背景
esp32はdual coreですが、普通に書いたloop関数ではコア1しか使わないため、Auino Coreではmulti core使えないのかと思っていたら、 xTaskCreatePinnedToCoreというのを使えば処理を各コアに分散させられるらしい。そうなるとマルチタスクの仕様に色々疑問が出てくるので実験。微妙にかぶるRaspberry PI zero Wとも比較してみた。
- コアに処理を分散させると処理能力が二倍になるのか
- 消費電力に変化はないのか
- main loopはどのコアを使うのか
- ラズパイゼロと比べてどうなのか
方法
ただ単に計算負荷をかけるだけのための関数を作成する。ここではとりあえず10秒間でハノイの塔20段を何回終了できるかを実行するdoHanoi関数を作成。この関数をmain loop及びxTaskCreatePinnedToCoreでコアを指定して走らせてみる。ハノイの塔は、とりあえず処理負荷をかけるだけの目的で利用。
必要に応じてタスクをコメントアウトし、それぞれの組み合わせのパフォーマンスを確認する。消費電力はきちんと調べられるもの持ってないので、とりあえず数百円で買ったUSBの電流計で代用。10mA精度で結果は目視なので精度は微妙。
ハノイの塔とは(本質ではないので興味がなければ無視してね)
https://ja.wikipedia.org/wiki/%E3%83%8F%E3%83%8E%E3%82%A4%E3%81%AE%E5%A1%94
段数をnとすると(2のn乗)-1の処理数が必要になるので、段数を調整することで1ループあたりの負荷を調整しやすい。おじさん世代には再帰プログラムの入門で使った。

下記のソースコードで適宜負荷処理部分をコメントアウトして色々実験。
# include "freertos/task.h"
int cnt;
//ハノイの塔の関数。負荷をかけるためだけのもので本質ではない。
void hanoi(int n,char a,char b,char c)
{
if(n>0) {
hanoi(n-1,a,c,b);
//Serial.printf("No. %d disk is moved from %c to %c.\n",n,a,b);
hanoi(n-1,c,b,a);
}
}
//ハノイの塔を実行する関数。負荷をかけるためだけのもので本質ではない。
void doHanoi(char* task, int n){
int cnt=0;
unsigned long time_s = micros();
n=20;
while(1){
vTaskDelay(1);
if(micros()-time_s < 10000000){
hanoi(n,'a','b','c');
cnt++;
}else{
Serial.printf("%d hanoi loops by %s on core %d done\n",cnt,task,xPortGetCoreID());
Serial.printf("%d msec passed\n",micros()-time_s);
break;
}
}
while(1){
vTaskDelay(1);
}
}
void task0(void* param) {
doHanoi("task0",20);
}
void task1(void* param) {
doHanoi("task1",20);
}
void setup() {
Serial.begin(115200);
delay(100);
// コア0で関数task0をstackサイズ4096,優先順位1で起動
xTaskCreatePinnedToCore(task0, "Task0", 4096, NULL, 1, NULL, 0);
// コア1で関数task1をstackサイズ4096,優先順位1で起動
xTaskCreatePinnedToCore(task1, "Task1", 4096, NULL, 1, NULL, 1);
}
void loop() {
// mail loopでのハノイの塔実施
doHanoi("main loop",20);
}
結果
パフォーマンス
10秒間で処理したハノイの党20段の数が多いと処理能力が高いとする。xTaskCreatePinnedToCoreでcore0,1に貼り付けたtask0,1と、暗黙的にcore1に割り当てられるloop関数内のタスクを比較。
Core0で59回,Mainloopでも59回処理できるがxTaskCreatePinnedToCoreでCore1にプロセスを貼り付けても半分程度しかパフォーマンスが出ない。この制約はmain loopのリソースをキープするのが目的かもしれない。
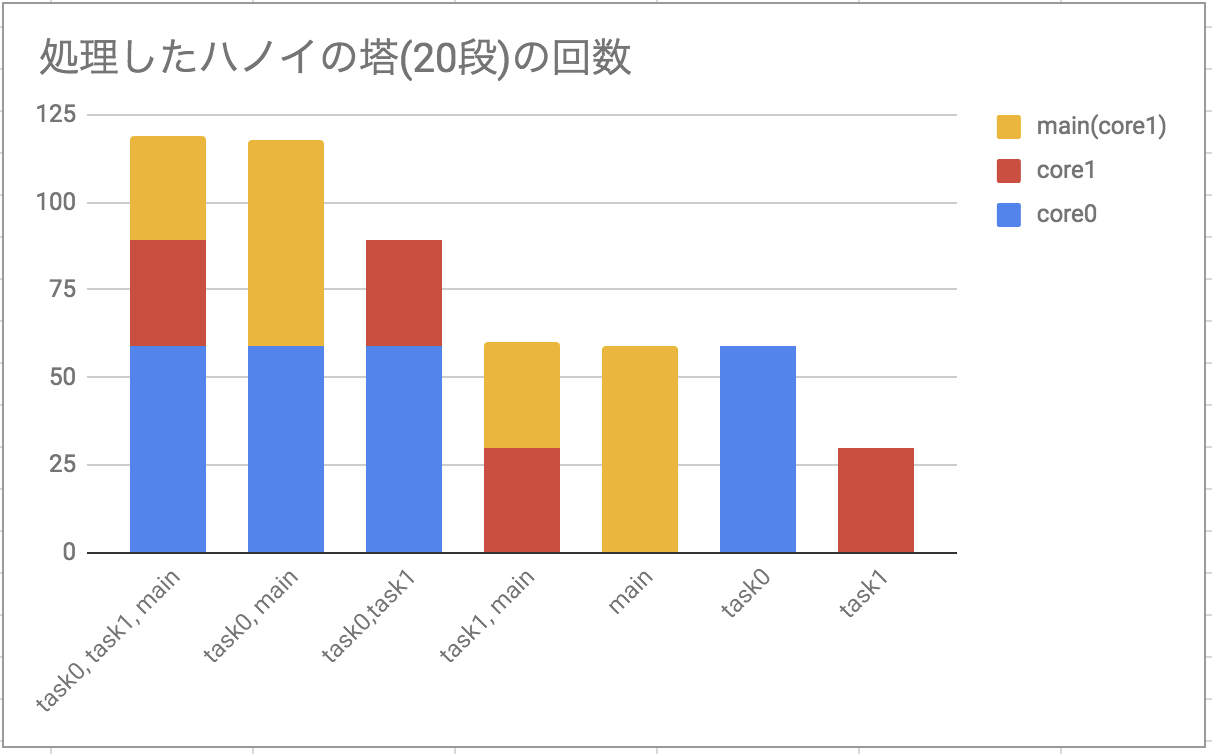
| core0 | core1 | main(core1) | total | |
|---|---|---|---|---|
| task0, task1, main | 59 | 30 | 30 | 119 |
| task0, main | 59 | 0 | 59 | 118 |
| task0,task1 | 59 | 30 | 0 | 89 |
| task1, main | 0 | 30 | 30 | 60 |
| main | 0 | 0 | 59 | 59 |
| task0 | 59 | 0 | 0 | 59 |
| task1 | 0 | 30 | 0 | 30 |
| Raspberry PI Zero w(参考) | 126 | 126 |
参考:Raspberry pi zero wはほぼ等価なCで書いたコードをシングルタスクで実行してハノイの塔20段を10秒で126回なので、消費電力の差を考えるとESP32は決して悪くない数字。
ちなみにxTaskCreatePinnedToCoreの最後の引数(xCoreID)に0や1ではなく、tskNO_AFFINITYという定数を指定すると空いているコアをダイナミックに割り当てるが、task1とtask0の合計処理数は上記データの合計処理数と同じ。
消費電力
というか、電流の目視確認。電力=電流x電圧。電圧はほぼ一定なので電流を雑に測定。明らかにコア0を使うと電流値が急激に上昇する。
| task | Core | 電流(mA) |
|---|---|---|
| task0, task1, main | 0,1 | 50 |
| task0, main | 0,1 | 50 |
| task0,task1 | 0,1 | 50 |
| task1, main | 1 | 10 |
| main | 1 | 10 |
| task0 | 0 | 40 |
| task1 | 1 | 10 |
| Raspberry PI Zero w(参考) | 0 |
|
(参考)Raspberry PI Zero wはcでほぼ等価なコードを書いてwifiをoffにして計測。ちなみに無負荷でも100mAぐらい消費するようです。 USB/HDMIを外すと大幅に減少。無負荷で20mAぐらい。
サマリー
- main loopは必ずCore1で実行された。
- Core1に処理を割り当てるとMain loopとリソースを取り合う。
- Main loopで何も処理をしなくともCore1に割り当てられる処理能力は50%程度。(Main loopの処理を保護するため?)
- 他にタスクがない時、Main loopの処理はCore1を占有できる。
ベストプラクティス
よくわかりませんw
パフォーマンス向上というより割り込み待ち時間のリスクを減らすのが主な目的? 特に理由がなければmain loopのみ使う。複数コアを使う場合は特定のプロセスがリソースを独占するのを防いだり、リアルタイムな処理のために専用コアを用意したりする場合。MQTTでpubとsubが処理を待ちあわないようにするために。であってます?
その他
xTaskCreatePinnedToCoreについて
下記URLの情報の超意訳です。
xTaskCreateと似ているが、SMP(対称マルチプロセッシング)に対応している。
BaseType_t xTaskCreatePinnedToCore(
TaskFunction_t pvTaskCode,
const char *constpcName,
const uint32_t usStackDepth,
void *constpvParameters,
UBaseType_t uxPriority,
TaskHandle_t *constpvCreatedTask,
const BaseType_t xCoreID)
pvTaskCode
タスクエントリー関数へのポインター。タスクはreternしてはいけない。(i.e. 無限ループさせる).
pcName
そのタスクの名称. 主にデバッグの時に使われます。 最大長はconfigMAX_TASK_NAME_LENで定義されていますが、デフォルト値は16です。
usStackDepth
タスクのスタックのサイズで、タスクが保持できる変数の数です。byte数ですではありません。例えばスタックが16bit幅でusStackDepthが100にの時、200byteがそのストレージに割り当てられます。
pvParameters
タスクが作られる時にそのパラメータとして使われるポインター
xPriority
どのタスクを起動するかを判定する優先順位を設定するパラメータ。
MPUをサポートするシステムはportPRIVILEGE_BITをセットすることでprivileged (system) modeでタスクを作成することができます。例えばpriority 2の優先権をもつタスクを設定するにはuxPriorityに2をセットします。
pvCreatedTask
作成されたタスク参照するhandleを返す。
xCoreID
もしこの値がtskNO_AFFINITYなら作成されたタスクはどのCPUにも固定されません。そしてスケジューラは利用可能などのコアでもそのタスクを走らせることができます。他の値の場合はそのタスクを固定するCPUのインデックス番号を指定します。コア数より大きい数字(portNUM_PROCESSORS - 1)を指定するとこの関数はfailします。
参考文献
https://docs.espressif.com/projects/esp-idf/en/latest/api-reference/system/freertos.html
https://www.mgo-tec.com/blog-entry-arduino-esp32-multi-task-dual-core-01.html
その他の個人的なESP32ネタ
ESP32 〜 Alibaba Cloud IoT Platform をMQTT接続(Arduino Core版)
https://qiita.com/makotaka/items/388fa1ee0eb1f0237012
ESP32 〜 Alibaba Cloud IoT Platform をMQTT接続(FreeRTOS版)
https://qiita.com/makotaka/items/0e9198cc4e397c4d1aa3
最後に
これは私の趣味の世界です。所属する団体の考え方は全く反映していません。
update
関数二つ、task0とtask1作る意味があるのかと聞かれました。なさそうです。 orz
関数task1を削除してtask0だけでいけると思います。。。。
xTaskCreatePinnedToCore(task0, "Task0", 4096, NULL, 1, NULL, 0);
xTaskCreatePinnedToCore(task0, "Task1", 4096, NULL, 1, NULL, 1);
というか、他にも色々ツッコミどころありますね。でも一応検証の目的は達せられるということで修正見送り。