本稿ではGCPサービスのAutoML Natural Languageを使って文章の分類を行います。
経緯
仕事でチャットボットの実装に携わる機会が増え、FAQの分類に使えるのでは?と思ったからです。
**質問(Q)が分類できれば、それに紐づく回答(A)**が分かるはずです。
AutoML Natural Languageとは?
カスタムの機械学習モデルを構築してデプロイし、ドキュメントの分析、分類、エンティティの識別、態度の評価を行えます。
今回はその中でも、分類モデルを作成するText & Document Classificationを利用します。
教師データを用意する
今回は飲食店のFAQ想定でデータを用意してみました。
Single-label-Classificationで学習させるのでDocumentとそのLabelだけ定義します。
| Document | Label |
|---|---|
| お手洗いはどこですか | toilet |
| 会計はクレジットカードでも良いですか | credit |
| タバコは吸えますか | tobacco |
| 予約はできますか | reservation |
| 宴会で利用できますか | party |
| 何時から営業してますか | starttime |
| 何時まで営業してますか | endtime |
| 営業日はいつですか | businessday |
| 最寄駅からのルートを教えてください | root |
| WiFiはありますか | wifi |
公式ドキュメントによると1Label当たり最低10Documentが必要で、推奨は1000Documentです。
今回は最低限の10Documentで学習させようと思うので、次のように表現を変えて1Labelに対するDocumentのバリエーションを作ります。
| Document | Label |
|---|---|
| タバコは吸えますか | tobacco |
| タバコを吸いたい | tobacco |
| 喫煙所はありますか | tobacco |
| 喫煙できますか | tobacco |
| 最寄りの喫煙所を教えて | tobacco |
| タバコ | tobacco |
| 喫煙できるか | tobacco |
| 喫煙可能か | tobacco |
| タバコ吸えるか | tobacco |
| 喫煙ルームはありますか | tobacco |
教師データをインポートする
Natural Language productsのAutoML Text & Document ClassificationのGet startedをクリックする。
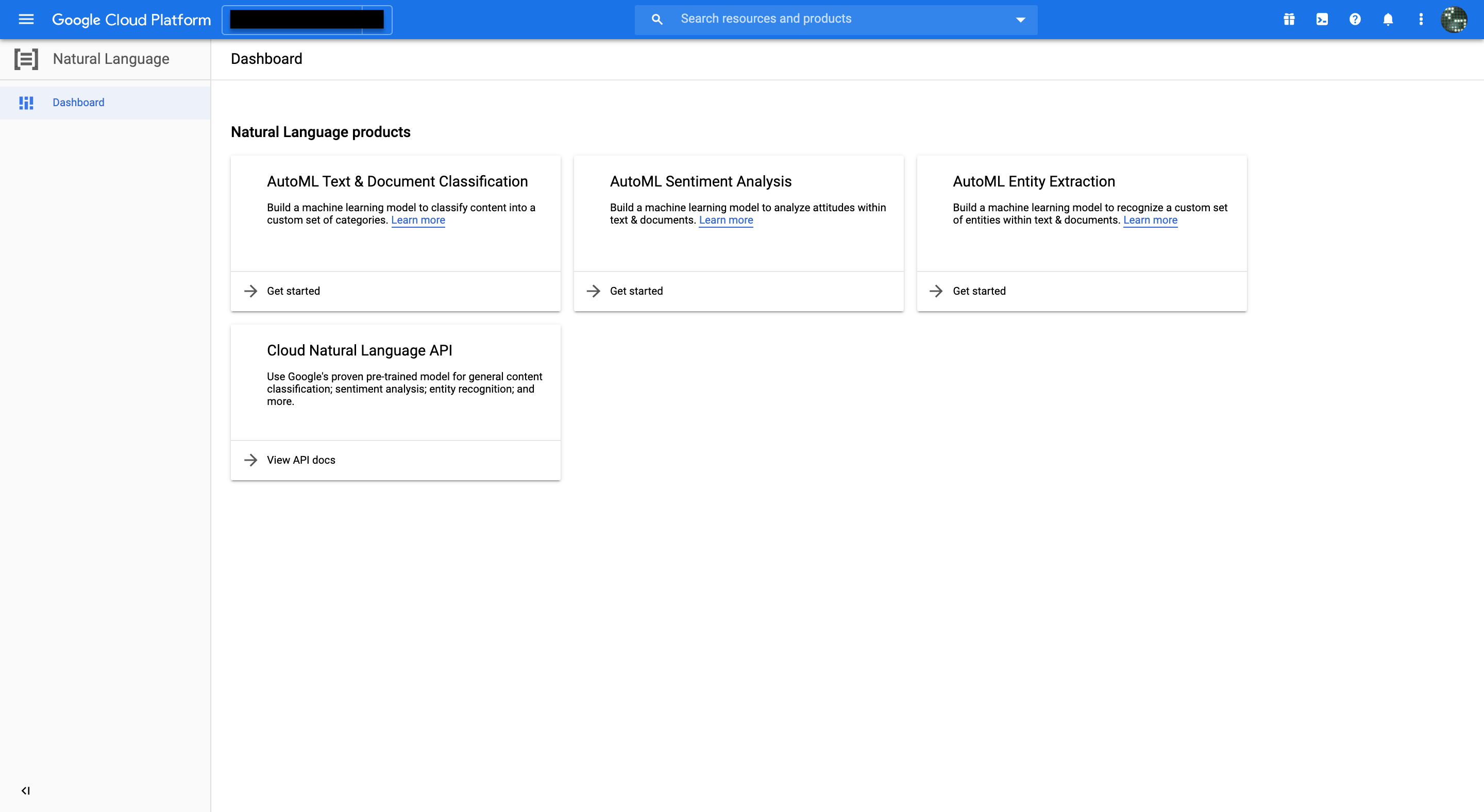
ヘッダーのNEW DATASETをクリックして次のダイアログを開く。
Dataset name:restaurant_faq
Location:任意
Select your model objective:Single-label-Classification
でCREATE DATASETをクリックする。
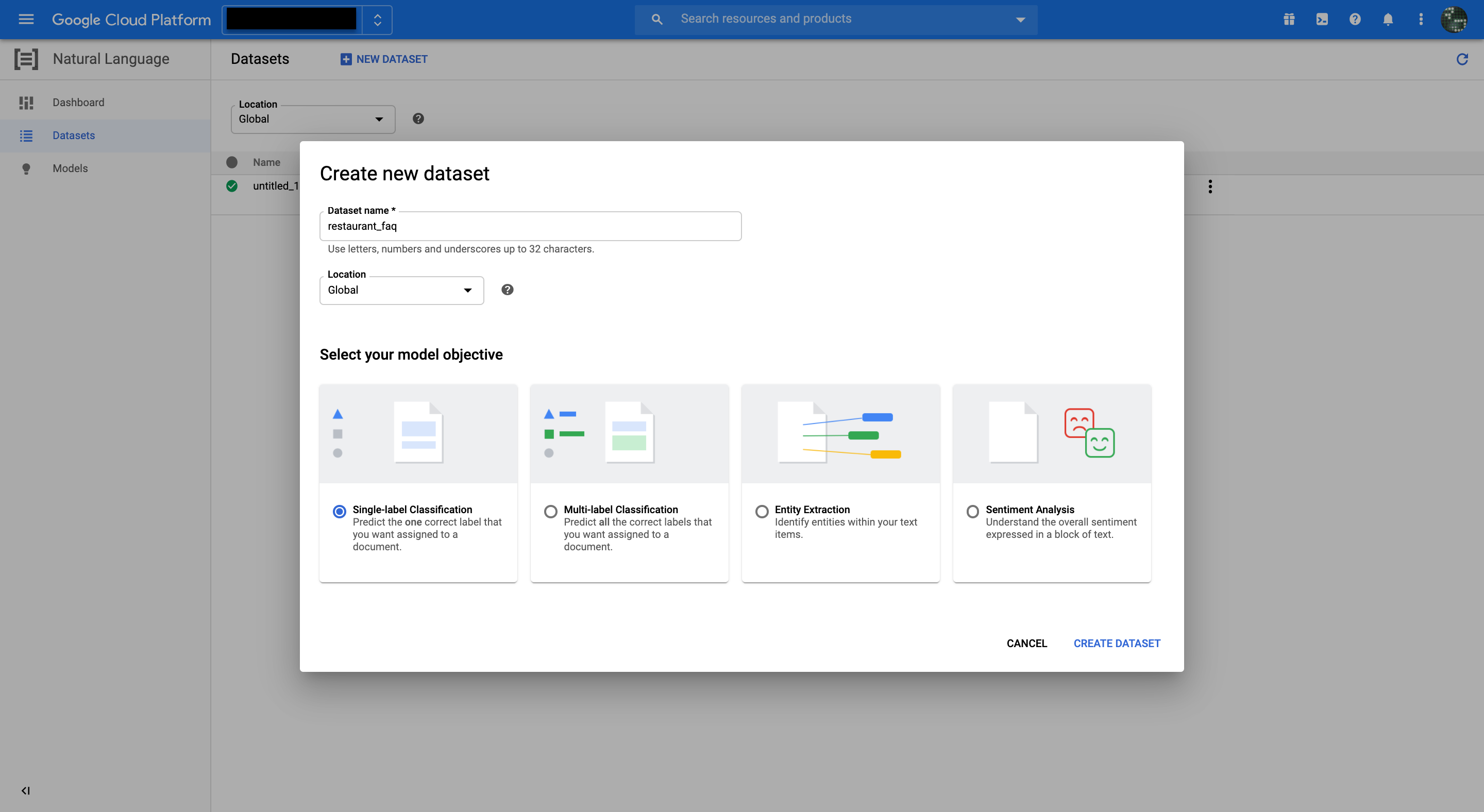
今回はローカルのCSVをアップロードするので、Upload a CSV file from your computerを選択する。
SELECT FILESでrestaurant_faq.csvで保存しておいたCSVデータを選択する。
最後にアップロード先のGSCバケットを指定して、IMPORTをクリックする。
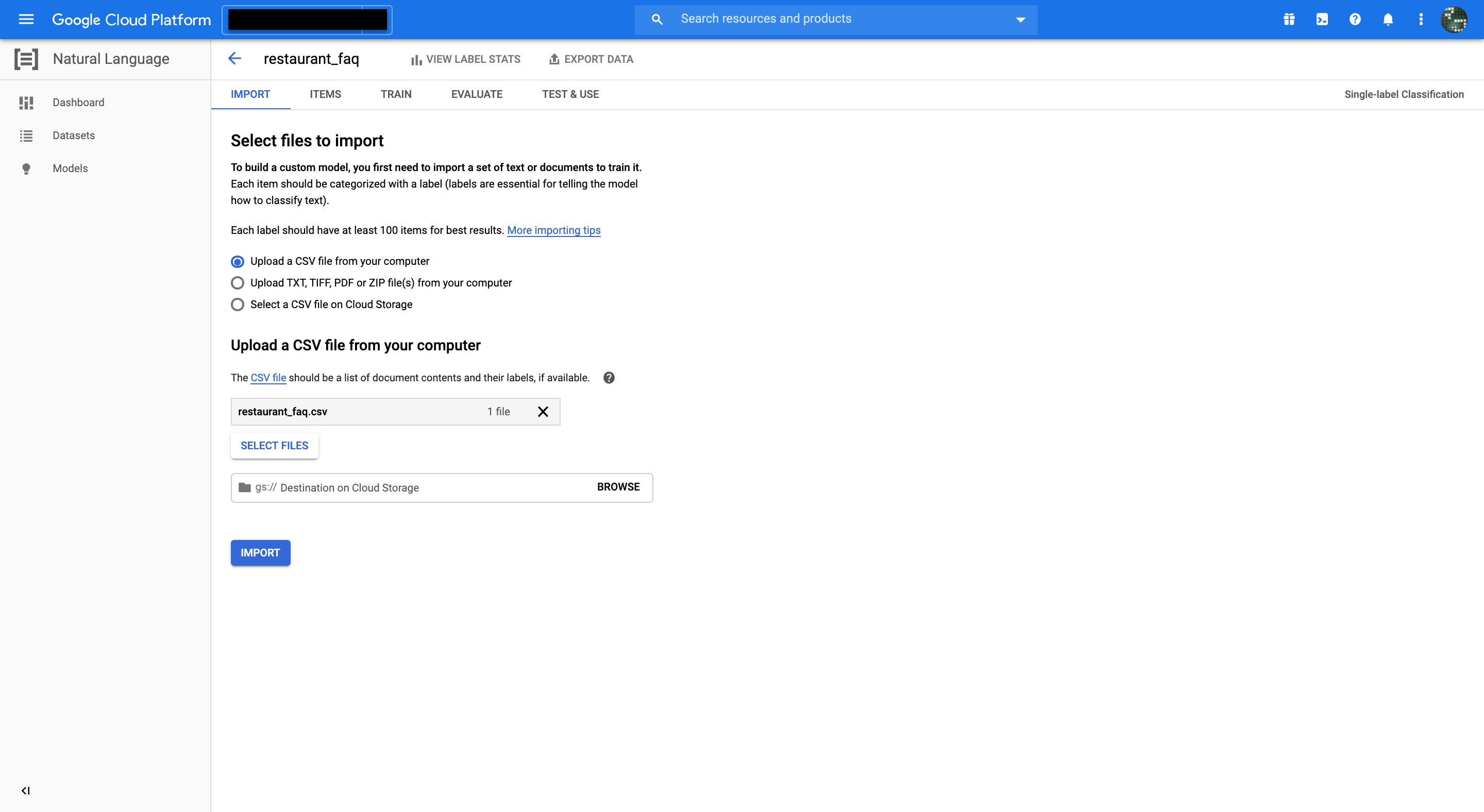
インポートが始まります。同時に、インポート開始メールが送信されます。
このインポートにはめちゃくちゃ時間がかかります。
今回の100Document10Labelのデータでさえ10分以上かかりました。
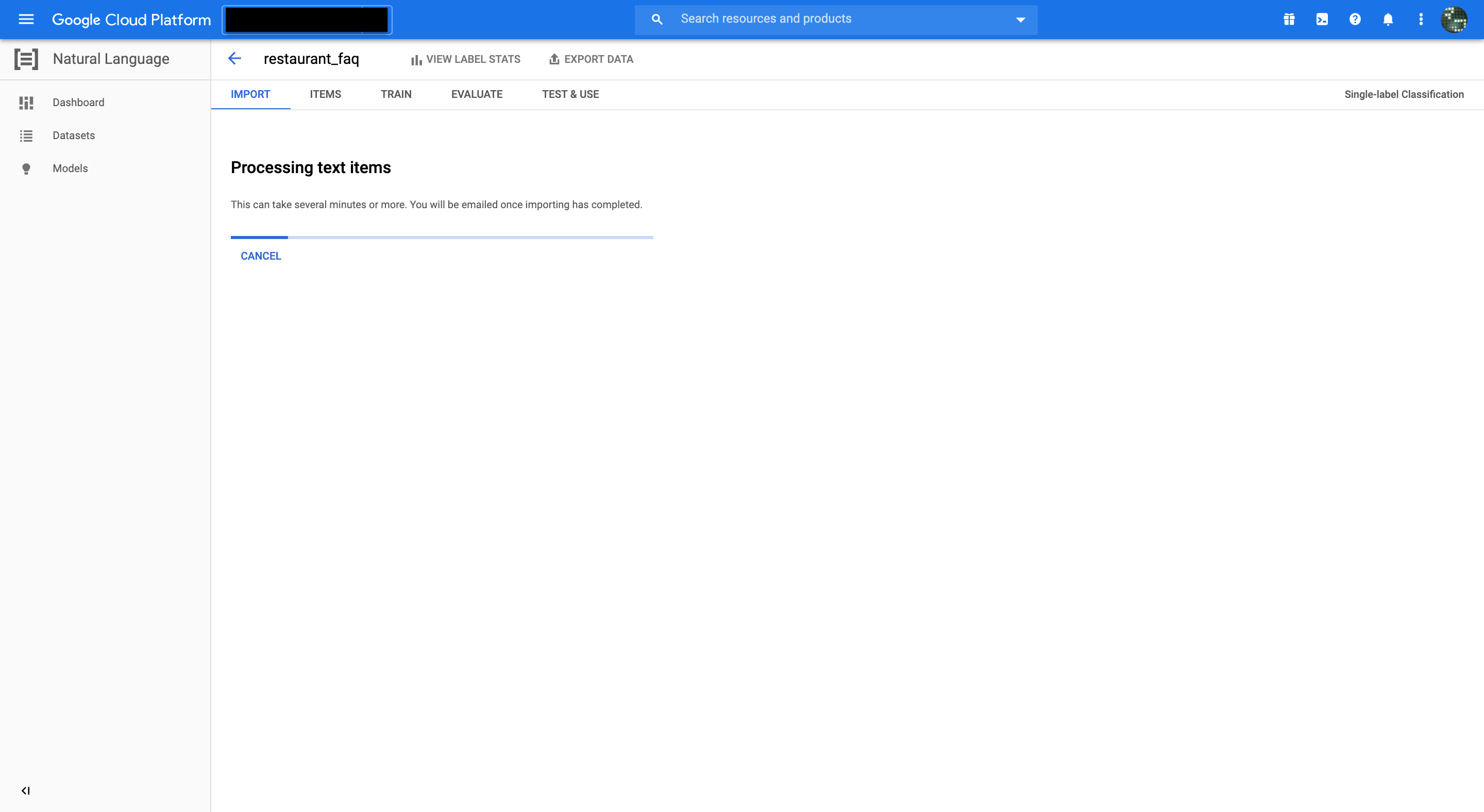
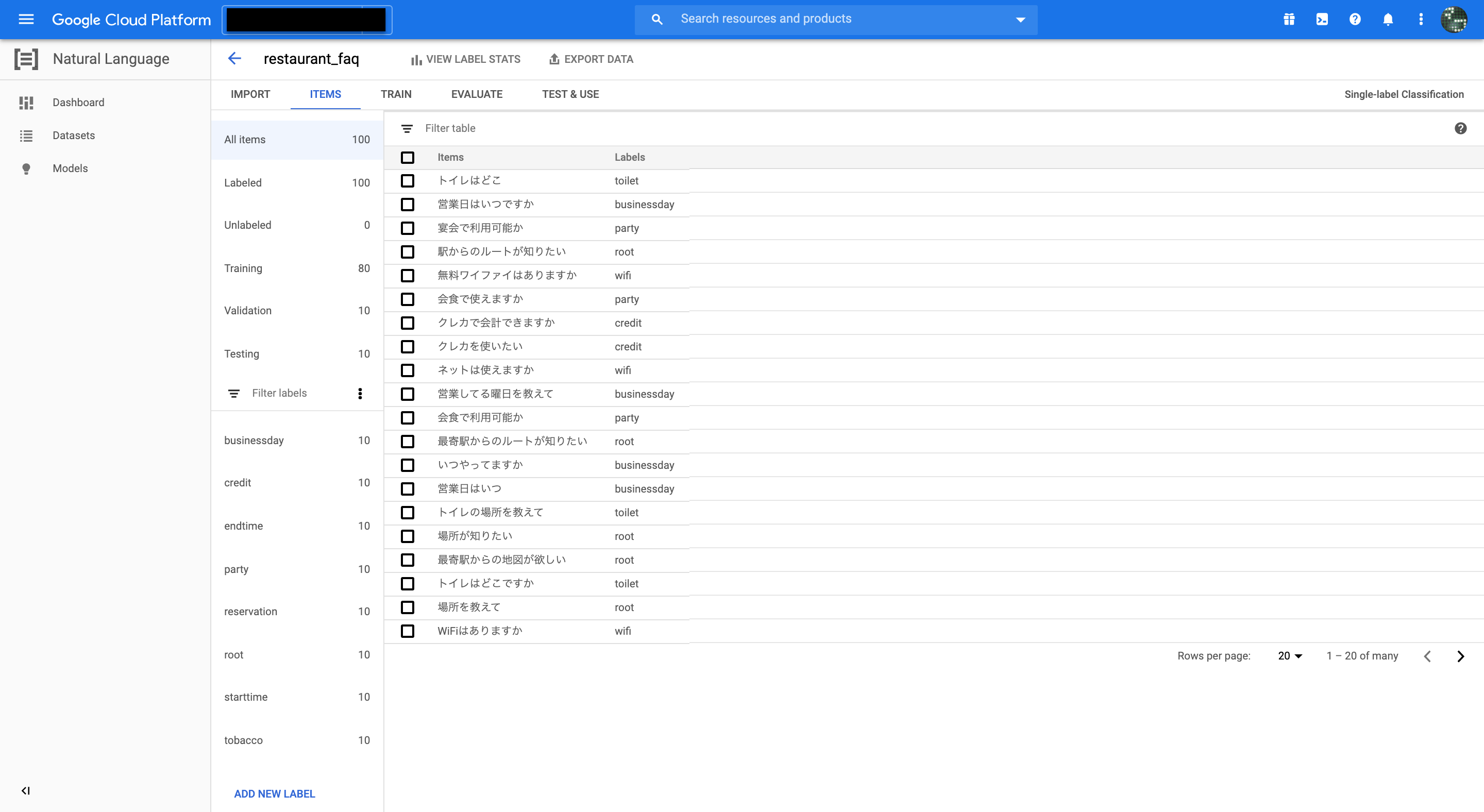
インポートが終わるとITEMSタブからデータを確認することができます。
Documentの重複等のデータ不備があればこの画面でワーニングが出るので分かります。
学習を開始する
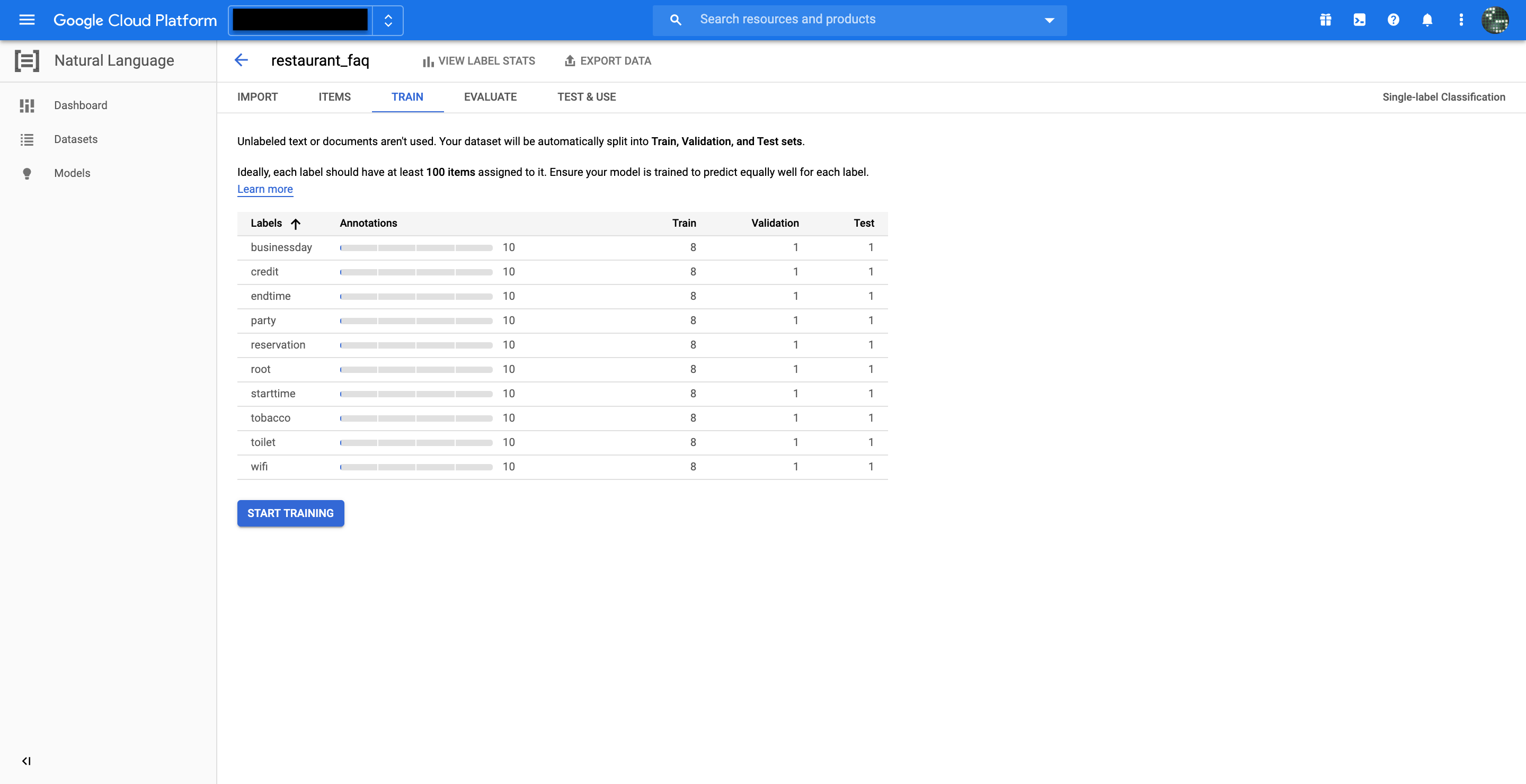
TRAINタブからトレーニング・バリデーション・テストに使うデータ数が確認できます。
Documentの80%がトレーニングに使われ、10%がバリデーション(ハイパーパラメータの調整)、残りの10%がテストに使われます。
START TRAININGボタンをクリックして学習を開始します。
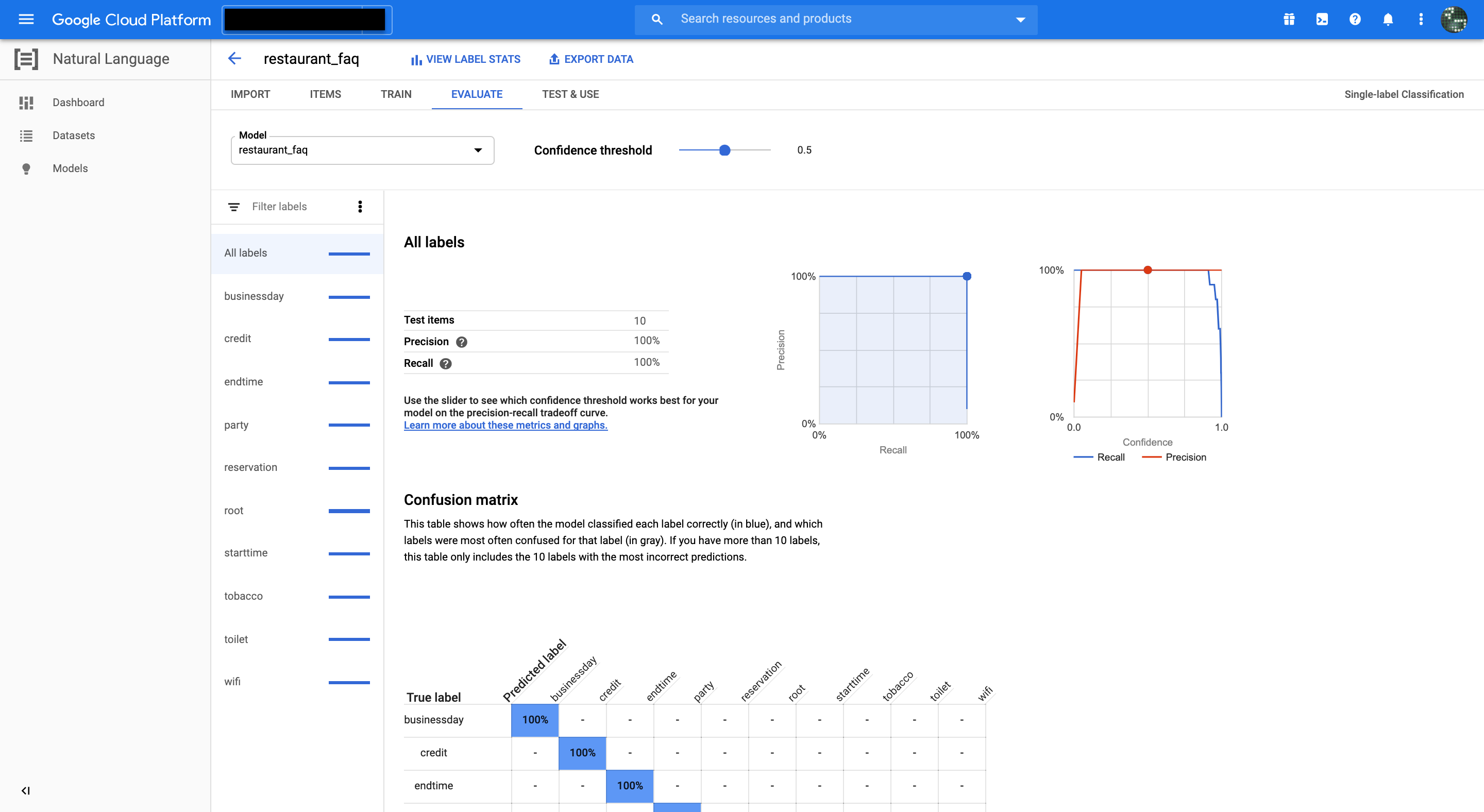
待つこと5時間...無事学習が終わるとEVALUATEタブからモデルの評価を確認できます。
各種データが少ないからなのか、PrecisionとRecallが共に100%出ています。
※学習は1時間3ドルかかります。今回だと15ドルかかった計算になります。GCP特有の無料枠があるかと思い、なくても今回のデータくらいならそんなにかからないだろうと思っていて、料金を調べず試していたら数千円の請求がきてしまいました。Predictは無料枠があるみたいです。
予測してみる
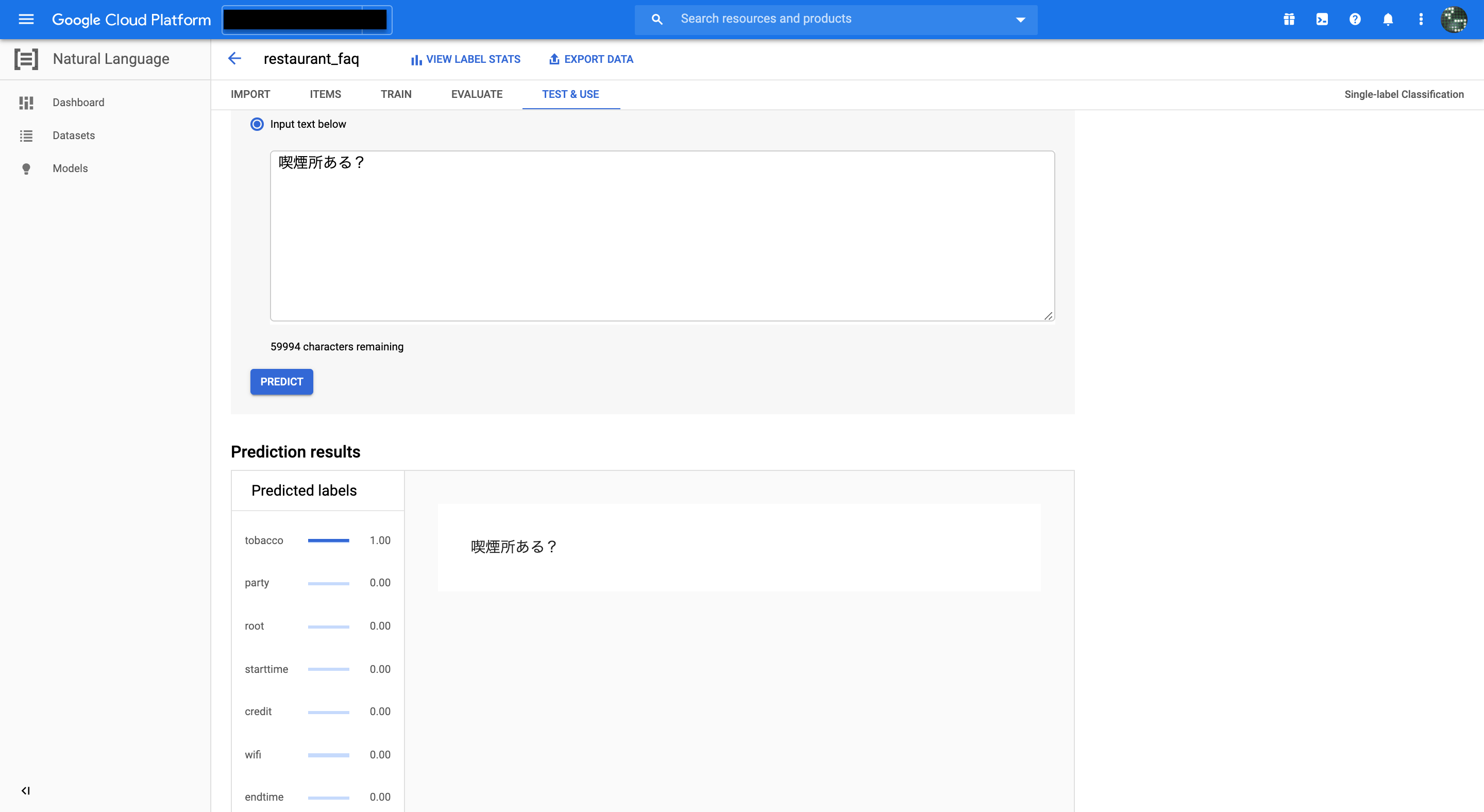
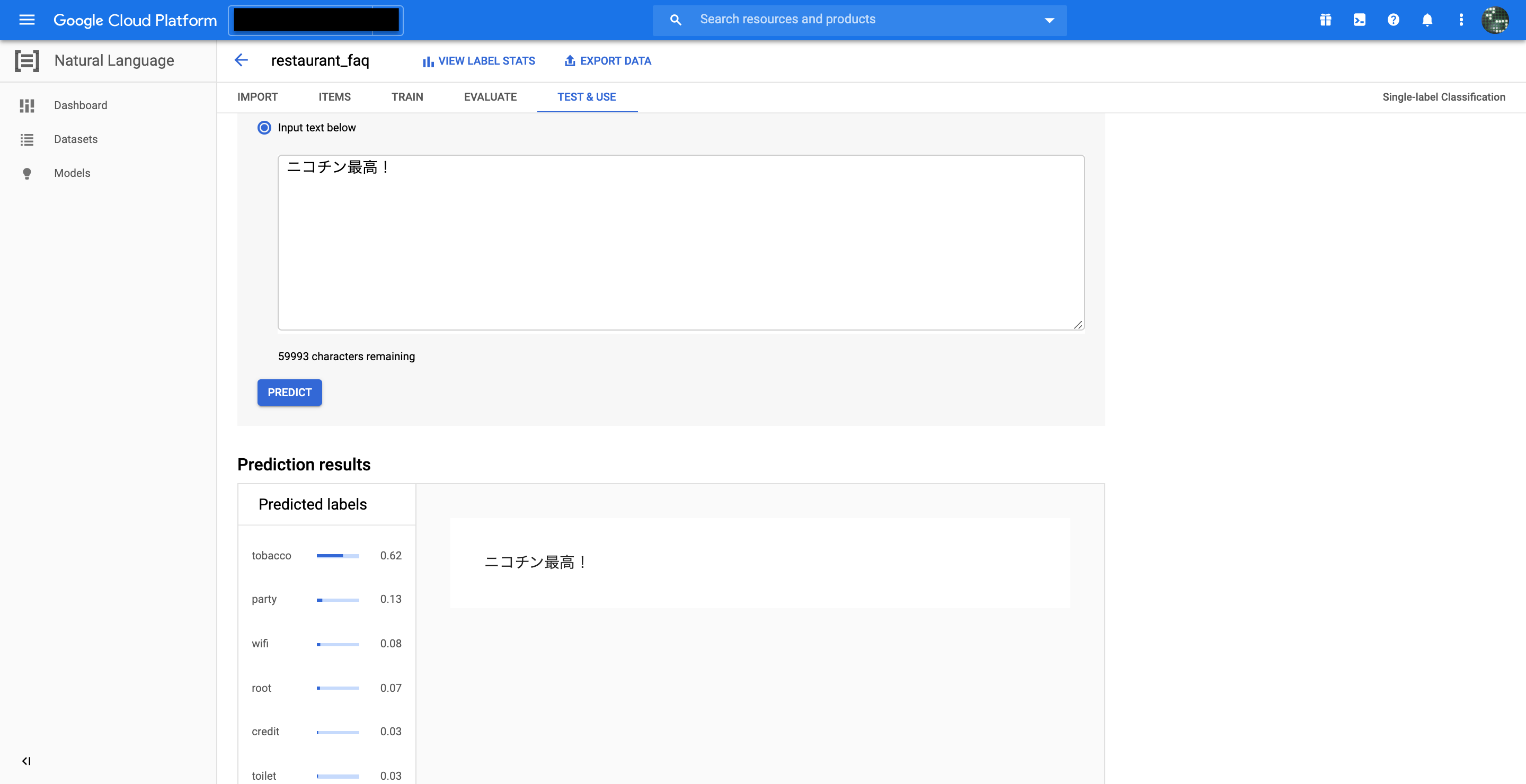
喫煙所ある? を試して見ます。
完全一致の文章は学習データに含まれてませんが、喫煙所という単語は含まれているため、見事にtabaccoのスコアが1.00!
次に全く学習データに含まれていない ニコチン最高! という文章を投げてみると、スコアは落ちるもののtabaccoであると言っています。凄い。タバコ=ニコチンという学習もしてくれていそうですね。
終わりに
FAQの分類に使えそうですね。
長い文章も学習できるので、より複雑なFAQにも対応できそうです。
ただし...お高い。