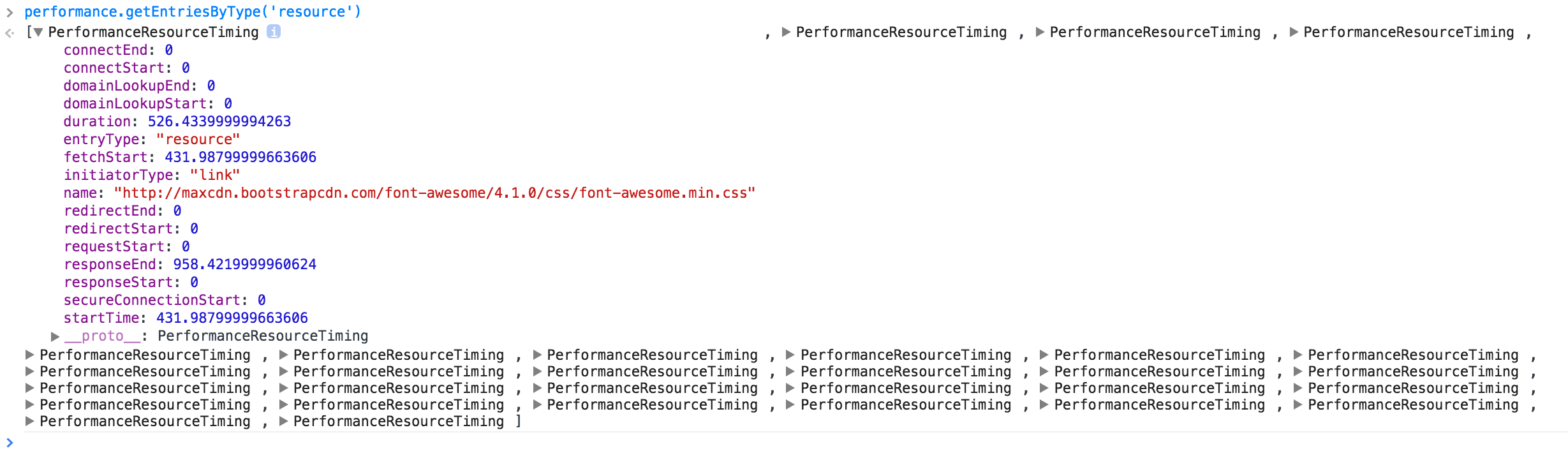
| プロパティ | 内容 |
|---|---|
name |
リクエストされたリソースのURL |
entryType |
resource |
startTime |
ダウンロードするリソースをキューに溜め込み始める直前の時間 |
duration |
responseEndとstartTimeとの差分の時間 |
initiatorType |
リソース取得タイプ |
redirectStart |
HTTPリダイレクトが発生している場合、リダイレクトのダウンロード開始の時間 |
redirectEnd |
HTTPリダイレクトが発生している場合、最後のリダイレクトの最後のバイトを受け取った直後の時間 |
fetchStart |
HTTPリダイレクトが発生しない場合、リソースのダウンロードを開始する直前の時間 |
domainLookupStart |
DNSルックアップが発生する直前の時間。DNSルックアップが不要な場合、"fetchStart"と同じ値になる。 |
domainLookupEnd |
DNSルックアップの発生直後の時間。DNSルックアップが不要な場合、"fetchStart"と同じ値になる。 |
connectStart |
サーバとの接続が確立される直前の時間 |
connectEnd |
サーバとの接続が確立された直後の時間 |
secureConnectionStart |
オプション。HTTPSプロトコルが使われているケースで、セキュアに接続するためのハンドシェイク処理の開始する直前の時間 |
requestStart |
サーバから、もしくはアプリケーションキャッシュかローカルリソースからのリクエストを開始する直前の時間 |
responseStart |
リソースの最初のバイトを受け取った直後の時間 |
responseEnd |
リソースの最後のバイトを受け取った直後の時間 |
Resource Timing practical tips | High Performance Web Sitesで書かれているように、
performance.getEntries()でもperformance.getntriesByType('resource')と同様の結果が得られるブラウザが多いけれども、getEntries()は将来的にresource、navigation、mark、measureの4種類のオブジェクトを返すようになるので、getEntriesByType('resource')で取得するようにしておいた方がいいようです。
また、生成元が異なるリソース(cross-origin)の場合、セキュリティ上の理由で詳細な値を得ることができないのでdurationの値がリソース取得にかかる時間を計測する値になりますが、SERIOUS CONFUSION with Resource Timing | High Performance Web Sitesによると、durationはブロッキングの時間も含んでいるので、正確なリソース取得に要した時間ではないようです。
つまり、ブラウザのホスト名での同時接続数制限によって、ダウンロード開始を順番待ちしている時間もdurationの時間に含まれているので、順番待ちをしているリソースほどdurationの値が極端に増加していきます。
この点に関して、Steve Souders氏は”networkDuration”の追加を提案しているので、今後どうなっていくか注目したいです。
High Resolution Time API
High Resolution Time APIはナビゲーション開始時を起点として、マイクロ秒で値を取得できるnow()メソッドのみを提供します。
Date.now()で取得したミリ秒の値を比較していた部分を、performance.now()に置き換えることでマイクロ秒での比較が可能になります。
より細かい粒度での測定が可能になることで、ミリ秒の精度では十分でなかったアニメーションのパフォーマンス測定などで有用らしいです。
function hoge () {
var list = [];
for (var i = 0, max = 100000; i < max; i++) {
list.push(i * i);
}
console.log(list);
}
var start = Date.now();
var startHR = performance.now();
hoge();
var end = Date.now();
var endHR = performance.now();
console.log(end - start);// -> 658
console.log(endHR - startHR);// -> 657.6000000000022
加えて、performance.now()はナビゲーション開始時から常に一定の間隔で単調に値を増やすので、15分から20分間隔で数ミリ秒の調整をおこなっているUNIX時間のDate.now()より高精度の測定ができそうです。
User Timing API
User Timing APIはperformanceオブジェクトで以下の4つのメソッドを提供しています。
| メソッド | 内容 |
|---|---|
mark(name) |
name に紐付いたDOMHighResTimeStamp を保持する |
clearMarks([name]) |
保持しているMarkを削除する |
measure(name[, mark1[, mark2]]) |
2つのMark間の経過時間を保持する |
clearMeasures([name]) |
保持しているMeasureを削除する |
High Resolution Time APIと同様にマイクロ秒で結果が得られます。
測定したい箇所に任意の名前でmarkをつけて、複数のmarkの間の経過時間をmeasureでとります。
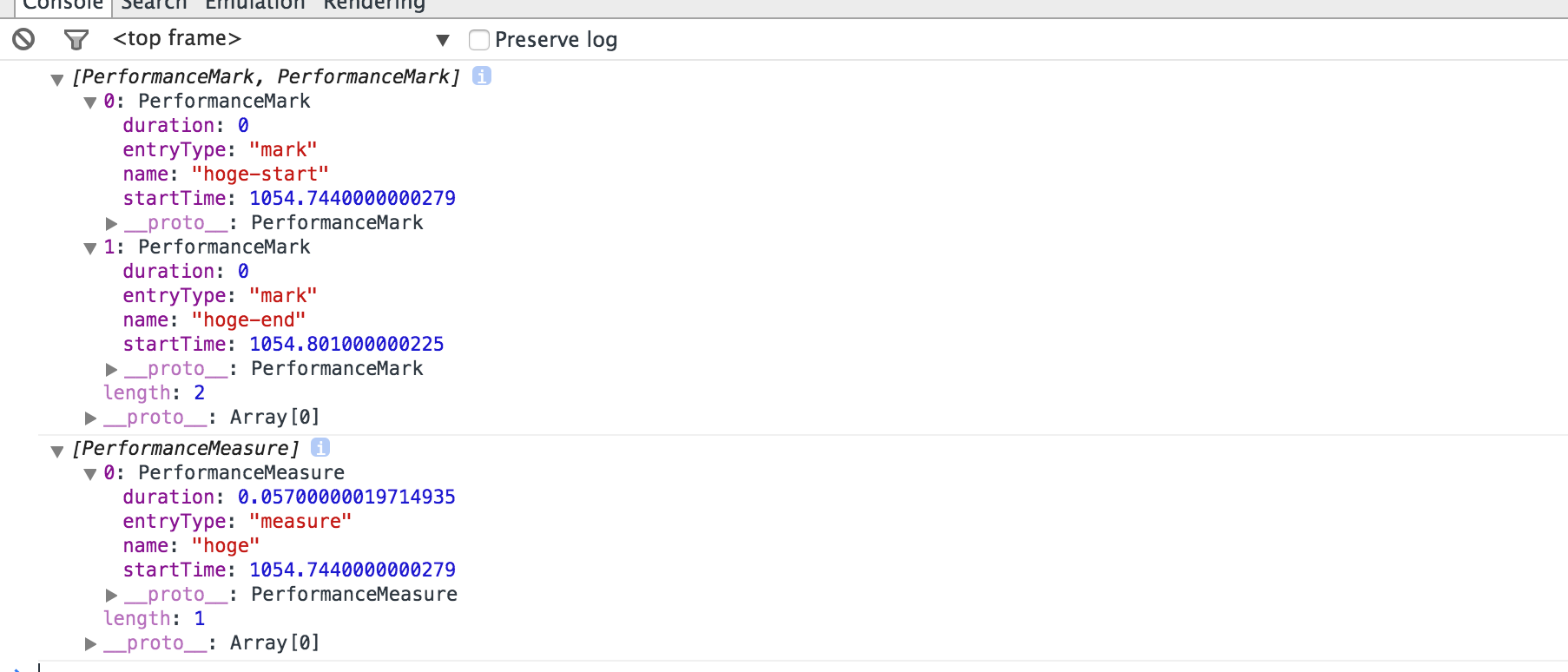
performance.mark('hoge-start');
var list = [];
for (var i = 0, max = 100; i < max; i++) {
list.push(i * i);
}
performance.mark('hoge-end');
performance.measure('hoge', 'hoge-start', 'hoge-end');
console.log(performance.getEntriesByType('mark'));
console.log(performance.getEntriesByType('measure'));
上記のようなコードで、以下のような結果がコンソールに出力されます。
今回このアドベントカレンダーを機会に、これらのAPIについて多少は整理がついたので、今後積極的に活用していきたいと思います。
Links
- Profiling Page Loads with the Navigation Timing API
- Improving Site Performance with the Navigation Timing API -Telerik Developer Network
- document.readyState - DOM | MDN
- Measuring Page Load Speed with Navigation Timing - HTML5 Rocks
- Navigation Timing — ナビゲーションの計時(日本語訳)
- Navigation Timingだからできる、Webアプリを俯瞰したパフォーマンス計測(1/3) | HTML5Experts.jp
- DNSルックアップとは 【 DNS look-up 】 - 意味/解説/説明/定義 : IT用語辞典
- Introduction to the Resource Timing API
- Google Developers Blog: Measuring network performance with Resource Timing API
- Resource Timing
- Resource Timing — リソース計時(日本語訳)
- Discovering the User Timing API - SitePoint
- Discovering the High Resolution Time API
- Fastersite: A better timer for JavaScript
- When milliseconds are not enough: performance.now()
- Web パフォーマンス: ミリ秒の精度では十分でない場合 - IEBlog 日本語 - Site Home - MSDN Blogs
- User Timing API: あなたの Web アプリをもっと理解するために - HTML5 Rocks
- UNIX時間 - Wikipedia
- Web Performance/EntryType - W3C Wiki
- Navigation Timing 2
- HTML5で Speed Test, Navigation Timing APIによる性能データ収集 - ぼちぼち日記
- Resource Timing practical tips | High Performance Web Sites
- Gmail スケールの効率的メモリ管理 - HTML5 Rocks
- JavaScriptからメモリ情報を取得する方法 | Web Scratch
- javascript - Why does my attempt at measuring render time with Web Performance API keep resulting in negative values - Stack Overflow
- Coding Web Performance ~Webパフォーマンス最適化のためのコーディング手法~ — MOL